Flinkが複雑すぎる?たった4行のコードで始めるストリーム処理入門チュートリアル
10年前、私は興味深いビッグデータプロジェクト Stratosphere に出会いました。その紹介で特に興味を引かれたのは、「単一マシン上でクラスタを立ち上げ、わずか3行のコードでMapReduceベースのWordCount計算を実行できる」という点でした!Hadoopが支配的だった当時、WordCountプログラムのインストールや実行には数時間から数日かかることも珍しくありませんでした。そんな時代に、同じ機能をたった3行のコードで実現したこのプロジェクトは、私に強烈な印象を与えました。このシンプルで強力なアプローチに惹かれ、私はこのプロジェクトを深く掘り下げ、最終的にはコントリビューターになりました。
現在、かつてStratosphereとして知られていたプロジェクトは進化を遂げ、Apache Flinkという名前で、ビッグデータ分野で最も人気のあるストリーム処理エンジンとして君臨しています。しかし、初期のStratosphereとは異なり、Flinkは非常に巨大かつ複雑なプロジェクトに成長しました。それでもなお、Flinkのストリーム処理エンジンの初期設計や開発に携わった身として、私はシンプルさを重視したユーザー体験を今でも追い求めています。ユーザーが素早くストリーム処理の世界に足を踏み入れ、その卓越した効率を体感してほしい——それが私の願いです。
こうした信念をもとに、私と私のチームは、クラウドベースのストリーミングデータベース RisingWave を開発しました。RisingWaveはPostgreSQLライクな使用感を持つ高性能な分散ストリーム処理環境を提供します。本記事では、RisingWaveを使ってわずか4行のコードでストリーム処理を始める方法を紹介します。
ストリーム処理とは?
注:すでにストリーム処理に精通している方は、このセクションを飛ばしていただいて構いません。
データ処理には、バッチ処理とストリーム処理という2つの基本モードがあります。過去20年間で、バッチ処理システムもストリーム処理システムも急速な進化を遂げ、単一マシンから分散システムへ、そしてビッグデータ時代からクラウドコンピューティング時代へと移り変わってきました。また、両者のアーキテクチャにも大幅な改善が施されています。

バッチ処理とストリーム処理の主な違いは以下の2点です:
- バッチ処理システムはユーザーが開始する計算に依存しているのに対し、ストリーム処理システムはイベント駆動型の計算を行います。
- バッチ処理システムは全量計算モデルを用いるのに対し、ストリーム処理システムはインクリメンタル計算モデルを採用しています。
バッチ処理もストリーム処理も、どちらもリアルタイム性を重視する方向へ進んでいます。現在、バッチ処理システムは主にインタラクティブ分析シナリオで、ストリーム処理システムはモニタリング、アラート、オートメーションなど多様なシナリオで広く使われています。

RisingWave:PostgreSQL体験で行うストリーム処理
RisingWave は Apache 2.0ライセンスで公開されているオープンソースの分散型SQLストリーミングデータベースです。PostgreSQL互換のインターフェースを採用しており、ユーザーはPostgreSQLデータベースを操作するのと同様に、分散型ストリーム処理を行えます。
RisingWaveは主に2つの代表的なユースケース、「ストリーミングETL」と「ストリーミング分析」のために設計されています。
ストリーミングETLとは、各種データソース(OLTPデータベース、メッセージキュー、ファイルシステムなど)から取り込んだデータをリアルタイムで処理(結合、集約、グループ化、ウィンドウ処理など)し、ターゲットとなるシステム(OLAPデータベース、データウェアハウス、データレイク、もしくはOLTPデータベースやメッセージキュー、ファイルシステムへの戻し処理)に送り込む処理を指します。このシナリオでは、RisingWaveはApache Flinkを完全に置き換えることが可能です。
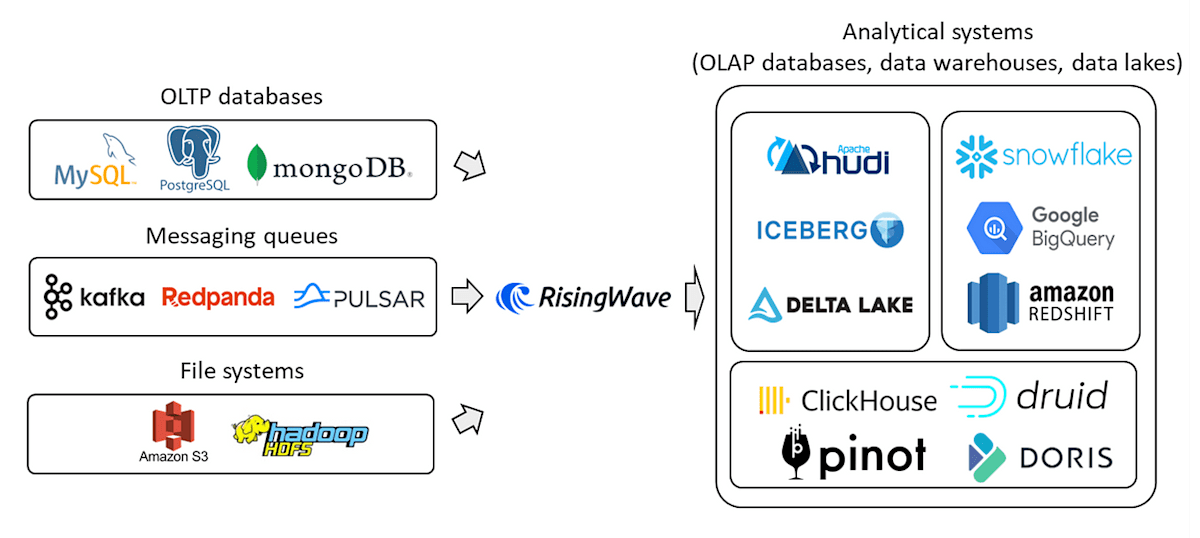
一方、ストリーミング分析とは、複数のデータソース(OLTPデータベース、メッセージキュー、ファイルシステムなど)から取り込んだデータに対して複雑な分析(結合、集約、グループ化、ウィンドウ処理など)を行い、BIダッシュボードに結果を表示する処理能力を指します。ユーザーはまた、異なるプログラミング言語のクライアントライブラリを利用して、RisingWave内のデータに直接アクセスすることも可能です。このシナリオでは、RisingWaveはApache FlinkとSQL/NoSQLデータベース(MySQL、PostgreSQL、Cassandra、Redisなど)の組み合わせを置き換えることができます。

RisingWave を4行のコードでデプロイする
Mac上でRisingWaveをインストールおよび実行するには、コマンドラインで以下の3つのコマンドを順に実行します(Linuxユーザーはこちらを参照してください):
$ brew tap risingwavelabs/risingwave
$ brew install risingwave
$ risingwave playground
次に、新しいコマンドラインウィンドウを開き、以下のコマンドでRisingWaveに接続します:
$ psql -h localhost -p 4566 -d dev -U root
理解しやすくするために、まずテーブルを作成し、INSERTを使ってテストデータを追加してみましょう。現実的なシナリオでは通常、メッセージキューやOLTPデータベースなどからデータを取得する必要があります(これについては後述します)。
まずは、ウェブサイト訪問履歴を記録するテーブルを作成しましょう:
