〰️
Xinference と連携して埋め込みモデルを読み込む
この記事では、DifyとXinferenceを使用してローカル環境でRAG(Retrieval-Augmented Generation)システムを構築するための設定手順を備忘録として記録します。
参考
Xinference とは
Xinferenceは、言語、音声認識、マルチモーダルモデルを提供するためのPythonライブラリです。Dockerを用いることで実行環境として活用でき、DifyやFastGPT、RAG Flowとも連携可能です。
セットアップ
Difyのdocker-compose.yaml設定
Dify起動時にXinferenceも自動で立ち上がるように、Difyのdocker-compose.yamlに以下を追加します。
xinference:
image: xprobe/xinference
container_name: xinference
ports:
- 9997:9997
volumes:
- $HOME/.xinference:/root/.xinference
- $HOME/.cache/huggingface:/root/.cache/huggingface
- $HOME/.cache/modelscope:/root/.cache/modelscope
command: "xinference-local -H 0.0.0.0"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
Xinference 側の設定
Dify起動後、http://localhost:9997/にアクセスします。アクセスに成功すると、Xinferenceのホーム画面が表示されます。
今回は、Embedding Modelの「bge-m3」をDifyで使用するための設定を行います。以下の手順でモデルを設定します。
- Launch Model → EMBEDDING MODELS → bge-m3 の順に選択。
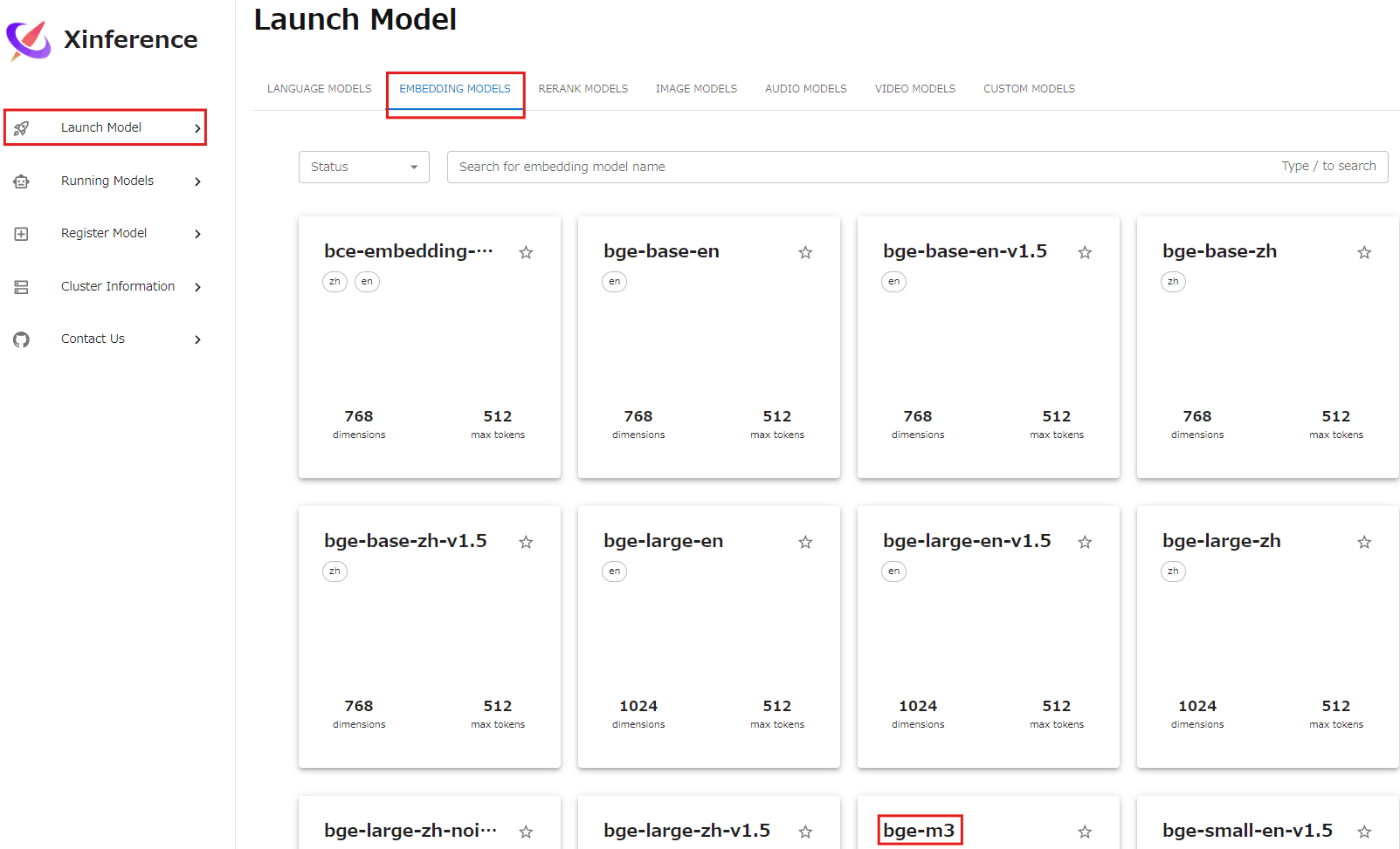
