PDF上に隠されている情報を簡易的に表示するツール "PDF Footprint Finder" を作った
PDF Footprint FinderというOSINT用の簡易的なツールを作成しました。
PDF上に隠されている情報をブラウザから簡単にチェックできます。
PDF上に隠されている情報とは
簡易的に閲覧できる範囲のものとして、以下のような情報が考えられます。
もちろん、本格的なForensicsとなるとこれ以外にも考慮すべき点があります。
メタデータ
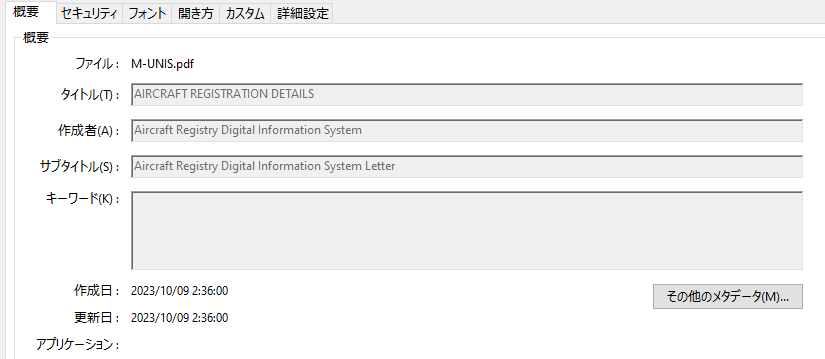
PDFにはタイトルや作成者、作成に使用したツール、作成日時、更新日時などが記録されています。
これはAdobe Readerなどから確認することが可能です。なお、以下で示した2つの例のように、ファイルによって記録されている情報には差があり、空欄になることもあります。

本文の黒塗り・白塗りなど
本文の一部を黒塗り・白塗りにしたり、文字を背景色と同化したりといった方法により、文字列を見えないようにしている文書があります。
ただ、文字列自体は削除されていないため、あくまで「見えづらくなっているだけ」に過ぎません。

隠れているように見えるが、選択してコピー・アンド・ペーストできる
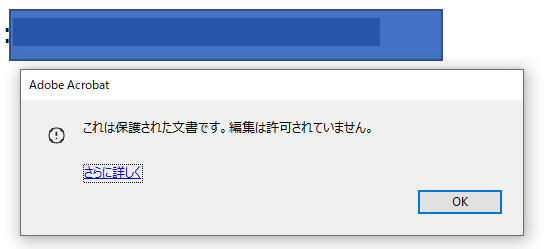
閲覧パスワードに加えて、編集パスワードが掛かっている場合、文字列がコピーできないPDF閲覧ソフトもある
