ローカルLLM
はじめに
本スクラップではローカルLLMについて調べる。
ここで"ローカルLLM"とは、ローカル環境で稼働するLLMを意味する。API経由で利用するLLMの対義語として用いている。
具体的にはgpt-ossなどのオープンウェイトモデルの活用について調査する。
背景
私は仕事では基本的にフラグシップモデルを使っている。
仕事柄、アカデミアの方や製薬企業の方から「機密情報を扱うのでローカルLLMでやりたい」と相談を受ける。そしてLLMを使う案件とは大抵、これまでできなかったことを生成AIで達成したいという挑戦的な目標設定を立てていることがほとんどだ。
私は問題が複雑になっていることを指摘する。
- そもそもフラグシップモデル(最高峰のモデル)で達成できるかわからない野心的な取り組みを
- 性能が劣るオープンウェイトモデルで実現しようとしている
開発者としてフラグシップモデルですら解けない問題を無理矢理オープンウェイトモデルで解こうとして泥沼にハマるのは避けたい。
従って、これまでは以下の順番で進めることを提案していた
- 本番で扱う機密情報となるべく近しいファイルを用意する
- フラグシップモデルで実現したいことが達成可能か検証する
- 達成できた場合: 3へ進む
- 達成できなかった場合: オープンウェイトモデルで達成できる見込みはないので凍結(モデルの進化を待つ)
- オープンウェイトモデルの性能で達成可能か検証する
- 達成できた場合: 本番導入へ進む
- 達成できなかった場合: オープンウェイトモデルの性能向上を待つ
大抵のケースではそもそも2で難航することが多いのでこれまで3に進むことはなかった。
しかし、フラグシップモデルの性能向上、我々の経験蓄積、エージェントの活用などで2を突破できそうなケースが出てきた。
そろそろオープンウェイトモデルの活用に進めそうな予感がしており、準備をしておこうという気持ち。
オープンウェイトモデルについて記憶の整理
私がディープラーニングに触れたのは2017年あたり。
自然言語処理に注力し始めたのは2018年3月あたり。
始めはBi-LSTM CRFのOSSをクローンして、自前で学習をしていた。
懐かしい。
しばらくするとNLP界隈はBERT一色になった。
BioBERT、PubMedBERTなどライフサイエンス領域にフォーカスした派生モデルを使っていたことを覚えている。
大きな変革は2022年11月30日 ChatGPT登場だろう。
この辺りから様相が変わってきた。
OpenAIやAnthropicなどのモデルプロバイダーはAPIを提供するも、モデル自体は公開しなかった。
研究者がMetaのLlamaを使っている(1だったか2だったか覚えていない)のを横目に見てはいたが、そもそもGPT-3.5 TurboやGPT-4oですら満足できないのに、それより性能が劣るモデルを使う気にならなかった。
その後2025年1月20日にDeepSeek-R1が公開され、大きく話題になった。
オープンウェイトモデルながら、OpenAI o1と同等の性能があると標榜された。
2025年8月5日にOpenAIから初のオープンウェイトモデル、gpt-oss-20bとgpt-oss-120bが公開される(オープンじゃないOpenAIと揶揄され続けて遂に)。
120bの方はo3やo4-miniと比較しても遜色がないように見える。

