Elixir で再帰的にリンクをクロールしページ情報を取得するクローラーを作る
Elixir でシンプルなクローラーを作ってみたのでまとめます。
何を作る?
URL を渡すと、そのページに含まれるリンクから同ホストのページを再帰的にクロールして、全ページの title と description を出力するクローラーを作ります。
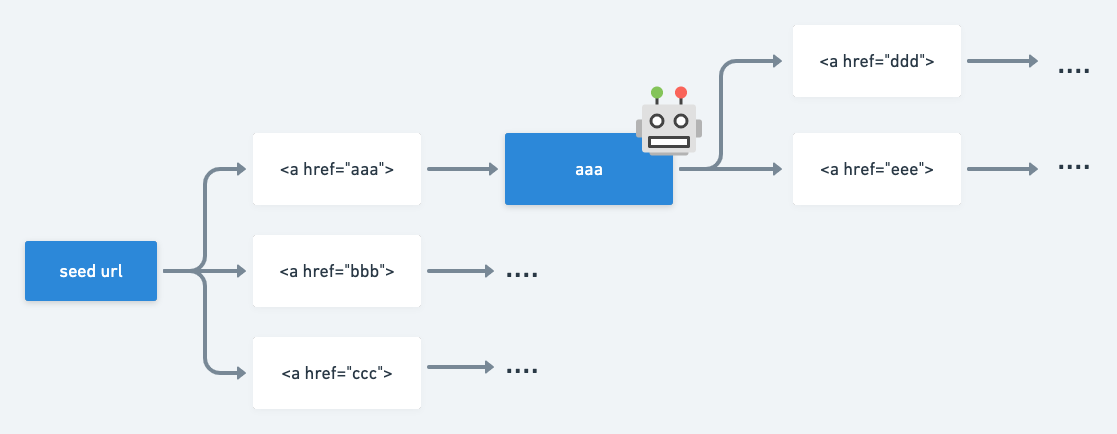
