【Snowflake World Tour Tokyo】Rookies Camp Demoでみたチャットボットを作ってみよう!
こんにちは。Rookies Camp幹事のnaoki_yokozawa(横澤 直樹)です。
Xはこちらのアカウントで主にデータマネジメント関連の発信をしていますのでフォローいただけますと幸いです!
さて、2025年9月11(木)、12(金)に開催しているSnowflake World Tour Tokyoにて我らが
Rookies Campですが『SNOWFLAKE COMMUNITY HUB』から4枠いただき念願のオフライン開催いたしました。ご参加いただきました皆さん本当にありがとうございました。
参加前にこのブログを見ていただいている方は是非楽しみにしていてください。
今回は、4枠のうちの夕方の2枠を利用して開催する『Rookies Camp Demo』についてのブログとなります。デモではどんな動きになるのかをお見せしただけで実際にどうやって作るのかは解説しませんでしたので、こちらでご説明させていただきます。
はじめに
本日記載する内容はデモの参考元としている以下のQuick Startの手順について、更にわかりやすいように補足を加えてご説明をさせていただきます。
Streamlit in Snowflakeのコード詳細やSemantic Modelについてなどは10/31(金)に開催予定の第5回Rookies Campで詳しくお話させていただきます。
※当日のデモ内容はQuick Startから少しカスタマイズしているため、その点も
更に深く知りたいという方は是非以下URLから奮ってお申し込みください。
Cotex Analystとは?
Snowflakeが提供する機能で、大規模言語モデル(LLM)を活用して自然言語で投げかけた質問をSQLクエリに変換してくれるサービスです。いわゆるText to SQLというやつです。
チャットボットの活用に利用することなどが想定されます。
📓全体手順
全体の手順は以下のとおりです。
- 各種オブジェクト(データベース、スキーマ、ウェアハウス、ステージ、テーブル)の準備
- ファイルの内部ステージへのアップ及びデータロード
- Cortex Searchの作成
- Streamlit in Snowflakeの作成
処理の流れは以下のとおりです。チャットボット画面としてStreamlit in Snowflakeを利用します。

各種オブジェクトの準備
オブジェクト作成用SQLファイルのダウンロード
「2. Set up the Snowflake environment」にも記載されていますがGitからcreate_snowflake_objects.sqlをダウンロードします。
以下の赤枠のボタンを押下するとSQLファイルがダウンロード可能です。

create_snowflake_objects.sql
/*--
• Database, schema, warehouse, and stage creation
--*/
USE ROLE SECURITYADMIN;
CREATE ROLE cortex_user_role;
GRANT DATABASE ROLE SNOWFLAKE.CORTEX_USER TO ROLE cortex_user_role;
-- TODO: Replace <your_user> with your username
GRANT ROLE cortex_user_role TO USER <your_user>;
USE ROLE sysadmin;
-- Create demo database
CREATE OR REPLACE DATABASE cortex_analyst_demo;
-- Create schema
CREATE OR REPLACE SCHEMA cortex_analyst_demo.revenue_timeseries;
-- Create warehouse
CREATE OR REPLACE WAREHOUSE cortex_analyst_wh
WAREHOUSE_SIZE = 'large'
WAREHOUSE_TYPE = 'standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE
COMMENT = 'Warehouse for Cortex Analyst demo';
GRANT USAGE ON WAREHOUSE cortex_analyst_wh TO ROLE cortex_user_role;
GRANT OPERATE ON WAREHOUSE cortex_analyst_wh TO ROLE cortex_user_role;
GRANT OWNERSHIP ON SCHEMA cortex_analyst_demo.revenue_timeseries TO ROLE cortex_user_role;
GRANT OWNERSHIP ON DATABASE cortex_analyst_demo TO ROLE cortex_user_role;
USE ROLE cortex_user_role;
-- Use the created warehouse
USE WAREHOUSE cortex_analyst_wh;
USE DATABASE cortex_analyst_demo;
USE SCHEMA cortex_analyst_demo.revenue_timeseries;
-- Create stage for raw data
CREATE OR REPLACE STAGE raw_data DIRECTORY = (ENABLE = TRUE);
/*--
• Fact and Dimension Table Creation
--*/
-- Fact table: daily_revenue
CREATE OR REPLACE TABLE cortex_analyst_demo.revenue_timeseries.daily_revenue (
date DATE,
revenue FLOAT,
cogs FLOAT,
forecasted_revenue FLOAT,
product_id INT,
region_id INT
);
