【Unity】実践!Compute Shaderを最適化してみよう
Compute Shader
GPUで汎用的な並列計算をさせたい際に使えるのがCompute Shaderです。通常の頂点シェーダーやフラグメントシェーダーとは異なり、Compute ShaderはGPUにおけるレンダリングパイプラインから独立しているため、より柔軟でオーバーヘッドの少ない処理を行うことができます。
Compute Shaderを使うからにはやはり大規模な並列計算を高速に行いたい、という場合が多いと思います。しかし、ハードウェアの性能をフルに活用するためには、ハードウェアの特性を理解してプログラミングを行う必要があります。
今回はUnity上で画面をぼかすポストエフェクトを例にとって、ステップバイステップで様々な最適化テクニックを試しながらGPUへの理解を深めていこうと思います。
最初の実装
こちらの記事にあるガウシアンブラーの実装(フラグメントシェーダー)をお借りし、Compute Shaderに移植していきます。
ガウシアンブラーは正方形サイズのフィルタにガウス関数で重みづけして平均を取り、畳み込むことで画面をぼかすことができるアルゴリズムです。しかし、上の記事にも記載されていますが、横方向ブラーと縦方向ブラーの2回にパスを分割することで、ほとんど同じ結果を格段に少ない計算量で得ることができます。
まずはこれを素直にCompute Shaderに移植してみましょう。
使用する環境は次の通りです。
- Unity 2022.1.8f1
- URP 14.0.6
- NVIDIA GeForce RTX 2070 SUPER
まずはCompute Shader本体です。
/*
* Blur.compute
*
* 1パスで線形ブラーを1回行う
* 1ラインを1スレッドグループで担当し、ライン数だけdispatchする
* 入力に対して常に横方向のブラーをかけるが、処理結果は入力に対して転置されるため、そのまま結果をもう一度入力することで縦横ブラーが完了する
*/
#pragma kernel CSMain
#pragma enable_d3d11_debug_symbols
RWTexture2D<float4> Source;
RWTexture2D<float4> Dest;
float _Sigma;
float _Radius;
uint _Length;
// numthreadsに指定できる最大値
#define NUM_THREADS 1024
[numthreads(NUM_THREADS,1,1)]
void CSMain(uint ti: SV_GroupIndex, uint3 gid: SV_GroupID)
{
// ぼかしで使用する値の定数部分を事前に計算して全体の計算量を削減する
const float s0 = 1.0 / (2.5066283 * _Sigma);
const float s1 = 2.0 * _Sigma * _Sigma;
const float invRadius = _Radius > 0 ? (1.0 / _Radius) : 0;
const uint repeat = ceil((float)_Length / NUM_THREADS);
// 1ラインのサイズがスレッドグループサイズを超える場合は、1スレッドが2ピクセル以上を担当する
for (int r = 0; r < repeat; r++)
{
// 重みの合計
float w_sum = 0.0;
// 画素値の合計
float4 c_sum = (0.0).xxxx;
// 中央ピクセル位置
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
// 近傍ピクセルの処理
for (int s = -_Radius; s < _Radius; s++)
{
// ピクセル位置
int p = clamp((int)index_r + s, 0.0, _Length - 1);
// ガウス関数のサンプル位置を正規化
const float d = abs(invRadius * s);
// ガウス関数で重み
float w = s0 * exp(-(d * d) / s1) * step(d, 1);
float4 c = Source[uint2(p, gid.x)] * w;
w_sum += w;
c_sum += c;
}
// 画素値の合計を重みの合計で割る
Dest[uint2(gid.x, index_r)] = c_sum / w_sum;
}
}
次に、URPでポストエフェクトを適用するためにRenderer Featureを作成します。
using UnityEngine;
using UnityEngine.Rendering;
using UnityEngine.Rendering.Universal;
public sealed class BlurFeature : ScriptableRendererFeature
{
[SerializeField] private ComputeShader blurShader = default;
[SerializeField, Range(0f, 64f)] private float radius = 0f;
[SerializeField, Range(float.Epsilon, 1f)]
private float sigma = 0f;
private BlurPass pass = default;
private static readonly int Radius = Shader.PropertyToID("_Radius");
private static readonly int Sigma = Shader.PropertyToID("_Sigma");
private static readonly int Length = Shader.PropertyToID("_Length");
class BlurPass : ScriptableRenderPass
{
private const string Tag = nameof(BlurPass);
private const int KernelIndex = 0;
private ComputeShader blurShader = default;
private float radius = default;
private RTHandle buffer0 = default;