実際の動作はこちらです。
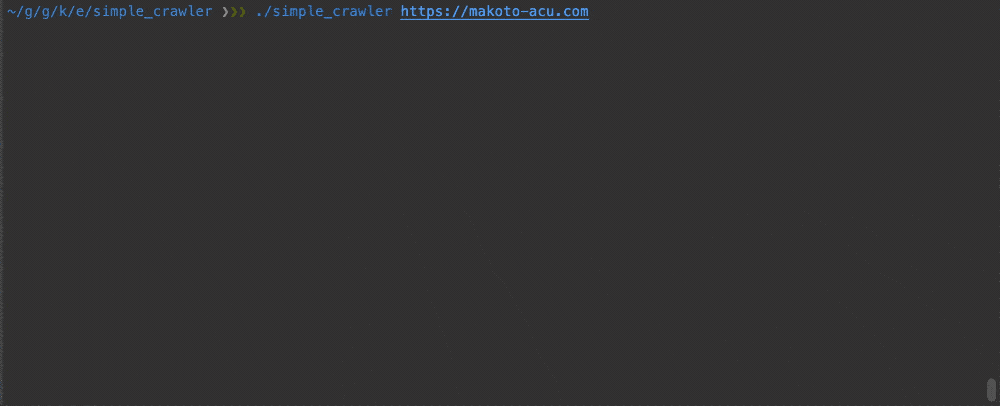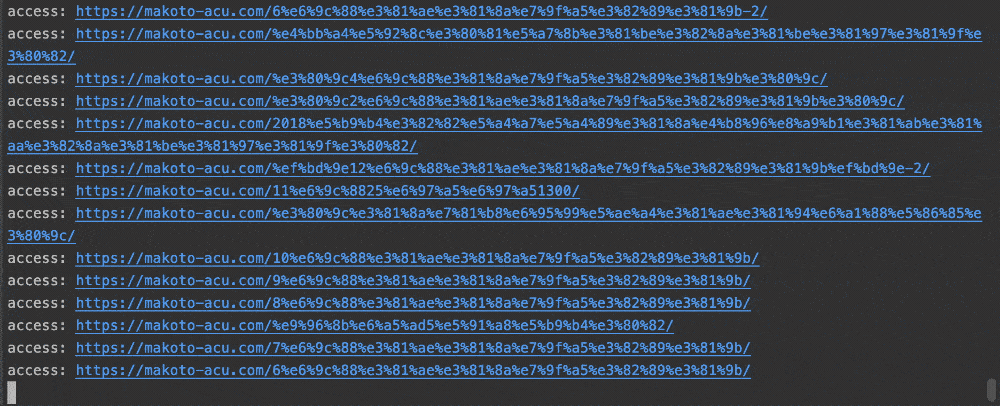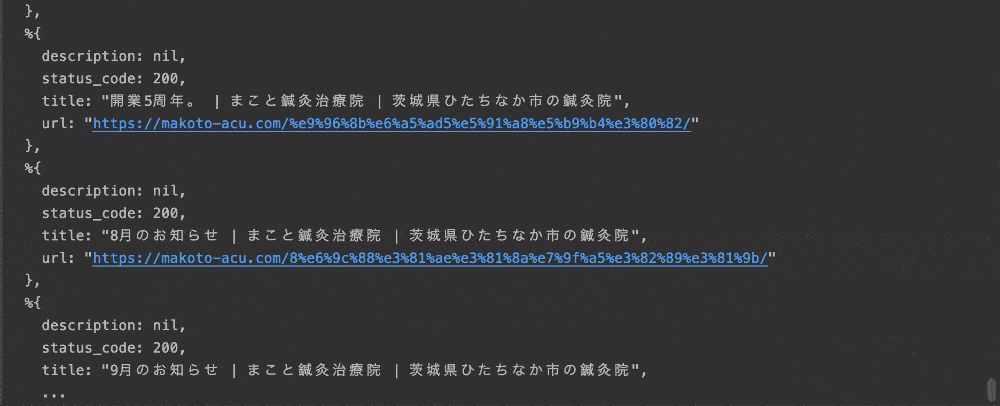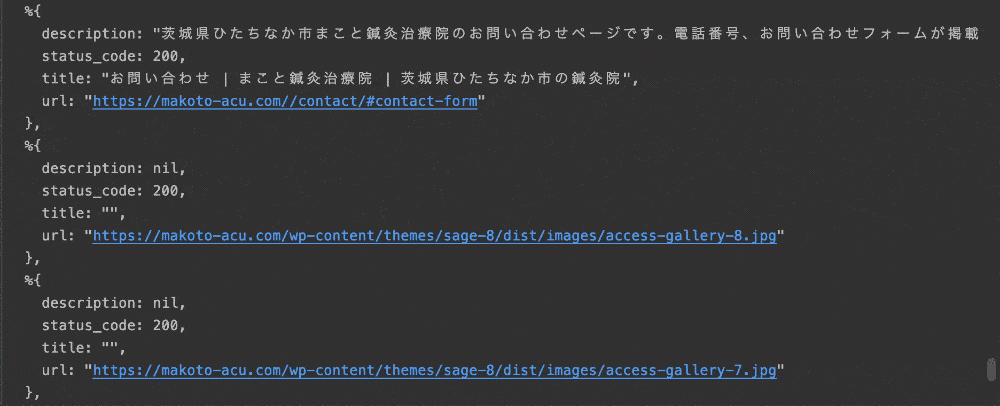