-- Dimension table: product_dim
CREATE OR REPLACE TABLE cortex_analyst_demo.revenue_timeseries.product_dim (
product_id INT,
product_line VARCHAR(16777216)
);
-- Dimension table: region_dim
CREATE OR REPLACE TABLE cortex_analyst_demo.revenue_timeseries.region_dim (
region_id INT,
sales_region VARCHAR(16777216),
state VARCHAR(16777216)
);
use role accountadmin;
-- create a Git API integration for Snowflake Labs
-- This integration allows access to GitHub repositories under Snowflake-Labs
-- It is used for accessing demo data and scripts from the Snowflake Labs GitHub organization
CREATE OR REPLACE API INTEGRATION snowflake_labs_git_integration
API_PROVIDER = git_https_api
API_ALLOWED_PREFIXES = ('https://github.com/Snowflake-Labs/')
ENABLED = TRUE;
USE ROLE cortex_user_role;
-- Create a schema for Git repositories
-- This schema will contain Git repositories for the Cortex Analyst demo
CREATE OR REPLACE SCHEMA cortex_analyst_demo.git_repos;
-- Create a Git repository for the Cortex Analyst demo
-- This repository contains scripts and data for the Cortex Analyst demo
CREATE OR REPLACE GIT REPOSITORY cortex_analyst_demo.git_repos.getting_started_with_cortex_analyst
API_INTEGRATION = snowflake_labs_git_integration
ORIGIN = 'https://github.com/Snowflake-Labs/sfguide-getting-started-with-cortex-analyst';
-- Fetch the latest content from the Git repository
ALTER GIT REPOSITORY cortex_analyst_demo.git_repos.getting_started_with_cortex_analyst FETCH;
ワークシートを作成してSQLを実行
ワークシートを選択。

SQLワークシートを選択。
先程のSQLをコピペしてワークシートに貼り付けて、<your_user>の部分を自分のユーザ名に書き換え。
※私はnaokiyokozawaに書き換えました
SQLを実行(赤丸部分を押下でもいいですし、Ctrl + Enterでも実行可能)
各種オブジェクトが作成されました
ファイルの内部ステージへのアップロード及びデータロード
ファイルをダウンロード
Gitリポジトリから以下のファイルをダウンロードします
ステージへのアップロード
以下の手順でステージにアップロードします。
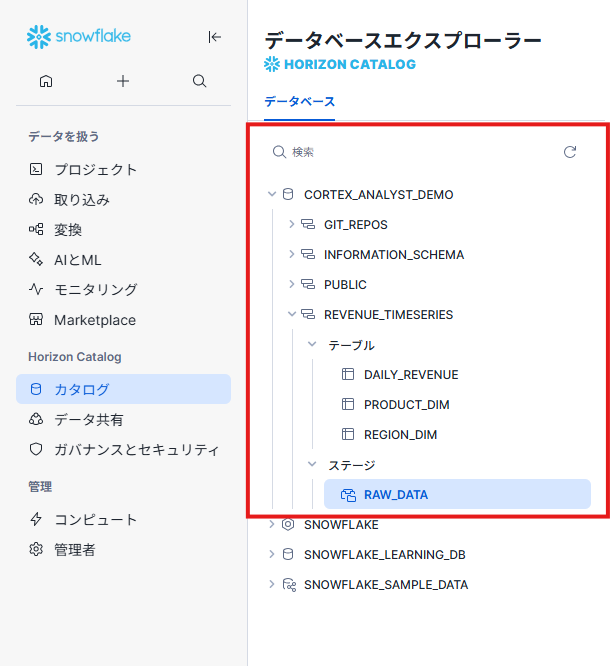
- [カタログ] - [データベースエクスプローラ]を押下
- [CORTEX_ANALYST_DEMO] - [REVENUE_TIMESERIES] - [ステージ] - [RAW_DATA]を押下
- 右上の [+ファイル]を押下
- 先ほどダウンロードした4ファイルをドラッグしてアップロード

データロード用SQLファイルのダウンロード
load_data.sqlをダウンロード
load_data.sql
/*--
• looad data into tables
--*/
USE ROLE CORTEX_USER_ROLE;
USE DATABASE CORTEX_ANALYST_DEMO;
USE SCHEMA CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES;
USE WAREHOUSE CORTEX_ANALYST_WH;
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE
FROM @raw_data
FILES = ('daily_revenue.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.PRODUCT_DIM
FROM @raw_data
FILES = ('product.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.REGION_DIM
FROM @raw_data
FILES = ('region.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
ワークシートを作成してSQLを実行
先程も説明した手順でload_data.sqlを実行
投入データのER図
以下構成のデータが投入されました。
※このデータだと、日別収益と地域マスタ結合すると増幅してしまうのですが、元データがそういうデータなので一旦このまま進めます。

Cortex Searchの作成
Cortex Search作成用SQLファイルのダウンロード
cortex_search_create.sqlをダウンロード