CREATE TABLE website_visits (
timestamp TIMESTAMP,
user_id VARCHAR,
page_id VARCHAR,
action VARCHAR
);
次に、各ページの訪問回数、訪問者数、最終訪問時刻を集計するためのマテリアライズドビューを作成します。なお、ストリーミングデータに基づくマテリアライズドビューはRisingWaveのコア機能の一つです。
CREATE MATERIALIZED VIEW page_visits_mv AS
SELECT page_id,
COUNT(*) AS total_visits,
COUNT(DISTINCT user_id) AS unique_visitors,
MAX(timestamp) AS last_visit_time
FROM website_visits
GROUP BY page_id;
続いて、INSERTを使用してデータを追加します:
INSERT INTO website_visits (timestamp, user_id, page_id, action) VALUES
('2023-06-13T10:00:00Z', 'user1', 'page1', 'view'),
('2023-06-13T10:01:00Z', 'user2', 'page2', 'view'),
('2023-06-13T10:02:00Z', 'user3', 'page3', 'view'),
('2023-06-13T10:03:00Z', 'user4', 'page1', 'view'),
('2023-06-13T10:04:00Z', 'user5', 'page2', 'view');
現在の結果を確認してみましょう:
SELECT * from page_visits_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page2 | 2 | 2 | 2023-06-13 10:04:00
page3 | 1 | 1 | 2023-06-13 10:02:00
page1 | 2 | 2 | 2023-06-13 10:03:00
(3 rows)
次に、さらに5件のデータを追加します:
INSERT INTO website_visits (timestamp, user_id, page_id, action) VALUES
('2023-06-13T10:05:00Z', 'user1', 'page1', 'click'),
('2023-06-13T10:06:00Z', 'user2', 'page2', 'scroll'),
('2023-06-13T10:07:00Z', 'user3', 'page1', 'view'),
('2023-06-13T10:08:00Z', 'user4', 'page2', 'view'),
('2023-06-13T10:09:00Z', 'user5', 'page3', 'view');
データを二度挿入することで、データが継続的に流入する状況をシミュレートしています。もう一度結果を確認してみましょう:
SELECT * FROM page_visits_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page1 | 4 | 3 | 2023-06-13 10:07:00
page2 | 4 | 3 | 2023-06-13 10:08:00
page3 | 2 | 2 | 2023-06-13 10:09:00
(3 rows)
結果が更新されていることが分かります。もしこれがリアルタイムのストリーミングデータ処理であれば、結果は自動的に最新状態が保たれます。
Kafkaとの連携
メッセージキューはストリームデータ処理でよく使用されますので、ここではKafkaからリアルタイムでデータを取得し処理する方法を確認しましょう。
Kafkaをまだインストールしていない場合は、まず公式サイトから適切な圧縮パッケージをダウンロード(ここでは例として3.4.0を使用)し、展開してください:
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
次にKafkaを起動します。
- クラスタUUIDを生成します:
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
- ログディレクトリをフォーマットします:
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
- Kafkaサーバーを起動します:
$ bin/kafka-server-start.sh config/kraft/server.properties
Kafkaサーバーを起動したら、トピックを作成しましょう:
$ bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092
Kafkaが正常に起動すると、コマンドラインから直接メッセージを入力できるようになります。
まず、以下のコマンドを実行してプロデューサプログラムを開始します:
$ bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
「>」の記号が表示されたら、メッセージを入力できます。RisingWaveでデータを消費しやすくするため、データをJSON形式で入力しましょう:
{"timestamp": "2023-06-13T10:05:00Z", "user_id": "user1", "page_id": "page1", "action": "click"}