※ 以降で説明するコードは全て以下リポジトリにあります。
環境構築
mix で Elixir のプロジェクトを作成します。
$ mix new crawler
$ cd crawler
次に HTTP クライアントの Httpoison、 HTML パーサーの Floki を依存関係に追加します。
defmodule Crawler.MixProject do
# ...
defp deps do
[
{:floki, "~> 0.30.0"},
{:httpoison, "~> 1.8"},
]
end
end
最後に deps.get で依存関係をインストールすれば環境構築は完了です。
$ mix deps.get
クローラーの実装
クローラーを実装します。
lib/crawler.ex を以下のように修正します。
defmodule Crawler do
def run(seed_url) do
Agent.start_link fn -> [] end, name: :crawled_result
crawl(seed_url, seed_url)
result = Agent.get :crawled_result, &(&1)
Agent.stop :crawled_result
result
end
defp crawl(target_url, seed_url) do
crawled_link_list = Agent.get :crawled_result, fn list -> Enum.map(list, &(&1[:url])) end
if !Enum.member?(crawled_link_list, target_url) do
IO.puts "access: #{target_url}"
%HTTPoison.Response{status_code: status_code, body: body} = HTTPoison.get!(target_url)
document = Floki.parse_document! body
page_info = document
|> parse_title_and_description
|> Map.merge(%{url: target_url, status_code: status_code})
un_crawled_link_list = document
|> parse_same_host_links(URI.parse(seed_url).host)
|> Enum.filter(&!Enum.member?(crawled_link_list, &1))
Agent.update(:crawled_result, &([page_info | &1]))
Enum.map(un_crawled_link_list, &(crawl(&1, seed_url)))
end
end
defp parse_same_host_links(document, host) do
document
|> Floki.find("a")
|> Floki.attribute("href")
|> Enum.filter(& &1)
|> Enum.map(&URI.parse &1)
|> Enum.filter(& &1.host == host)
|> Enum.map(&to_absolute_uri &1, host)
|> Enum.filter(&Regex.match?(~r/^(http|https)/, &1.scheme))
|> Enum.map(&URI.to_string &1)
end
defp to_absolute_uri(uri, host) do
case uri.host do
nil -> URI.merge(host, uri)
_ -> uri
end
end
defp parse_title_and_description(document) do