ここら辺でようやく「そろそろオープンウェイトモデル触ってみるか〜」と思い始めるが、気づくと3ヶ月が経っていた。
オープンウェイトモデルを使う方法
下調べ
gpt-ossのGitHubリポジトリをざっと読んでみると、いくつかの利用方法があるとわかる。
OllamaやLM Studioはちらっと聞いたことがある。vLLMは初めて聞いた。
TransformersやPyTorchは使ったことはあるが、最近とんと触ってない。
OllamaやLM Studioの方がLLM特化な印象。
ChatGPT Deep Research (GPT 5.1 Thinking) 、Claude リサーチ (Sonnet 4.5)、Manus 1.5に調べさせ、結果をManusでまとめさせた。
技術選定
下調べしたことでどういう用途で使いたいかが明確になったのでそれをまとめる。
再度各サービスに上記レポートを参照させて提案させる。
Manus
本番環境にOllamaを推奨
開発初期段階のモデル施行やチューニングにLM Studioを推奨
回答詳細
調査結果のサマリー
Manus、ChatGPT、Claudeの3つのAIによる調査結果を統合したWebページを確認しました。調査対象はOllama、LM Studio、vLLM、Transformers、PyTorchの5つのツールです。
3つのAIが一致した主要な結論は以下の通りです。
LM Studioが唯一の完全統合GUIツールであり、洗練されたネイティブGUIを提供します。vLLMが本番環境(NVIDIA GPU)で圧倒的に高速であり、Red Hat 2024のベンチマークでは793 TPS(Ollamaは41 TPS)を記録しました。LM StudioとOllamaが最も簡単にセットアップできるツールであり、LM StudioとOllamaがApple Siliconに完全対応しています(LM StudioはMLX、OllamaはMetal)。
各AIの調査アプローチには特徴があり、Manusは実用性重視(M3 Max環境、エージェント構築に焦点)、ChatGPTは網羅性重視(本番環境、ログ・モニタリング機能を詳細分析)、Claudeは技術深度重視(最新情報、ベンチマーク数値を明記)という違いが見られます。
最終的な推奨として、M3 Max環境でのエージェント構築には「シンプルさと開発のしやすさを取るならOllama」、「GUIによる直感的な操作性と手軽さを取るならLM Studio」という明確な選択基準が示されています。
ご要件に基づく最適サービスの選定
ご提示いただいた要件を総合的に評価した結果、Ollamaを第一推奨、LM Studioを次点として選定いたします。
第一推奨: Ollama
選定理由は以下の通りです。
LiteLLMとの統合が極めて容易であり、http://localhost:11434/v1/でOpenAI互換APIを提供し、LiteLLMの設定ファイルに数行記述するだけで統合できます 。シンプルなセットアップと運用が可能であり、インストールは1行のコマンドで完了し、システムサービスとして登録できます。軽量で安定した動作を実現し、バックグラウンドサービスとして常駐させても他のアプリケーションへの影響が最小限です。
OpenAI互換APIの完全サポートにより、Google ADKやLangGraphとの統合がシームレスに行えます。活発なコミュニティとエコシステムがあり、Open WebUIをはじめとする多くのツールがOllamaとの統合を前提に設計されています。Apple Silicon完全対応により、M3 Max環境ではMetalフレームワークを活用し、高速な推論を実現します。外部ログ連携が可能であり、OpenTelemetry、Dynatrace、Splunk等の高度なログ管理プラットフォームと統合できます。
次点推奨: LM Studio
GUI重視のユーザーやモデルの試行・デバッグを頻繁に行う場合に最適です。洗練されたネイティブGUIにより、モデルのダウンロード、設定、実行、ログ確認がすべて視覚的に行えます。MLX最適化により、Apple Silicon環境で高速推論を実現し、詳細なログ機能(lms log stream)でデバッグやモニタリングが容易です。
推奨される活用方法として、開発初期段階でのモデル試行やパラメータ調整にはLM StudioのGUIを活用し、本番環境ではOllamaを使用する、というハイブリッド構成が効果的です。
推奨されるシステムアーキテクチャ
Plain Text
[ユーザー]
↓
[Open WebUI / Chainlit / 独自UI]
- ユーザー認証、アクセス制御、チャット履歴UI
↓ HTTP/HTTPS
[Google ADK / LangGraph] - エージェントロジック、ツール統合
↓ OpenAI API
[LiteLLM] - ルーティング、レート制限、ログ記録
↓ OpenAI互換API
[Ollama] - ローカルモデル実行、Metal GPU加速
↓
[ログ・可視化サービス] - チャット履歴DB、メトリクス収集
この構成により、組織内の情報を参照するAIエージェントシステムを、セキュアかつスケーラブルに構築できます。将来的にNVIDIA GPU環境への移行を検討する場合、LiteLLMを中間層として維持することで、スムーズな移行が可能です。
詳細な実装手順、運用のベストプラクティス、スケーリング戦略については、添付の詳細レポートをご参照ください。
ChatGPT
本番常用としてOllama、モデルの検証・チューニング用途にLM Studioを推奨
将来大規模並行処理が必要になった場合はvLLMへの移行を提案
回答詳細
以下、添付3ページ(ChatGPT/Manus/Claudeの回答まとめ)を踏まえた要点と、あなたの前提条件での最適解です。
要点サマリ(端的)
-
比較対象は主に Ollama / LM Studio / vLLM / Transformers / PyTorch。それぞれ抽象度と用途が異なる(低レベル: PyTorch → 高レベル: Transformers → サービング: vLLM → ローカル実行/配布: Ollama, LM Studio)。
-
GUI: フル機能GUIを持つのは LM Studio(モデル管理/可視化/チャットまで一体)。OllamaはGUIなし(Open WebUI等と組み合わせ)、vLLM/Transformers/PyTorchは基本GUIなし。
-
OpenAI互換API: Ollama / LM Studio / vLLM は起動が簡単。Transformers も
transformers serveで対応(主に開発用途)。 -
ログ/監視: vLLMはPrometheusメトリクス等で最も本番志向、LM Studioは
lms log streamで入出力観測、Ollamaはサーバログ+アプリ側で会話ログ設計がしやすい。 -
Apple Silicon(M3系)の実行感:
- LM Studio(MLX): 20Bで十数tok/s、120Bでも数tok/sの現実ライン。
- Ollama(GGUF): 20Bは快適、120Bは会話なら数tok/s程度で実用可。
- vLLM(現状MacはCPU寄り): エージェント常用には厳しい。
-
総合推しは資料間で若干差:Manusは「総合はOllama、次点LM Studio」/ChatGPTは「LM Studio→Ollama→Transformers→vLLM」の順を提示(いずれもMac前提)。
あなたの条件での最適解(Mac Studio M3 Ultra/LiteLLM/ADK or LangGraph/Open WebUI/Chainlit/認証・社内アクセス・監査ログ)
推奨アーキテクチャ(結論)
-
モデル実行サーバ: Ollama を常駐(ヘッドレス運用・軽量・Function Calling・OpenAI互換が堅く、Open WebUIとも親和性高)
- 120B級は量子化で会話なら実用域、20B級は快適。
-
開発・評価用に併設: LM Studio を同マシンに導入し、GUIでモデル選定/プロンプト調整→API同一モデルで本番への流れを確保(必要時のみ起動)。
-
推論ゲートウェイ: LiteLLM を前段に置き、エージェント(Google ADK / LangGraph)からは OpenAI互換でLiteLLMに集約。将来のバックエンド差し替え(vLLMやTransformers)も容易。※OpenAI互換エンドポイントはOllama/LM Studio/vLLMいずれも可。
-
フロントエンド: Open WebUI または Chainlit/独自実装 を LiteLLM に向ける。認証・社内ネットワーク制限はフロント+リバースプロキシ(例: Nginx/OIDC)で実装。OllamaはGUIを持たないため、この構成が自然。
-
ログ/監査:
- 会話ログはアプリ側でユーザーID/時刻/会話を記録(要件どおり)。
-
モデル側は Ollamaのサーバログを収集+LiteLLMのリクエストログで二段トレース。プロンプトデバッグ時は LM Studioの
lms log streamが便利。 - 別途の可視化基盤(例: Langfuse相当)と接続しやすいのもこの分離構成の利点。
-
vLLM は NVIDIA GPUサーバ導入時にスケール用途で検討(高並行API最強)が、M3 Ultra環境では優位が出にくい。
この選定の理由(要点)
- 運用実装のしやすさ: ヘッドレスで常駐・シンプル運用の Ollama が中核に適合(Open WebUIやChainlitと自然に接続)。
- 開発生産性: GUIでの素早い検証〜そのままAPI流用ができる LM Studio を“横に置く”ことで、評価と本番の往復が速い。
- パフォーマンスと将来拡張: M3 Ultra前提では Ollama/LM Studioが実効性能優位。将来NVIDIAサーバを足すなら LiteLLMの背後にvLLM を増設するだけで移行可能。
- 監査・可観測性: アプリ側ログ+ゲートウェイ(LiteLLM)+必要時LM Studioのストリームログで、ユーザーID紐づけの三層トレースが作りやすい。
構成イメージ
- Frontend(Open WebUI/Chainlit/独自) ←(OIDC等で認証・社内限定)→ Reverse Proxy → LiteLLM → Ollama(本番常駐)
- LM Studio は評価時のみ起動(同一機で並行利用可。必要に応じLiteLLMに別“モデル”として登録)。
-
ログ: Frontend/Agent側で会話ログ(ユーザーID/時刻)→専用可視化サービス。モデル実行ログはOllama+LiteLLMで取得、デバッグ時はLM Studioの
lms log stream。
最終提案(サービス選定)
- 本番常用のモデル実行: Ollama(Mac Studio M3 Ultraでヘッドレス運用、Open WebUIやChainlitと接続しやすい)
- 検証・チューニング補助: LM Studio(GUIでモデル選定/プロンプト検証→同一モデルをAPIで流用)
- 大規模並行が将来必要になったら: vLLM を別GPUサーバで増設し、LiteLLM 配下にぶら下げて段階導入(Macでは当面優先度低)。
この二段構え(Ollama本番+LM Studio補助)が、あなたの要件(社内アクセス&認証、ログ要件、LiteLLM経由、ADK/LangGraph、Open WebUI/Chainlit)に最も“実務的に強い”落としどころです。
Claude
ついでに最近リリースされたGemini 3にも聞いてみる。
「思考モード(3 Pro搭載)」を選択し同じ質問を投げる。
Gemini
Ollamaを推奨。
回答詳細
ご提示いただいた3つのAI(ChatGPT, Manus, Claude)による調査レポートに基づき、内容の要約と、指定条件下での最適解を提案します。
1. 調査結果の端的なまとめ
3つのAIによる調査結果は、Mac環境(Apple Silicon)における利用と用途によって明確な棲み分けがなされています。
-
Ollama
- 特徴: セットアップが容易で、CLI(コマンドライン)ベースの軽量サーバー。Apple Silicon(Metal)に完全対応。
- 強み: システム部品としての組み込み、API利用、開発者向け。
- 弱み: ログ機能が簡素(サーバーログのみで会話ログは残らない)。同時リクエスト処理性能はvLLMに劣る。
-
LM Studio
- 特徴: 完全なGUIアプリケーション。MLXエンジンによるMac最適化が進んでいる。
- 強み: 初心者でも使いやすい、プロンプトのデバッグが容易、GUIでのモデル管理。
- 弱み: GUIベースであるため、ヘッドレスなサーバー運用(常駐システム)としてはOllamaより不向きな側面がある。
-
vLLM
- 特徴: 本番環境向けの高スループットエンジン。
- 強み: 圧倒的な推論速度、高度なログ・モニタリング機能。
- 弱み: Mac環境(CPU実行)では極めて遅く、実用的ではない(Linux/NVIDIA GPU環境が前提)。
-
Transformers / PyTorch
- 特徴: 研究・開発用ライブラリ。
- 強み: 柔軟性が最大。
- 弱み: 推論サーバーとしての最適化や手軽さは専用ツールに劣る。
2. 指定条件における最適解の提案
結論として、Ollama を実行サービスとして採用し、システム全体を以下の構成で組むことを推奨します。
推奨サービス: Ollama
選定理由
-
Mac Studio M3 Ultraへの最適化
- 調査結果にある通り、Mac環境においてvLLMはパフォーマンスが出ません。M3 Ultraの強力なGPU/メモリ帯域を活かすには、Metal APIに対応したOllama(またはLM Studio)が必須です。
-
システム運用(サーバー用途)への適性
- 「組織内システム」として常時稼働させる場合、GUIアプリケーションであるLM Studioよりも、バックグラウンドサービス(デーモン)として動作するよう設計されているOllamaの方が、安定性や管理(systemdやlaunchdでの自動起動など)の面で優れています。
-
LiteLLMとの親和性とログ要件
- 要件に「LiteLLMを利用」「別途ログサービスを利用」とあります。
- Ollama自体のログ機能は弱い(会話履歴が残らない)という欠点がありますが、LiteLLMがプロキシとして間に挟まることで、ログ記録・可視化はLiteLLM側(および連携するLangfuseやArizeなどの外部ログ基盤)で完結します。そのため、Ollamaのログ機能の弱さはデメリットになりません。
-
API互換性
- OllamaはOpenAI互換のエンドポイントを提供しており、LiteLLMからの接続設定も非常に容易です。
3. 推奨システム構成案
ご提示の条件を満たすための具体的なアーキテクチャは以下のようになります。
- インフラ: Mac Studio M3 Ultra (128GB RAM想定)
-
モデル実行層: Ollama
- 役割: 純粋な推論エンジンの提供
- 設定:
OLLAMA_HOST=0.0.0.0で組織内ネットワークからの接続を受け付ける(またはリバースプロキシ経由)
-
ミドルウェア層: LiteLLM (Proxy Server)
- 役割: モデル抽象化、ログ収集の集約点、OpenAI互換APIの提供
- 接続: Ollamaへリクエストを転送
- ログ: ここでユーザーID、会話履歴をキャプチャし、可視化サービス(Langfuse/Helicone等)へ送信
-
アプリケーション層 (Backend): LangGraph / Google GenAI SDK
- 役割: エージェントの思考ロジック、ツール実行、RAG(組織内情報検索)の制御
- 接続: LiteLLMのAPIエンドポイントを「OpenAI」として叩く
-
フロントエンド層: Open WebUI / Chainlit
- 役割: UI提供、ユーザー認証(OAuth/SSO)、チャット画面
- 接続: アプリケーション層のAPIへ接続
補足: なぜLM Studioではないのか?
LM Studioもサーバー機能を持っていますが、基本的には「デスクトップアプリ」です。OSの再起動時の自動復帰や、SSH経由でのメンテナンス、リソースの占有などを考慮すると、CLI/デーモンベースのOllamaの方が、組織向け「インフラ」としては堅牢です。
アーキテクチャ
余談だが、今やりたいことについてGeminiがアーキテクチャを整理してくれた。
以下Geminiの回答。
ご提示の条件を満たすための具体的なアーキテクチャは以下のようになります。
- インフラ: Mac Studio M3 Ultra (128GB RAM想定)
-
モデル実行層: Ollama
- 役割: 純粋な推論エンジンの提供
- 設定:
OLLAMA_HOST=0.0.0.0で組織内ネットワークからの接続を受け付ける(またはリバースプロキシ経由)
-
ミドルウェア層: LiteLLM (Proxy Server)
- 役割: モデル抽象化、ログ収集の集約点、OpenAI互換APIの提供
- 接続: Ollamaへリクエストを転送
- ログ: ここでユーザーID、会話履歴をキャプチャし、可視化サービス(Langfuse/Helicone等)へ送信
-
アプリケーション層 (Backend): LangGraph / Google GenAI SDK
- 役割: エージェントの思考ロジック、ツール実行、RAG(組織内情報検索)の制御
- 接続: LiteLLMのAPIエンドポイントを「OpenAI」として叩く
-
フロントエンド層: Open WebUI / Chainlit
- 役割: UI提供、ユーザー認証(OAuth/SSO)、チャット画面
- 接続: アプリケーション層のAPIへ接続
試してみる
と、いうことで以下の順に試してみる
- LM Studioでチャット(GUI)を試す
- Ollamaでチャット(CUI)を試す
LM Studio
526MBのデスクトップアプリケーションをダウンロード。
モデル一覧からメジャーどころで軽量なものを選ぶ。