cortex_search_create.sql
USE ROLE cortex_user_role;
USE DATABASE cortex_analyst_demo;
USE SCHEMA revenue_timeseries;
CREATE OR REPLACE CORTEX SEARCH SERVICE product_line_search_service
ON product_dimension
WAREHOUSE = cortex_analyst_wh
TARGET_LAG = '1 hour'
AS (
SELECT DISTINCT product_line AS product_dimension FROM product_dim
);
ワークシートを作成してSQLを実行
cortex_search_create.sqlを実行
Streamlit in Snowflakeの作成
Streamlit in Snowflake用Pythoコードのダウンロード
cortex_analyst_sis_demo_app.pyをダウンロード
cortex_analyst_sis_demo_app.py
"""
Cortex Analyst App
====================
This app allows users to interact with their data using natural language.
"""
import json
import time
from datetime import datetime
from typing import Dict, List, Optional, Tuple, Union
import _snowflake
import pandas as pd
import streamlit as st
import altair as alt
import re
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.exceptions import SnowparkSQLException
AVAILABLE_SEMANTIC_MODELS_PATHS = [
"CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.RAW_DATA/revenue_timeseries.yaml"
]
API_ENDPOINT = "/api/v2/cortex/analyst/message"
FEEDBACK_API_ENDPOINT = "/api/v2/cortex/analyst/feedback"
API_TIMEOUT = 50000
session = get_active_session()
def main():
if "messages" not in st.session_state:
reset_session_state()
st.session_state.show_initial_message = True
show_header_and_sidebar()
if st.session_state.get("show_initial_message", False):
with st.chat_message("assistant"):
st.markdown("どのようなご質問がありますか?お気軽にどうぞ。")
display_conversation()
handle_user_inputs()
handle_error_notifications()
# display_warnings()
def reset_session_state():
st.session_state.messages = []
st.session_state.active_suggestion = None
st.session_state.warnings = []
st.session_state.form_submitted = {}
def show_header_and_sidebar():
st.title("❄️Rookies Camp Demo❄️")
st.markdown("このアプリでは、自然言語でSnowflakeのデータと対話できます。質問を入力してください。")
with st.sidebar:
st.selectbox(
"使用するセマンティックモデルを選択:",
AVAILABLE_SEMANTIC_MODELS_PATHS,
format_func=lambda s: s.split("/")[-1],
key="selected_semantic_model_path",
on_change=reset_session_state,
)
st.divider()
_, btn_container, _ = st.columns([2, 12, 2])
if btn_container.button("チャット履歴をリセット", use_container_width=True):
reset_session_state()
def handle_user_inputs():
user_input = st.chat_input("ご質問をどうぞ")
if user_input:
process_user_input(user_input)
elif st.session_state.active_suggestion is not None:
suggestion = st.session_state.active_suggestion
st.session_state.active_suggestion = None
process_user_input(suggestion)
def handle_error_notifications():
if st.session_state.get("fire_API_error_notify"):
st.toast("APIエラーが発生しました", icon="🚨")
st.session_state["fire_API_error_notify"] = False
def process_user_input(prompt: str):
st.session_state.warnings = []