private RTHandle buffer1 = default;
public BlurPass(ComputeShader blurShader)
{
this.blurShader = blurShader;
}
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
var cmd = CommandBufferPool.Get(Tag);
try
{
var renderer = renderingData.cameraData.renderer;
var cameraDesc = renderingData.cameraData.cameraTargetDescriptor;
var desc = new RenderTextureDescriptor(
cameraDesc.width,
cameraDesc.height,
RenderTextureFormat.ARGB32
);
//Compute Shaderで参照するテクスチャはenableRandomWriteをオンにする
desc.enableRandomWrite = true;
int width = desc.width;
int height = desc.height;
//フルHDを基準としてぼかし半径を調整
float effectiveRadius = height / 1080f * radius;
//一時バッファを確保
RenderingUtils.ReAllocateIfNeeded(ref buffer0, desc);
//転置
desc.width = height;
desc.height = width;
RenderingUtils.ReAllocateIfNeeded(ref buffer1, desc);
//たまに中身が空のcameraColorHandleが渡されてバグるようなのでここで弾く
if (renderer.cameraColorTargetHandle == null || renderer.cameraColorTargetHandle.rt == null) return;
//画面をbuffer0にコピー
Blitter.BlitCameraTexture(cmd, renderer.cameraColorTargetHandle, buffer0);
if (effectiveRadius > 0)
{
//各パラメータのセット
cmd.SetComputeFloatParam(blurShader, Radius, effectiveRadius);
//横方向(buffer0 => buffer1)
{
cmd.SetComputeIntParam(blurShader, Length, width);
cmd.SetComputeTextureParam(blurShader, KernelIndex, "Source", buffer0);
cmd.SetComputeTextureParam(blurShader, KernelIndex, "Dest", buffer1);
cmd.DispatchCompute(blurShader, KernelIndex, height, 1, 1);
}
//縦方向(buffer1 => buffer0)
{
cmd.SetComputeIntParam(blurShader, Length, height);
cmd.SetComputeTextureParam(blurShader, KernelIndex, "Source", buffer1);
cmd.SetComputeTextureParam(blurShader, KernelIndex, "Dest", buffer0);
cmd.DispatchCompute(blurShader, KernelIndex, width, 1, 1);
}
}
//buffer0を画面にコピー
Blitter.BlitCameraTexture(cmd, buffer0, renderer.cameraColorTargetHandle);
context.ExecuteCommandBuffer(cmd);
}
finally
{
cmd.Clear();
CommandBufferPool.Release(cmd);
}
}
public void Set(float radius)
{
this.radius = radius;
}
public void Dispose()
{
buffer0?.Release();
buffer1?.Release();
}
}
public override void Create()
{
pass = new BlurPass(blurShader);
}
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{
pass.Set(radius);
pass.renderPassEvent = RenderPassEvent.BeforeRenderingPostProcessing;
blurShader.SetFloat(Sigma, sigma);
renderer.EnqueuePass(pass);
}
protected override void Dispose(bool disposing)
{
pass.Dispose();
}
}
RendererFeatureをセットすると、画面にぼかしが適用されます。
ひとまずはRadiusを64、Sigmaを0.5にセットしておきます。

パフォーマンス計測
さて、この実装をもとに最適化を行っていくわけですが、最適化の効果を確認するためには、実際の処理時間を知りたいところです。FPSを見て判断してもいいのですが、FPSはほかの処理やVSyncの影響もあったりするので、ここはPIXを使って処理時間を計測します。
PIXはMicrosoftが提供しているDirectX用のプロファイラで、API呼び出しのキャプチャや処理時間の計測など、パフォーマンスチューニングに便利な様々な機能を有しています。PIXは当然Windows専用ですが、macOSをお使いの方はXcodeでGPUプロファイラが使えるようです(未検証)。
PIXの詳しい使い方はこちらでは書きませんが、公式マニュアルやUnityステーションの動画を見るとよくわかると思います。
PIXの結果は以下のようになりました。

BlurPassの処理時間は2,919,840nsでした。
さて、ここからどのくらい高速化できるでしょう?
