ローカルLLMのための最適なGPU選定:Mac Studio購入の決め手
はじめに
どんな人向けの記事?
- ローカルLLMに興味がある方
- ローカルLLM向けにGPUの購入を検討している方
内容
本記事では、ローカルLLMの推論に向いているGPUの選定を行います。
タイトルにある通り、結論から言うと私はM2 Ultra搭載のMac Studioを購入しました。
なぜ私が60万円以上もするMac Studioを購入するに至ったのか?その経緯を書き留めています。
検討項目
- ローカルLLMの推論向けに最適なGPUは何か?
- 今後のGPU販売計画も考慮して、今買うべきか待つべきか?
- Mac Studioを購入する際の具体的なスペックはどうすべきか?
背景
昨年、画像生成AI向けにNVIDIAのGeForce RTX 3060 (12GB)を購入しましたが、最近のローカルLLMの性能向上により、このGPUでは物足りなくなってきました。また、メインで使用している第8世代Core iシリーズのUbuntuマシンの買い替えも考えていました。
他にも、ローカルLLM性能の昨今の成長速度を考えると、比較的成長速度の遅いGPUの価値は時間とともに劣化するどころか、少しずつ増していくのではないかと考えたからです。
LLM推論時のボトルネック
当初、コンシューマ向けNVIDIA製GPUで最高性能を誇るGeForce RTX 4090(24GB)を購入するつもりでした。しかし、Meta-Llama-3-70Bのようなパラメータ数の多いモデルではVRAM 24GBでは不十分との情報を得て、LLM推論時のボトルネックについて調査しました。
その過程で非常に参考になったのが、うみゆきさんのポストです。