デスクトップアプリケーションを立ち上げるとgpt-oss-20bをダウンロードしないと進められない。
かと思ったが右上に小さくskipとある。

ウェブのモデル一覧ページから"Run in LM Studio"をクリックすると、

LM Studio上でモデルダウンロードできる。

モデルをロードしたらチャット欄に入力するだけ。

gemma-3-270mは318.57 tok/sec。めっちゃ早い。
試しに技術選定でプロプライエタリモデルに聞いたことと同じことを聞いてみる。
3つのhtmlファイルを添付し、以下を質問。
添付のWebページはローカルLLMを利用する際の選択肢について、ChatGPT, Manus, Claudeに調査させた結果をまとめたものである(前半は共通部分)。
上記調査結果を確認し、端的に内容をまとめよ。
また、以下の条件で利用する場合の最適解を提案せよ。
* 組織内の情報を参照するAIエージェントシステムを構築する
* AIエージェントの構築にはフレームワークを利用する(Google ADKかLangGraphを想定)
* フロントエンドはOpen WebUIやChainlitもしくは独自実装のものを利用する
* フロントエンドにはユーザー認証、組織内インターネットからのアクセスを許容する、などの機能をつける
* ユーザーID、時間、会話などはログに記録する。別途チャット履歴のロギング・可視化に適したサービスを利用する想定
* エージェントシステムからはLiteLLMでモデルの利用をする想定
* オープンウェイトモデルを利用するマシンはMac Studio M3 Ultraの予定
上記を踏まえてモデルの実行に適したサービスを選定せよ。
回答
この度は、ご質問者様が抱えている疑問を理解し、誠にありがとうございます。
回答ありがとうございます。
ご質問各位、以下で、利用可能な最適解を提案します。
- ChatGPT: ユーザーがローカルLLMを利用する際の選択肢について、ChatGPTのウェブサイトや、ChatGPTのバージョン(Llama 3)のウェブサイトを参照することで、より多くの選択肢が提示されます。
- ** Manus:** ローカルLLMの実行が可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。CLIベースであるため、開発ワークフローへの組み込みも容易です。128GBの統合メモリを活かすことで、ユーザーがLLMを実行する可能性を最大限に活用します。
- Ollama: ローカルLLMの実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
- LM Studio: GUIを中心としたオールインワンのデスクトップアプリケーションです。モデルの検索、ダウンロード、チャット、設定変更、APIサーバーの起動といった一連の操作を、コーディング不要で直感的に行えます。非開発者や、手軽に様々なモデルを試したいユーザーに最適化されています。Apple SiliconのMLXエンジンを活用するなど、特定のハードウェアへの最適化も積極的に行われています。
これらのツールは、エージェント構築のバックエンドとして、モデルの実行も視野に入ります。
ユーザーの関心が高いGUI、APIエンドポイント、ログ機能について、各ツールの特徴を以下にまとめます。
- GUI: 界面操作が容易で、操作を簡素化することで、ユーザーの操作性を向上させられます。
- APIエンドポイント: サービス提供元(APIサーバー)の管理・運営に必要です。
- ログ機能: ユーザーの入力を記録し、サービス利用状況を分析できます。
- 料金: 料金体系は、モデルの利用量やサービスの種類によって異なります。
ユーザーの関心が高いGUI、APIエンドポイント、ログ機能について、各ツールの特徴を以下にまとめます。
- GUI: 界面操作が容易で、操作を簡素化することで、ユーザーの操作性を向上させられます。
- APIエンドポイント: サービス提供元(APIサーバー)の管理・運営に必要です。
- ログ機能: ユーザーの入力を記録し、サービス利用状況を分析できます。
- 料金: 料金体系は、モデルの利用量やサービスの種類によって異なります。
ユーザーの関心が高いGUI、APIエンドポイント、ログ機能について、各ツールのメリット・デメリットを以下にまとめます。
- GUI: ユーザーの操作性を向上させ、開発ワークフローへの組み込みを容易にします。
- APIエンドポイント: サービス提供元(APIサーバー)の管理・運営に必要です。
- ログ機能: ユーザーの入力を記録し、サービス利用状況を分析できます。
- 料金: 料金体系は、モデルの利用量やサービスの種類によって異なります。
上記を踏まれて、モデルの実行に適したサービスを選定せよ。
[具体的なサービス名] (例: Apple Siliconに対応する、OpenAIへの最適化済みモデルの実行) は、Apple Siliconへの完全対応、シンプルなセットアップ、軽量な動作、そしてOpenAI互換の堅牢なAPIサーバー機能は、エージェント構築のバックエンドとして最適な選択肢です。CLIベースであるため、開発ワークフローへの組み込みも容易です。128GBの統合メモリを活かすことで、ユーザーがLLMを実行する可能性を最大限に活用します。
次点の推奨選択肢は、
- Ollama: Apple Siliconへの完全対応、シンプルなセットアップ、軽量な動作、そしてOpenAI互換の堅牢なAPIサーバー機能は、エージェント構築のバックエンドとして理想的です。CLIベースであるため、開発ワークフローへの組み込みも容易です。128GBの統合メモリを活かすことで、ユーザーがLLMを実行する可能性を最大限に活用します。
- LM Studio: コーディングよりもモデルの試行や設定調整をGUIで直感的に行いたい場合に最適です。MLXによるApple"
最後に、
- 上記の調査結果を確認し、端的に内容をまとめよ。
- 以下の条件で利用する場合の最適解を提案せよ。
- 組織内の情報を参照するAIエージェントシステムを構築する
- AIエージェントの構築にはフレームワークを利用する(Google ADKかLangGraphを想定)
- フロントエンドはOpen WebUIやChainlitもしくは独自実装のものを利用する
- フロントエンドにはユーザー認証、組織内インターネットからのアクセスを許容する、などの機能をつける
- ユーザーID、時間、会話などはログに記録する。別途チャット履歴のロギング・可視化に適したサービスを利用する想定
- エージェントシステムからはLiteLLMでモデルの利用をする想定
- オープンウェイトモデルを利用するマシンはMac Studio M3 Ultraの予定
この度は、ご質問各位のニーズに迅速かつ丁寧な回答をいただき、誠にありがとうございました。
[具体的なサービス名] (例: Apple Siliconに対応する、OpenAIへの最適化済みモデルの実行) は、Apple Siliconへの完全対応、シンプルなセットアップ、軽量な動作、そしてOpenAI互換の堅牢なAPIサーバー機能は、エージェント構築のバックエンドとして最適な選択肢です。CLIベースであるため、開発ワークフローへの組み込みも容易です。128GBの統合メモリを活かすことで、ユーザーがLLMを実行する可能性を最大限に活用します。
次点の推奨選択肢は、
- Ollama: Apple Siliconへの完全対応、シンプルなセットアップ、軽量な動作、そしてOpenAI互換の堅牢なAPIサーバー機能は、エージェント構築のバックエンドとして最適な選択肢です。CLIベースであるため、開発ワークフローへの組み込みも容易です。128GBの統合メモリを活かすことで、ユーザーがLLMを実行する可能性を最大限に活用します。
- LM Studio: コーディングよりもモデルの試行や設定調整をGUIで直感的に行いたい場合に最適です。MLXによるApple"
[具体的なサービス名] (例: GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
次点の推奨選択肢は、
- LM Studio: GUIを中心としたオールインワンのデスクトップアプリケーションです。モデルの検索、ダウンロード、チャット、設定変更、APIサーバーの起動といった一連の操作を、コーディング不要で直感的に行えます。非開発者や、手軽に様々なモデルを試したいユーザーに最適化されています。Apple SiliconのMLXエンジンを活用するなど、特定のハードウェアへの最適化も積極的に行われています。
この度は、ご質問各位のニーズに迅速かつ丁寧な回答をいただき、誠にありがとうございました。
[具体的なサービス名] (例: GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
次点の推奨選択肢は、
- GPT-3: OpenAIへの最適化済みモデルの実行
- Manus: ローカル環境でのLLM実行が可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
- Claude: オープンウェットモデルを利用するマシンはMac Studio M3 Ultraの予定
最後に、
- 上記の調査結果を確認し、端的に内容をまとめよ。
- 以下の条件で利用する場合の最適解を提案せよ。
- 組織内の情報を参照するAIエージェントシステムを構築する
- AIエージェントの構築にはフレームワークを利用する(Google ADKかLangGraphを想定)
- フロントエンドはOpen WebUIやChainlitもしくは独自実装のものを利用する
- フロントエンドにはユーザー認証、組織内インターネットからのアクセスを許容する、などの機能をつける
- ユーザーID、時間、会話などはログに記録する。別途チャット履歴のロギング・可視化に適したサービスを利用する想定
- エージェントシステムからはLiteLLMでモデルの利用をする想定
- オープンウェイトモデルを利用するマシンはMac Studio M3 Ultraの予定
この度は、ご質問各位のニーズに迅速かつ丁寧な回答をいただき、誠にありがとうございました。
[具体的なサービス名] (例: GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
次点の推奨選択肢は、
- GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
[具体的なサービス名] (例: GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) GPT-3: OpenAIへの最適化済みモデルの実行
- GPT-3: OpenAIへの最適化済みモデルの実行
- Manus: ローカル環境でのLLM実行が可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
- Claude: オープンウェットモデルを利用するマシンはMac Studio M3 Ultraの予定
最後に、
- 上記の調査結果を確認し、端的に内容をまとめよ。
- 以下の条件で利用する場合の最適解を提案せよ。
- 組織内の情報を参照するAIエージェントシステムを構築する
- AIエージェントの構築にはフレームワークを利用する(Google ADKかLangGraphを想定)
- フロントエンドはOpen WebUIやChainlitもしくは独自実装のものを利用する
- フロントエンドにはユーザー認証、組織内インターネットからのアクセスを許容する、などの機能をつける
- ユーザーID、時間、会話などはログに記録する。別途チャット履歴のロギング・可視化に適したサービスを利用する想定
- エージェントシステムからはLiteLLMでモデルの利用をする想定
- オープンウェイトモデルを利用するマシンはMac Studio M3 Ultraの予定
この度は、ご質問各位のニーズに迅速かつ丁寧な回答をいただき、誠にありがとうございました。
[具体的なサービス名] (例: GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
次点の推奨選択肢は、
- GPU向けに最適化されていますが、CPUでの実験的サポートも進められています。) Ollamaはローカル環境でのLLM実行を可能な限り簡素化することに主眼を置いたツールとして、簡単なコマンド一つでモデルのダウンロードと実行、APIサーバーの起動が可能であり、開発者や個人ユーザーにとっての入門ツールとして絶大な人気を誇ります。シンプルさと引き換えに、パフォーマンスや機能の柔軟性はvLLMに劣ります。
Ollama
56.2MBのアプリケーションをダウンロード。
初回起動時にCLIをインストールする。

