ArangoDBのAQLでJOINしてみよう
AQLとは
The ArangoDB Query Languageのことです。ざっくり言えばSQLのArangoDB版です。
AQLでできること
SQLでの基本的な操作(SELECT UPDATE INSERT DELETE)はできます。JOINもできます。
AQLとSQL比較表を見るとわかりやすい
AQLを試す
データに関して
usersとrelationsを使います
AQL実行方法
ArangoDB Web UIでQUERIESをクリックするとAQL実行できるUIになります。

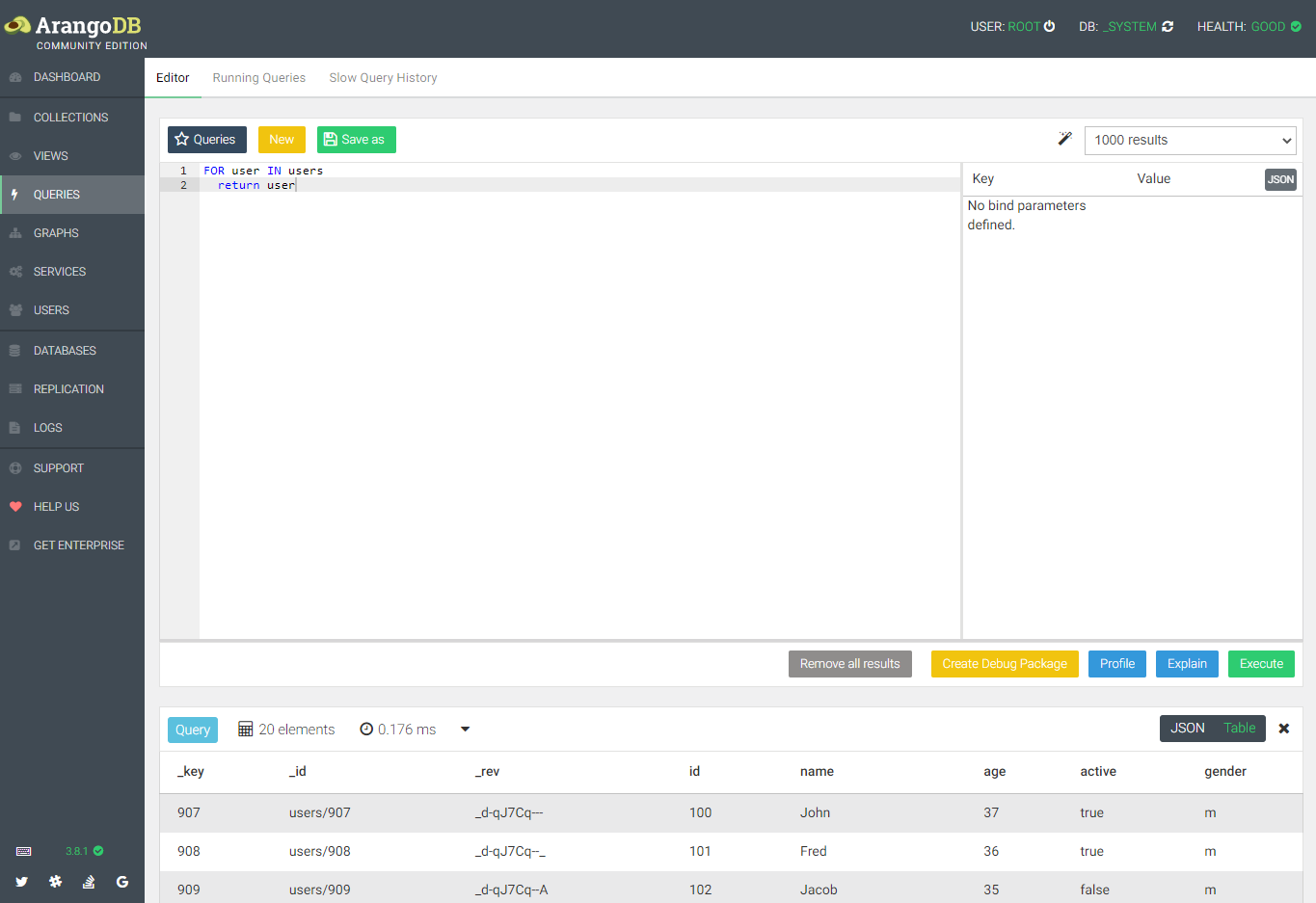
SQLで言うところのSELECTをしてみる
FOR user IN users
return user
と記載してExecuteをクリックするとAQLが実行されて結果が下に出てくる
SQLで言うところのJOINをしてみる
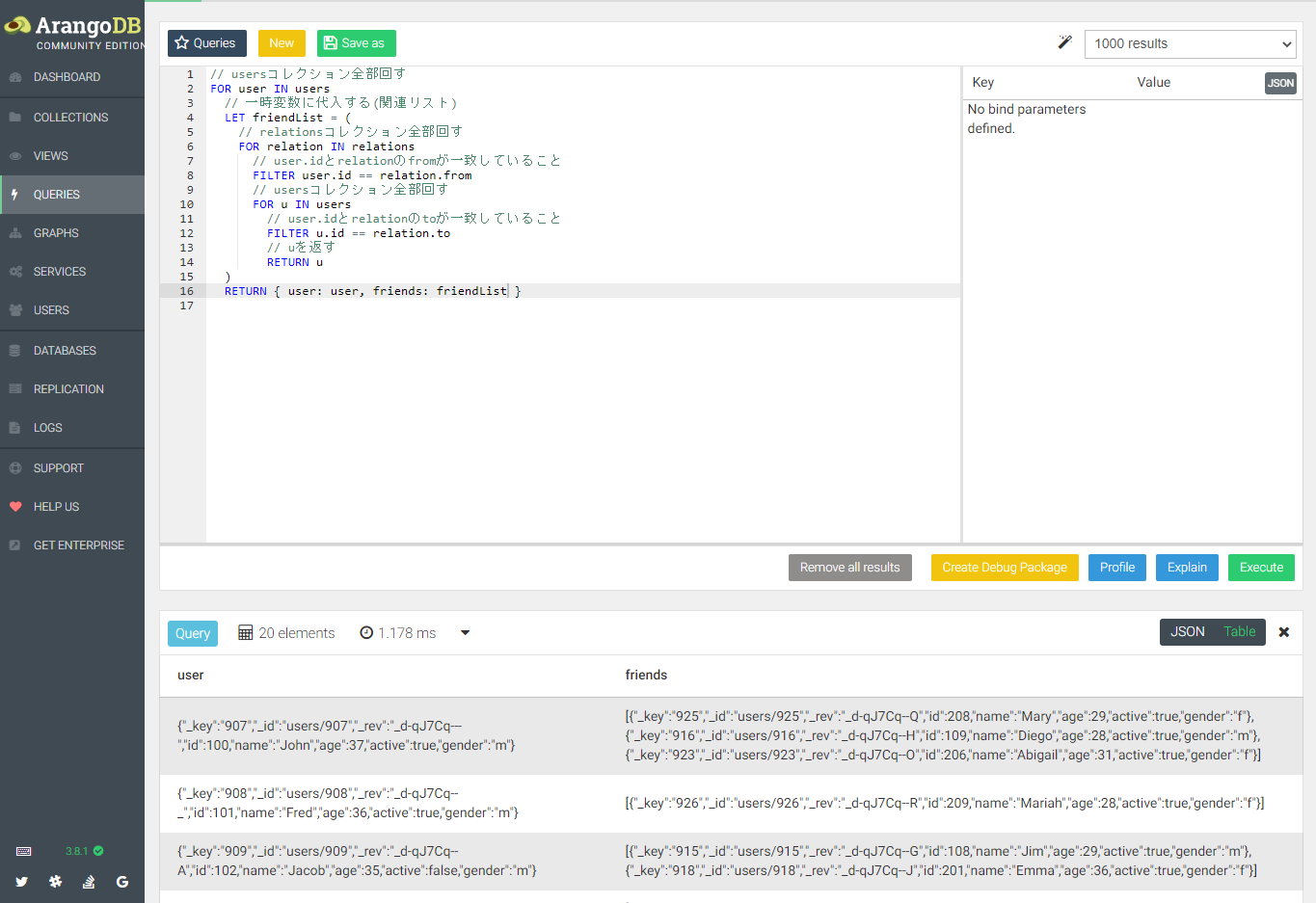
全ユーザーの友達リストを出力するのを試す
// usersコレクション全部回す
FOR user IN users
// 一時変数に代入する(友達リスト)
LET friendList = (
// relationsコレクション全部回す
FOR relation IN relations
// user.idとrelationのfromが一致していること
FILTER user.id == relation.from
// usersコレクション全部回す
FOR u IN users
// user.idとrelationのtoが一致していること
FILTER u.id == relation.to
// uを返す
RETURN u
)
// userとfriendListを返す
RETURN { user: user, friends: friendList }
問題点
Explainした結果
Query String (442 chars, cacheable: true):
// usersコレクション全部回す
FOR user IN users
// 一時変数に代入する(友達リスト)
LET friendList = (
// relationsコレクション全部回す
FOR relation IN relations
// user.idとrelationのfromが一致していること
FILTER user.id == relation.from
// usersコレクション全部回す
FOR u IN users
// user.idとrelationのtoが一致していること
FILTER u.id == relation.to
// uを返す
RETURN u
)
// userとfriendListを返す
RETURN { user: user, friends: friendList }
Execution plan:
Id NodeType Est. Comment
1 SingletonNode 1 * ROOT
