ストリーミングデータベース + LLM: 問われる前に行動するプロアクティブエージェントの構築
はじめに
Q&Aエージェントは、ユーザーが質問したときにのみ応答を生成する。この仕組みは機能するのか? もちろん機能する。LLMはすでに私の生活の一部になっている。例えば、未知の国へ行く際に必要な情報をすべて教えてくれたり、プレゼンテーションの向上を手助けしてくれたりする。しかし、これらの「魔法」は、私がLLMに適切な質問をし、現在の状況を正確に説明したときにのみ発生する。では、指示なしに適切な行動を取ることができるプロアクティブなエージェントを実装することは可能だろうか?
これを実現するには、エージェントがリアルタイムで何が起こっているのかを把握する必要がある。毎瞬、無数のイベントが発生している。エージェントには環境の変化を監視するための「目」と「耳」が必要であり、それによって、私たちが適切な質問や正確な状況説明を思いつく前に、何かが起こったときに行動を取ることができるようになる。
プロアクティブエージェント
プロアクティブエージェントの例を見てみよう。
🤔: 月間売上が過去最高を更新したらメールを送信する。
🤔: 自宅に近づいたらエアコンをオンにする。
🤔: リターンが3%以上になったらTSLA株の40%を売却する。
ほとんどのLLMは、あなたの代わりにメールを送信することができる。また、Home AssistantのAPIにアクセスできれば、エアコンをオンにすることも可能だ。さらに、あなたが許可すればTSLA株を売却することもできる。しかし、これらの動作は、ユーザーが明示的に指示したときにのみ実行される。リターン率が3%を超えたときに自動で株を売却したり、自宅に近づいたらエアコンを自動でオンにしたりすることはできない。
もちろん、優秀な開発者にこれらの機能を実装してもらうことは可能だ。しかし、もし「別の条件を満たしたら株を売却する」という要件が発生したらどうするだろうか? あるいは、「LLMがすべてのイベントを処理できるようにする」ことは可能なのだろうか?
現時点では、LLMがすべてのイベントを処理することは不可能だ。なぜなら、それは非効率的であり、動作が遅く、高コストだからである。さらに、毎秒何千、何百万ものイベントが発生する可能性があるため、LLM単体でこれらを処理するのは現実的ではない。そこで、LLMに「イベントリスナー」を作成させることが必要になる。
アーキテクチャ
朝7時に起きたいとき、5分ごとに時計をチェックする必要はあるだろうか? そんなことはしない。ただ目覚ましをセットするだけだ。そして、時間になったら目覚ましがブザーを鳴らして起こしてくれる。この場合、「イベント」は「時刻」であり、「興味のあるイベント」は「7:00 AMになった」という事象である。同様に、LLMもイベントリスナーをセットし、興味のあるイベントが発生したときにトリガーされるようにすればよい。

上の図は、イベント駆動型エージェントのデータフローを示している。ストリーミングデータベースを活用することで、イベント駆動型エージェントを構築できる。ストリーミングデータベースは、イベントの保存、処理、変換を行い、ユーザーがデータをクエリできるようにする。
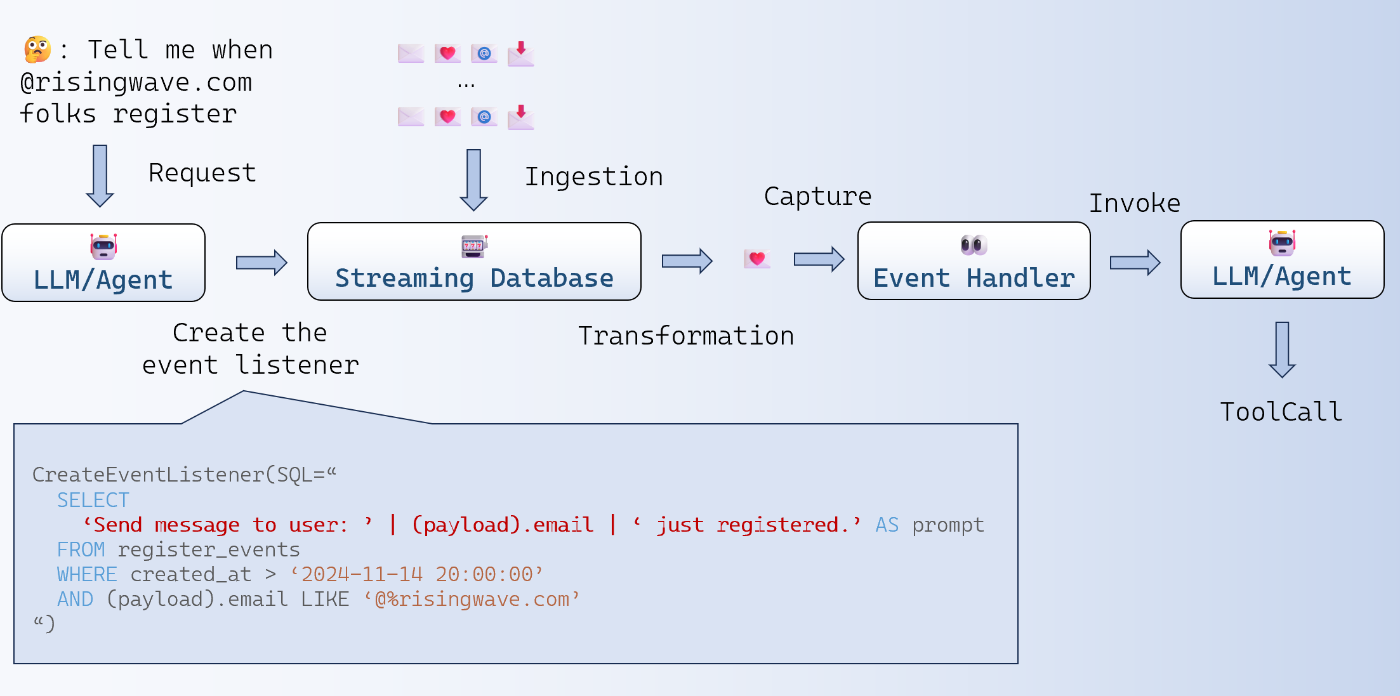