① 共有メモリを使ってテクスチャフェッチを減らす
GPUでは様々なレベルでの並列化が行えるように設計されています。Compute ShaderではGPU上の複数の計算ユニット(NVIDIAではStreaming Multiprocessor=SM, AMDではCompute Unit=CUと呼ばれる)にそれぞれ異なるスレッドグループをアサインすることで、複数のスレッドグループを並列に動作させています。シェーダー内部で使用する変数等は各計算ユニット内部のレジスタに保持するため高速に読み書きできるのですが、テクスチャのようなデータはGPU全体で共有されるグローバルメモリに配置されており、アクセスには比較的大きなコストがかかります。テクスチャへのアクセスはCompute Shaderでもボトルネックになりがちなので、まずはここを改善します。
これにはスレッドグループ共有メモリ (TGSM, thread group shared memory)の活用が有効です。TGSMは各計算ユニットの内部に配置されたメモリで、各スレッドグループの実行は必ずどれかひとつの計算ユニットに閉じているので、TGSMに書き込んだデータはスレッドグループ内部で共有することができます。TGSMへのアクセスはグローバルメモリと比較すると格段に高速です。
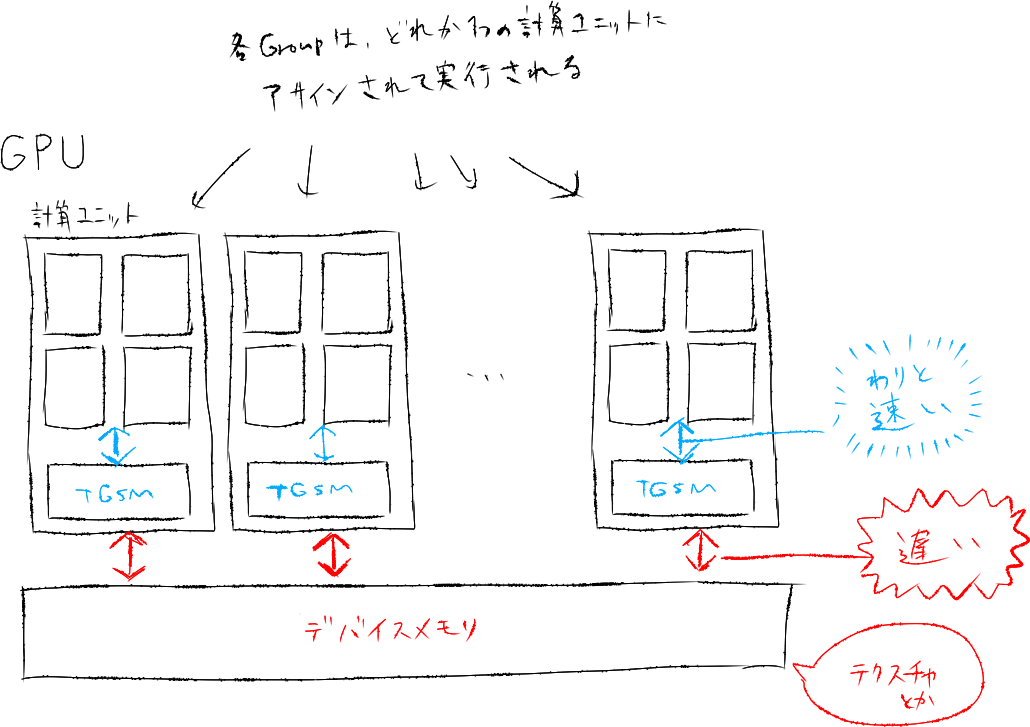
現在、各スレッドがぼかし処理のために近傍の複数のピクセルをフェッチしています。ここで、グローバルメモリ上のピクセルを事前にTGSMにキャッシュすることで、グローバルメモリへのアクセスを減らし高速化を行うことができます。これは特定へのピクセルへの重複したアクセスが多ければ多いほど恩恵が大きくなります。
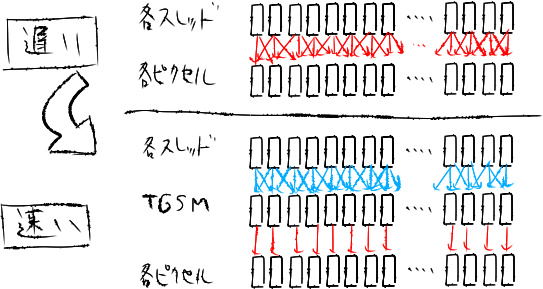
今回の場合は各スレッドグループが1ラインのぼかしを担当するため、1ラインをTGSMに保存すればよさそうです。DirectComputeにおけるTGSMは(スレッドグループあたりの)サイズ上限が32KiBまでとなっているため、float4を2048個までキャッシュすることができます。すなわち処理できるテクスチャサイズが各辺2048ピクセルまでという制約がついてしまいますが、今回はフルHDに足りればよいという判断で許容することにします。
Compute ShaderでTGSMを使用するには、groupsharedというキーワードを付与したグローバル変数を定義します。以下が改良後のシェーダーコードです。
#pragma kernel CSMain
#pragma enable_d3d11_debug_symbols
RWTexture2D<float4> Source;
RWTexture2D<float4> Dest;
float _Sigma;
float _Radius;
uint _Length;
// numthreadsに指定できる最大値
#define NUM_THREADS 1024
+
+ // TGSM用の変数。今回は面倒なので最大サイズの2048で固定
+ groupshared float4 lineCache[2048];
[numthreads(NUM_THREADS,1,1)]
void CSMain(uint ti: SV_GroupIndex, uint3 gid: SV_GroupID)
{
// ぼかしで使用する値の定数部分を事前に計算して全体の計算量を削減する
const float s0 = 1.0 / (2.5066283 * _Sigma);
const float s1 = 2.0 * _Sigma * _Sigma;
