はじめに
- LLMの登場により、自然言語処理におけるタスクの中でも、どちらかというと簡単なタスク(分類や回帰)は、どのような選択をして検証を進めるべきかと考えることがあります。
- 簡単な分類タスク(代表的なもので言えば、メールのフィルタリングの2値分類的など)は伝統的な言語モデルや確率モデルで十分なことは自明です。
- ただし、「そうは問屋は降ろさない」のがビジネスの実タスクであり、将来的に実現したいタスクの難易度は徐々に上がるものです。
- 検証の時間も限られている中で、どうモデルを選択し、検討していくべきか~というのが今回の始まりです。
- (機械学習から離れていた期間もあるので、自分なりの復習・学習と理解も含みます)
BERT と LLM(GPT)
概略
- 特にモデルの解説は端折りますが、時系列的には下記
- 2017年にTransformerの元になる超有名論文 Attention Is All You Need
- 2018年にGoogleからBERT論文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 2019年にOpenAIからGPT-2の論文 Language Models are Unsupervised Multitask Learners
- そして今日に渡り、GPTはアーキテクチャやパラメータの進化を遂げていますよね。
- コンシューマー向けにChatGPTが登場して、モデルを日常活用することが当たり前となり、このLLMブームが来たと理解しています
ざっくりの特徴・共通点や違いは?
- どちらともTransformerベースのアーキテクチャである
- ただGPTは単方向とBERTは双方向でアーキテクチャに違いがある
- GPTのDecoderのみ利用は引き続きであり、BERTは逆にEncoderのみでしたが、発展モデルだとEn/Deという形
- BERTは双方向という観点から、事前学習としてはMLM(Masked Language Model)ベースがメインであり、文脈を深く理解する
- イメージ:習ったことをちゃんと理解しようとする。どちらというと下位タスクをメインにタスクを発展して考えられる
- GPTは単方向という観点から、事前学習としてはNext Token Predictionベースがメインであり、どんどん文章(ワード)を生成する
- イメージ:持っている知識から確率が高いものを生成。どちらというと上位タスク(生成)をメインにタスクを制限して考えられる
- 学習におけるパラメータ数に大きな差がある(下記国産モデルのみのイメージ)
- BERTの公開されている事前学習済みモデルのパラメータ数 : 約10M ~ 300Mあたり(1000万 ~ 3億程度)
- LLMの公開されている事前学習済みモデルのパラメータ数 : 約1B ~ 100Bあたり(10億 ~ 1000億程度)
- (商用モデルのGPT-4とかだと約1.8兆個のパラメータであるウワサ)
つまりどちらのモデルを使うのか?
- 資料やアーキテクチャ上は「タスクによる」が回答になりそうです。
- ただ、広範な生成タスクはLLMに分があるにしても、下位タスクはどちらでもいい感じに解けそうというのがここまでの所感ですね。
ファインチューニングをしてみる
タスク
- sentiment分析(感情分類)を実施
- positive negative neutralを分類
- ただし、推論されるべきデータはSNSで発信されるような口語文章も想定し、特に誹謗中傷にスポットを当てたい
- 誹謗中傷度合をスコアで出したい
データ
- wrime-sentiment
- 色々使えそうですが、極性のみ使用
- japanese-toxic-dataset
- メインは短文のみですが、誹謗中傷周りはデータが少ないので利用させていただきました
- その他クローリング + アノテーション
- 約1000件ほどを某SNSなどからクローリング、主に誹謗中傷が多め
- 数人でのアノテーション、かつそのフラグで誹謗中傷度合を機械的にスコア化
モデル
BERT
- 選択理由としては関連タスクに対しての精度が高かかったため~という形です
LLM
- unslothを使ったfine tuningを行ったため、下記を使用しています
- Llama 3.1 (8B)
- Gemma 2 (9B)
- (モデルの量子化やライブラリにより効率的にfine-tuningが可能です。colab上のT4でも十分機能します)