# 表示用には元のユーザー入力を使う
new_user_message = {
"role": "user",
"content": [{"type": "text", "text": prompt}],
}
st.session_state.messages.append(new_user_message)
with st.chat_message("user"):
user_msg_index = len(st.session_state.messages) - 1
display_message(new_user_message["content"], user_msg_index)
# Cortex APIに送る用のメッセージリストを複製して日本語指示を埋め込む
messages_for_api = st.session_state.messages.copy()
last_msg_api = messages_for_api[-1]
if last_msg_api["role"] == "user":
original_text = last_msg_api["content"][0]["text"]
if "日本語" not in original_text:
last_msg_api["content"][0]["text"] = original_text + "(日本語で回答してください)"
with st.chat_message("analyst"):
with st.spinner("解析中...少々お待ちください。"):
time.sleep(1)
response, error_msg = get_analyst_response(messages_for_api)
if error_msg is None:
analyst_message = {
"role": "analyst",
"content": response["message"]["content"],
"request_id": response["request_id"],
}
else:
analyst_message = {
"role": "analyst",
"content": [{"type": "text", "text": error_msg}],
"request_id": response["request_id"],
}
st.session_state["fire_API_error_notify"] = True
if "warnings" in response:
st.session_state.warnings = response["warnings"]
st.session_state.messages.append(analyst_message)
st.rerun()
def quote_japanese_aliases(sql: str) -> str:
# AS の後ろに日本語が来ている箇所を "日本語" に変換
def replacer(match):
alias = match.group(1)
return f'AS "{alias}"'
# 「AS 日本語」のパターンにマッチ(日本語を含むワードを検出)
return re.sub(r'AS\s+([一-龯ぁ-んァ-ンーa-zA-Z0-9々〆〤]+)', r'AS "\1"', sql)
def display_conversation():
for idx, message in enumerate(st.session_state.messages):
role = message["role"]
content = message["content"]
with st.chat_message(role if role in ("user", "analyst") else "assistant"):
if role == "analyst":
display_message(content, idx, message.get("request_id"))
else:
display_message(content, idx)
def display_message(content: List[Dict[str, Union[str, Dict]]], message_index: int, request_id: Union[str, None] = None):
for item in content:
if item["type"] == "text":
st.markdown(item["text"])
elif item["type"] == "suggestions":
for suggestion_index, suggestion in enumerate(item["suggestions"]):
if st.button(suggestion, key=f"suggestion_{message_index}_{suggestion_index}"):
st.session_state.active_suggestion = suggestion
elif item["type"] == "sql":
# SQLクリーンアップ(日本語エイリアスにクォートを付ける)
clean_sql = quote_japanese_aliases(item["statement"])
display_sql_query(clean_sql, message_index, item["confidence"], request_id)
@st.cache_data(show_spinner=False)
def get_query_exec_result(query: str) -> Tuple[Optional[pd.DataFrame], Optional[str]]:
global session
try:
df = session.sql(query).to_pandas()
return df, None
except SnowparkSQLException as e:
return None, str(e)
def display_sql_confidence(confidence: dict):
if confidence is None:
return