2 EnumerateCollectionNode 20 - FOR user IN users /* full collection scan */
14 SubqueryStartNode 20 - LET friendList = ( /* subquery begin */
4 EnumerateCollectionNode 800 - FOR relation IN relations /* full collection scan, projections: `from`, `to` */
5 CalculationNode 800 - LET #6 = (user.`id` == relation.`from`) /* simple expression */ /* collections used: user : users, relation : relations */
6 FilterNode 800 - FILTER #6
7 EnumerateCollectionNode 16000 - FOR u IN users /* full collection scan */
8 CalculationNode 16000 - LET #8 = (u.`id` == relation.`to`) /* simple expression */ /* collections used: u : users, relation : relations */
9 FilterNode 16000 - FILTER #8
15 SubqueryEndNode 20 - RETURN u ) /* subquery end */
12 CalculationNode 20 - LET #10 = { "user" : user, "friends" : friendList } /* simple expression */ /* collections used: user : users */
13 ReturnNode 20 - RETURN #10
Indexes used:
none
Optimization rules applied:
Id RuleName
1 reduce-extraction-to-projection
2 splice-subqueries
Optimization rules with highest execution times:
RuleName Duration [s]
use-indexes 0.00003
reduce-extraction-to-projection 0.00001
splice-subqueries 0.00001
remove-redundant-calculations 0.00000
inline-subqueries 0.00000
41 rule(s) executed, 1 plan(s) created
インデックス貼ってないので当然だけどフルスキャンしまくる
インデックスを貼る
COLLECTIONのusersに行く
左上の方にIndexesがあるのでクリック
左下に+(緑丸の中に+)があるのでクリック
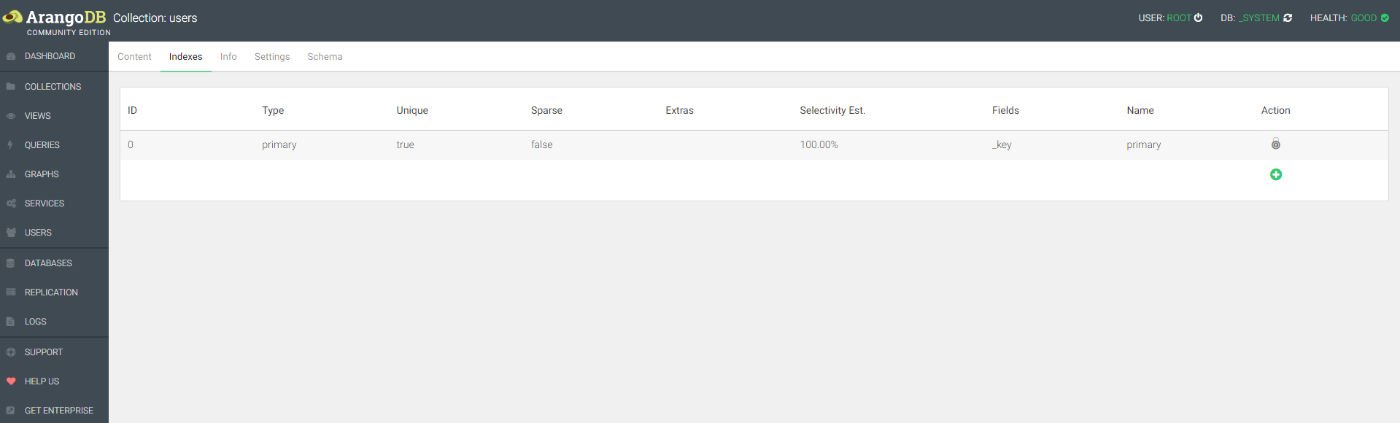