const float invRadius = _Radius > 0 ? (1.0 / _Radius) : 0;
const uint repeat = ceil((float)_Length / NUM_THREADS);
+
+ // TGSMに処理対象のラインをキャッシュ
+ for (int r = 0; r < repeat; r++)
+ {
+ uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
+ lineCache[index_r] = Source[uint2(index_r, gid.x)];
+ }
+
+ // グループ内の全スレッドがキャッシュ完了するのを待つ
+ GroupMemoryBarrierWithGroupSync();
// 1ラインのサイズがスレッドグループサイズを超える場合は、1スレッドが2ピクセル以上を担当する
for (int r = 0; r < repeat; r++)
{
// 重みの合計
float w_sum = 0.0;
// 画素値の合計
float4 c_sum = (0.0).xxxx;
// 中央ピクセル位置
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
// 近傍ピクセルの処理
for (int s = -_Radius; s < _Radius; s++)
{
// ピクセル位置
int p = clamp((int)index_r + s, 0.0, _Length - 1);
// ガウス関数のサンプル位置を正規化
const float d = abs(invRadius * s);
// ガウス関数で重み
float w = s0 * exp(-(d * d) / s1) * step(d, 1);
- float4 c = Source[uint2(p, gid.x)] * w;
+ float4 c = lineCache[p] * w;
w_sum += w;
c_sum += c;
}
// 画素値の合計を重みの合計で割る
Dest[uint2(gid.x, index_r)] = c_sum / w_sum;
}
}

処理時間は2,919,840ns -> 2,435,072nsになりました。
② サンプリング回数を間引く
現在、ぼかし半径を(フルHDで)64ピクセルに設定しており、各カーネルが129ピクセルをサンプリングするようになっています。しかしサンプリング回数上限を64回に設定し、ピクセルを一個飛ばしにサンプリングするように変更することでグローバルメモリへのアクセス回数や計算量を削減できそうです。
当然ぼかしの品質に影響があるはずですが、とりあえずやってみてどんな見た目になるか確認してみましょう。
#pragma kernel CSMain
#pragma enable_d3d11_debug_symbols
RWTexture2D<float4> Source;
RWTexture2D<float4> Dest;
float _Sigma;
float _Radius;
uint _Length;
// numthreadsに指定できる最大値
#define NUM_THREADS 1024
+
+ // 最大サンプリング回数を制限
+ #define HALF_MAX_SAMPLES 32
// TGSM用の変数。今回は面倒なので最大サイズの2048で固定
groupshared float4 lineCache[2048];
[numthreads(NUM_THREADS,1,1)]