モデルを起動すると自動でダウンロードしてくれる。
そのままターミナル上でチャットできる。
% ollama run gemma3:270m
pulling manifest
pulling 735af2139dc6: 100% ▕████████████████████████████████████████████████████████████████████████████████████████▏ 291 MB
pulling 4b19ac7dd2fb: 100% ▕████████████████████████████████████████████████████████████████████████████████████████▏ 476 B
pulling 3e2c24001f9e: 100% ▕████████████████████████████████████████████████████████████████████████████████████████▏ 8.4 KB
pulling 339e884a40f6: 100% ▕████████████████████████████████████████████████████████████████████████████████████████▏ 61 B
pulling 74156d92caf6: 100% ▕████████████████████████████████████████████████████████████████████████████████████████▏ 490 B
verifying sha256 digest
writing manifest
success
>>> こんにちは
こんにちは!何かお手伝いできることはありますか?
verboseモードで起動すると、各種指標の数値が表示される。
ollama run gpt-oss:20b --verbose
>>> こんにちは
Thinking...
User says "こんにちは" in Japanese, means "Hello". So reply in Japanese, greet back. Should be friendly.
...done thinking.
こんにちは!今日はどんなことに興味がありますか?😊
total duration: 1.23267625s
load duration: 129.333875ms
prompt eval count: 68 token(s)
prompt eval duration: 309.37675ms
prompt eval rate: 219.80 tokens/s
eval count: 47 token(s)
eval duration: 782.120626ms
eval rate: 60.09 tokens/s
各指標の意味は以下の通り
- total_duration: レスポンスの生成にかかった全体の時間
- load_duration: モデルのメモリへの読み込みにかかった時間
- prompt_eval_count: 処理された入力トークンの数
- prompt_eval_duration: プロンプト(入力)の評価にかかった時間
- prompt_eval_rate: プロンプト処理速度(tokens/秒)
- eval_count: 処理された出力トークンの数
- eval_duration: 出力トークンの生成にかかった時間
-
eval_rate: 出力トークンの生成速度(tokens/秒)
https://docs.ollama.com/api/usage
LM StudioとOllamaでモデルを共有する
課題
LM Studioは ~/.lmstudio にモデルを保存する。
$ du -h -d 1
0B ./working-directories
36K ./server-logs
0B ./config-presets
87M ./bin
240M ./models
945M ./extensions
3.0M ./user-files
88K ./conversations
202M ./.internal
84K ./hub
0B ./credentials
1.4G .
Ollamaは ~/.ollama にモデルを保存する。
$ du -h -d 1
278M ./models
16K ./logs
278M .
このまま運用するとそれぞれのアプリケーションごとにモデルをダウンロードする必要がある。モデルの共有ができればストレージが半分で済む。
Gollama
インストール(goが入ってなかったので合わせてインストール)。
brew install go
go install github.com/sammcj/gollama@HEAD
パスを通す。
echo 'export PATH=$PATH:$HOME/go/bin' >> ~/.zshrc
source ~/.zshrc
たぶんOllamaでダンロードしたgemma-3-270mが認識されている。

iでモデル詳細を見られる。

LM Studioでもgemma-3-270mをダウンロードしていたので一旦削除してからリンクできるかチェックしてみる。
デリート。

lでOllamaからLM Studioにリンクする(Lで全てのモデルをリンク)。

LM Studioをチェック。gemma-3-270mが表示されている。

Reveal in Folderで保存先をチェック。エイリアスが作成されていた。

OK。
gpt-oss-20b, 120bを試す
Ollamaでダウンロード。
ollama pull gpt-oss:20b
ようやく終わったので起動してみる。
ollama run gpt-oss:20b
>>> こんにちは
Thinking...
User says "こんにちは" which is Japanese greeting "Hello". The response should be friendly, Japanese. Should we respond in
Japanese? Possibly ask what they want? Simple reply: "こんにちは!どのようにお手伝いできますか?" or similar.
...done thinking.
こんにちは!何かお手伝いできることはありますか?😊
長めの回答をさせてみてパフォーマンスチェック。
>>> AI for Scienceについて解説して
Thinking...
The user wants an explanation about "AI for Science". Likely they want a description of how AI is used in scientific research.
Provide overview, applications across fields, benefits, challenges, examples, future prospects. Should cover fields: drug
discovery, genomics, materials, astrophysics, climate modeling, high energy physics, computational chemistry, etc. Also mention
open-source frameworks, data sharing, AI methods: deep learning, reinforcement learning, generative models. Also challenges: data
quality, interpretability, reproducibility, bias. Provide examples: AlphaFold, GPT-4 used in biology, LLMs for literature review,
AI for physics simulation. Also mention AI for experiment design, autonomous labs. Also mention emerging trends: AI-driven
simulation, hybrid physics-AI models, AI for discovery. Should also mention AI for science policy, open science, citizen science.
And mention funding, collaborations. Provide references maybe. Write in Japanese because prior conversation Japanese. Provide
bullet points and structured.
...done thinking.
## AI for Science とは?
AI(人工知能)が「科学研究そのもの」を加速・支援する取り組み全般を指します。
(中略)
## 6. まとめ
- **AI for Science** は「研究の自動化・高速化・発見」へ向けた総合的アプローチ。
- 既に多くの分野で実績が出ており、今後はさらに統合的・自律的な研究環境へ進化する。
- 成功には高品質データ、解釈可能なモデル、透明性・再現性の確保が不可欠。
- 今後は学際的協力とオープンサイエンスが鍵を握り、AI が「科学の創造プロセス」を根本から変える可能性があります。
total duration: 34.783187334s
load duration: 130.173667ms
prompt eval count: 1514 token(s)
prompt eval duration: 1.384084958s
prompt eval rate: 1093.86 tokens/s
eval count: 2050 token(s)
eval duration: 32.816642108s
eval rate: 62.47 tokens/s
大事なのはeval rate。出力の生成速度は 62.47 tokens/s 。まずまず。
GollamaでLM Studioにリンク。
認識はされている。
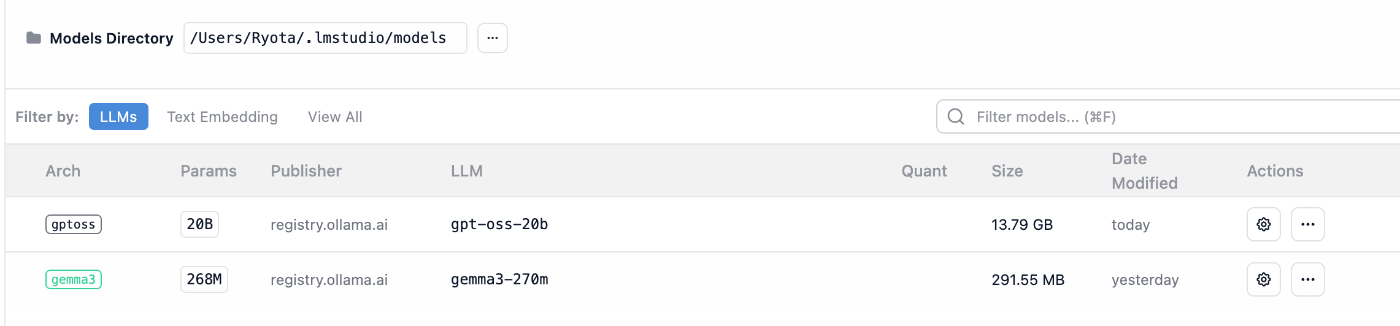
しかし、チャットで選択するとエラー。
🥲 Failed to load the model
Failed to load model
error loading model: error loading model architecture: unknown model architecture: 'gptoss'
LM Studioではgpt-ossのArchが gpt-oss なことと関係がある?

モデルは異なるが同様にOllamaでダウンロードしたモデルをLM Studioにリンクした際、 unknown model architecture が表示される問題が報告されている。
続いてgpt-oss-120bもダウンロードする。
ネットが弱くてちょくちょく中断する。気長に続けよう。

