Prisma を使って Firestore のデータを SQLite にダンプする
Firestore のデータを SQLite にダンプしてみたので、そのメモです。
なぜ Firestore のデータを SQLite に?
個人的に GitHub Trending に掲載されたリポジトリ情報を流す Twitter Bot を運用しているのですが、その元データ(日々の GitHub Trending のデータ)が Firestore に溜まっていました。
そのデータを分析したらおもしろそうと思ったのですが、Firestore の NoSQL のデータのまま分析をするのが少し面倒で、慣れた SQL でデータを扱いと考え SQLite へのデータ移行に行き着きました。
SQLite を選んだ理由は、とくに DB のセットアップが不要で、ファイル単位で管理できるというのが手軽で都合良かったからです。
運用中の TwitterBot
| @ghtrending | @gh_trending_js |
|---|---|
 |
 |
| @gh_trending_py | @gh_trending_rs |
|---|---|
 |
 |
TwitterBot の作成記事
なぜ Prisma?
データの出力自体は、Firebase の Admin SDK を使ってデータを取得し、sqLite3 など SQLite のクライントを使えば容易にできます。ただ、悲しいかな ORM に慣れてしまった身として、コード中に SQL をそのまま書くことに若干抵抗がありました。そこで、以前から試したかった Prisma を使ってみようと思い立ちました。
Prisma は型安全にクエリを発行でき、マイグレーションも管理してくれる Node.js 用の ORM です。
RDB の構成
Firestore に保存している GitHub Trending のデータ構造は以下のようなものでした。
この構造が、すべての言語、JavaScript & TypeScript、Python、Rust のトレンド種別ごとにあります。
type GHTrend = {
owner: string;
repository: string;
language?: string;
description?: string;
starCount: string;
forkCount: string;
todayStarCount: string;
ownersTwitterAccount?: string;
url: string;
createdAt: number;