{"timestamp": "2023-06-13T10:06:00Z", "user_id": "user2", "page_id": "page2", "action": "scroll"}
{"timestamp": "2023-06-13T10:07:00Z", "user_id": "user3", "page_id": "page1", "action": "view"}
{"timestamp": "2023-06-13T10:08:00Z", "user_id": "user4", "page_id": "page2", "action": "view"}
{"timestamp": "2023-06-13T10:09:00Z", "user_id": "user5", "page_id": "page3", "action": "view"}
入力したメッセージを確認するには、コンシューマプログラムを起動します:
$ bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092
では、RisingWaveがこのメッセージキューからどのようにデータを取得するか見てみましょう。このシナリオにおいて、RisingWaveはメッセージコンシューマの役割を担います。psqlのウィンドウに戻り、先ほど作成したトピックとの接続を確立するためのデータソースを作成します。この段階では、まだデータを消費していないことに注意してください。
データソースを作成する際、ストリームデータに含まれるJSONデータの関連フィールドをマッピングするスキーマを直接定義できます。先ほどのテーブルとの競合を避けるため、このデータソースをwebsite_visits_streamと命名します。
CREATE source IF NOT EXISTS website_visits_stream (
timestamp TIMESTAMP,
user_id VARCHAR,
page_id VARCHAR,
action VARCHAR
)
WITH (
connector='kafka',
topic='test',
properties.bootstrap.server='localhost:9092',
scan.startup.mode='earliest'
)
ROW FORMAT JSON;
次に、RisingWaveがデータの取り込みを開始し計算を実行するために、マテリアライズドビューを作成します。理解しやすいように、上記と類似のビューを作成します。
CREATE MATERIALIZED VIEW visits_stream_mv AS
SELECT page_id,
COUNT(*) AS total_visits,
COUNT(DISTINCT user_id) AS unique_visitors,
MAX(timestamp) AS last_visit_time
FROM website_visits_stream
GROUP BY page_id;
ここで結果を確認してみましょう:
SELECT * FROM visits_stream_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page1 | 1 | 1 | 2023-06-13 10:07:00
page2 | 2 | 2 | 2023-06-13 10:08:00
page3 | 1 | 1 | 2023-06-13 10:09:00
(3 rows)
これで、Kafkaからデータを取得し、処理を行うことが成功しました。
高度な応用例:RisingWaveを使ったリアルタイムモニタリングシステムの構築
リアルタイムモニタリングは、ストリーミングアプリケーションにおいて非常に重要な役割を果たしています。データをリアルタイムで処理することで、結果をリアルタイムに可視化し、モニタリングできます。RisingWaveはデータソースとして機能し、SupersetやGrafanaなどの可視化ツールとシームレスに連携して、処理済みメトリクスデータをリアルタイムで表示できます。自分だけのストリーム処理および可視化システム構築に挑戦してみることをお勧めします。具体的な手順については、当社のユースケースドキュメントをご参照ください。このドキュメントでは、RisingWaveを使用してシステム性能メトリクスをモニタリング・処理し、Grafanaを通じてリアルタイムに結果を提示する方法を紹介しています。私たちのデモは比較的シンプルですが、実際のデータや馴染みのある業務シナリオにおいて、より豊かで影響力のある表示効果を実現できると確信しています。

まとめ
RisingWaveの最大の特徴はその驚くべきシンプルさであり、SQLを用いて分散型ストリーム処理を手軽に利用できる点にあります。性能面においても、RisingWaveはApache Flinkのようなビッグデータ時代のストリーム処理プラットフォームを上回ります。
性能向上の規模は非常に注目に値します。詳細を示すと、ステートレスな計算では約10%〜30%の性能向上が見られ、一方ステートフルな計算では驚異的な10倍以上の向上が確認されています!
まもなく公開されるパフォーマンスレポートでは、これらの詳細についてさらに深く掘り下げる予定です。効率的なストリーム処理プラットフォームにとってシンプルさは常に最優先事項であり、RisingWaveはまさにそれを提供し、さらにはそれ以上の価値を届けます。
RisingWaveについて
RisingWaveは、クラウドベースの分散型SQLストリーミングデータベースです。Apache 2.0ライセンスのもと、オープンソースで提供されています。
- 公式ウェブサイト:risingwave.com
- GitHub:risingwave.com/github
- ドキュメント:risingwave.dev
Discussion