verified_query_used = confidence["verified_query_used"]
with st.popover("検証済クエリ情報", help="Verified Query Repository によるSQL生成の出典情報です。"):
with st.container():
if verified_query_used is None:
st.text("Verified Query Repository による生成SQLは使われていません。")
return
st.text(f"名称: {verified_query_used['name']}")
st.text(f"質問: {verified_query_used['question']}")
st.text(f"検証者: {verified_query_used['verified_by']}")
st.text(f"検証日: {datetime.fromtimestamp(verified_query_used['verified_at'])}")
st.text("生成されたSQL:")
st.code(verified_query_used["sql"], language="sql", wrap_lines=True)
def display_sql_query(sql: str, message_index: int, confidence: dict, request_id: Union[str, None] = None):
with st.expander("生成されたSQL", expanded=False):
st.code(sql, language="sql")
display_sql_confidence(confidence)
with st.expander("SQLの実行結果", expanded=True):
with st.spinner("SQLを実行中..."):
df, err_msg = get_query_exec_result(sql)
if df is None:
st.error(f"SQLの実行に失敗しました。エラー内容: {err_msg}")
elif df.empty:
st.write("SQLは実行されましたが、データが返されませんでした。")
else:
data_tab, chart_tab = st.tabs(["データ 📄", "グラフ 📊"])
with data_tab:
st.dataframe(df, use_container_width=True)
with chart_tab:
display_charts_tab(df, message_index)
if request_id:
display_feedback_section(request_id)
def display_charts_tab(df: pd.DataFrame, message_index: int) -> None:
if len(df.columns) >= 2:
all_cols_set = set(df.columns)
col1, col2, col3 = st.columns(3)
x_col = col1.selectbox("X軸", all_cols_set, key=f"x_col_select_{message_index}")
y_col = col2.selectbox("Y軸", all_cols_set.difference({x_col}), key=f"y_col_select_{message_index}")
group_col = col3.selectbox(
"グルーピング列(任意)",
options=["(なし)"] + list(all_cols_set.difference({x_col, y_col})),
key=f"group_col_select_{message_index}",
)
chart_type = st.selectbox(
"グラフの種類",
options=["折れ線グラフ 📈", "棒グラフ 📊"],
key=f"chart_type_{message_index}",
)
# 棒グラフオプション(積み上げ or グループ)
is_stacked = False
if chart_type == "棒グラフ 📊" and group_col != "(なし)":
is_stacked = st.radio(
"棒グラフの表示方法",
options=["積み上げ型", "グループ型"],
horizontal=True,
key=f"bar_stack_option_{message_index}"
) == "積み上げ型"
# データ整形
if group_col != "(なし)":
chart_data = df[[x_col, y_col, group_col]].dropna()
else:
chart_data = df[[x_col, y_col]].dropna()
# チャート生成
if chart_type == "折れ線グラフ 📈":
line = alt.Chart(chart_data).mark_line().encode(
x=alt.X(x_col, title=x_col),
y=alt.Y(y_col, title=y_col),
color=group_col if group_col != "(なし)" else alt.value("steelblue")
).properties(title="折れ線グラフ")
st.altair_chart(line, use_container_width=True)
elif chart_type == "棒グラフ 📊":
bar = alt.Chart(chart_data).mark_bar().encode(
x=alt.X(x_col, title=x_col),
y=alt.Y(y_col, title=y_col, stack="zero" if is_stacked else None),
color=group_col if group_col != "(なし)" else alt.value("orange")
).properties(title="棒グラフ")