- モデル設定画面に進み、以下の項目を確認または設定します。
- Model UID, model name:表示されている「bge-m3」のままで問題ありません。モデルの識別子です。
- Replica:1のままで問題ありません。モデルのレプリカ数です。
- Device:通常、GPUを使用することで高速な処理が可能です。選択されているGPUで問題ありません。
- GPU Idx:複数GPUがある場合は使用するGPU番号を指定します。1台の場合は空欄で問題ありません。
- Worker Ip:単独マシンでの実行なら空欄のままで問題ありません。分散システム用の設定です。
- Download hub:「huggingface」が選択されていますが、これで問題ありません。
- Model Path:Hugging Faceからダウンロードする場合、空欄のままで問題ありません。
- 設定を確認後、ページ下部のロケットボタンをクリックし、モデルをダウンロードします。ダウンロード成功後、「Running Models」の「EMBEDDING MODELS」にbge-m3が追加されていれば完了です。

Dify 側の設定
Difyにログインし、設定画面で「モデルプロバイダー」を選択して「Xorbits Inference」をクリックします。

その後、次の項目を入力します。
- Mode Type: Text Embedding
- Model Name: bge-3
- Server URL: http://xinference:9997/
- Model UID: bge-3
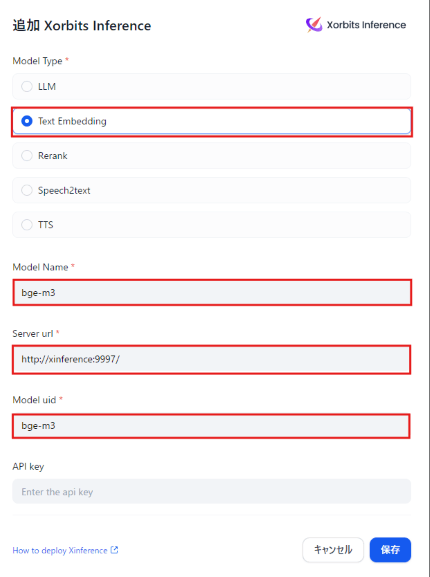
設定を保存すると、モデルプロバイダー画面上部にXorbits Inferenceが表示され、bge-m3が選択可能になっていれば接続は成功です。
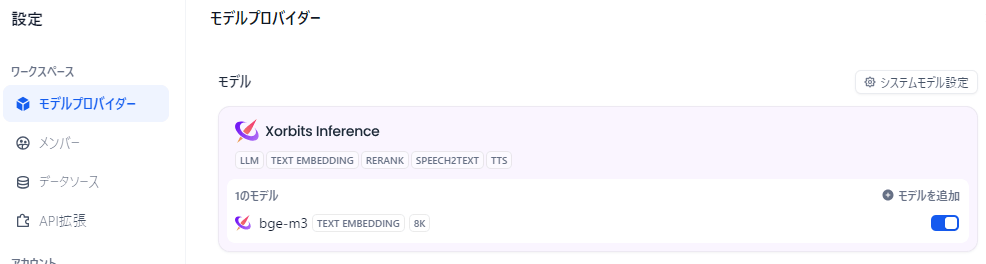
以上で、DifyとXinferenceの連携設定は完了です。
Discussion