このような設定をする(TypeがPersistent IndexでFieldsがidでNameは適当)
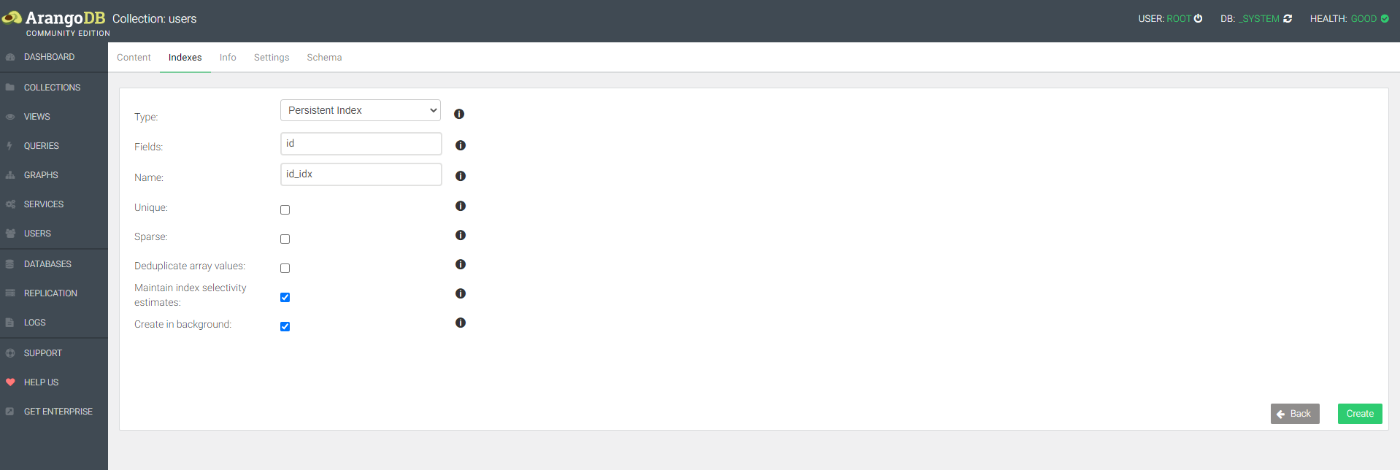
Nameで指定した名前でインデックス作成された
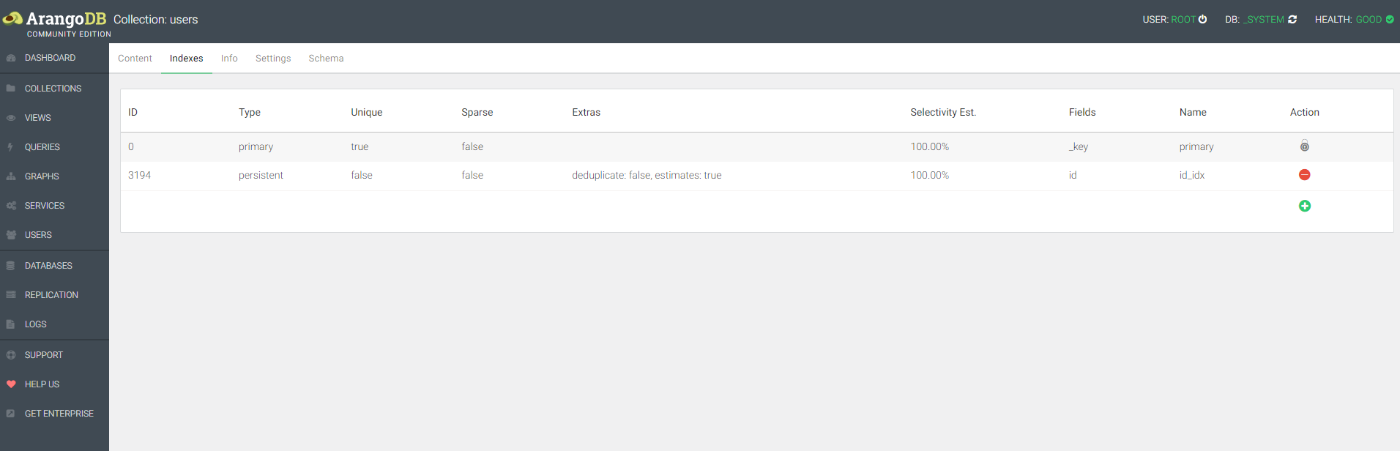
再度Explainする
Query String (442 chars, cacheable: true):
// usersコレクション全部回す
FOR user IN users
// 一時変数に代入する(友達リスト)
LET friendList = (
// relationsコレクション全部回す
FOR relation IN relations
// user.idとrelationのfromが一致していること
FILTER user.id == relation.from
// usersコレクション全部回す
FOR u IN users
// user.idとrelationのtoが一致していること
FILTER u.id == relation.to
// uを返す
RETURN u
)
// userとfriendListを返す
RETURN { user: user, friends: friendList }
Execution plan:
Id NodeType Est. Comment
1 SingletonNode 1 * ROOT
2 EnumerateCollectionNode 20 - FOR user IN users /* full collection scan */
15 SubqueryStartNode 20 - LET friendList = ( /* subquery begin */
4 EnumerateCollectionNode 800 - FOR relation IN relations /* full collection scan, projections: `from`, `to` */
5 CalculationNode 800 - LET #6 = (user.`id` == relation.`from`) /* simple expression */ /* collections used: user : users, relation : relations */
6 FilterNode 800 - FILTER #6
14 IndexNode 800 - FOR u IN users /* persistent index scan */
16 SubqueryEndNode 20 - RETURN u ) /* subquery end */
12 CalculationNode 20 - LET #10 = { "user" : user, "friends" : friendList } /* simple expression */ /* collections used: user : users */
13 ReturnNode 20 - RETURN #10
