Closed6
llama-bench比較ログ(M2 Ultra、EVO-X2、RTX 3060、RTX3090)
はじめに
環境
- Mac Studio(M2 Ultra, 60-GPU, UMA 128GB)
- EVO-X2(Ryzen AI Max+ 395, Radeon 8060S, UMA 128GB)
- Core i5-12500(DDR4-3200, 96GB) + RTX 3060 (12GB)

検証に用いたモデル
Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf
結果まとめ
私のUbuntu24.04環境ではHIPでllama.cppをビルドできなかったため、HIPは未検証。
M2 UltraとEVO-X2(Vulkan)を比較した結果、プロンプト処理はM2 Ultra(Metal)の圧勝という以外な結果に。プロンプト処理はGPU性能が高いEVO-X2が優勢かという認識だったが、そこまで単純な話でもないらしい。
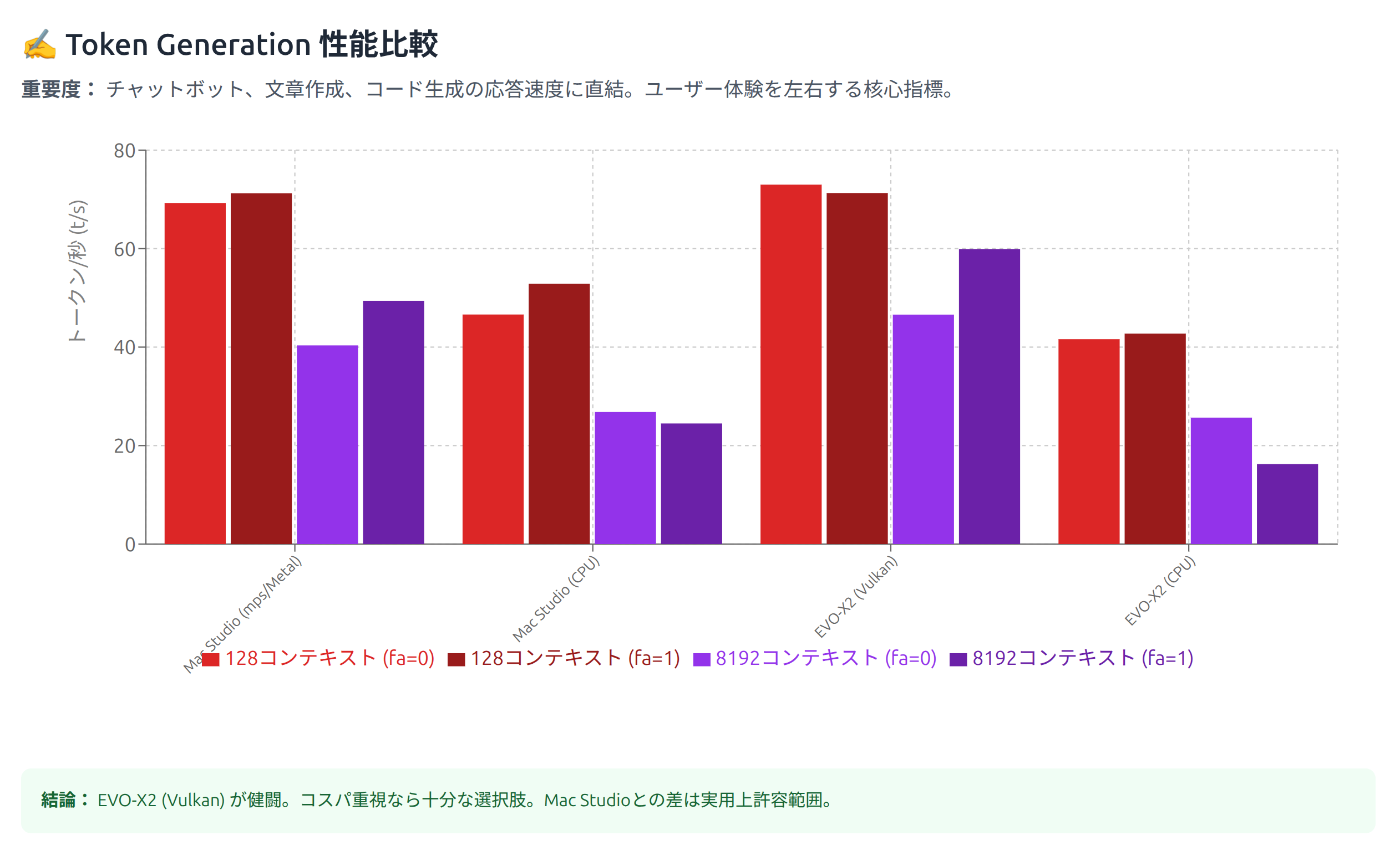
一方、生成速度ではメモリ帯域幅では3倍以上あるM2 Ultraと同程度になっている。これはEVO-X2が速いというよりは、llama.cppではMoEモデルがApple Siliconに最適化されていないためではないか?と考えている。
-
プロンプト処理(pp: prompt processing)

-
トークン生成(tg: token generation)
【追記】ROCm 6.4.0, RTX 3060, RTX3090を追加


Mac Studio(M2 Ultra, 60-GPU, 128GB)
mps(Metal)
- pp512/tg128
🐔@Mac-Studio:~/AI/llama.cpp $ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 100 -fa 0,1
build: 9c35706b9 (6060)
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | pp512 | 1080.52 ± 4.06 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | tg128 | 69.27 ± 0.05 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | pp512 | 1096.84 ± 5.48 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | tg128 | 71.23 ± 0.08 |
- pp8192/tg8192
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | pp8192 | 818.85 ± 1.34 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | tg8192 | 40.35 ± 0.03 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | pp8192 | 784.33 ± 0.66 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | tg8192 | 49.40 ± 0.02 |
CPU
- pp512/tg128
🐔@Mac-Studio:~/AI/llama.cpp $ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 0 -fa 0,1
build: 9c35706b9 (6060)
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | pp512 | 145.27 ± 6.73 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | tg128 | 46.62 ± 3.92 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | pp512 | 152.72 ± 0.76 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | tg128 | 52.88 ± 1.42 |
- pp8192/tg8192
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | pp8192 | 79.12 ± 0.39 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 0 | tg8192 | 26.82 ± 0.15 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | pp8192 | 64.53 ± 0.65 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Metal,BLAS | 16 | 1 | tg8192 | 24.49 ± 0.02 |
EVO-X2:Radeon 8060S(Ryzen AI Max+ 395, 128GB)
Vulkan
- pp512/tg128
🐔@EVO-X2:llama.cpp-vulkan$ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 100 -fa 0,1
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon Graphics (RADV GFX1151) (radv) | uma: 1 | fp16: 1 | bf16: 0 | warp size: 64 | shared memory: 65536 | int dot: 1 | matrix cores: KHR_coopmat
build: 9c35706b9 (6060)
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 0 | pp512 | 391.54 ± 1.50 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 0 | tg128 | 72.99 ± 0.31 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 1 | pp512 | 399.76 ± 1.41 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 1 | tg128 | 71.29 ± 0.11 |