void CSMain(uint ti: SV_GroupIndex, uint3 gid: SV_GroupID)
{
// ぼかしで使用する値の定数部分を事前に計算して全体の計算量を削減する
const float s0 = 1.0 / (2.5066283 * _Sigma);
const float s1 = 2.0 * _Sigma * _Sigma;
+ const uint sampleStep = (floor(_Radius) / HALF_MAX_SAMPLES) + 1;
const float invRadius = _Radius > 0 ? (1.0 / _Radius) : 0;
const uint repeat = ceil((float)_Length / NUM_THREADS);
// TGSMに処理対象のラインをキャッシュ
for (int r = 0; r < repeat; r++)
{
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
lineCache[index_r] = Source[uint2(index_r, gid.x)];
}
// グループ内の全スレッドがキャッシュ完了するのを待つ
GroupMemoryBarrierWithGroupSync();
// 1ラインのサイズがスレッドグループサイズを超える場合は、1スレッドが2ピクセル以上を担当する
for (int r = 0; r < repeat; r++)
{
// 重みの合計
float w_sum = 0.0;
// 画素値の合計
float4 c_sum = (0.0).xxxx;
// 中央ピクセル位置
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
// 近傍ピクセルの処理
- for (int s = -_Radius; s < _Radius; s++)
+ for (int s = -HALF_MAX_SAMPLES + 1; s < HALF_MAX_SAMPLES; s++)
{
// ピクセル位置
- int p = clamp((int)index_r + s, 0.0, _Length - 1);
+ int ss = s * sampleStep;
+ int p = clamp((int)index_r + ss, 0.0, _Length - 1);
// ガウス関数のサンプル位置を正規化
- const float d = abs(invRadius * s);
+ const float d = abs(invRadius * ss);
// ガウス関数で重み
float w = s0 * exp(-(d * d) / s1) * step(d, 1);
float4 c = lineCache[p] * w;
w_sum += w;
c_sum += c;
}
// 画素値の合計を重みの合計で割る
Dest[uint2(gid.x, index_r)] = c_sum / w_sum;
}
}
処理時間は2,435,072ns -> 1,905,920nsになりました。
ぼかしのクオリティですが、フルサイズだとzenn側で圧縮がかかってしまってわかりにくかったので、切り出して比較してみます。
変更前

変更後

変更後はうっすらと格子状のアーティファクトが発生しています。ほとんどわからない程度なので許容することにしましょう。
もっとパフォーマンスを切り詰めたければ、もっとサンプリング回数を間引くのもアリです。アーティファクトはより濃く現れてくるので、ここは要求クオリティと相談して決めましょう。