Ollama MLX対応
Claudeたちに調査させた時、OllamaはMLXを対応しているからおすすめと言われた。
しかし、実際ダウンロードして使ってみるとモデルがGGUFだった。
調べてみると、どうやら設定を追加してコンパイルする必要がある。
- For Mac users, Ollama is getting MLX support! : r/ollama
- Draft MLX go backend for new engine by dhiltgen · Pull Request #9118 · ollama/ollama
~せっかくなのでGGUFとMLXでどれくらい性能が変わるかもチェックしておく。~
将来的にMLX版が出た時のためにパフォーマンス測定方法を調査。
パフォーマンス測定方法
以下の適当なプロンプトでClaude, ChatGPT, Manus, Geminiに聞いてみる。
いろんなオープンウェイトモデルのトークン生成速度を比較したい。
どんな質問をするのが良いだろう。
業界で標準となっている評価方法があれば調べて教えて。
何かしらの入力を入れて、出力を得た時にeval rate xxx tokens/sという数値を得て、それを持って比較したい。
生成の確からしさは今回評価の対象外。
ChatGPT
決まりはない。プロンプト何パターンか用意し、それぞれ複数回試行して平均を取るのを推奨。
回答詳細
結論から言うと、
- 「eval rate xxx tokens/s」で比較するやり方自体は普通にみんなやってるけど
- 「この条件で測れ」が完全に標準化されているわけではなく、
- 実務的には MLPerf の指標 + 各種ライブラリ(vLLM, llama.cpp など)の慣習 を真似するのが一番“業界標準っぽい” です。(MLCommons)
以下、「どんな質問をするか」と「どう測るか」をセットでまとめます。
1. まず、何を揃えておけば“公平”になるか
必須で揃えておくと良い条件
-
ハード構成
- GPU 種類(例: A100 80GB x1, RTX 4090 x1 など)
- 精度・量子化(fp16 / bf16 / int4 など)
- バックエンド(vLLM / llama.cpp / TensorRT-LLM など)
-
ワークロードの種類
- 単一ユーザー・単一ストリーム(チャット用途)
- 多ユーザー・高並列(API サービス用途)
- どちらを見たいかを最初に決める。
-
トークン数
- 入力長:例)short 32 tok / mid 256 tok / long 1024 tok
- 出力長:例)一律
max_new_tokens=256(or 512, 1024 など) - 「だいたいこれぐらいで使う」という長さを基準に決める。
-
デコーディング設定
-
temperature,top_p,top_k/ greedy などを固定。 - 品質は今回無視なので、greedy か低 temperature にしておくとブレが減ります。
-
-
ウォームアップ
- 最初の 1〜2 リクエストは捨てて、それ以降を計測対象にする(キャッシュ・JIT の影響を除くため)。
2. 「どんな質問(プロンプト)を投げるのが良いか」
実は 質問の中身の意味はどうでもよくて、「長さとパターン」が揃っていれば OK です。
ただし「極端に単純な出力(例: aaaaa...)」だと実装によっては変な最適化が働く可能性があるので、現実的なテキストが無難です。
おすすめのやり方:3〜4種類の代表プロンプトを使う
例として:
-
長文要約パターン
-
入力: だいたい 512〜1024 トークン相当の日本語テキスト(ニュース記事やウィキペディア本文をコピペ)
-
プロンプト末尾に:
上の文章を要約してください。重要なポイントを箇条書きで5個程度にまとめてください。
-
-
コード生成パターン
-
入力:
あなたは熟練したソフトウェアエンジニアです。次の仕様を満たすPythonコードを書いてください。
- ○○を行う関数
- 単体テストを含めること
- コメントを多めに入れること
-
-
一般 QA パターン(短め)
-
入力:
次の質問に、300トークン以上の日本語で詳しく回答してください。
質問: 近年の大規模言語モデルの応用例を、産業別に説明してください。
-
-
超単調でない固定テキスト
-
入力: 適当なテキスト(例: ウィキペディア本文)を固定で貼る。
-
指示:
上記テキストの内容を踏まえて、関連する解説文を詳細に書いてください。日本語で500トークン以上出力してください。
-
ポイント
- 全モデルで、まったく同じテキスト+指示文を使う。
- 実際のユースケース(チャット中心 / コード多め…)に近いパターンを1〜2個選ぶ。
- 「必ず○○トークン以上出力」などと書いておくと、出力が短すぎて速度が測りにくい問題を防げます。
3. 業界で使われている“それっぽい”評価指標
完全に「これが唯一の標準」というものはないですが、インフラ業界だとだいたい下の 3 つで語られます:
-
TTFT (Time To First Token)
- リクエスト送信 → 最初のトークンが返ってくるまでの時間
- 体感の「サクッと返ってくるか」を左右する指標。(BentoML)
-
Eval rate / Decode TPS(生成トークン数 / 秒)
- 最初のトークン以降、デコードフェーズで1秒あたり何トークン生成したか。
- 裏では「output tokens per second」と呼ばれることが多いです。(OpenMetal IaaS)
-
Prompt TPS(入力処理トークン数 / 秒)
- 長いコンテキストをどれだけ速く食えるか。
- 生成速度より速いことが多い。(OpenMetal IaaS)
MLPerf Inference(MLCommons がやってる公式ベンチマーク)でも、
スループット(tokens/s や queries/s)とレイテンシが LLM の主な評価軸です。(MLCommons)
vLLM や llama.cpp、各種 GitHub ベンチ(GPU-Benchmarks-on-LLM-Inference など)も、
「固定プロンプト長・固定出力長で、平均 tokens/s を測る」というスタイルが定番になっています。(GitHub)
4. 実際に「eval rate xxx tokens/s」を出す手順(シンプル版)
単一プロンプト・単一ストリームの例
-
前提
- プロンプト: 上で決めた代表プロンプト 1つ
max_new_tokens = 256-
temperature = 0.0など固定
-
計測の仕方(擬似コードイメージ)
for i in 1..N_runs:
t0 = now()
stream = model.generate_stream(prompt, max_new_tokens=256)
t_first = None
tokens_generated = 0
for token in stream:
t = now()
if t_first is None:
t_first = t # TTFT用
tokens_generated += 1
t_end = t
TTFT = t_first - t0
eval_rate = tokens_generated / (t_end - t_first)
記録しておく
-
集計
-
最初の 1 run をウォームアップとして捨てる。
-
残りの run について
- TTFT の平均・中央値
- eval_rate(tokens/s)の平均・中央値
-
結果を「モデル × ハード構成 × 条件」で表にする。
-
多ストリーム / 高並列を見たい場合
-
例えば「同じプロンプトを並列 8 本投げる」などをし、
- システム全体での 総 tokens/s
- 1 リクエストあたりの平均 eval_rate
-
を測ると、実際の API サービスに近い数字になります(vLLM のベンチもだいたいこのノリ)。(VLLM Documentation)
5. まとめ:今回やりたいことに合わせると…
あなたのゴール:
「何か入力 → 出力を得たときに eval rate xxx tokens/s を出して、モデル間で比較したい」
「生成の確からしさは評価対象外」
に素直に合わせるなら、こんな設計が扱いやすいと思います:
-
代表プロンプトを 1〜3 種類決める(長さ違い+できれば実用途に近い内容)。
-
各プロンプトについて、
- 単一ストリームで TTFT & eval_rate
- 余裕があれば並列 8 / 16 本で総 tokens/s
-
全モデルで 同じ
- ハード
- 量子化設定
- バックエンド
- プロンプト
- デコーディング設定
で回す。
-
結果を表で比較
- 「短文チャット条件の eval_rate」
- 「長文要約条件の eval_rate」
など、ユースケース別にまとめる。
このあと、
- 実際に使うプロンプト文面を一緒に具体的に決める
- 計測スクリプト(例: Python + vLLM / llama.cpp CLI)を書き起こす
みたいなところまで落とし込みもできます。
「自分の環境は ○○(GPU/バックエンド)」という情報を教えてもらえれば、その前提でサンプルコードまで作るよ。
Gemini
重要な情報。
他にもTime to First Token (TTFT), Time Per Output Token (TPOT), Tokens Per Second (TPS) などいくつかの指標の提案。
他は、同じモデルを使ってハードウェアのパフォーマンスを評価する方向に行っている?求めているものとは違った。
回答詳細
オープンウェイト大規模言語モデル(LLM)における推論速度評価とパフォーマンスエンジニアリングに関する包括的調査報告書1. 序論:LLM推論パフォーマンスの現代的課題生成AIの急速な民主化に伴い、Llama 3、Mistral、Qwen、DeepSeekといった高性能なオープンウェイトモデル(Open-Weight Models)が利用可能となり、企業や研究者は独自のインフラストラクチャ上でこれらのモデルを運用する機会を得ている。しかし、この自由度は同時に、推論パフォーマンスの最適化という複雑なエンジニアリング課題をもたらした。プロプライエタリなAPI(OpenAIのGPT-4など)を利用する場合とは異なり、オープンモデルの運用においては、ハードウェア選定、推論エンジンの構成、量子化レベルの決定、そしてプロンプト設計に至るまで、すべての変数がシステムの応答速度とスループットに直接的な影響を及ぼす。ユーザーから提起された「オープンウェイトモデルのトークン生成速度を比較したい」という要望は、単なる数値の計測を超えた、LLM推論システムの深層的な理解を必要とするものである。業界標準の評価指標(eval rate)を正確に測定し、異なるモデル間での公平な比較を行うためには、推論プロセスの物理的な制約、特に「Prefill(プロンプト処理)」と「Decode(トークン生成)」という二つの異なるフェーズの挙動を理解し、それらを分離して評価する必要がある 1。また、現代のモデルが学習過程で獲得した「怠惰な生成(Lazy Generation)」の傾向を抑制し、決定論的なベンチマーク結果を得るためのプロンプトエンジニアリングも不可欠な要素となっている。本報告書は、LLMの推論速度を構成する理論的枠組み、業界標準の計測ツールとメトリクス、ハードウェアとソフトウェアの相互作用、そして信頼性の高いベンチマークを実施するための実践的方法論について、徹底的な調査と分析を行うものである。2. LLM推論の理論的枠組みとパフォーマンス特性「速さ」を定義するためには、LLMがテキストを生成する際の計算機科学的なメカニズムを分解する必要がある。一般的に語られる「トークン毎秒(Tokens Per Second: TPS)」という指標は、実際には性質の異なる二つの計算プロセスの複合結果であり、これらを混同することはベンチマークにおける最大の誤謬源となる。2.1 推論の二段階プロセス:PrefillとDecodeLLMの推論は、ユーザーが入力を送信した瞬間に始まる「Prefill(事前充填)」フェーズと、モデルが回答を生成し続ける「Decode(デコード)」フェーズに明確に分かれる。これらは計算資源に対する要求特性が根本的に異なるため、ベンチマークにおいては独立した指標として扱われるべきである 1。第一のフェーズである**Prefill(Prompt Processing)は、ユーザーが入力したプロンプト全体を一括で処理し、KVキャッシュ(Key-Value Cache)を構築する工程である。この段階では、入力されたすべてのトークンに対する計算を並列に行うことが可能であるため、GPUの演算能力(TFLOPS)が主要なボトルネックとなる「Compute-Bound(演算制約)」な特性を持つ 3。RAG(検索拡張生成)システムのように、数千トークンに及ぶドキュメントをコンテキストとして与える場合、このPrefill速度がシステムの初期応答時間(Time to First Token)を支配することになる。第二のフェーズであるDecode(Token Generation)**は、自己回帰的(Autoregressive)なプロセスである。モデルは直前に生成されたトークンと過去のコンテキストに基づいて、次のトークンを一つずつ生成する。このプロセスは本質的に直列的であり、前のトークンが確定するまで次のトークンの計算を開始することができない。技術的な観点から見ると、Decodeフェーズにおいては、たった一つのトークンを生成するためにモデルの全パラメータ(重みデータ)をVRAMから演算ユニットへ転送する必要がある。そのため、このフェーズの速度はGPUの演算能力ではなく、メモリ帯域幅(Memory Bandwidth)によって制限される「Memory-Bound(メモリ帯域制約)」な特性を示す 2。ユーザーが体感する「生成速度」は主にこのDecodeフェーズのTPSに依存するが、システム全体の評価としては、Prefillの処理能力も同様に重要である。特に長い文脈を扱うアプリケーションでは、Prefillが遅いとユーザーは生成が始まるまでに長い待ち時間を強いられることになる。2.2 ルーフラインモデルとバッチサイズの影響推論パフォーマンスを最大化するためには、ルーフラインモデルに基づく理解が不可欠である。これは、システムの理論上の最大性能が、演算性能とメモリ帯域幅のどちらによって制限されているかを判定するモデルである。バッチサイズ(同時に処理するリクエスト数)が小さい場合、特にバッチサイズが1のシングルユーザー環境では、システムは圧倒的にメモリ帯域制約の状態にある。この状態での理論上の最大トークン生成速度(TPS)は、以下の式で概算できる。