tweeted: boolean;
};
このデータ構造を正規化し、以下のようなテーブル構造にしました。
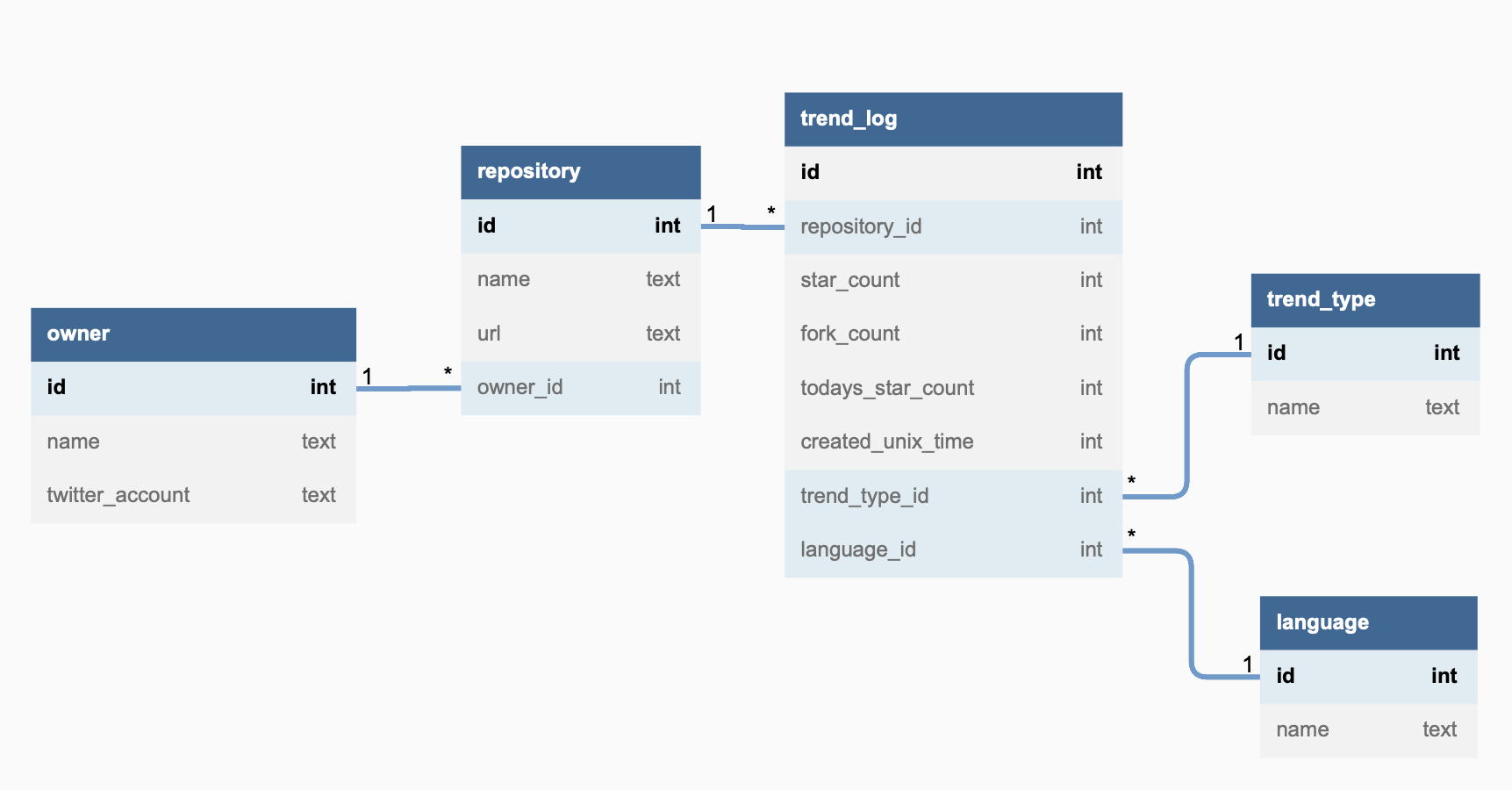
素直に正規化しただけですが、一部特殊なのは言語情報を司るlanguageテーブルが、repositoryテーブルではなく、trend_logテーブルに紐付いている点です。これは、language の情報があくまで trend に掲載された時点の情報で、その後リファクタリング等により変わる可能性があるからです(実際に複数言語でトレンドに掲載されたリポジトリがありました)。
実装
Prisma を使ってダンプするまでの実装を簡単にまとめます。
実際のコードはこちらのリポジトリにあります。
Prisma のセットアップ
まず Prisma のセットアップです。
公式ドキュメントの通りに環境設定します。
$ npm install prisma typescript ts-node @types/node --save-dev
$ npx prisma init
これで、Prisma のディレクトリが自動作成されます
prisma
└── schema.prisma
スキーマの作成
shema.prisma に DB のスキーマを記述します。
前述の DB 構造を表すスキーマはこちらです。
@relationでテーブル同士のリレーションを、@uniqueでユニーク制約を表しています。
スキーマを記述後、以下コマンドを実行すると、prisma 配下に SQLite の DB が作成されます。また、その DB の構造に合わせたクライアントの型定義も node_module の prisma 内に生成されます。
$ npx prisma migrate dev --name init
prisma
├── github_tending.db
├── github_tending.db-journal
├── migrations
│ ├── 20220707223253_init
│ │ └── migration.sql
│ └── migration_lock.toml
└── schema.prisma
Firestore からの dump スクリプトの作成
Firestore からのダンプは以下コードで行いました。
Firebase Admin SDK を使って、Firestore のデータを取得し、Prisma の ORM のクエリーセットを使って DB にデータを挿入しています。