- pp8192/tg8192
$ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 100 -fa 0,1 -p 8192 -n 8192
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon Graphics (RADV GFX1151) (radv) | uma: 1 | fp16: 1 | bf16: 0 | warp size: 64 | shared memory: 65536 | int dot: 1 | matrix cores: KHR_coopmat
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 0 | pp8192 | 284.71 ± 0.45 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 0 | tg8192 | 46.60 ± 1.34 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 1 | pp8192 | 315.36 ± 0.33 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | Vulkan,RPC | 100 | 1 | tg8192 | 59.91 ± 1.95 |
ROCm 6.4.0
$ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 100 -fa 0,1
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 ROCm devices:
Device 0: AMD Radeon Graphics, gfx1151 (0x1151), VMM: no, Wave Size: 32
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 0 | pp512 | 409.48 ± 0.81 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 0 | tg128 | 59.78 ± 0.40 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 1 | pp512 | 401.48 ± 2.72 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 1 | tg128 | 65.93 ± 0.18 |
- pp8192/tg8192
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 0 | pp8192 | 254.28 ± 0.36 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 0 | tg8192 | 30.78 ± 0.08 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 1 | pp8192 | 383.41 ± 0.46 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | ROCm | 100 | 1 | tg8192 | 63.27 ± 0.17 |
CPU
- pp512/tg128
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 0 | pp512 | 223.33 ± 8.97 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 0 | tg128 | 41.61 ± 0.16 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 1 | pp512 | 223.31 ± 1.68 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 1 | tg128 | 42.74 ± 0.34 |
- pp8192/tg8192
| model | size | params | backend | threads | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 0 | pp8192 | 127.83 ± 0.26 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 0 | tg8192 | 25.68 ± 0.34 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 1 | pp8192 | 66.91 ± 0.53 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CPU | 16 | 1 | tg8192 | 16.24 ± 0.49 |
Core i5-12500(DDR4-3200, 96GB) + RTX 3060 (12GB)
CUDA:RTX 3060 (12GB)
'-ngl 30'ぐらいが限界で、それ以上だとVRAM不足でOOMとなった。
- pp512/tg128
$ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 30 -fa 0,1
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3060, compute capability 8.6, VMM: yes
build: 711d5e6f (6068)