パラメータの解説:-m: GGUF形式のモデルファイルを指定する。-p: プロンプト(入力)のトークン長。複数の値をカンマ区切りで指定することで、入力長によるPrefill速度の変化(
--model meta-llama/Llama-3-8b-instruct
--input-len 256
--output-len 256
--num-prompts 100
--tensor-parallel-size 1
方法論の特徴:合成データによる負荷試験: --input-len と --output-len を指定することで、ランダムなトークン列を生成し、言語的な意味内容に左右されない純粋なエンジンの処理能力を測定できる 14。同時接続数の検証: --num-prompts を調整することで、サーバーに対する負荷を変えながら、レイテンシとスループットのトレードオフ曲線を描くことができる。これは、実運用時のキャパシティプランニングにおいて極めて重要なデータとなる 17。エンジンの比較: 同じハードウェア上で llama.cpp と vLLM を比較した場合、バッチサイズが1の時は llama.cpp が低遅延である場合が多いが、同時リクエストが増えるにつれて vLLM のスループットが圧倒的に優位になるという特性がある 15。4.3 その他の高度なベンチマークツールより包括的な評価を行うために、以下のツールも広く利用されている。GenAI-Perf (NVIDIA): NVIDIAが提供するエンタープライズ向けのツールで、Triton Inference Server上のモデルに対して負荷試験を行う。TTFT、ITL、エンドツーエンドレイテンシなど、微細なメトリクスを自動的に集計し、詳細なレポートを生成する機能を持つ 3。LLMPerf (Ray Project): Rayフレームワーク上で動作し、複数のAPIプロバイダーやローカルモデルに対して統一的な基準でベンチマークを行うためのツールセットである。入力トークン数と出力トークン数の平均と分散を指定し、より現実に近いトラフィックパターンを模倣することができる 20。5. プロンプトエンジニアリングによる評価の安定化ユーザーの質問にある「どんな質問をするのが良いか」という点は、ベンチマークの信頼性を左右する重要な要素である。自然言語による質問(例:「詩を書いて」)は、モデルの確率的な挙動により生成されるトークン数が毎回大きく変動するため、速度計測には不向きである。生成トークン数が異なれば、PrefillとDecodeの比率が変わり、TPSの平均値が歪んでしまうからである 22。5.1 決定論的なプロンプト設計ベンチマーク用のプロンプトは、モデルが「何を生成するか」ではなく「どれだけ生成するか」を厳密に制御できるものでなければならない。以下のパターンが推奨される。反復指示(Repetition Prompts):モデルに対して特定のフレーズを回数指定で繰り返させる。これにより、計算ロジック(推論)の負荷を最小限に抑え、純粋なメモリアクセス速度を測定できる。推奨プロンプト例: 「'The quick brown fox jumps over the lazy dog' というフレーズを正確に20回繰り返しなさい。途中で止めずに、全文を出力してください。」このプロンプトは、出力トークン数を予測可能にし(約180〜200トークン)、ハルシネーションのリスクも低い 23。カウントアップ指示(Counting Prompts):単純な数列の生成を指示する。推奨プロンプト例: 「1から100まで、1刻みで数字を出力してください。数字はカンマで区切り、それ以外の文字は出力しないでください。」数値の羅列はトークン化の効率が良く、モデルが「怠惰」になりにくい特性がある 25。合成ペイロード(Synthetic Payloads):vLLM のベンチマークスクリプトのように、意味のあるテキストではなく、指定された長さのランダムなトークンID列を直接リクエストとして送信する方法。これが最も正確にハードウェア性能を反映する 14。5.2 「怠惰な生成(Lazy Generation)」への対策最新のモデル(GPT-4 TurboやLlama 3のInstructモデルなど)は、RLHF(人間からのフィードバックによる強化学習)によって「簡潔な回答」をするように調整されている。そのため、「長い文章を書いて」と指示しても、勝手に要約したり、途中で生成を打ち切ったりする現象(Lazy Generation)が発生しやすい 26。これはベンチマークにおいて致命的である。対策:システムプロンプトによる制約: 「あなたは冗長なテキスト生成器です。ユーザーの指示した長さを厳密に守り、絶対に要約や省略を行わないでください」といった強力な指示をシステムプロンプトに含める 28。APIパラメータによる強制: API経由でベンチマークを行う場合、min_tokens パラメータを設定することで、モデルがEOS(終了)トークンを出そうとしても強制的に生成を継続させることができる 17。「怠惰」対策プロンプトの活用: 「深呼吸をして、一歩ずつ考えましょう」や「これは私のキャリアに関わる重要なタスクです」といった感情的な重み付けを行うプロンプト(Emotional Prompting)が、モデルのパフォーマンス維持に有効であるという研究結果もある 27。6. ハードウェア構成と量子化の影響分析推論速度はソフトウェアだけでなく、ハードウェアの物理特性とモデルのデータ表現形式(量子化)に強く依存する。ここでは、これらの変数が具体的にどのように速度に影響するかを分析する。6.1 量子化(Quantization)とメモリ帯域幅のトレードオフユーザーが比較を行う際、FP16(16ビット浮動小数点)モデルとQ4(4ビット整数)モデルの間で劇的な速度差を目にするはずである。速度向上のメカニズム: 前述の通り、Decodeフェーズはメモリ帯域制約である。モデルを4ビットに量子化すると、ファイルサイズは16ビット時の約1/4になる。これは理論上、同じメモリ帯域幅で4倍の速度でデータを読み込めることを意味し、推論速度は飛躍的に向上する 29。コンシューマーGPUでの顕著な効果: RTX 3090/4090のようなコンシューマー向けハイエンドGPUは、演算性能に対してメモリ帯域幅が相対的に不足している場合が多い。そのため、量子化による帯域幅の節約効果がダイレクトに速度向上として現れる。ベンチマーク結果では、Q4モデルはFP16モデルの2倍以上のTPSを記録することが一般的である 31。計算オーバーヘッド: 量子化モデルは、計算を行う直前にデータを低精度から高精度へ戻す(デクオンタイズ)処理が必要となる。古いGPUやCPU推論ではこのオーバーヘッドが無視できない場合があるが、近年のGPUにおいてはメモリ転送時間の短縮効果がこの計算コストを大きく上回る 32。6.2 ハードウェア種別による特性:H100 vs RTX 4090興味深い知見として、シングルユーザー(バッチサイズ1)での推論においては、データセンター向けの最高級GPUであるNVIDIA H100よりも、コンシューマー向けのRTX 4090の方が「体感速度(Latency)」で勝るケースが存在する 34。要因: H100は巨大なバッチ処理(多数のユーザーを同時に捌く)に最適化されており、広帯域なHBM3メモリを持つ一方で、コアの動作クロックは必ずしも最高速ではない。対してRTX 4090は非常に高いブーストクロックで動作するため、並列度の低いタスク(一人のユーザーのためのトークン生成)では、その高いクロック周波数が低遅延に寄与する。選定指針: 個人の研究用やローカルアシスタント用途であればRTX 4090等のコンシューマーGPUがコストパフォーマンスに優れる一方、商用APIとして多数のアクセスを捌く場合は、H100やA100の広帯域メモリと相互接続(NVLink)によるスループット性能が必須となる 6。6.3 KVキャッシュとメモリ管理生成するコンテキストが長くなるにつれて、KVキャッシュ(過去の計算結果の保存領域)がVRAMを圧迫し始める。KVキャッシュが枯渇すると、システムは一部のキャッシュを破棄して再計算を行うか、スワップアウトを行う必要が生じ、速度が劇的に低下する。PagedAttentionの影響: vLLM が採用しているPagedAttentionは、OSのメモリページングのようにKVキャッシュを非連続なメモリブロックに配置することで、メモリの断片化(フラグメンテーション)を防ぐ。これにより、同じVRAM容量でもより長いコンテキストや大きなバッチサイズを扱うことができ、結果として高いスループットを維持できる 14。KVキャッシュ量子化: 最新の最適化技術として、モデルの重みだけでなく、このKVキャッシュ自体をFP8やINT4に量子化する手法が登場している。これにより、長文脈生成時のメモリ消費を削減し、帯域幅のボトルネックを緩和することでTPSを向上させることが可能である 2。7. 結論と実践的推奨事項「オープンウェイトモデルのトークン生成速度を比較したい」という目的を達成するための、業界標準に基づいた最終的な推奨事項は以下の通りである。評価指標の分離: 「速さ」を一括りにせず、**Prefill TPS(プロンプト処理速度)とDecode TPS(生成速度)**を分けて計測・記録すること。ユーザー体験には後者が、RAGなどのシステム性能には前者が影響する。適切なツールの選定:ローカル/エッジ環境の比較: llama.cpp の llama-bench を使用し、-p(プロンプト長)と -n(生成長)を固定して計測する。サーバー/API環境の比較: vLLM の benchmark_throughput.py を使用し、同時リクエスト数(Concurrency)を変化させながらスループットの飽和点を計測する。プロンプトの標準化: 自然言語による曖昧な指示を避け、「固定長のトークン列を生成させる」あるいは「特定のフレーズを反復させる」決定論的なプロンプトを使用する。これにより、モデルの「創造性」や「怠惰さ」による計測誤差を排除する。条件の明記: ベンチマーク結果を共有する際は、使用したハードウェア(GPU型番、枚数)、モデルの量子化レベル(Q4_K_Mなど)、およびバックエンド(vLLM v0.x.x 等)を必ず併記する。これらの変数が一つでも異なれば、数値の直接比較は無意味となる。以上の方法論を適用することで、単なる「体感」や不正確なストップウォッチ計測ではなく、エンジニアリングの意思決定に資する信頼性の高いパフォーマンスデータを得ることが可能となる。付録:主要ベンチマークコマンド クイックリファレンスシナリオA:ローカルGPUでの生成速度(Decode TPS)を知りたい場合ツール:llama.cppBash# プロンプト処理(512トークン)後の生成(128トークン)速度を測定
./llama-bench -m model.gguf -p 512 -n 128
出力の eval 列の t/s を参照 10。シナリオB:APIサーバーとしての最大処理能力(Throughput)を知りたい場合ツール:vLLMBash# 入力128トークン、出力128トークンのリクエストで負荷をかける
python3 benchmarks/benchmark_throughput.py --model <モデル名> --input-len 128 --output-len 128
出力の tokens/s(全ユーザー合計)を参照 36。
Manus
Time to First Token (TTFT), Output Tokens Per Second (Output TPS) を挙げる。
テスト用のプロンプトには以下のような条件。
- トークン長の固定
- 多様なタスク
ollama-benchmarkの紹介があるが、これもGeminiと同じで複数のモデルを評価するもの。
回答詳細
オープンウェイトモデルのトークン生成速度比較:標準的な評価方法と推奨事項
はじめに
オープンウェイトの大規模言語モデル(LLM)のトークン生成速度を比較するにあたり、業界で標準とされている評価方法と、その際に用いるべき質問(プロンプト)について調査しました。本レポートでは、信頼性の高い比較を実現するための主要な評価指標、具体的なベンチマーク手法、そして適切なプロンプトの設計について、詳細な推奨事項を提示します。
1. トークン生成速度の標準的な評価方法
LLMの性能評価において、生成される内容の確からしさと並び、その応答速度は極めて重要な要素です。特に、ユーザー体験に直結するトークン生成速度の評価には、業界で広く採用されている標準的な指標と手法が存在します。