③ 重複する計算を減らす
現在、各スレッドが特定のピクセルを中心にしてその両側の領域を舐めています。ガウシアンブラーにおける重みは中心をピークとして対称に降りていく形をしているため、重みはどちらか片側のみ計算すれば十分です。

ということで、コードを修正していきます。
#pragma kernel CSMain
#pragma enable_d3d11_debug_symbols
RWTexture2D<float4> Source;
RWTexture2D<float4> Dest;
float _Sigma;
float _Radius;
uint _Length;
// numthreadsに指定できる最大値
#define NUM_THREADS 1024
// 最大サンプリング回数を制限
#define HALF_MAX_SAMPLES 32
// TGSM用の変数。今回は面倒なので最大サイズの2048で固定
groupshared float4 lineCache[2048];
[numthreads(NUM_THREADS,1,1)]
void CSMain(uint ti: SV_GroupIndex, uint3 gid: SV_GroupID)
{
// ぼかしで使用する値の定数部分を事前に計算して全体の計算量を削減する
const float s0 = 1.0 / (2.5066283 * _Sigma);
const float s1 = 2.0 * _Sigma * _Sigma;
const uint sampleStep = (floor(_Radius) / HALF_MAX_SAMPLES) + 1;
const float invRadius = _Radius > 0 ? (1.0 / _Radius) : 0;
const uint repeat = ceil((float)_Length / NUM_THREADS);
// TGSMに処理対象のラインをキャッシュ
for (int r = 0; r < repeat; r++)
{
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
lineCache[index_r] = Source[uint2(index_r, gid.x)];
}
// グループ内の全スレッドがキャッシュ完了するのを待つ
GroupMemoryBarrierWithGroupSync();
// 1ラインのサイズがスレッドグループサイズを超える場合は、1スレッドが2ピクセル以上を担当する
for (int r = 0; r < repeat; r++)
{
// 重みの合計
float w_sum = 0.0;
// 画素値の合計
float4 c_sum = (0.0).xxxx;
// 中央ピクセル位置
uint index_r = clamp(ti + r * NUM_THREADS, 0, _Length - 1);
+
+ // 中央ピクセルの処理
+ {
+ w_sum += s0 * 0.5;
+ c_sum += lineCache[index_r] * s0;
+ }
// 近傍ピクセルの処理
- for (int s = -HALF_MAX_SAMPLES + 1; s < HALF_MAX_SAMPLES; s++)
+ for (int s = 1; s < HALF_MAX_SAMPLES; s++)
{
// ピクセル位置
int ss = s * sampleStep;