また、実社会のファイルではなかなか遭遇しませんが、ARGや謎解きといったゲームにおいては「文字列に特殊なフォントを適用し、一見すると分からないがコピペすると文字列として読める」といったPDFが与えられる例もあります。
PDF Footprint Finderは何をするツールか
前述した2点の情報を自動で抽出するツールです。ブラウザ上で動作し、PC・スマートフォンのいずれでも利用できます。
- PDFに含まれているメタデータを取得する
- PDF上に含まれている文字情報を抜き出し、テキストとして表示する
PDF.jsというライブラリを使用しており、すべての処理はブラウザ上で行われます。ファイルはサーバ上に送信されません。
使い方
- https://pdf-footprint.vercel.app/ にアクセスする
- PDFファイルを選択する
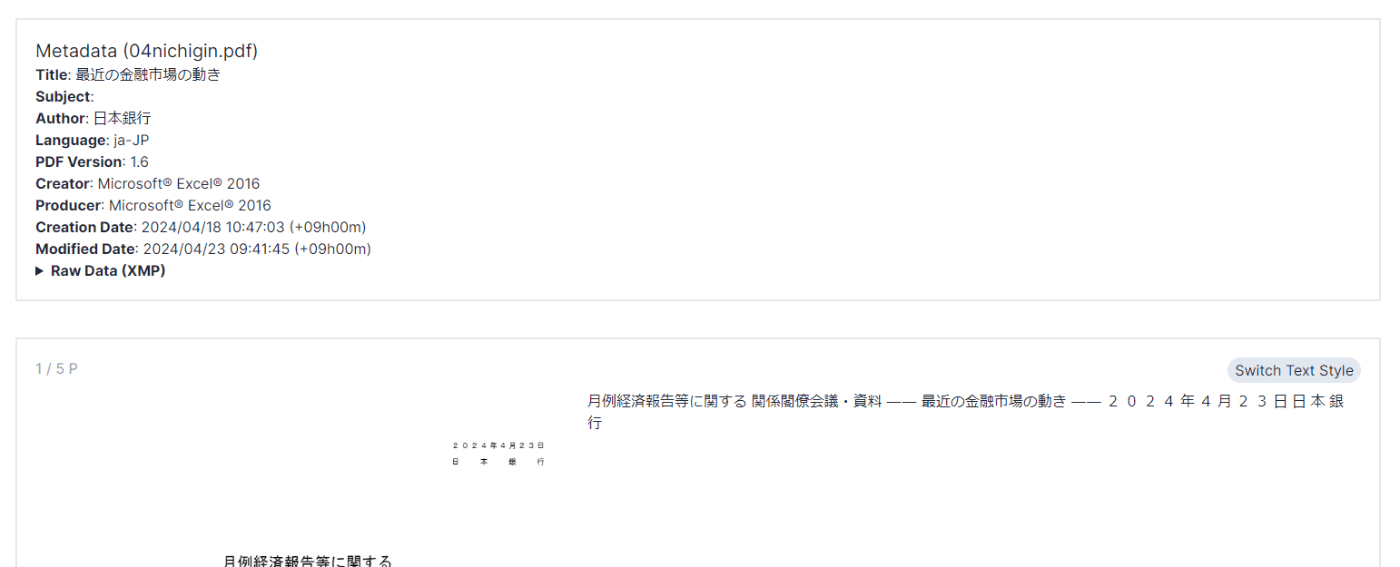
- 抽出結果が表示される(ファイルサイズやPCの性能によって若干時間が掛かる場合があります)
項目が存在しない場合、その欄は空欄になります。
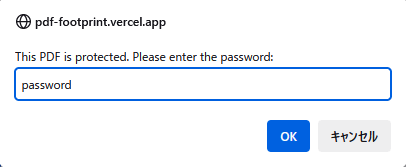
パスワード付きPDFについて
閲覧パスワード付きのPDFを読み込んだ場合、ダイアログボックスが表示されます。
正しいパスワードを入力してEnterを押すことで続行できます。
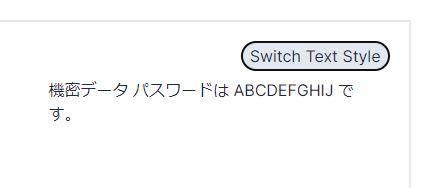
Switch Text Style について
取得したテキストは断片のようなものになっています。デフォルトではこれらを繋げて表示しますが、このボタンを押すことによって断片単位で箇条書きとして表示できます。