さらに、下記のベンチマーク結果がLLM推論時のボトルネック≒メモリ帯域幅説を確信に変えました。
実際に上記ベンチマーク結果とメモリ帯域幅の関係性をグラフにすると、下記の通りです。
-
生成速度
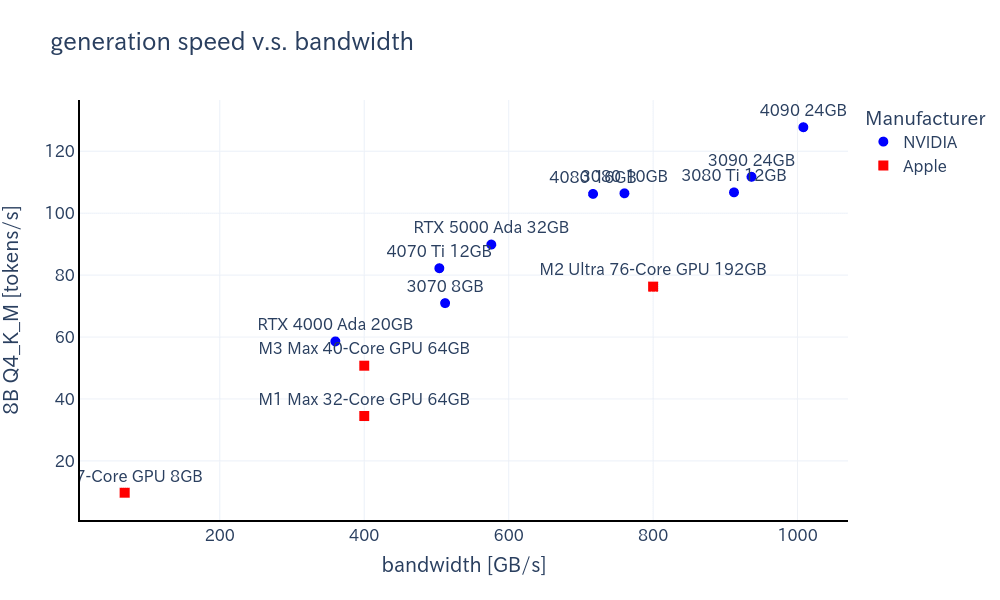
-
プロンプト評価速度
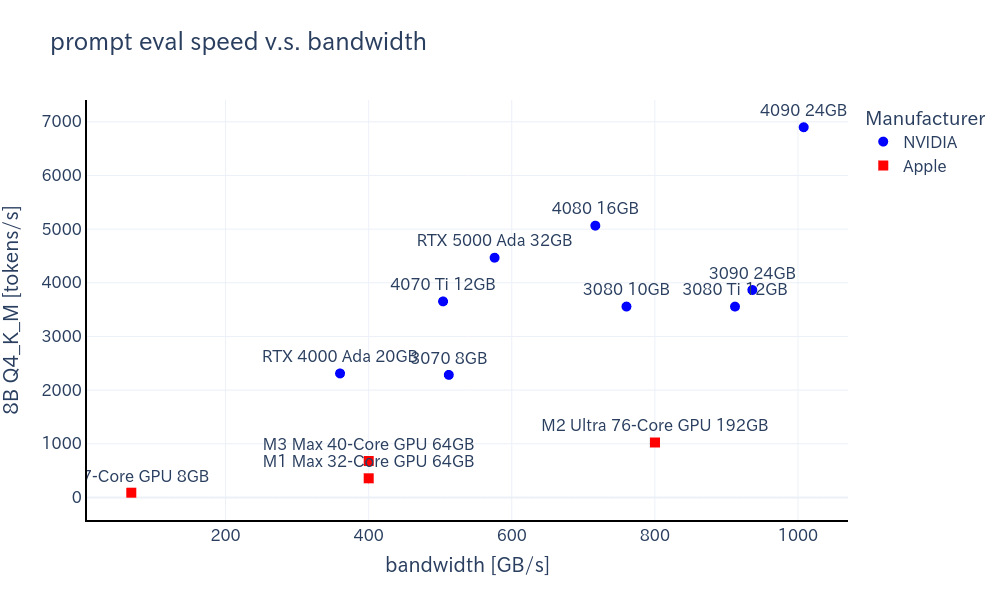
図から下記のことがわかります。
- メモリ帯域幅と生成速度はほぼ比例している。
- ただし、GPU性能にもある程度依存する。
- M1 MAXとM3 MAXはメモリ帯域幅が一致しているが、M3 MAXの方が生成速度が速い
- NVIDIA製GPUとApple siliconでは、NVIDIA製GPUの方が傾きが大きい(同じ帯域幅でも性能が高い)
-
プロンプト評価速度は圧倒的にNVIDIA製GPUの方が性能が高い。
- これはメモリ帯域幅よりもGPU性能の依存性が高いためだと考えられる。
- ただし生成速度と比べると10倍程度は速いので、生成速度を重視することにする。
なぜMacを選択したのか?
上記のグラフだけを見ても、NVIDIA製GPUではなくMacを選ぶ人はいないと思います。
それではなぜ私はMacを選択したのか?
NVIDIA製GPUではなくMacを選んだ理由は、推論速度よりもVRAM容量の大きさが重要だと判断したためです。
- 8Bモデルは12GBのVRAMで十分だが、70BモデルはQ4_K_Mに量子化した場合でも42.5GB以上必要。
- NVIDIA製GPUでこれを実現するには最低2枚以上のGPUが必要で、マザーボードやケース、電源等もそれに合わせてカスタマイズすると、マシンのコストが80〜100万円に達する。
