最近のモチベーション
- 生成AIの導入支援において、クローズドなモデルの比較検証を行うことが多い
- 行うことはそれほど難しくないのだが、
- 各社のモデル登場スピードが早く、比較対象が多い(気がつけば、アレも!となる)
- input/中間/outputでちょっとした処理や連携が必要
- ソースは外部サービスのストレージ とか
- 中間の結果は別でも見比べたいから、〇〇にも蓄積 とか
- 検証の初回~中期の評価は定性的な評価がマストと感じる
- いきなり定量的に行える課題はひと握り
- 数値化や指標化するにもプロセスの棚卸しや言語化が必要
- 評価軸は抑えども、やっぱり人手で1シートにまとまった内容を見て評価する必要がある(ことが多い)
- いきなり定量的に行える課題はひと握り
そろそろワークフロー使いたい
- 検証自体は1スクリプトで十分書ける
- Langchainなどフレームワークがあれば、モデル間の差異を感じずにコードが書ける
- 少し前は新しいものとして、キャッチアップも含めて楽しくコードを書いていたが、単純なスクリプトには飽きてきた
- あと、ライブラリ内で廃止になる要素も多く、少し時間が立って気軽にversion-upできないのも地味に面倒になってきた
- Langsmithなどを使って中間やログ保持、評価プロセスを回す
- 全体のフロー構築者やエンジニアが状態確認やメンテを行う分には問題ないが、第三者のビジネスユーザーや評価者に見てもらうには少しハードルが高い、見たい人が増えている
- GUI上での表現や利用を、リッチにしたい
Dify vs n8n
- どちらも日常のユースケースなら十分使いやすい
- 個人的には、DifyはTheローコードで、n8nはもう少し技術要素があって、日常的に自動化したり(そういうサービスを触ったりするのも好きな人で)、ちょっとしたスクリプトを書いたりする人向けな印象
