第1回Snowflake Rookies Camp開催~Snowflakeとは?~
こんばんは!
Snowflake Rookies Camp幹事のKaoriです。
今回はSnowflake Rookies Camp 第1回の勉強会で幹事の横澤さんにご説明いただいた内容を
復習できるように記事にしてみました!
まずはじめに・・・
Snowflakeとは?

Snowflakeは「AI Data Cloud」として、データを保存・管理・分析するためのプラットフォームです。従来のデータウェアハウス(DWH)に加えて、さまざまな便利な機能を備えています。
特に重要だと思われる4つの機能を紹介します!
-
Snowpipe
データを自動で取り込む機能です。
Snowpipeを使うと、手動でアップロードするのではなく、新しいデータが追加されるたびに自動で取り込んでくれます。例えば、ECサイトの売上データをリアルタイムでSnowflakeに取り込むことができます。 -
Data Sharing
他の企業や部門とデータを簡単に共有できる機能です。
SnowflakeのData Sharingを使えば、リンクを共有するだけで相手もデータを利用できます。
これにより、最新のデータをリアルタイムでやり取りできます。 -
Cortex AI
AIや機械学習を活用するための機能です。すでに用意されたAIモデルをSnowflake内でそのまま使えるため、Snowflake上でAIを使ってデータ分析が簡単に行えます。 -
Snowpark
Python・Java・Scalaを使ってデータ処理や分析を行う機能です。
データウェアハウスでのデータ処理はSQLで行うのが普通ですが、Snowparkを使うとPythonやJavaなどのプログラミング言語で処理できます。データサイエンティストやエンジニアが、使い慣れた言語でデータ分析や機械学習の開発を行えます。
次に、アーキテクチャについて紹介します!
特に重要アーキテクチャ
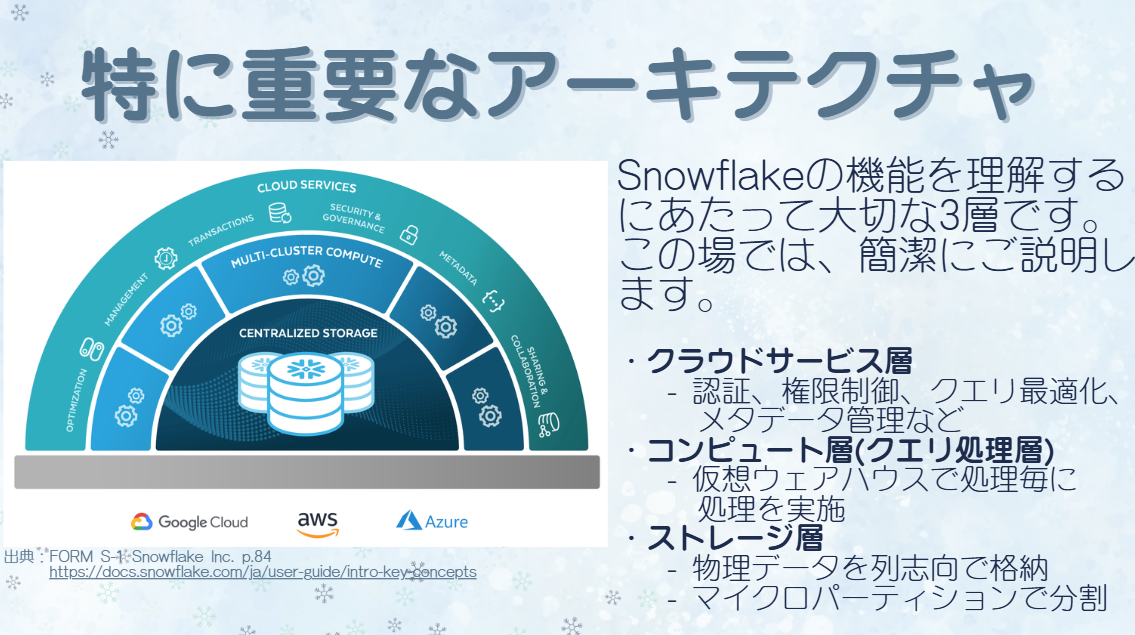
Snowflakeはデータを効率的に管理・処理するために3つの主要な層で構成されています。
-
クラウドサービス層(Cloud Services Layer)
データの管理やセキュリティを担う層です。
ユーザーがSnowflakeを利用する際の認証、アクセス制御、メタデータ管理、クエリの最適化などを担当します。主な役割 認証・アクセス管理 → 誰がどのデータにアクセスできるかを制御 クエリの最適化 → データ検索を効率化し、高速に処理 メタデータ管理 → データの構造や変更履歴を管理 -
コンピュート層(Compute Layer / クエリ処理層)
データ処理を実行する層です。
Snowflakeでは「仮想ウェアハウス」と呼ばれる仕組みを使い、ウェアハウスごとに独立したコンピュートリソースを提供します。ウェアハウスを分けることにより、ETLでのロード処理とBIツールの参照処理など異なるワークロードの処理が依存することがなくなります。
例えば、大量データのロードでETL処理がリソースを大量に使った場合もBIツールの参照処理の性能に全く影響することは有りません。主な役割 データの検索・集計・計算を実行(SQLクエリを処理) 負荷に応じて処理能力を増減させ、スケーラブルな処理を実行 複数のクエリを並行実行し、高速な処理を実現 -
ストレージ層(Storage Layer)
データを保存する層です。
Snowflakeではデータをクラウドストレージ上に列指向フォーマットで格納し、効率的に管理・圧縮しています。主な役割 データの管理と保存 列指向フォーマットによる高速なデータ取得(分析に最適化) マイクロパーティショニングによるデータ分割と最適化
最後に
ただいま、第2回目のイベントを企画していますので、
この記事で復習していただきつつ、是非ご参加を検討いただければ嬉しいです♪
みなさまと一緒にSnowflakeを学べることを楽しみにしてます!
Discussion