ソースコードやデータの工夫
今回、コードの紹介まではしませんが、いくつか補足程度に
- unslothのREADMEから辿れるサンプルコードを少し変えるだけで、簡易に学習が可能でした
- BERT側も同様にtransformersを使ったコードで簡易に仕上げられます
- データは実際数百程度で良いと思いますが、BERT側の処理期待も込めて、各クラスに対して数千を用意しました
- LLM側の学習はお作法通り少ないepoch数(1,2~)から回してみていますが、それほど思考錯誤をしていません(サクッと検証と捉えていただければ)
- 出力結果は極性の3値に加えて、誹謗中傷のスコアをつけてもらうようにしています
- BERT側は下準備が間に合わなかったので、negativeとして捉えたaccurasyをスコアとすることにしています(なので誹謗中傷のスコアよりかはどれだけでネガティブ度が強いのかが正しいですね)
- LLMに送り込んだ際のプロンプトは下記のような形です。
以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
以下の入力文章がポジティブな内容か、ネガティブな内容か、ニュートラルな内容か判定してください。
ポジティブな内容は1、ネガティブな内容は-1、ニュートラルな内容は0の評点を選択して出力してください。
また、攻撃性の高いものや誹謗中傷が含まれるものは100点満点でのスコアをつけてください。
対象は評点をネガティブと判定した文章のみで、ポジティブやニュートラルと判定された文章は0点としてください。
具体例として直接的な表現、例えば「~~誹謗中傷なので略~~」を100点のスコアと想定します。
つまり最終的には評点とスコアを出力してください。
### 入力:
{}
### 応答:
label : {}
score : {}
結果
- データセットに対してspitした数百件に対しての正解値は約93-95%程度でした
- 共に学習時間(colabのT4環境)は10-20分程度で収まるぐらいの学習設定
- BERTではneutral関連での間違いが多く、対してPOSITIVE←→NEGATIVEの誤りは少なかったです
- LLM側の精度や誹謗中傷の精度も測るために、15件のセンテンス(negativeや中傷寄り)を追加で確認してみました
- 「気持ち悪い」という単語を含んだ文章で、ちょっとネットに上げるのもはばかられる部分は [unk] としています(実際は名詞や固有名詞が入っています)
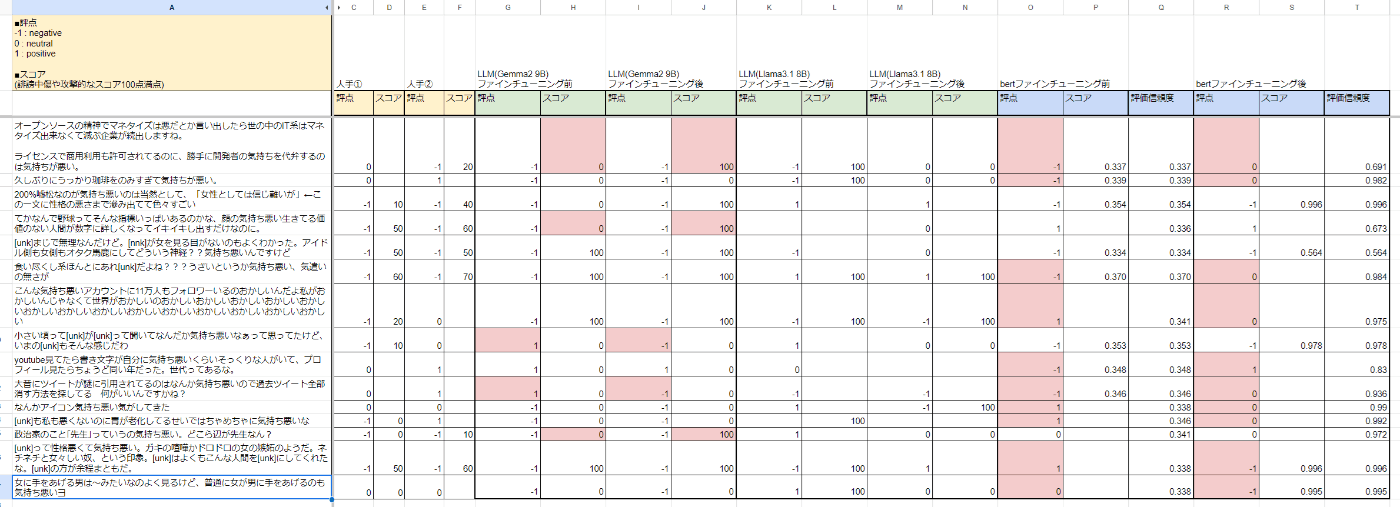
考察
- 結果を見るに、LLMの学習はあまりうまくいかなかったという印象です
- negative判断が多く、neutralがほぼ出ていません
- Llamaに至っては出力制御すらできていない部分(セルが空白の部分など)もあって、もう少しtry&errorが必要な印象です
- これはデータの食わせ方が悪い可能性が高いのですが、スコアが0 or 100しか付いていない状況です
- ただし、極性は-1でもスコアは0と判断しているセンテンスもある(誹謗中傷はなく、純粋なnegative判断)ので、その点は評価できそうです
- BERTの分類は人手の判断と比べても遜色ないので、良い感じと言えると判断できそうです。
まとめ
(以下本タスクに対しての所感です、一般的な観点ではありませんのでご注意ください)
- fine-tuningの手軽さという点では、方法次第ですがそれほど変わらないかなという印象です
- LLMはサンプル数が少なくてOKということも踏まえると、リソースに対しての学習時間もそれほど差があるようには感じませんでした
- 学習における試行錯誤に関しては、LLMのほうが必要な印象です。ただし、プロンプトも加味すると打ち手は多い印象です
- BERTはサクッと精度が出ている形なので、早めに試してベンチマークとするのが良いかもしれません
- 誹謗中傷スコアなどはより改善できるような取り組みを試せたら~というのと、LLMの組み込み想定モデル(1~2B程度)もまた使ってみたいと思います
宣伝
謝辞として、本記事はインターン生の阿部さんに手伝っていただきました。ありがとうございます!
弊社ではLLM側のご相談や構築も対応しておりますので、お気軽にお問合せください。
また、インターンや採用の問い合わせもお待ちしています!

Discussion