どちらが読みやすいかはPDFファイルによるので、必要に応じて使い分けてください。

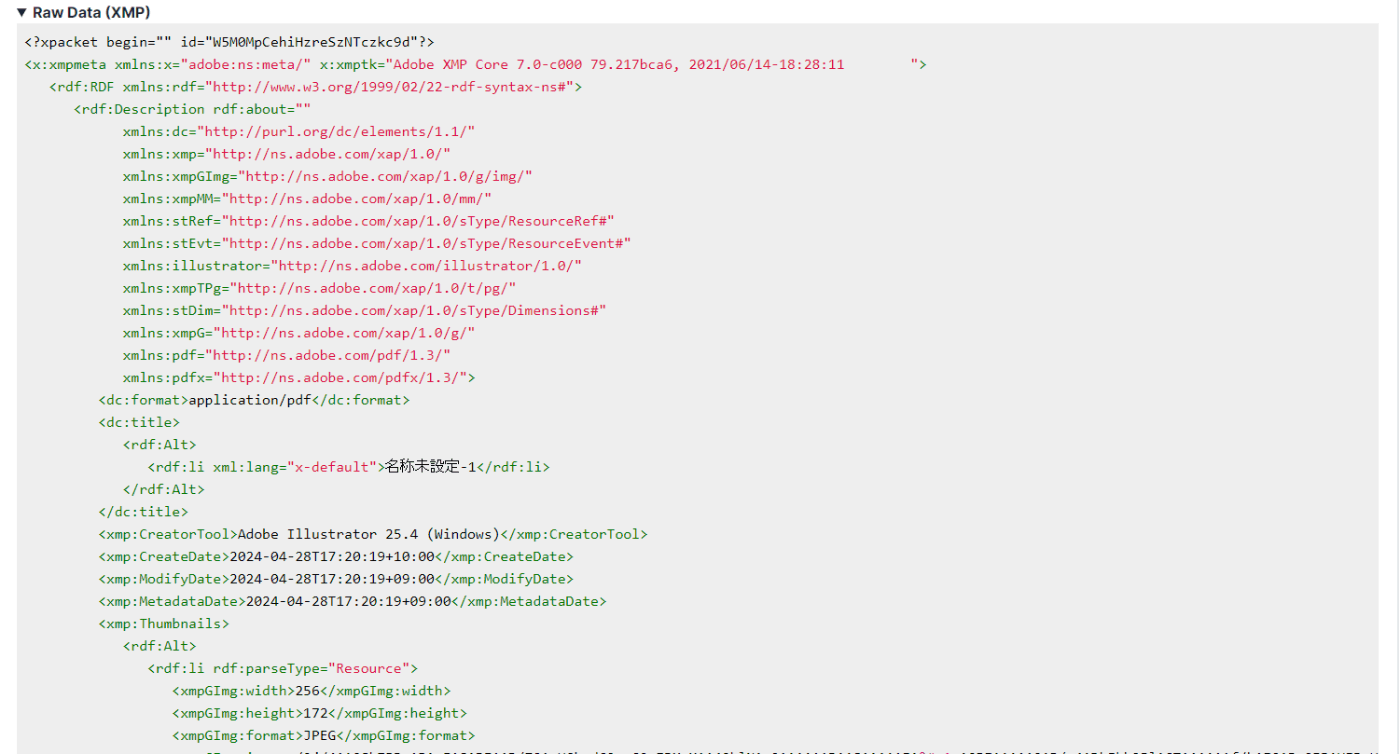
メタデータの生データ(XMP)
メタデータ欄にある "Raw Data (XMP) " をクリックすると、XML形式の生データが表示できます。取得できない場合は空欄になります。
ファイルにもよりますが、ここには編集ソフト側のデータや、使われた画像のファイルパス、作成者の社名・部署名といった詳細な情報が含まれていることがあります。
別のファイルを読み込みたい場合
右上にある"Open Another File"をクリックするか、ページを再読み込みしてください。
自分が作成したPDFに意図しない個人情報が載っていたら?
本ツールで確認できたように、メタデータには思っていたよりも詳細な情報が含まれている場合があります。もちろん、それが公開して差し支えないものであればよいのですが、公開されることを想定していない情報ならば削除するべきでしょう。
書き出し時の設定でこれらを抑制するのが一番確実ですが、その方法が不明な場合や、すでに書き出ししてしまった場合などは別のツールからその情報を削除するという手があります。
有名なものだと、ExifCleanerはXMPデータの削除にも対応しているようです。
ただし、こういった「個人情報を削除する」ことを謳うツールやアプリの中には、信頼性が不明なもの(つまり、受け取ったファイルを外部に送信したり、蓄積したりするもの)もあります。十分に信頼性や評判などを確認してから利用しましょう。