- int p = clamp((int)index_r + ss, 0.0, _Length - 1);
+ int2 p = clamp(int2(index_r + ss, index_r - ss), (0.0).xx, (_Length - 1).xx);
// ガウス関数のサンプル位置を正規化
const float d = abs(invRadius * ss);
// ガウス関数で重み
float w = s0 * exp(-(d * d) / s1) * step(d, 1);
- float4 c = lineCache[p] * w;
+ float4 c = (lineCache[p.x] + lineCache[p.y]) * w;
w_sum += w;
c_sum += c;
}
+
+ w_sum *= 2.0;
// 画素値の合計を重みの合計で割る
Dest[uint2(gid.x, index_r)] = c_sum / w_sum;
}
}
処理時間は1,905,920ns -> 1,604,448nsになりました。
④ numthreadsを最適化する
GPUの各計算ユニットではより多くのスレッドグループを同時に実行できた方が性能が上がりやすくなります。いまいち詳しくないのですが、あるスレッドが重いメモリアクセスを行っている間に別のスレッドを動かして遅延を隠す、いわゆるパイプライン処理が行われることによるものらしいです。
しかし、計算ユニットが同時に実行できるスレッドグループの数は、TGSMの使用量、カーネルで使用しているベクタレジスタの数、スレッドグループサイズなどによって制限されます。
今回はTGSMを最大32KiB使用しますが、自分が使っているNVIDIA GeForce RTX 2070において各SMのTGSMサイズは64KiBになっているため、計算ユニットが同時に実行できるスレッドグループの数はどうがんばっても2が上限となります(TGSMの制限を除けば、RTX 2070自体は各SMが32グループまで同時に実行可能)。
ここで、RTX 2070において各計算ユニットが同時に担当できるスレッド数の上限は1024なので、2個のスレッドグループを同時に実行するためにはnumthreadsを512にする必要があります。
またレジスタ数にも気を使う必要があり、RTX 2070における各計算ユニット内部のベクタレジスタ数は65536 x 32bitなので、これまでの条件ではカーネルの使用するレジスタ数を64 x 32bitに収める必要があります。
ということで、numthreadsを512に変更してPIXでプロファイリングしてみましょう。
- #define NUM_THREADS 1024
+ #define NUM_THREADS 512
処理時間は1,604,448ns -> 1,308,608nsとなりました。最初と比較すると半分以下になっています。
カーネルが使用しているレジスタの数を調べるには、PIX上でtpc average registers per thread shader cs.ratioカウンタを有効にします(NVIDIAの場合)。
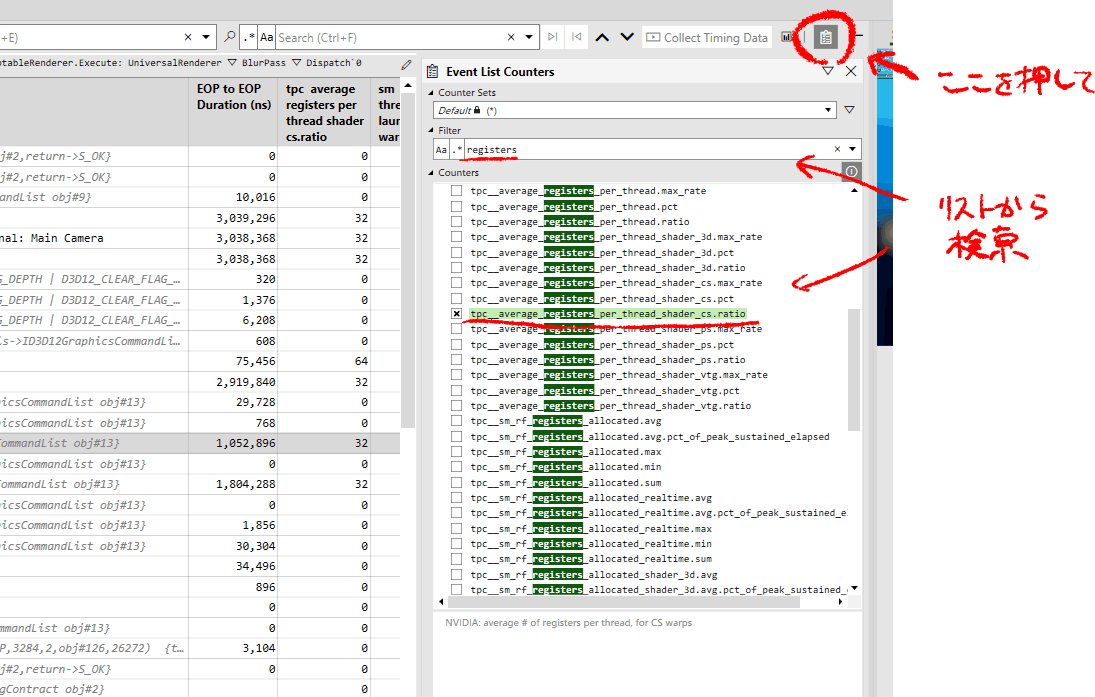

64に収まっているようです。
ここで紹介したような、シェーダーがハードウェアをどのくらい活用できているかを表す用語としてOccupancyというものがあります。今回、CUDA Occupancy Calculatorというツールを使ってOccupancyをチェックしてみました。各ハードウェアの能力値をもとに、最適なスレッドグループサイズやレジスタ数、TGSMの使用量などを導出することができてとても便利です。
