Apache Icebergが未来を制した — 2025年には何が待っているのか?
長年にわたり、データエンジニアリングコミュニティはオープンテーブルフォーマットの未来について議論してきました。Delta LakeのDatabricksとの密接な統合が勝者となるのか? Apache Hudiのストリーミング世界での早期採用が持ちこたえるのか? それともApache Icebergが静かに支配的な存在として浮上するのか?
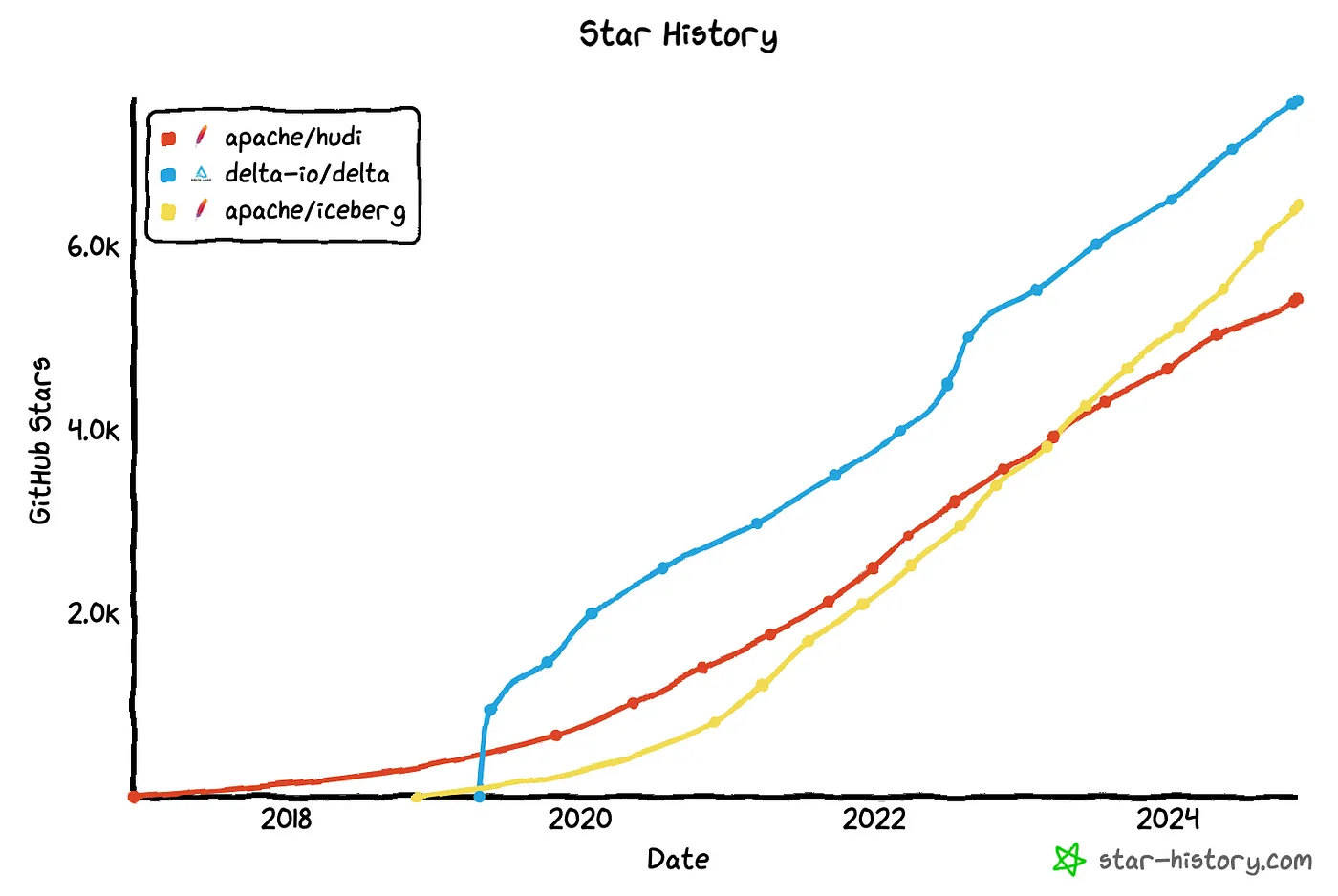
2024年末には、答えが明確になりました:Apache Icebergが勝者です。
私たちはどうしてここに到達したのでしょうか? DatabricksはTabular(Icebergのオリジナルの創設者たちによって設立された会社)を買収し、Icebergの可能性に対する大きな支持を示しました。一方、SnowflakeはPolarisというIcebergベースのカタログ機能を展開しました。StarburstやDremioなど、著名なクエリエンジンベンダーがPolarisをサポートしており、業界は共通の標準に向けて調整されました。

現在、Apache Icebergは事実上のオープンテーブルフォーマットです。しかし、真の物語はこれから始まります。2025年に向けて、Icebergの地位を確固たるものにするいくつかのエキサイティングな開発が待っています。
2025年に向けてIcebergには何が待っているのか?