Indexes used:
By Name Type Collection Unique Sparse Selectivity Fields Ranges
14 id_idx persistent users false false 100.00 % [ `id` ] (u.`id` == relation.`to`)
Optimization rules applied:
Id RuleName
1 use-indexes
2 remove-filter-covered-by-index
3 remove-unnecessary-calculations-2
4 reduce-extraction-to-projection
5 splice-subqueries
Optimization rules with highest execution times:
RuleName Duration [s]
use-indexes 0.00004
reduce-extraction-to-projection 0.00001
splice-subqueries 0.00001
remove-filter-covered-by-index 0.00001
remove-unnecessary-calculations-2 0.00000
42 rule(s) executed, 1 plan(s) created
Est.が減ってるのがわかる&Indexes usedで使われてるのがわかる
更にrelationsにもやってのExplain
relationsのfromにもインデックス貼っての結果
Query String (442 chars, cacheable: true):
// usersコレクション全部回す
FOR user IN users
// 一時変数に代入する(友達リスト)
LET friendList = (
// relationsコレクション全部回す
FOR relation IN relations
// user.idとrelationのfromが一致していること
FILTER user.id == relation.from
// usersコレクション全部回す
FOR u IN users
// user.idとrelationのtoが一致していること
FILTER u.id == relation.to
// uを返す
RETURN u
)
// userとfriendListを返す
RETURN { user: user, friends: friendList }
Execution plan:
Id NodeType Est. Comment
1 SingletonNode 1 * ROOT
2 EnumerateCollectionNode 20 - FOR user IN users /* full collection scan */
16 SubqueryStartNode 20 - LET friendList = ( /* subquery begin */
15 IndexNode 40 - FOR relation IN relations /* persistent index scan, projections: `to` */