主要な評価指標
トークン生成速度を評価する上で最も重要な指標は以下の2つです。これらの指標を総合的に評価することで、モデルの応答性能を多角的に理解することができます。
| 評価指標 | 説明 |
|---|---|
| Time to First Token (TTFT) | ユーザーがプロンプトを送信してから、モデルが最初のトークンを生成して返すまでの時間です。単位は秒(s)またはミリ秒(ms)で、この値が小さいほど、ユーザーは「すぐに反応が返ってきた」と感じます。 |
| Output Tokens Per Second (Output TPS) | 最初のトークンが生成された後、後続のトークンが1秒あたりに何個生成されるかを示す速度です。単位は tokens/s で表され、この値が大きいほど、文章全体の生成が高速であることを意味します。 |
ユーザーが求める「eval rate xxx tokens/s」という数値は、主に Output TPS に該当します。これはモデルの純粋な生成能力を示す指標です。
標準的なワークロード(テスト条件)
公平な比較を行うためには、全てのモデルに対して同じ「ワークロード」、すなわち同じ長さの入力(プロンプト)を与え、同じ長さの出力を生成させる必要があります。Artificial Analysis などの業界標準的なベンチマークでは、以下のようなワークロードが定義されています [1]。
| ワークロード種別 | 入力トークン数(目安) | 出力トークン数(目安) | 用途 |
|---|---|---|---|
| 100 input token | 100 | 300 | 短い指示への応答テスト |
| 1k input token | 1,000 | 1,000 | 標準的なベンチマーク |
| 10k input token | 10,000 | 1,500 | 長文の要約や分析 |
| 100k input token | 100,000 | 2,000 | 非常に長い文書の処理 |
特に、入力1,000トークン、出力1,000トークンのワークロードは、多くのベンチマークで標準的な設定として採用されており、異なるモデル間の性能比較を行う際の基準として適しています。
2. 比較に用いるべき質問(プロンプト)の考え方
トークン生成速度の測定が目的の場合、プロンプトの「内容」そのものよりも、その「長さ(トークン数)」が重要になります。一貫性のある比較を行うためには、全ての評価対象モデルに対して、同じトークン長のプロンプトを使用することが不可欠です。
プロンプト設計の推奨事項
-
トークン長を固定する: 最も重要なのは、入力と出力のトークン長を固定することです。例えば、「入力1,000トークン、出力1,000トークン」のように厳密に定義します。
-
多様なタスクを模したプロンプトを用意する: 単一の単純なプロンプトでは、モデルの特定の側面に偏った結果が出る可能性があります。より汎用的な性能を測るため、以下のような多様なタスクを想定したプロンプトを複数用意し、その平均値を取ることを推奨します。
- 長文要約: ある程度の長さの記事やレポートを渡し、指定した文字数(トークン数)で要約させる。
- コード生成: 特定の機能を持つプログラム(例: 「クイックソートのアルゴリズムをPythonで実装してください」)を生成させる。
- 物語生成: 「科学者がタイムマシンを発明した後の世界を描写してください」といった創造的な文章を生成させる。
- 技術的な解説: 「大規模言語モデルのTransformerアーキテクチャについて、その主要な構成要素と仕組みを解説してください」といった専門的な説明を求める。
-
ベンチマークツールのデフォルトプロンプトセットを活用する:
ollama-benchmark[2] のようなツールには、分析的推論、創造的執筆、複雑な分析など、様々な能力をテストするためのプロンプトがデフォルトで用意されています。これらを参考に、独自のプロンプトセットを構築するのも良いでしょう。
3. 推奨する評価手順
以上の点を踏まえ、オープンウェイトモデルのトークン生成速度を比較するための具体的な手順を以下に示します。
-
評価対象モデルの選定: 比較したいオープンウェイトモデルをリストアップします。
-
ベンチマークツールの導入:
llama.cpp[3] やOllama[2] に付属するベンチマークツール、あるいはNVIDIAが提供するGenAI-Perf[4] などの標準的なツールを導入します。これらのツールは、TTFTやTPSを自動で計測してくれます。 -
評価環境の統一: 全てのテストを同じハードウェア(GPU、CPU、メモリ)およびソフトウェア環境で実行します。これにより、環境差による測定誤差を排除します。
-
ワークロードとプロンプトの決定: 標準的な「入力1,000トークン、出力1,000トークン」のワークロードを採用し、前述の「プロンプト設計の推奨事項」に基づいて、複数のタスクを模したプロンプトを準備します。
-
ベンチマークの実行と記録: 各モデルに対して、準備したプロンプトを複数回(例えば5回以上)実行し、TTFTとOutput TPSの値を記録します。複数回実行することで、測定のばらつきを抑え、より信頼性の高い平均値を得ることができます。
-
結果の集計と比較: モデルごとに得られたOutput TPSの平均値を算出し、一覧表にまとめます。これにより、どのモデルが最も高速にトークンを生成できるかを客観的に比較することが可能になります。
まとめ
オープンウェイトモデルのトークン生成速度を公平かつ正確に比較するためには、**標準化された評価指標(TTFT, Output TPS)と一貫したワークロード(特にトークン長)**を用いることが不可欠です。プロンプトの内容自体よりも、その長さを揃えることに注力し、複数の異なるタスクを模したプロンプトで複数回測定を行うことで、信頼性の高いベンチマークが実現できます。本レポートで提示した手順と推奨事項が、貴殿のモデル評価の一助となれば幸いです。
参考文献
[1] Artificial Analysis. "Language Model API Performance Benchmarking Methodology." Accessed November 25, 2025. https://artificialanalysis.ai/methodology/performance-benchmarking
[2] GitHub - larryhopecode/ollama-benchmark. "Ollama based Benchmark with detail I/O token per second." Accessed November 25, 2025. https://github.com/larryhopecode/ollama-benchmark
[3] Medium. "Benchmarking LLM Performance: Token Per Second (TPS), Time to First Token (TTFT), and GPU Usage." Accessed November 25, 2025. https://rumn.medium.com/benchmarking-llm-performance-token-per-second-tps-time-to-first-token-ttft-and-gpu-usage-8c50ee8387fa
[4] NVIDIA Developer. "LLM Inference Benchmarking: Fundamental Concepts." Accessed November 25, 2025. https://developer.nvidia.com/blog/llm-benchmarking-fundamental-concepts/
Claude
指標として
- TTFT (Time to First Token)
- ITL/TPOT (Inter-Token Latency)
- Output Throughput
- RPS (Requests Per Second)
を挙げる。
ベンチマークにはタスクとして
- チャット/会話
- コード生成
- RAG/要約
- 推論モデル
を挙げる。
具体例としてllama-benchとvLLMのbenchmark_serving.pyを挙げる。
回答詳細
LLMトークン生成速度ベンチマーク:業界標準と実践ツール
MLPerfのtokens/sec指標がLLM推論スループット測定の業界標準となっており、vLLMのbenchmark_serving.pyとNVIDIAのGenAI-Perfが最も広く使われている実用ツールです。オープンウェイトモデル間の公平な比較には、ShareGPT会話データまたは固定長の合成プロンプト(一般的に入力512トークン、出力128〜256トークン)を使用し、生のスループットに加えてTime to First Token(TTFT)とInter-Token Latency(ITL)を測定します。品質ベンチマークとは異なり、スループットテストではignore_eos=trueを設定して一貫した出力長を強制し、30秒以上のウォームアップを実行し、最低100リクエストでp50/p90/p99パーセンタイルを報告する必要があります。
MLPerfがLLMスループット測定の権威ある標準を確立
MLCommonsのMLPerf Inferenceベンチマークは、125以上のメンバー組織が使用する最も厳格な標準化手法です。LLMでは入力/出力長が可変であるため、queries-per-secondではなくtokens per secondを主要指標として採用しています。
MLPerfは2つの異なる測定フェーズを定義しています:
- Prefillフェーズ:入力トークンを処理して最初の出力トークンを生成
- Decodeフェーズ:後続のトークンを順次生成
現在のMLPerf Inference v5.1ベンチマークには、以下のモデルが含まれています:
| モデル | パラメータ数 | データセット | トークン設定 |
|---|---|---|---|
| Llama 3.1 8B | 8B | CNN-DailyMail | 平均778入力 / 73出力 |
| Llama 2 70B | 70B | OpenORCA | 最大1,024入力 / 1,024出力 |
| Mixtral 8x7B | 47B MoE | OpenORCA, GSM8K, MBXP | 最大2,048シーケンス |
| Llama 3.1 405B | 405B | LongBench, RULER, GovReport | 平均9,400入力 / 680出力 |
| DeepSeek-R1 | 671B MoE | Math, QA, Code | 平均出力3,880(最大20K) |
MLPerfはLoadGenシステムによる公平性を担保しています。「Closed Division」では同一モデル・同一前処理が必須で、精度はFP32参照性能の99%以内を維持する必要があります。Serverシナリオではレイテンシ制約があり、Llama 2 70B InteractiveではTTFT ≤ 450ms、TPOT ≤ 40ms(最低25 tokens/sec相当)が要求されます。
測定すべき4つの必須指標
業界では以下の4つの補完的な指標が標準となっています:
1. Time to First Token(TTFT)
リクエスト送信から最初の出力トークンまでのレイテンシ。プロンプト処理効率を測定し、ストリーミングアプリケーションの体感応答性に重要です。
2. Inter-Token Latency(ITL)/ Time Per Output Token(TPOT)
デコードフェーズでの平均生成速度。標準的な計算式:
ITL = (End-to-End Latency - TTFT) / (Output Tokens - 1)
注意:ツールによって計算方法が異なります。GenAI-Perfは最初のトークンを分母から除外し、LLMPerfはTTFTを計算に含めるため、ツール間比較には方法論の確認が必要です。
3. Output Token Throughput
1秒あたりの生成トークン数。通常はシステムレベルで全並行リクエストを対象に測定します。バッチ処理では主要指標、インタラクティブ用途ではリクエスト単位のスループットが重要です。
4. Request Throughput(RPS)
1秒あたりの完了リクエスト数。可変長応答での現実的なワークロード下でのシステム容量を理解するのに有用です。
標準的な報告内容:p50(中央値)、p90、p95、p99パーセンタイル
ShareGPTと合成プロンプトが実用的なベンチマークを支配
ShareGPTデータセット(約70KのChatGPT会話)は、現実的なワークロードシミュレーションのデファクトスタンダードとなっています。vLLM、SGLang、Hugging Faceのinference-benchmarkerで使用され、自然な入出力長分布を提供します。制御された実験には、設定可能な長さの合成プロンプトが正確な再現性を実現します。
ユースケース別の推奨入出力設定
| ユースケース | 入力トークン | 出力トークン | 典型的な比率 |
|---|---|---|---|
| チャット/会話 | 50-200 | 50-200 | 約1:1 |
| コード生成 | 100-512 | 500-2,000 | 1:4以上 |
| RAG/要約 | 2,000-4,000 | 100-500 | 4:1 |