……こんなふうに、特定のGPUをターゲットにすることで、そのGPUにとって最適なチューニングを行うことができます。ただ実行環境依存なのでPCゲームやモバイルゲームなどでは扱いが難しいかもしれません。逆にコンシューマ機に向けた最適化ではこうしたアプローチがパワーを発揮しそうな感じがします(PIXは使えないかもしれませんが)。
そのほかのテクニック
今回は有効ではなかったけど、覚えておくと役に立つテクニック集です。
ループのunroll
HLSLではforループに[unroll]という属性をつけることができ、これをやるとコンパイル時にループ内の処理がインライン展開されます(ループ回数がコンパイル時に決定できる必要がある)。これによりループごとの条件分岐などをスキップすることができ、処理速度向上のために使用されます。
ただ今回のシェーダーではほぼ効果がないどころか、微妙に速度が落ちるようでした。unrollを行うとレジスタ数が大きくなる傾向があるようなので(未検証)、それによってOccupancyが低下しているのかもしれません。もちろん環境によって変わる可能性があるので、とりあえず試してみて計測してみるのもいいと思います。
共有メモリのバンク衝突を避ける
NVIDIA GPUにおけるTGSMは複数のバンクに分割されており、異なるメモリバンクへのアクセスは並列化されるので高速になります。逆に、同じバンクに同時にアクセスしようとすると待ち時間が発生して低速になります。
最近のNVIDIA GPUにおけるTGSMのメモリバンクは各32ビット幅で、全部で32個であります。すなわち32個の連続したfloatやintに並列でアクセスすると速くなります。NVIDIA GPUは32スレッドを単位としてSIMD実行するので、これらを加味して各スレッドがアクセスするアドレスを調整することで、バンクの衝突を防ぎアクセス速度を向上することができます。
今回は共有メモリ上の連続したfloat4(=4x32ビット)にアクセスしていたので、32スレッドで同時にアクセスすればバンクが衝突しそうな感じがするのですが、実際にバンクアクセスをずらしてみてもほとんど効果がありませんでした。もしかすると内部で自動的にバンクアクセスをずらす処理が行われているのかもしれません。(未検証です。)
Memory Coalescingを発動させる
NVIDIAのGPUでは、グローバルメモリの連続した領域に同時にアクセスすると、アクセスが高速化されるMemory Coalescingというテクニックがあり、これによってテクスチャアクセスを高速化することができます。
メモリ内において、テクスチャは横方向にピクセルが連続した状態で格納されています。今回、テクスチャのロードはMemory Coalescingが発動する条件を満たしています。一方で処理結果のストアは転置されるためMemory Coalescingが発動しません。これもできることなら発動させたいところですが、ちょっとうまいアルゴリズムが思いつきませんでした。
おわり
状況によって使えるテクニックと使えないテクニック、速くなるテクニックと速くならないテクニックなどなど、様々です。Compute Shaderのパフォーマンスチューニングでは「こうすれば速くなる」と言い切れるものが少なく、最終的にはPIXのようなツールを使って実際に計測していくことが必要だと思います。ただ、それでもGPUの構造に基づいた理屈(グローバルメモリやTGSMなどのメモリの構造, レジスタ, スケジューリングなど)を知ることで、より速く最適なコードに近づけていくことができます。
Discussion