14 IndexNode 40 - FOR u IN users /* persistent index scan */
17 SubqueryEndNode 20 - RETURN u ) /* subquery end */
12 CalculationNode 20 - LET #10 = { "user" : user, "friends" : friendList } /* simple expression */ /* collections used: user : users */
13 ReturnNode 20 - RETURN #10
Indexes used:
By Name Type Collection Unique Sparse Selectivity Fields Ranges
15 from_idx persistent relations false false 50.00 % [ `from` ] (user.`id` == relation.`from`)
14 id_idx persistent users false false 100.00 % [ `id` ] (u.`id` == relation.`to`)
Optimization rules applied:
Id RuleName
1 use-indexes
2 remove-filter-covered-by-index
3 remove-unnecessary-calculations-2
4 reduce-extraction-to-projection
5 splice-subqueries
Optimization rules with highest execution times:
RuleName Duration [s]
use-indexes 0.00005
remove-filter-covered-by-index 0.00001
reduce-extraction-to-projection 0.00001
splice-subqueries 0.00001
remove-unnecessary-calculations-2 0.00000
42 rule(s) executed, 1 plan(s) created
Est.が更に減る&インデックスも2つ使われてるのがわかる
インデックス貼るときにおいてのメモリに関して
ArangoDB3出た当時はMMFilesだったのでデータ増えれば増えるほどメモリ使いまくってメモリ容量越えるとエラーで落ちてたんですが、ArangoDB3.2からRocksDBが追加されて、ArangoDB3.4からRocksDBがデフォルトになり、ArangoDB3.6でMMFilesは非推奨となりArangoDB3.7でMMFiles関連は削除されました。RocksDBのメリットはメモリあまり気にしなくて良くなった(メモリ量からディスク容量に変化)。起動もMMFilesだとArangoDB起動時に再構築しないといけないのがしなくて良くなったりと安心。
Discussion