- なので、細かい分岐や制御がなく、LLMに処理させてその結果を使いたいという観点であれば、Difyは直感的に組める
- n8nは外部連携(アプリ)がそれなりにあるのがありがたい、あとサービス開発者としてなかなか目が向きにくいフロー自体の拡張や制御(分岐やWait)があり、そのあたりとAgentを組み合わせられるのはありがたい、ただ設定はそれなりに面倒である
n8nを使う
検証であれば、Dockerを使って立てる
n8nでワークフローを組む
例えば下記のようなワークフローを組んでみた
PDFはソニー決算報告書を利用し、XにPOSTするために140文字の要約を依頼するものとした
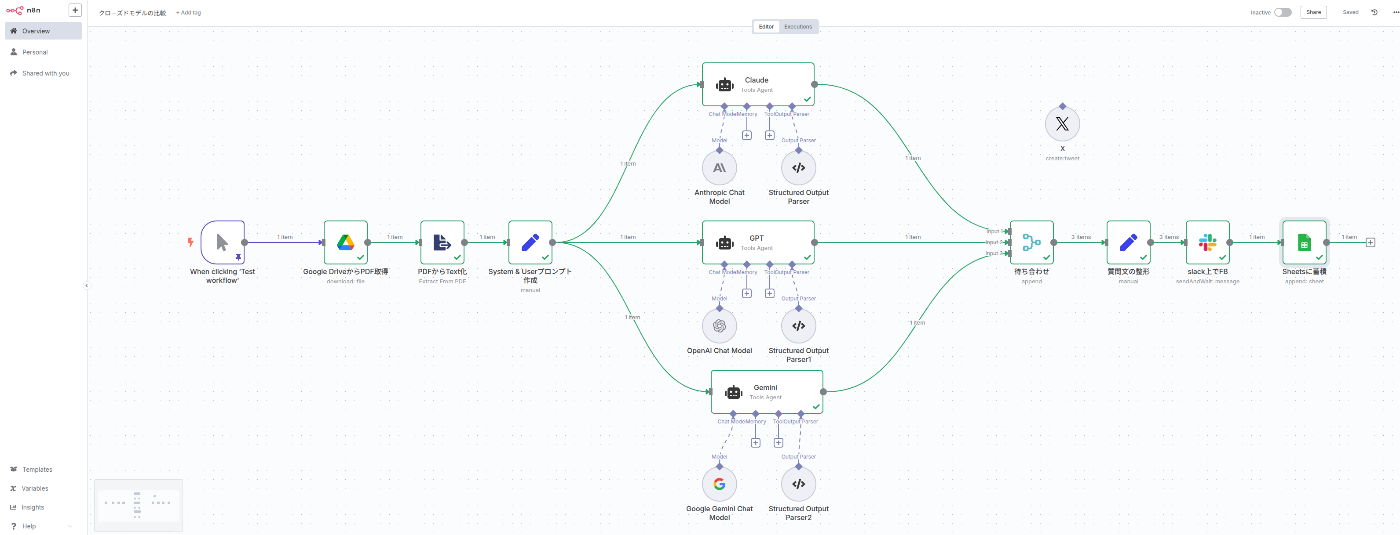
- Google Drive上の任意のPDFを読み取り
- PDFからText化(モデルに直でPDFデータを渡したかったが、NGそうだったので)
- 共通的なプロンプト(システム & ユーザー)を定義
- 各種モデルの呼び出し & 出力をJsonスキーマで統一
- ジョブの待ち合わせ & 人手評価に向けたフォームとTextの整形
- slack上での評価
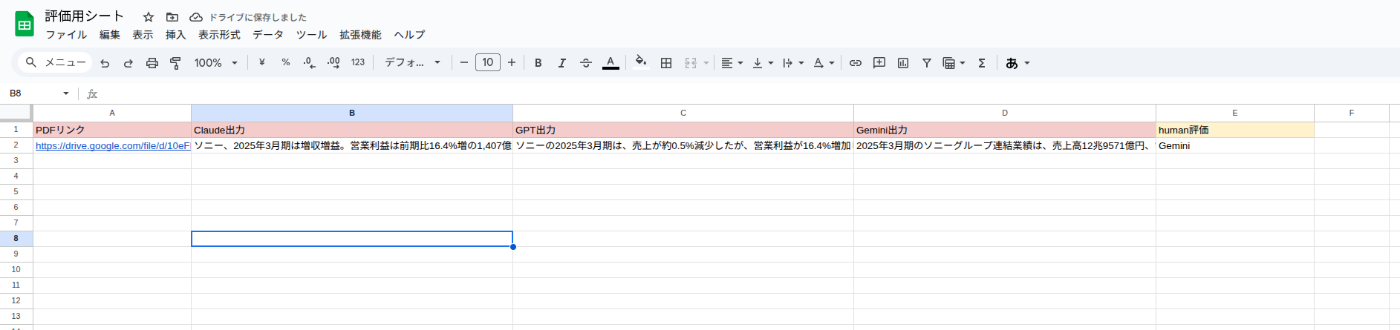
- 一連のデータをスプレッドシートに出力
その上でいくつか良いポイントと悪いポイント(慣れる必要があるポイント)を記載
良いポイント
外部コネクタは豊富 & 接続ドキュメントも結構網羅的に書かれている
- 基本的に使いたいなーと思う有名所のコネクタは揃っていたと思う
- SaaSやアプリだけではなく、BigQueryやSnowflakeといったDWHまであったので、データ連携/蓄積にも一部使えるかもという感じ
- その上で、書くコネクタのクレデンシャル設定がOauthやtokenなど、複数選択肢を置かれていることも多く、サポートのドキュメントもそれなりにメンテされていて、ここにあまり手間取らなかったのはいいなと思えた
