【Vision Transformer】 コード解説
内容
Vision Transformer のコード解説をしていこうと思います。
論文: An image is worth 16x16 words: Transformers for image recognition at scale
使用するコードはこちらです。
Pre-Norm
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
TransformerのSub-Layerで使用するクラスです。本家のTransformerではPost-Normを採用していますが、Vision TransformerではPre-Normを使いますfnにMulti-Head AttentionやFeed Forward Networkが代入され、正規化後の値を処理していきます。
※Pre-Normを採用する理由: Learning Deep Transformer Models for Machine Translation
FeedForwardNetwork
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
こちらは、Transformer-Blockの2層目で使用するクラスです。特に、解説するところはありません。
Attention 機構
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
こちらが、Attentionクラスです。下図のモデルを実装しています。
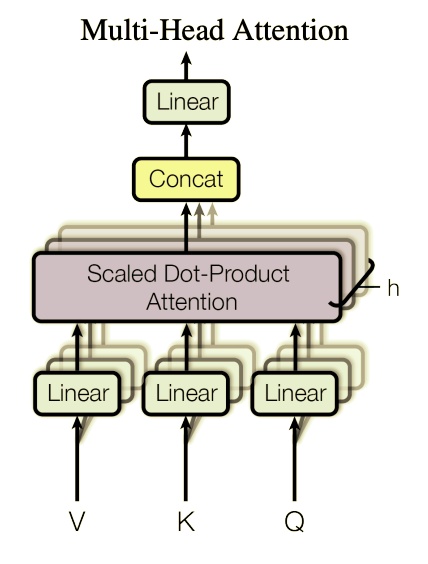
__init__
inner_dim = dim_head * heads
inner_dimは、Query, Key, Valueを生成するLiner層の出力次元数です。
Multi-Head Self-Attentionを使用しており、各Q, K, Vについてhead数の数だけ欲しいので、head毎の次元数とhead数(heads)を掛けた値を設定します。
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
Attentionを求める際の、
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
このLinear層は、
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
図中の、最終層Linearに該当します。
forward
qkv = self.to_qkv(x).chunk(3, dim = -1)
.chunk()で、配列を3つに分割し、3要素を持つタプルにしています。
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
rearrange関数で、head毎に分割する形で配列を変形しています。
具体的には、(1, 65, 1024)でhead数が16の場合、(1, 16, 65, 64)になります。
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
最後に、patche毎になるよう変形し、Linear層に入力します。
Transformer Encoder
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
こちらが、Transformer Encoderです。上記で作成したクラスを使って、シンプルに実装されています。論文中のこちらです。
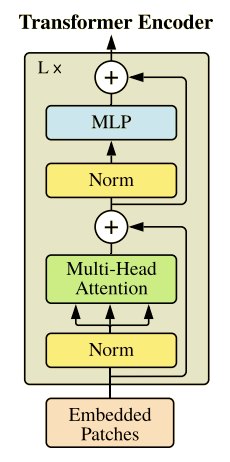
参照: An image is worth 16x16 words: Transformers for image recognition at scale
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
__init__関数内でモデルを構築しています。depthがBlock数になっており、Attention機構とFeedForwardNetworkをblock数だけ繰り返しています。
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
Transformer EncoderではResidual Learningを採用しているため、forward関数内では、入力と出力の残差を学習するようにしています。
Vision Transformer
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
こちらが、いよいよVision Transformerの実装です。

参照: An image is worth 16x16 words: Transformers for image recognition at scale
ここでは、分かりやすくするため次の設定で解説します。
| 変数 | 値 |
|---|---|
| 画像サイズ | 256x256x3 |
| patche画像の一辺 | 32 |
| class数 | 1000 |
| dim | 1024 |
| depth | 6 |
| heads | 16 |
__init__
num_patches = (image_height // patch_height) * (image_width // patch_width)
元画像の縦横をpatcheの縦横で割ることで、patcheの数を計算しています。image_heightが256, patch_heightが32なので、各々8になり、num_patchesは64です。
patch_dim = channels * patch_height * patch_width
patch_dimは、3 * 32 * 32で、3072になります。
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
patche画像をエンべディングする層です。図中のLinear Projection of Flattened Patchesに該当します。
Rearrangeは、画像データを変形し、patcheに分割しています。
具体的には、入力画像(1, 3, 256, 256)を(1, 64, 1024)に変換しています。
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
Position Embeddingを定義しています。
論文中の式
元画像の中での位置を明示的に与えず、パラメータとして学習させます。また、patche数に1を加算しているのは、式にもある通り、先頭にclass_tokenを付与するためです。これにより、サイズは(1, 65, 1024)になります。
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
こちらで、class_tokenを定義しています。class_tokenを付与することにより、画像の識別を学習することができます。
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
Transformer Encoderの出力を受け取り、クラス分類をする層です。図中の、MLP Headに該当します。
forward
x = self.to_patch_embedding(img)
画像を各patcheに分割し、エンべディングしています。xのサイズは(1, 64, 1024)です。
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
repeat関数で、cls_tokenと画像のエンべディングの次元数が合うよう次元を追加しています。そして、先頭に追加します。cls_tokensのサイズは(1, 1, 1024)、xのサイズは(1, 65, 1024)です。
x += self.pos_embedding[:, :(n + 1)]
Position Embeddingを、入力に加算しています。xのサイズは(1, 65, 1024)です。
x = self.transformer(x)
Transformer Encodingに入力し、出力を受け取ります。xのサイズは(1, 65, 1024)です。
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
Transformer Encodingの出力の中から、'cls_token'に対応する、先頭の部分のみ利用します。xのサイズは(1, 1024)です。
self.mlp_head(x)
最後に、Transformerの出力を分類層に入力します。この時、出力のサイズは(1, 1000)です。
おわり
いかがだったでしょうか、ViTはパラメータは多いものの、実装は非常にシンプルです。これからViTを学ぶ方の理解の助けになれば幸いです。
Discussion