st.altair_chart(bar, use_container_width=True)
else:
st.warning("グラフを表示するには2列以上のデータが必要です。")
def display_warnings():
for warning in st.session_state.warnings:
st.warning(warning["message"], icon="⚠️")
def get_analyst_response(messages: List[Dict]) -> Tuple[Dict, Optional[str]]:
request_body = {
"messages": messages,
"semantic_model_file": f"@{st.session_state.selected_semantic_model_path}",
}
resp = _snowflake.send_snow_api_request(
"POST", API_ENDPOINT, {}, {}, request_body, None, API_TIMEOUT,
)
parsed_content = json.loads(resp["content"])
if resp["status"] < 400:
return parsed_content, None
else:
error_msg = f"""
🚨 Cortex Analyst API エラー 🚨
* ステータスコード: `{resp['status']}`
* リクエストID: `{parsed_content['request_id']}`
* エラーコード: `{parsed_content['error_code']}`
* レスポンス内容: `{resp.get('content', '')}`
メッセージ:
"""
return parsed_content, error_msg
def display_feedback_section(request_id: str):
with st.popover("📝 フィードバックを送信"):
if request_id not in st.session_state.form_submitted:
with st.form(f"feedback_form_{request_id}", clear_on_submit=True):
positive = st.radio("生成されたSQLの評価", options=["👍", "👎"], horizontal=True)
positive = positive == "👍"
feedback_message = st.text_input("任意でコメントを記入してください")
submitted = st.form_submit_button("送信")
if submitted:
err_msg = submit_feedback(request_id, positive, feedback_message)
st.session_state.form_submitted[request_id] = {"error": err_msg}
st.rerun()
elif (
request_id in st.session_state.form_submitted
and st.session_state.form_submitted[request_id]["error"] is None
):
st.success("フィードバックありがとうございました ✅")
else:
st.error(st.session_state.form_submitted[request_id]["error"])
def submit_feedback(request_id: str, positive: bool, feedback_message: str) -> Optional[str]:
request_body = {
"request_id": request_id,
"positive": positive,
"feedback_message": feedback_message,
}
resp = _snowflake.send_snow_api_request(
"POST", FEEDBACK_API_ENDPOINT, {}, {}, request_body, None, API_TIMEOUT,
)
if resp["status"] == 200:
return None
parsed_content = json.loads(resp["content"])
err_msg = f"""
🚨 フィードバックAPI エラー 🚨
* ステータスコード: `{resp['status']}`
* リクエストID: `{parsed_content['request_id']}`
* エラーコード: `{parsed_content['error_code']}`
メッセージ:
"""
return err_msg
if __name__ == "__main__":
main()
- ロールを「CORTEX_USER_ROLE」に切替
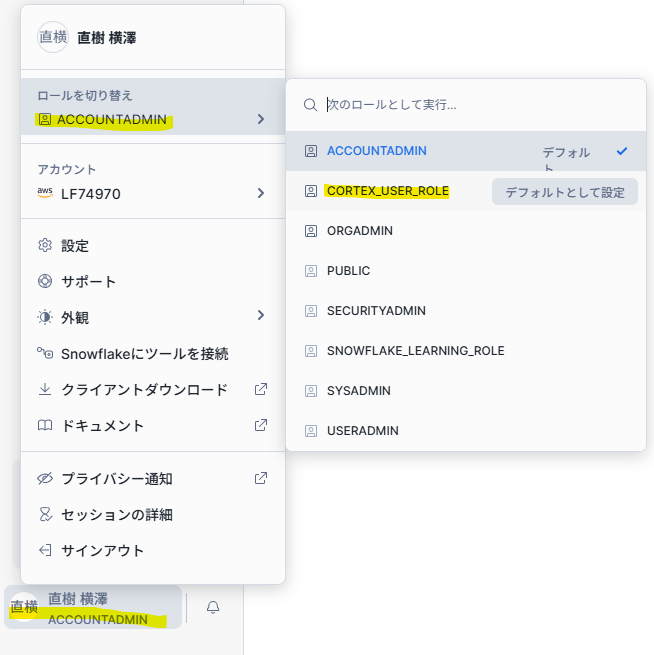
- [プロジェクト] - [Streamlit]を押下
- [+ Streamlitアプリ]を押下
- 以下を指定して[作成]を押下
・ アプリタイトル:任意の名称
・ データベース:CORTEX_ANALYST_DEMO
・ スキーマ:REVENUE_TIMESERIES
・ ウェアハウス:CORTEX_ANALYST_WH - デフォルトのコードを削除したうえでダウンロードしたPythonコードをコピペする
- 右上の[▶実行]を押下
以下の画面が完成

さいごに
手順に則って実施いただければ、簡単にチャットボットを作ることができたのではないでしょうか。今回の内容を応用していただければ自社データで活用することも可能です。
ただ、この中で触れたStreamlit in SnowflakeやSemantic Modelについては詳細説明ができていないため、繰り返しになりますが是非第5回Rookies Campをお申し込みください!
長文でしたが、お付き合いいただきありがとうございました!!
Discussion