- Mac Studioは1台で128 or 192GBのユニファイドメモリを搭載可能で、価格性能比が優れている(+64GBで12万円は破格)。
- モデル切り替えも考慮すると、メモリは多過ぎて困るということはない。
1GBあたりのコスト
下記は価格-VRAM容量の関係性を示しています。
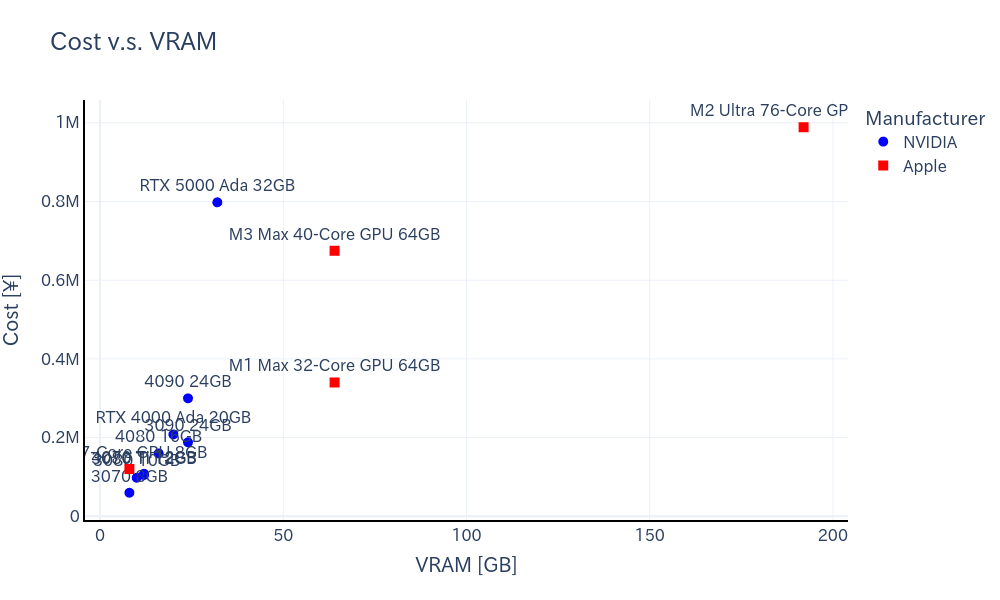
このグラフから、M2 Ultraの優位性は明らかです。もちろんGPUを複数枚用意すれば、同じだけのVRAM容量は実現できます。しかし、GBあたりの価格で見るとNVIDIA製の方が相対的に高コストであることがわかります。しかもこのグラフでは、NVIDIA製はGPU単体化の価格であるのに対し、Apple製は完成品の価格であることも留意すべき事実です。
ワットパフォーマンス
下記は、消費電力あたりの生成速度はNVIDIAとAppleで比較したグラフです。
量子化後の比較的小さなモデルではNVIDIA製の方が消費電力あたりの生成速度は速いですが、F16モデルではほとんど違いはありません。
-
8B Q4_K_M
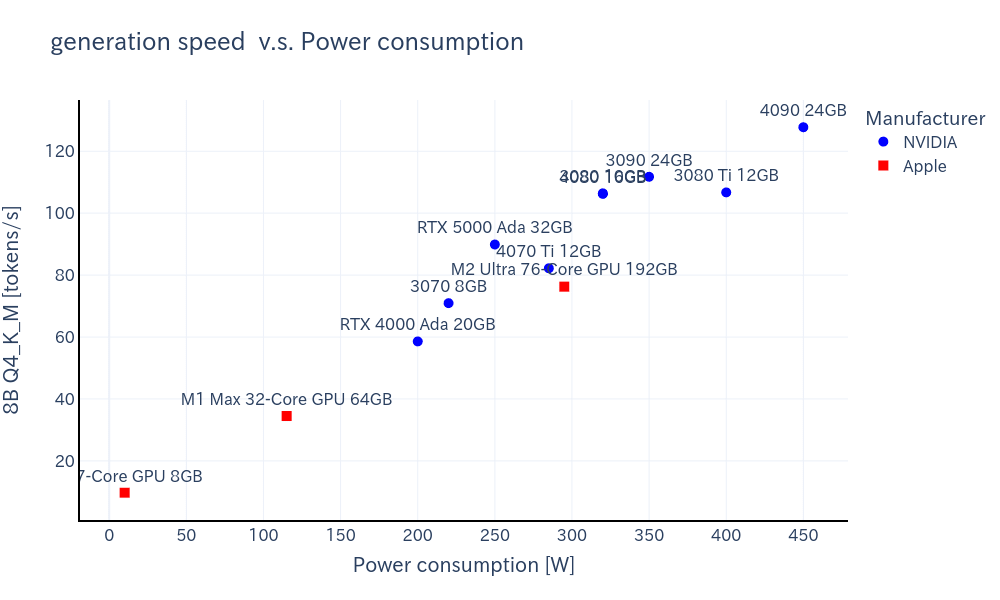
-
8B F16
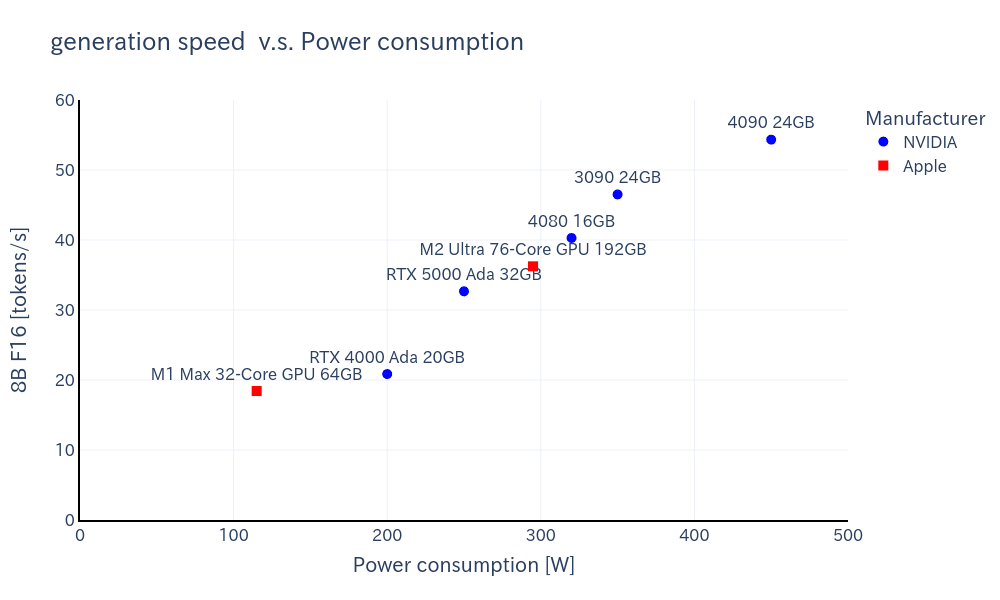
ただし詳細は別の記事に記載予定ですが、Mac Studioはアイドル時の消費電力が非常に低いのもポイントが高いです。
画像生成速度
Apple M2 Ultraでも画像生成自体はできるものの、残念ながらNVIDIA製GPUと比べて生成速度はかなり遅いようです。

出典:GeForce RTX環境で「Stable Diffusion Web UI」を高速化、NVIDIA自家製ツール登場