1. RBACカタログ:大規模な権限管理の解決
正直なところ、データレイクでの権限管理は常に厄介でした。統一されたアプローチがないため、ユーザーはS3バケットレベルでの権限設定や、クエリエンジン固有のアクセス制御を使用するなど、アドホックな方法に頼らざるを得ませんでした。この断片化は効率的ではないだけでなく、セキュリティリスクも引き起こします。
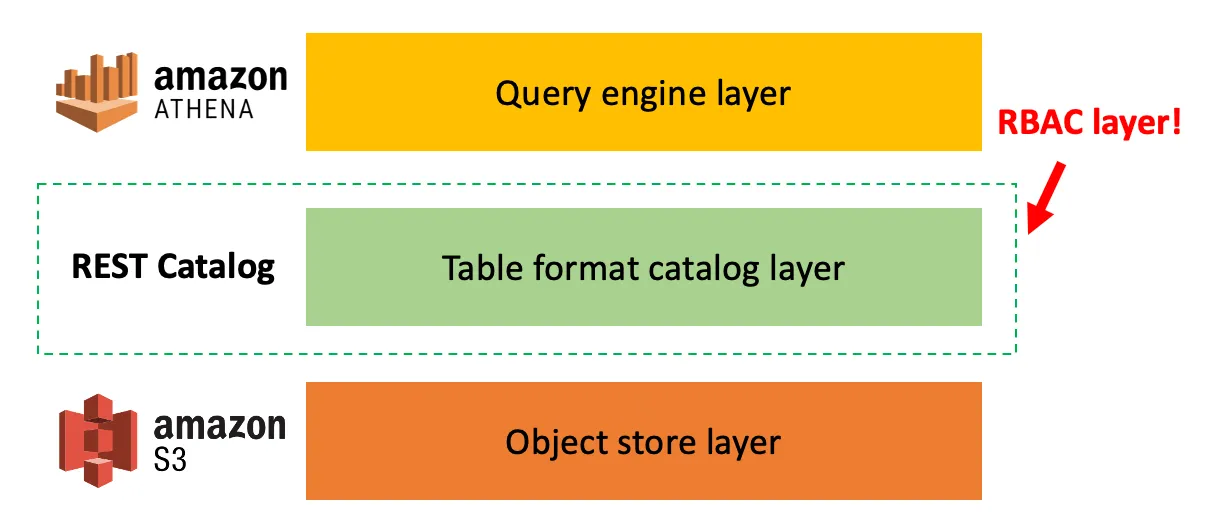
Icebergコミュニティは、この問題を新しいOpenAPI仕様(PR #10722)で解決しています。この仕様は、提供される認証情報の構造を標準化し、開発者がIcebergカタログに直接**ロールベースアクセス制御(RBAC)**システムを組み込むことを可能にします。
例えば、管理者は基盤となるストレージやクエリエンジンに依存せず、カタログレベルで細かいアクセス権限ポリシーを定義できます。これにより、DatabricksのUnity Catalogのような企業向けの機能が提供されますが、Icebergが提供する柔軟性とオープン性を兼ね備えています。
2. 変更データキャプチャ(CDC):Icebergのストリーミング進化
「Icebergはストリーミング向けではない」というのがこれまでの一般的な見解でした。実際、Icebergは堅牢なCDC機能を欠いていました。そのアーキテクチャはバージョン管理されたテーブルスナップショットをサポートしていましたが(Spark CDC手順)、高頻度のデータ変更やリアルタイム分析には最適化されていませんでした。
しかし、Iceberg Spec V3によって、状況は変わりつつあります。これにより、重要な機能である**行の系譜(Row Lineage)**が導入されます。
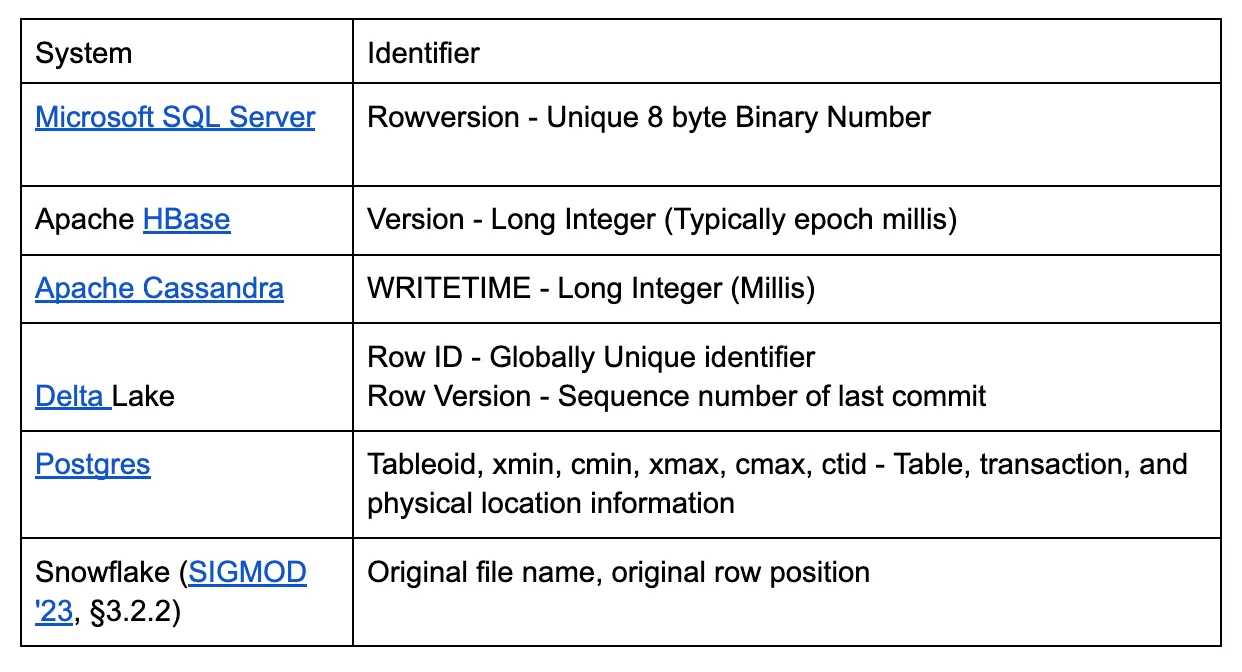
行の系譜は、行が更新、削除、挿入されるたびにその変化を追跡できるようにします。これにより、Icebergテーブルで効率的なCDCパイプラインを直接実装できるようになり、ストリーミングユースケースにおいて大きな前進となります。例えば、マテリアライズドビューのメンテナンスやシステム間のデータ同期がよりシームレスになります。