- slack側での評価入力も1ジョブで実現でき、FBが出力されるまでワークフローはwaitといった細かな実装や制御もデフォルトで実現できた
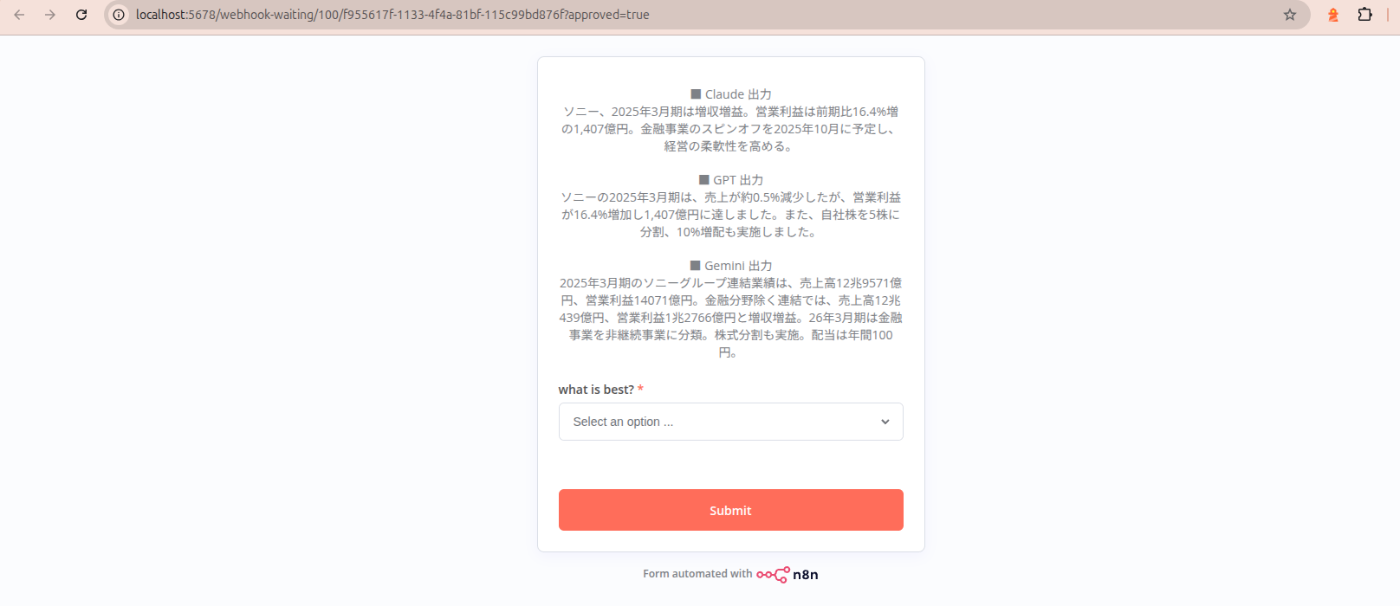
ワークフローを稼働させると指定したslackチャンネルにリンクが送付され、押下すると
自分がフロー上で設定したフォームが表示される、毎回通知されるのは面倒だが、やり方を検討すれば十分使える
AIAgentのジョブに面白みがある
- 少し言葉では言い表しにくいのだが、単一のジョブ自体に拡張性があるなと感じた
- 図からもわかる通り、「モデル/メモリ/Tool/出力の設定」が1ジョブにぶら下がる形となる
- ToolはMCPカスタムも含めて、多数のサービス選択肢がすでに存在しており、「ちょっとアレにも連携しておくか、ちょっとあそこと見比べておくか」ができそうである、拡張性Good
- 出力フォーマットもJsonスキーマをつくるにあたってLLMを呼び出してAutoで作成するなど、どのタスクでどのモデルをどんな形で呼び出すか、を設定できる。まぁ複雑にはなりやすいけど
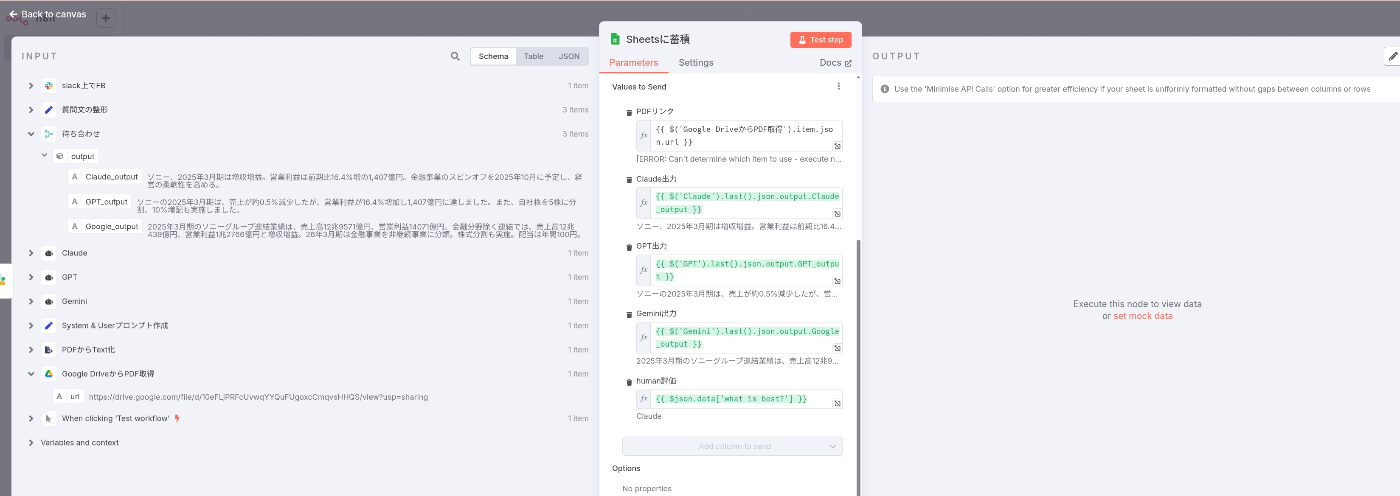
定義した変数情報の永続性
- これはどこまで深く保持されるのかわからないが、生成AIのフロー管理として情報を使いまわす(メモリ的な要素も含めて)という意味では、使いやすいと思った
- フローでは一番左でジョブで定義した「PDFのURL情報」が、フローの一番最後のスプレッドシートまで引き継がれている状態である(各ジョブで変数の再定義などは不要)
その他今回見ていないが、起動におけるトリガー観点なども融通が効きそうなので、また触ってみたいと思う。
悪いポイント(慣れる必要があるポイント)
基本的に良いポイントとトレードオフになりそうな点が多い