RDB とする都合上、データの挿入順は重要です。リレーションの末端となるテーブルへのデータ挿入は先に行っています。また、挿入時に重複が生まれないように、trend_log 以外のテーブルは、データがある場合はそのレコードを取得し存在しない場合は挿入するという処理を行っています。
あとは、このスクリプトを ts-node で実行すれば、prism/github_trending.db にデータが挿入されます。
$ npx ts-node --files admin/dumpData.ts
データ分析(一部)
SQLite にデータが入ったので、後は好きな DB クライントで SQLite に接続して、データ分析を行えます。
データ分析結果については、別記事にまとめようと思うので本記事では簡単にひとつだけ。
以下 SQL で 2021 年 11 月〜2022 年 7 月 8 日現在までに全言語のトレンドにおいて、どの言語のリポジトリが多く掲載されたかをみるものです。
with all_trend_group_by_repos as
(select t.*, ty.name as trend_type, repo.name as repo_name
from trend_log t
left outer join trend_type ty on t.trend_type_id = ty.id
left outer join repository repo on t.repository_id = repo.id
where ty.name = 'all'
group by repo.url)
select lang.name as language_name, count(alt.repo_name) as repository_count
from all_trend_group_by_repos alt
left outer join language lang on alt.language_id = lang.id
where lang.name != ''
group by lang.name
order by repository_count desc
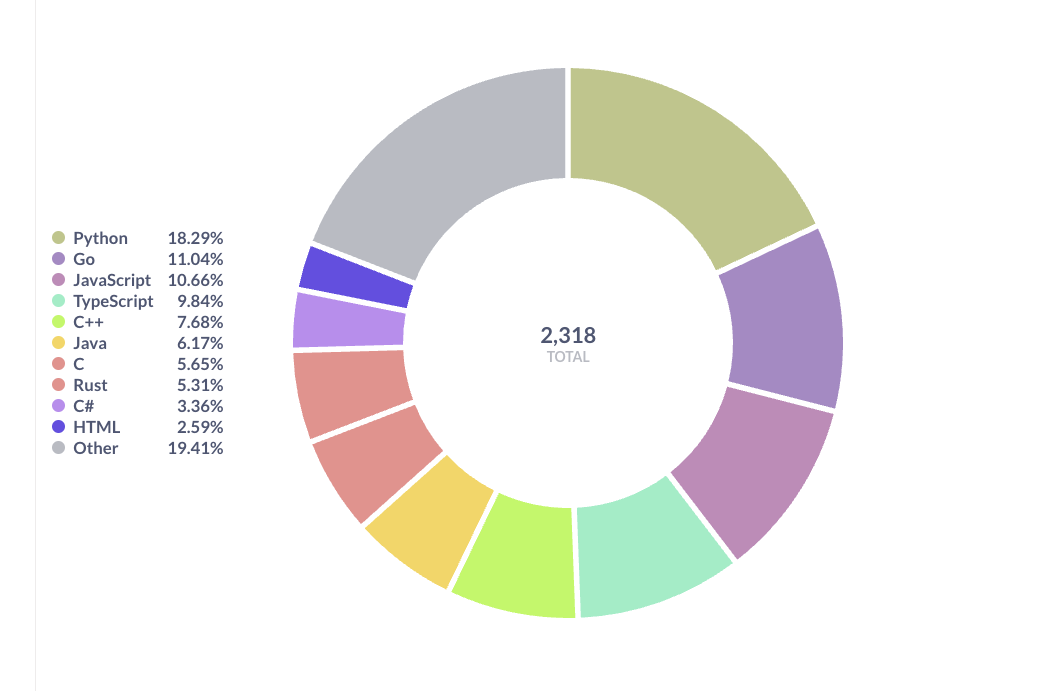
Metabse で可視化するとこのような結果となりました
Python と Go、JavaScript がやはり強いようですね。
おわりに
Firestore は最高に便利ですが、やはり慣れた SQL の方がデータ分析はしやすいですね。
あと、Prisma の開発体験はとても良かったです。今後も色々な機械で使っていこうと思いました。
Discussion