詳細については仕様提案をご覧ください。Spec V3が完全に実装されれば、IcebergはKafkaやHudiといった従来のストリーミングファーストシステムと並ぶリアルタイムデータ処理のライバルとなるでしょう。
3. マテリアライズドビュー:派生データの簡素化
データレイクは、生の履歴データ(しばしば「ブロンズ」データと呼ばれる)が保存されている場所です。これらのテーブルは膨大で遅く動きますが、実際の価値はその生データから計算された派生データセットにあります。集計、変換、事前計算されたメトリクスなどがそれに該当します。
これまで、Icebergはマテリアライズドビューをサポートしていなかったため、ユーザーは外部システムやカスタムソリューションに頼らざるを得ませんでした。これにより、次の二つの大きな課題が生じました:
- 基本テーブルと派生テーブル間の依存関係を追跡するのが面倒だった。
- 基本テーブルに対する更新があるたびに、派生データの再計算が必要だった。
提案されたマテリアライズドビュー機能(PR #11041)はこれを解決します。マテリアライズドビューでは、事前計算された結果がテーブルとして保存され、Icebergは依存関係を追跡するためのメタデータを処理します。これにより、クエリ性能が向上し、基本テーブルの変更に応じて派生データが自動的に更新されます。
Icebergの拡張
Icebergが進化するにつれて、そのエコシステムも拡大しています。2025年に注目すべきいくつかの分野は次のとおりです:
- 新しいデータ型:タイムゾーン付きのナノ秒精度のタイムスタンプをサポートすることで、金融業界や通信業界など、高精度なデータが重要な業界でIcebergを活用できるようになります。
- バイナリ削除ベクター:Spec V3は、削除処理を効率的かつスケーラブルに行うソリューションを導入します。これは規制環境やGDPR準拠に特に有用です。
- より広範なクエリエンジンサポート:RisingWave、Trino、Dremio、Flinkなどは、Iceberg統合を積極的に強化しています。
Icebergに欠けているものは?