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 0 | pp512 | 399.85 ± 0.64 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 0 | tg128 | 26.33 ± 0.06 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 1 | pp512 | 412.71 ± 0.49 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 1 | tg128 | 26.70 ± 0.05 |
- pp8192/tg8192
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 0 | pp8192 | 328.18 ± 0.30 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 0 | tg8192 | 17.74 ± 0.23 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 1 | pp8192 | 395.15 ± 0.20 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 30 | 1 | tg8192 | 15.15 ± 0.07 |
CPU:Core i5-12500(DDR4-3200, 96GB)
- pp512/tg128
$ ./build/bin/llama-bench -m ../../models/Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf -ngl 0 -fa 0,1
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3060, compute capability 8.6, VMM: yes
build: 711d5e6f (6068)
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 0 | pp512 | 202.60 ± 0.16 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 0 | tg128 | 16.77 ± 0.01 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 1 | pp512 | 206.19 ± 0.09 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 1 | tg128 | 16.79 ± 0.18 |
- p8192/tg8192
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 0 | pp8192 | 171.52 ± 8.55 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 0 | tg8192 | 8.94 ± 2.76 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 1 | pp8192 | 196.35 ± 0.05 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 0 | 1 | tg8192 | 7.75 ± 0.01 |
RTX 3090(24GB)
- pp512/tg128
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 0 | pp512 | 2185.83 ± 25.50 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 0 | tg128 | 142.41 ± 0.92 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 1 | pp512 | 2350.00 ± 11.06 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 1 | tg128 | 144.78 ± 0.06 |
- pp8192/tg8192
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 0 | pp512 | 1528.01 ± 6.93 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 0 | tg128 | 95.43 ± 0.89 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 1 | pp512 | 2001.65 ± 1.08 |
| qwen3moe 30B.A3B Q4_K - Medium | 16.45 GiB | 30.53 B | CUDA | 99 | 1 | tg128 | 124.36 ± 0.89 |
llama.cppビルドメモ
- cpu, mps
$ git clone https://github.com/ggml-org/llama.cpp.git
$ cd llama.cpp
$ cmake -B build
$ cmake --build build --config Release
- CUDA
$ sudo apt update && sudo apt dist-upgrade && sudo apt install curl libcurl4-openssl-dev
$ git clone https://github.com/ggml-org/llama.cpp.git llama.cpp-cuda
$ cd llama.cpp-cuda
$ cmake -B build -DGGML_CUDA=ON
$ cmake --build build --config Release
- vulkan
$ git clone https://github.com/ggml-org/llama.cpp.git llama.cpp-vulkan
$ cd llama.cpp-vulkan
$ cmake -B build -DGGML_VULKAN=ON
$ cmake --build build --config Release
- ROCm 6.4.0
下記の記事にビルド方法が非常にわかりやすくまとめられていた。そのとおりにすることで問題なくビルドができた。
ただし非公式な導入方法であり、ROCm7.0の正式リリースで最適化されることに期待。
このスクラップは4ヶ月前にクローズされました