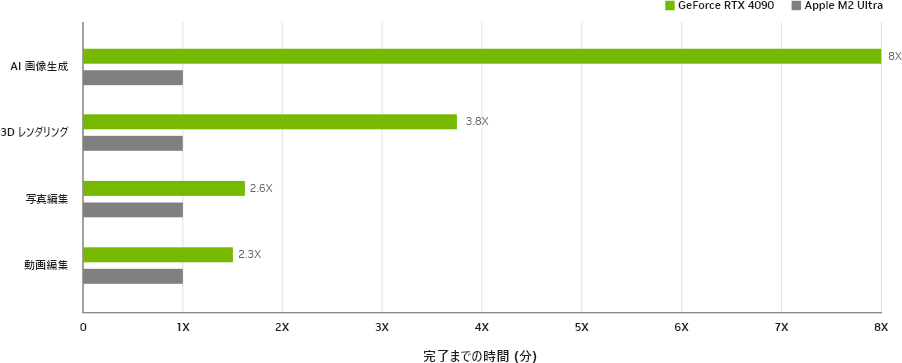
出典:マウスコンピュータ公式HP(クリエイティブ制作の高速化)
選定理由まとめ
まとめると、ローカルLLM向けGPUとしてM2 Ultra搭載Mac Studioを選定した理由は下記の通りです。ただし、重要度は個人の主観によるものです。
| 項目 | 重要度 | NVIDIA | Apple | Appleの特徴・備考 |
|---|---|---|---|---|
| VRAM容量 | ★★★★★ | △ | ◎ | 現状代替製品がほぼない |
| テキスト生成速度 | ★★★ | ◎ | ○ | NVIDIAより遅いが、気になるほどではない |
| プロンプト評価速度 | ★★ | ◎ | △ | NVIDIAよりかなり遅いが、生成時間が支配的となることが多い |
| 画像生成速度 | ★ | ◎ | ☓ | 画像生成には向かない |
| 消費電力 | ★★ | ○ | ◎ | アイドル時の省電力性は魅力的 |
| コスト | ★★★ | 高い | 高い | 80万円〜100万円 (Mac Studio) |
| 拡張性 | ★★ | ◎ | ☓ | 拡張性なし(eGPUも使えない) |
こうして見てみると、Apple siliconがNVIDIA製GPUに勝っている部分はほとんどないことがわかります。加えて、私はアップル製品を他に一つも持っておらず、iPhoneやiPadとの連携ができると言ったメリットもありません。
それでもなお、M2 UltraのVRAM容量の大きさは選定する理由として十分であるという結論に至り、購入を決断しました。
M4 Ultraまで待つべき?