待ち合わせにもジョブが必要
- 各モデルの出力を待ち合わせて、slack上での評価を行うわけですが、そのままフローをlineで繋いで収束させてもジョブの待ち合わせが行われなかった。上記スクショの通り、待ち合わせのジョブが必要。このあたりは直感的ではないですね、、
変数情報がちゃんと引き継がれているのか怪しいシーンがある
- 良いポイントにも書いた通り、各ジョブのinput情報にはこれまで設定した変数の情報が引き継がれているのだが、test実行時だとエラーになっているように見受けられたりと、うーんとなることが数回あった。ちゃんと切り分けしていないが、変数名に日本語を使用したりした場合にNGがあったりと、ちょっとしたことにはまだまだ気をつける必要がありそう。
ジョブの並行実行は無理?
- これも調べきれていないが、2023年あたりのサポートDocやデフォルトのワークフローの挙動(3又に分岐している部分)を見る限りでは直列で動いていそうだった
- まぁ、もし実装されてなくても、これは時間とニーズで結構すぐに解決される話な気がする。ただマネージドのみの機能にならなければよいが
総括
当初のモチベーションに対して、モデルの比較を行った上でメタデータを付与し管理することは十分運用可能なサービスだと感じた。ワークフロー全体のバージョン管理なども備わっているので、よりエンジニアライクなコード管理なども進んでいくんだろうなと思う。
ただ、Difyに比べれば、ジョブの挙動やフローの組み方など慣れるべきポイントは多い。ただ、コネクタの使い勝手やメンテ具合、AIAgentのフロー利用は単純に将来性を感じるので、変にビジネスライクなサービス体験に舵を切りすぎることなく、拡張されていってほしい。
宣伝
弊社ではデータ基盤やLLMのご相談や構築も可能ですので、お気軽にお問合せください。
また、中途採用やインターンの問い合わせもお待ちしています!

Discussion