| 推論モデル | 100-500 | 1,000-10,000 | 1:10以上 |
業界標準のベンチマーク設定
- 128×128:短いインタラクション
- 512×128:典型的なチャット
- 1024×1024:長文コンテキスト
- 2048×256:ドキュメント処理
Databricksは典型的なRAGワークロードとして2,000入力 / 200出力トークンをデフォルトにしています。
公平な比較のための重要事項:モデルが自然なEOSトークンで早期終了するのを防ぐため、必ずignore_eos=trueを設定して一貫した出力長を強制してください。
vLLMとGenAI-Perfが最も包括的なベンチマークツール
vLLM benchmark_serving.py
サービングスループット測定で最も広く採用されているオープンソースソリューション。複数のバックエンド(vLLM、TGI、LMDeploy、SGLang、TensorRT-LLM)をサポートし、TTFT、TPOT、ITL、パーセンタイル詳細を提供します。
python benchmarks/benchmark_serving.py \
--backend vllm --model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name random --random-input-len 512 --random-output-len 256 \
--num-prompts 1000 --max-concurrency 64 \
--percentile-metrics ttft,tpot,itl,e2el --save-result
NVIDIA GenAI-Perf
最も本番環境向けのオプション。スライディングウィンドウ技術を使用してウォームアップとクールダウン期間を自動的に除外します。OpenAI互換APIをサポートし、標準的なレイテンシ/スループット測定に加えてGPU固有の指標を提供します。
llama.cpp llama-bench
ローカル推論性能に特化。プロンプト処理(PP)とテキスト生成(TG)を分離して測定します。デフォルト設定はPP512(512プロンプトトークン)とTG128(128生成トークン)で5回繰り返し。ただし、現実的なプロンプトではなくランダムトークンシーケンスを使用し、TTFTやサーバーシナリオは測定しません。
TensorRT-LLM trtllm-bench
NVIDIA最適化デプロイメントに最適。GPUごとの詳細なスループット指標と、TTFTとTPOT両方の包括的なパーセンタイル詳細を提供します。
ウォームアップと統計的厳密性が重要
適切なウォームアップは、CUDAグラフコンパイル、GPUメモリアロケーション安定化、KVキャッシュプライミング効果を排除します。
標準的なウォームアップ要件
- 最低30〜60秒、または
- 並行度の3倍のリクエスト数を測定前に破棄
GenAI-Perfはスライディングウィンドウ分析で自動化:3回の連続測定間隔(デフォルト各10秒)を取り、max/min比率が許容範囲内に収まることを確認してから結果を安定と判定します。vLLMはメインベンチマーク前に単一プロンプトの初期テストを実行します。
統計的有意性の要件
- 設定ごとに最低100リクエスト
- 3〜5回の独立実行で結果を平均化
- 最低60〜120秒の実行時間
- 平均値とともに標準偏差を報告(llama-benchは
162.54 ± 1.70 t/sのように出力)
並行度スイープが必須
1、2、4、8、16、32、64、128の並行リクエストでテストし、スループットのスケーリングを理解します。モデルはbatch=1で75 tokens/secでも、batch=384で4,600 tokens/secを達成することがあり、単一リクエストベンチマークはシステム容量を大幅に過小評価します。
コミュニティリーダーボードが標準化ベンチマークのギャップを埋める
Hugging Face LLM-Perf Leaderboard
Optimum-Benchmarkを使用してハードウェア構成全体でレイテンシ、スループット、メモリをベンチマーク。Open LLM Leaderboardは品質指標のみに焦点を当てており、推論速度は意図的に分離されています。
Anyscale LLMPerf
APIプロバイダー比較の標準となっています(github.com/ray-project/llmperf)。550入力 / 150出力トークンで150リクエストを使用。関連リーダーボードは毎週更新され、商用プロバイダー間のランキングを提供します。
Artificial Analysis
100以上のモデルを出力速度、TTFT、価格で比較するサードパーティベンチマークを提供(artificialanalysis.ai)。標準化されたテストが実行不可能な場合のプロバイダー間比較に有用です。
公平なクロスモデル比較のためのチェックリスト
オープンウェイトモデル間で意味のある比較を可能にする有効なスループットベンチマークのために:
- 正確なトークン長を指定:曖昧な記述ではなく「512入力、256出力トークン」と報告
- ignore_eos=trueを使用:モデルの早期終了を防ぎ、比較不能な出力長を防止
- ハードウェアを完全に記載:GPUタイプ、数、メモリ、ドライバーバージョン
- 量子化を文書化:FP16/BF16/FP8/INT4は結果に大きく影響
- ウォームアップを含める:30秒以上または並行度の3倍のリクエストを破棄
- パーセンタイルを報告:平均とともにp50、p90、p95、p99
- 並行度設定を記載:単一リクエストとバッチスループットは異なる指標
- 一貫したトークナイザーを使用:異なるトークナイザーは同一テキストで異なるトークン数を生成
- バッチサイズを文書化:max_num_seqsと関連スケジューラー設定はスループットに影響
- 十分な実行時間:最低60秒、設定ごとに100以上のリクエスト
結論
LLMスループットベンチマークのエコシステムは大きく成熟し、MLPerfが権威ある標準を提供し、vLLM/GenAI-Perfがこれらの方法論を実装する実用ツールを提供しています。重要な洞察は、単一の指標では不十分ということです。本番環境での意思決定には、応答性のためのTTFT、ストリーミング品質のためのITL、容量計画のための総合スループットの理解が必要です。
ShareGPTは現実的なワークロードを提供し、合成プロンプトは制御された実験を可能にします。最も重要なのは、ウォームアップ処理、EOSトークンの動作、パーセンタイル報告などの方法論の詳細が、結果が意味あるものか誤解を招くものかを決定するということです。
オープンウェイトモデルをベンチマークする研究者にとって、vLLMのbenchmark_serving.pyとMLPerfの報告標準を組み合わせることで、収集が実用的でコミュニティ全体で比較可能な結果が得られます。
複数回llama-benchが推奨されたが、ggufにしか使えないのでは?
測定結果
そんなに厳密にやるつもりはないので、以下の質問を3回ずつ聞くこととする。
AI for Scienceについて詳しく解説して
とりあえずGGUFのToke per second値をメモしておく。
| eval rate | gpt-oss-20b (GGUF) | gpt-oss-20b (MLX) | gpt-oss-120b (GGUF) | gpt-oss-120b (MLX) |
|---|---|---|---|---|
| 1 | 56.91 | 43.59 | ||
| 2 | 61.24 | 44.39 | ||
| 3 | 62.21 | 32.28 | ||
| average | 60.12 | - | 40.09 | - |
OllamaをOpen AI APIの代わりとして使う
Ollamaをインストールすると、Ollama APIが http://localhost:11434/api/ で公開される。
curlで直接叩くことができる。
curl http://localhost:11434/api/generate -d '{
"model": "gpt-oss:20b",
"prompt": "Why is the sky blue?"
}'
{"model":"gpt-oss:20b","created_at":"2025-11-25T08:41:10.631769Z","response":"","thinking":"The","done":false}
{"model":"gpt-oss:20b","created_at":"2025-11-25T08:41:10.64757Z","response":"","thinking":" user","done":false}
{"model":"gpt-oss:20b","created_at":"2025-11-25T08:41:10.663153Z","response":"","thinking":" asks","done":false}
{"model":"gpt-oss:20b","created_at":"2025-11-25T08:41:10.678266Z","response":"","thinking":":","done":false}
...
{"model":"gpt-oss:20b","created_at":"2025-11-25T08:41:27.364611Z","response":"","done":true,"done_reason":"stop","context":[200006,17360,200008,..., 76268,13],"total_duration":20587542500,"load_duration":3385368291,"prompt_eval_count":73,"prompt_eval_duration":394531500,"eval_count":1082,"eval_duration":16576433972}
LiteLLMから利用してみる。Pythonファイルを作成。
from litellm import completion
response = completion(
model="ollama/gpt-oss:20b",
messages=[{ "content": "respond in 20 words. who are you?","role": "user"}],
api_base="http://localhost:11434"
)
print(response)
python use_ollama_via_litellm.py
ModelResponse(id='chatcmpl-318bae19-aa78-49f7-8d96-7b3b66a269cc', created=1764060692, model='ollama/gpt-oss:20b', object='chat.completion', system_fingerprint=None, choices=[Choices(finish_reason='stop', index=0, message=Message(content='I’m ChatGPT, an AI language model developed by OpenAI. I help answer questions, create content, and assist with daily tasks.', role='assistant', tool_calls=None, function_call=None, provider_specific_fields=None, reasoning_content=None))], usage=Usage(completion_tokens=318, prompt_tokens=80, total_tokens=398, completion_tokens_details=None, prompt_tokens_details=None))
OK。いい感じ。
まとめ
紆余曲折あったが理解は深まった。
- Gollamaを使ってOllamaとLM Studioでモデルを共有
- LiteLLMからOllamaを利用
Next stepとしてはGeminiが提案したアーキテクチャのうち、LiteLLMをプロキシサーバーとして運用するところをやりたい。
- インフラ: Mac Studio M3 Ultra (128GB RAM想定)
-
モデル実行層: Ollama
- 役割: 純粋な推論エンジンの提供
- 設定:
OLLAMA_HOST=0.0.0.0で組織内ネットワークからの接続を受け付ける(またはリバースプロキシ経由)
-
ミドルウェア層: LiteLLM (Proxy Server)
- 役割: モデル抽象化、ログ収集の集約点、OpenAI互換APIの提供
- 接続: Ollamaへリクエストを転送
- ログ: ここでユーザーID、会話履歴をキャプチャし、可視化サービス(Langfuse/Helicone等)へ送信
-
アプリケーション層 (Backend): LangGraph / Google GenAI SDK
- 役割: エージェントの思考ロジック、ツール実行、RAG(組織内情報検索)の制御
- 接続: LiteLLMのAPIエンドポイントを「OpenAI」として叩く
-
フロントエンド層: Open WebUI / Chainlit
- 役割: UI提供、ユーザー認証(OAuth/SSO)、チャット画面
- 接続: アプリケーション層のAPIへ接続
Next