まず、ユーザーは監視したいイベントを指定する。例えば、「@risingwave.comのドメインを持つユーザーが登録したら通知してほしい」と指示するとしよう。この場合、ユーザーのエージェントはウェブサイト管理を担当している。そして、エージェントは新規登録者を特定できるデータにアクセスできる。たとえば、バックエンドのログや、USERテーブルへのINSERTステートメントが該当する。
このイベントデータは次のような形式で記録されるとする:
{"id": "x7cj7Hjis52-H", "payload": {"email": "peter.shen@example.com"}, "timestamp": "2024-11-14T06:00:00"}
{"id": "gdgs+52djKFO", "payload": {"email": "john.doe@example.com"}, "timestamp": "2024-11-14T07:00:00"}
{"id": "289ghnwNFoiu9dK", "payload": {"email": "mike.wang@risingwave.com"}, "timestamp": "2024-11-14T08:00:00"}
......
これらのイベントはすべてストリーミングデータベースに取り込まれる。そして、LLMはストリーミングデータベース内で特定のルールを作成し、条件に合致するイベントが発生したときに通知を受ける。通知を受け取ると、イベントハンドラーがLLMを呼び出し、イベントとコンテキストを含むプロンプトを生成する。
例えば、以下のようなプロンプトを作成できる:
ユーザーにメッセージを送信: mike.wang@risingwave.com が新規登録しました。
その後、LLMはツールを呼び出し、このイベントをユーザーに通知する。
SQLクエリの例
以下のSQLクエリを見てみよう:
SELECT
'Send message to user: ' || (payload).email || ' just registered.' AS prompt
FROM register_events
WHERE created_at > '2024-11-14 20:00:00'
AND (payload).email LIKE '@%risingwave.com'
このSQLクエリは、次のような処理を行う:
-
created_at > '2024-11-14 20:00:00'により、過去のイベントを除外し、現在以降の@risingwave.comの登録者のみを対象とする。 -
payload.email LIKE '@%risingwave.com'により、登録者のメールアドレスがrisingwave.comで終わるものだけを抽出する。 - 取得した登録イベントをプロンプトの形式に変換し、LLMのトリガーに利用する。
これはプロアクティブエージェントの「目」と「耳」の役割を果たす。
「このSQLはどのようにしてイベントをフィルタリングし、LLMを呼び出せるのか?」と疑問に思うかもしれない。答えは、このSQLがマテリアライズドビューの作成に使用されることにある。完全なSQL文は次のようになる:
CREATE MATERIALIZED VIEW event_listener_risingwavecom_register AS
SELECT ... FROM ...