公式からの発表ではないですが、下記の予想スケジュールを見て来年夏以降までは待てないと思い、今買うことを決断しました。
次はM3 UltraではなくM4 Ultraが登場するそうなので、飛躍的な性能向上が期待できると思ってます。購入を検討していて、来年中頃まで待てる人は待ってから購入することをおすすめします。
| 時期 | 発売予定 |
|---|---|
| 2024年末から | M4チップのローエンド14インチMacBook Pro 24インチiMac |
| 2024年末〜2025年初頭 | M4 Pro/Maxチップ搭載のハイエンドの14インチ 16インチMacBook Pro M4/M4 Proチップ搭載のMac mini |
| 2025年春 | M4チップ(M4 Pro/Max?)のMacBook Air |
| 2025年中頃 | ハイエンドM4チップ(M4 MAX/M4 Ultra?)を搭載したMac Studio |
| 2025年後半 | M4 Ultraチップ搭載MacPro |
購入したMac Studioのスペックと価格
最後に、私が購入したMac Studioのスペックと価格を紹介します。

出典:Wikipedia
- 私が購入したMac Studioのスペックの情報
| 項目 | 説明 | 備考 |
|---|---|---|
| 製品名 | Mac Studio(2023) | |
| チップ | M2 Ultra | |
| CPUコア | Pコア16基 + Eコア8基 | |
| GPUコア | 60コア | +10万で76コアにする価値はないと判断※追記 |
| ユニファイドメモリ | 128GB | 台数限定の整備済製品のため、+10万の192GBモデルを選べなかったことだけが唯一の心残り |
| メモリ帯域幅 | 800GB/s | |
| ストレージ | 2TB | 2TBだけでは心もとないので、別途外付けSSDを購入 |
| 価格(税込) | ¥651,800 | 定価:¥778,800 |
ちなみに、私が買ったのは整備済製品で、定価の約15%オフで購入することができました。選択肢が少ないのが難点ですが、少しでも安く買いたい方はおすすめです。
2024-08-09追記
GPUコアを含むApple Siliconの推論速度評価は、llama.cppのgithubにて調査結果がまとめられていました。
この調査結果については、うみゆきさんがわかりやすくまとめてくれています。
プロンプト評価速度に関しては、76コアにすることで60コアよりも25%程度の性能向上が見込めるので、+10万円のコスト増とのトレードオフで判断すればよいかと思います。
まとめ
最初の記事にしてはだいぶ長くなってしまいましたが、本記事では私がローカルLLM推論用のマシンとしてMac Studioを購入するに至った経緯を紹介しました。
今後の執筆方針
今後の予定としては、Mac Studio開封・ローカルLLM環境整備などの記事を少しずつ書いていくつもりです。その後は、主に生成AI関係の記事を書きつつ、たまに米国経済や資産運用シミュレーションに関する記事なども書きたいと思ってます。あとは、新しいローカルLLM等が登場したら使用感等をクイックにまとめる方針です。
最後まで読んでいただきありがとうございました。これからもよろしくお願いします。
Discussion