Icebergのエコシステムはすでに強固です。KafkaやPostgresプロトコル(RisingWave経由)を使用してデータを取り込み、さまざまなエンジンでクエリを実行できます。しかし、1つ明白なギャップがあります:軽量なコンパクション。
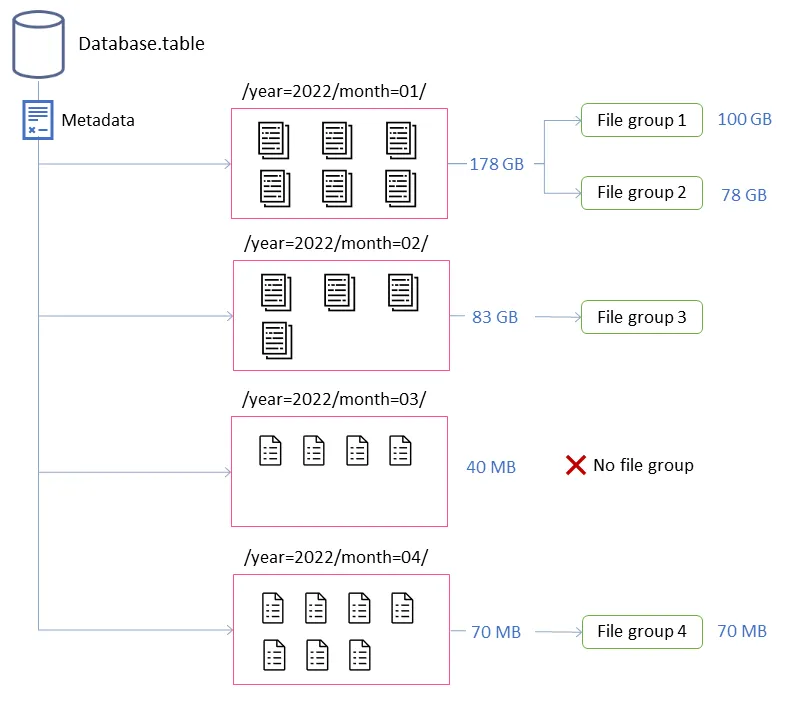
現在、コンパクションは通常、重いSparkジョブに依存していますが、これは小規模なチームやワークロードには過剰です。これにより、Icebergテーブルのコンパクションをより簡単でリソース効率の良い方法で行いたいSQLやPythonユーザーにとって障壁となっています。
良いニュースは、この問題についてコミュニティが認識しており、軽量でエンジン非依存のコンパクションフレームワークの構築に対する関心が高まっていることです。2025年には、Icebergをすべてのユーザーにとってよりアクセスしやすくする解決策が提供されることを期待しています。
未来に向けて
RBACカタログ、ストリーミング機能、マテリアライズドビュー、新しいデータ型のサポートなどの革新により、Apache Icebergはデータエンジニアリングのためのユニバーサルなテーブルフォーマットになる道を歩んでいます。
2024年は、Icebergがフォーマット戦争に勝利することを証明しました。2025年には、その使いやすさと速度、効率性を向上させ、すべてのユーザーにとってさらに優れたものとなるでしょう。リアルタイム分析パイプラインを構築している方も、ペタバイト規模の履歴データを管理している方も、データレイクハウスアーキテクチャの最前線を探求している方も、Icebergには何かが待っています。
データエンジニアリングの未来はすでにここにあります。それはIcebergです。
Discussion