title = document
|> Floki.find("title")
|> Floki.text
description = document
|> Floki.find("meta[name=description]")
|> Floki.attribute("content")
|> Enum.at(0)
%{title: title, description: description}
end
end
crawl 関数では渡された URL のページにアクセスして、ページ情報(title, description)を取得するとともに、ページに含まれる全てて a タグを取得し、再帰的に処理を実行しています。
そのまま全ての aタグのリンクにアクセスすると、インターネットの海から返ってこなくなってしまうので、parse_same_host_linksで同ホストのリンクのみに制限しています。また、Agent を使いクロール済みのページ情報(crawled_result)を状態として持ち、一度到達したページはスキップすることで無限ループを防いでいます。
この状態でiex -S mix で REPL を起動して、Crawler.run を実行すると、指定した URL からリンクで辿れる同ホストの全てのページ情報が出力されるはずです。
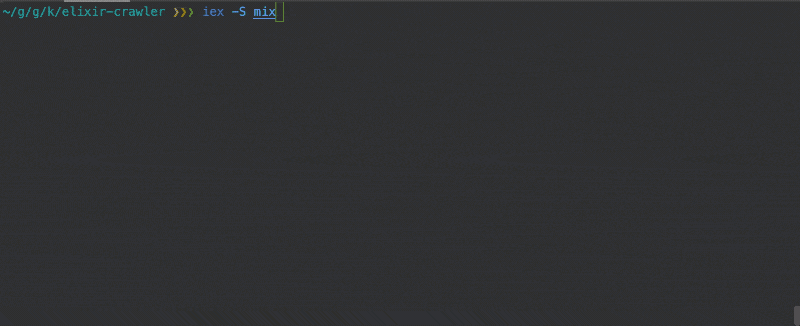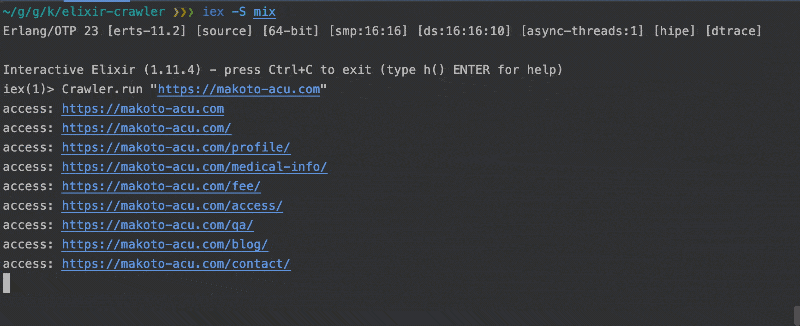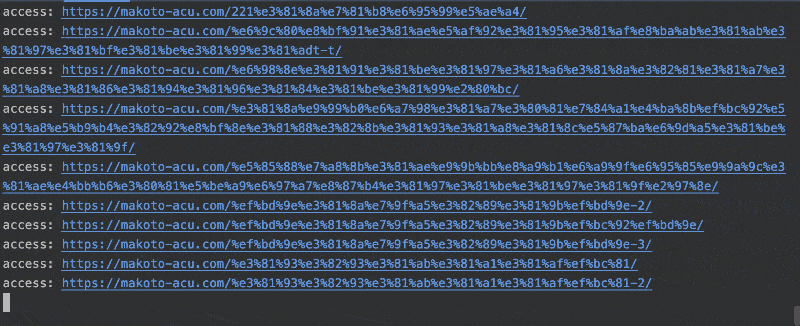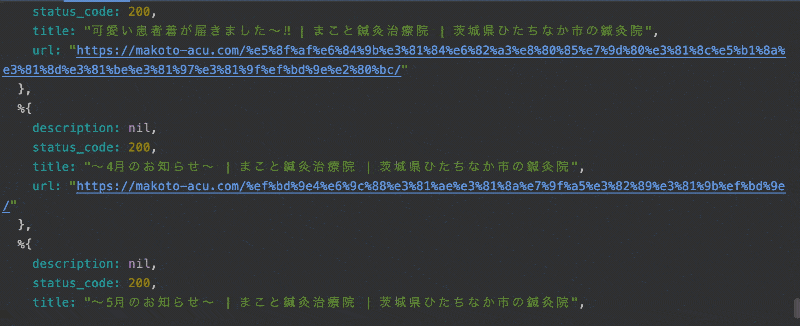
実行ファイルとしてビルド
コマンドラインで簡単に動かせるように実行ファイルとして書き出してみます。
lib配下にcrawler_cli.exを追加します。
defmodule Crawler.CLI do
def main(args) do
[url | _] = args
url
|> Crawler.run
|> IO.inspect
end
end
mix.exs にスクリプトの設定を追記します。
defmodule Crawler.MixProject do
use Mix.Project
def project do
[
app: :crawler,
version: "0.1.0",
elixir: "~> 1.11",
start_permanent: Mix.env() == :prod,
deps: deps(),
+ escript: [main_module: Crawler.CLI]
]
end
# ...
end
最後に mix でスクリプトをビルドします。
$ mix escript.build
プロジェクト直下にcrawlerという実行ファイルが作成されます。
以下でクロール結果が標準出力に表示されます 🎉
$ ./crawler https://makoto-acu.com
CLI での出力の際にEnum.filter(&Regex.match?(~r/^(4|5).*/, "#{&1.status_code}"))をパイプすれば、400 系、500 系となるリンクだけ出力するなども可能です。
終わりに
以上、簡単ですが Elixir で作るクローラーでした。とても単純な仕組みですが、Elixir とクローラーの勉強になって良かったです。
📣 宣伝 📣
モブプロ生配信「4 時間でフロントエンジニアはクローラー開発者になれるのか?」と題して、LAPRAS の開発チームで Web クローラー開発を YouTube 配信しています。普段のプロダクト開発とほぼ変わらない形でワイワイ開発しているので「モブプロのやり方に興味がある」「クローラーってどうやって作るのだろう?」など思った方は視聴してもらえると嬉しいです!
Discussion