マテリアライズドビューは、クエリの最新の結果を保存する。これに対してクエリを実行することもできるし、新たなマテリアライズドビューを作成することも可能である:
SELECT * FROM event_listener_risingwavecom_register;
ストリーミングデータベースにおいて、マテリアライズドビューは上流のデータが更新されると自動かつ増分的に更新される。そのため、新規登録イベントがregister_eventsテーブルに挿入されると、ストリーミングデータベースはこの挿入イベントをSQLで定義されたルールに基づいて処理する。そして、新しく挿入された行のemailが「@risingwave.com」で終わる場合、そのイベントはマテリアライズドビューに挿入される。このマテリアライズドビューの更新自体も1つの「イベント」であり、RisingWaveはパブリッシュ/サブスクライブ機構を提供することで、ビューの更新時に下流のシステムへ通知を送信できる。
なぜストリーミングデータベースなのか
ストリーミングデータベースこそが、この仕組みの中心となる要素である。ストリーミングデータベースには、ストリーム処理エンジン、データストレージ、データ提供機能、SQLインターフェースといった、イベント駆動型エージェントを構築するのに必要な要素がすべて揃っている。
ストリーム処理エンジンは数多く存在するが、SQLインターフェースを持つものを利用すれば、イベント駆動型エージェントの開発にかかる時間を大幅に短縮できる。RisingWaveは、そのような要件を満たす優れた選択肢の1つである。
SQLインターフェースの重要性
SQLは、計算手順を記述するのではなく、「求める結果」を宣言的に記述するための言語である。データベースは、SQLクエリを解析し、最適化された計算グラフを自動生成する。たとえば、売上データから金額の上位10件を取得する場合、以下のようにSQLを記述すればよい:
SELECT * FROM sales_global ORDER BY amount_usd LIMIT 10;
また、MATERIALIZED VIEW を使用すれば、このクエリの最新の結果を常に維持できる:
CREATE MATERIALIZED VIEW top_10_sales AS
SELECT * FROM sales_global ORDER BY amount_usd LIMIT 10;
このマテリアライズドビューに対してクエリを実行すれば、常に最新の上位10件の売上データを取得できる:
SELECT * FROM top_10_sales;
さらに、マテリアライズドビューは、上流データが更新されるたびに増分的に更新されるため、計算のオーバーヘッドが大幅に削減される。
では、「LLMにPythonコードを書かせて同じ処理を実装する」ことは可能だろうか? 確かに可能ではあるが、Pythonコードでこの処理を実装する場合、LLMは正しい計算手順を記述する必要がある。たとえば、この場合、LLMは「増分更新可能な分散Top-Kアルゴリズム」を実装する必要がある。しかし、これは高度なストリーム処理と分散システムの知識を必要とし、適切なプロンプトエンジニアリングが求められる。
一方、SQLを使えば、LLMは「求める結果」を簡潔に記述するだけで済む。そのため、以下のような利点がある:
- LLMの思考ステップを減らせる
- プロンプトエンジニアリングの負担が軽減される
- ストリーム処理に関する専門知識が不要になる
- コストを削減できる
入出力の統合
RisingWaveはPostgreSQL互換であるため、PostgreSQLエコシステムとシームレスに統合できる。たとえば、psql、dbt、または各種プログラミング言語のPostgreSQLクライアントライブラリを使用してアクセス可能である。
これにより、RisingWaveは次のような用途で利用できる:
- GrafanaのPostgreSQLデータソースとして使用
- PostgreSQLのFDW(Foreign Data Wrapper)として外部データベースと連携
- 外部データストアからのデータ取得(
CREATE SOURCE) - 外部データストアへのデータ出力(
CREATE SINK)
たとえば、Kafka、MySQL、ClickHouse、Icebergテーブルなどの外部ストレージと連携できる。
本記事で紹介したユースケースでは、データをストリーミングデータベースにINSERTし、更新があった際にサブスクリプション機能を使ってイベントハンドラーへ通知を送る仕組みを利用する。
ストリーミング結合(Streaming Joins)
RisingWaveは、ストリーミングジョインを活用したイベント駆動型アプリケーションにも適している。これは、従来のカラムナーストレージデータベースでは効率的に処理できないケースである。
たとえば、国際企業を経営しているとしよう。あなたは中国・北京にある本社で、リアルタイムの売上高(CNY換算)を監視したいと考えている。この場合、データベースには次の2つのテーブルがあるとする:
-
sales_global: 売上トランザクションの記録 -
exchange_rate: 特定の時点における最新の為替レート

売上は世界中で発生するため、さまざまな通貨で決済される。したがって、売上金額を集計する前に、各トランザクションの金額を、その時点での最新の為替レートを使用してCNYに変換する必要がある。
たとえば、「2024-11-05T07:00:00, 10 USD」の売上記録をCNYに変換するには、次の条件を満たすexchange_rateのレコードを取得しなければならない:
current_from = 'USD'current_to = 'CNY'-
ts(タイムスタンプ)が2024-11-05T07:00:00以下で、かつ最大値であること
このようなストリーミングジョインは、通常のカラムナーストレージデータベースでは効率的に処理できない。しかし、RisingWaveのようなストリーム処理向けデータベースでは、リアルタイムでのデータ処理が可能であり、大量のディメンションテーブルを活用するような複雑なユースケースにも対応できる。
デモ
LLMがストリーミングデータベースを活用してイベントを監視する仕組みを理解するために、デモを作成した。詳細は以下のリポジトリを参照してほしい:https://github.com/cloudcarver/event-driven-agent-demo

Discussion