ローカルLLMでGraphRAGを動かしてみた
はじめに
どんな人向けの記事?
- ローカルLLMに興味のある方
- GraphRAGに興味のある方
Mac Studio(M2 Ultra 128GB)
内容
今回は、Microsoftが2週間ほど前にgithubに公開したGraphRAGを試してみようと思います。
GraphRAGとは何なのかを説明できるほど理解できていないので、使いながら理解していくスタイルで進めていきます。
環境構築等で躓いたところなども、できるだけ省略せずに記載していこうと思います。
結論
結論から述べると、下記の通りになりました。
- GraphRAGのGet Startedページに従って導入したものの、実行中にエラーが出たため断念。
- GraphRAG-Ollama-UIを使うことで、かなり簡単に環境構築ができた。
- 日本語文書のRAGは成功しなかった。原因と解決策は調査中。
- 英語文書のRAGには成功。精度としては、悪くない印象。
GraphRAGの導入
Get Started
まず最初に、GraphRAGの導入をします。
最初、GraphRAGのGet Startedページに従って導入したのですが、こちらは実行中にエラーが出て解決策が見つからなかったので一旦断念しました。
どんなエラーが出たかだけ書き留めておきます。logを見ても、原因が全く理解できませんでした。
⠴ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_base_text_units
├── create_base_extracted_entities
├── create_summarized_entities
└── create_base_entity_graph
❌ Errors occurred during the pipeline run, see logs for more details.
GraphRAG-Ollama-UI
上記エラーの解決策を探していたところ、GraphRAG-Ollama-UIなるものがgithubで公開されているのを発見しました。
見たところ、下記のような特徴があるようです。
- GraphRAGをgradioのUIでインタラクティブに扱える
- デフォルトでOllamaに対応
これは使えそうだ!と思い、早速GraphRAG-Ollama-UIで環境構築をすることにしました。
実際、GraphRAG-Ollama-UIは非常に簡単に使えるところまでいけました。
- GraphRAG-Ollama-UIのクローン〜実行まで
$ git clone https://github.com/severian42/GraphRAG-Ollama-UI.git
$ cd GraphRAG
$ python3 -m venv graphrag-ollama
$ source graphrag-ollama/bin/activate
$ gradio app.py
ここで下記のようなエラーが出ました。
ModuleNotFoundError: No module named 'distutils'
これは下記のコマンドで解決できます。
$ pip install setuptools
もう一度$ gradio app.pyを実行することで、gradioが起動します。
ブラウザでlocalhost:7860にアクセスすれば下記のような画面が表示されるはずです。
以上でインストールは完了です。
GraphRAG-Ollama-UIの使い方
Settings
gradio上のSettingsタブで、私が変更した部分のみ記載します。
- chunks
{
"group_by_columns": [
"id"
],
"overlap": 128,
"size": 512
}
chunksサイズは512トークン、オーバーラップ量は25%の128トークンが良いという記事があったので、そのように設定しました。
- embeddings
{
"async_mode": "threaded",
"llm": {
"api_base": "http://localhost:11434/api",
"api_key": "${GRAPHRAG_API_KEY}",
"concurrent_requests": 10,
"model": "avr/sfr-embedding-mistral:f16",
"type": "openai_embedding"
}
}
- llm
{
"api_base": "http://localhost:11434/v1",
"api_key": "${GRAPHRAG_API_KEY}",
"concurrent_requests": 10,
"model": "qwen2:72b-instruct-q4_K_M",
"model_supports_json": true,
"type": "openai_chat"
}
LLMモデルの選定
上記ではモデルとしてqwen2:72b-instruct-q4_K_Mを設定していますが、正直ここに何を選ぶべきかまだ答えが出ていません。EZO-Hummanities-9B-gemma-2-itやgemma-2-9b-itなどで試したところ、後述するindexingには成功するのですが、質問しても下記のようなエラーが出てうまく機能しませんでした。
FileNotFoundError: [Errno 2] No such file or directory: '/Volumes/20240625/AI/GraphRAG-Ollama-UI/ragtest/output/20240715-191122/artifacts/create_final_nodes.parquet'
正確な原因究明ができていませんが、context windowの短さが一因かもしれません。ちなみに、llama3:8b-instruct-fp16ではうまくいきました。
また、日本語文書のGraphRAGがうまく動作しなかったので、本記事では英語の文書でGraphRAGをしています。ただし、プロンプトは日本語で入力する予定なので、一旦qwen2:72b-instruct-q4_K_Mを採用しています。Indexingや回答の生成が遅いので、とりあえずllama3-8bでも良いかと思います。
embeddingモデルの選定
正直embeddingモデルについては、勉強不足のためそれが何なのか理解しきれていません。
勉強は今後するとして、何を使うべきかという観点で調査しました。
その結果、MTEBのベンチマークでわりとハイスコアを出していて、かつollama libraryに登録してあったavr/sfr-embedding-mistralモデルを採用することにしました。
実行
今回読み込む文章として何を入れるべきか悩んだのですが、下記を採用しました。
- 走れメロスの英文で、MelosとSelinuntiusの文字列を入れ替えたもの
理由は下記のとおりです。
- 走れメロスは有名であり、検索すれば正解がわかりそうなこと。
- 本文そのままだとLLM自身が持つ知識で答えてしまう可能性があるため、あえて役割を入れ替えました。
Indexingの実行
-
txtファイルの格納
./ragtest/inputにtxtファイルを入れます。 -
テキストファイルの選択
gradio上で、File Management->Select FileでRefresh File Listをクリックすると、先ほど格納したtxtファイルが選択できるようになっているはずです。
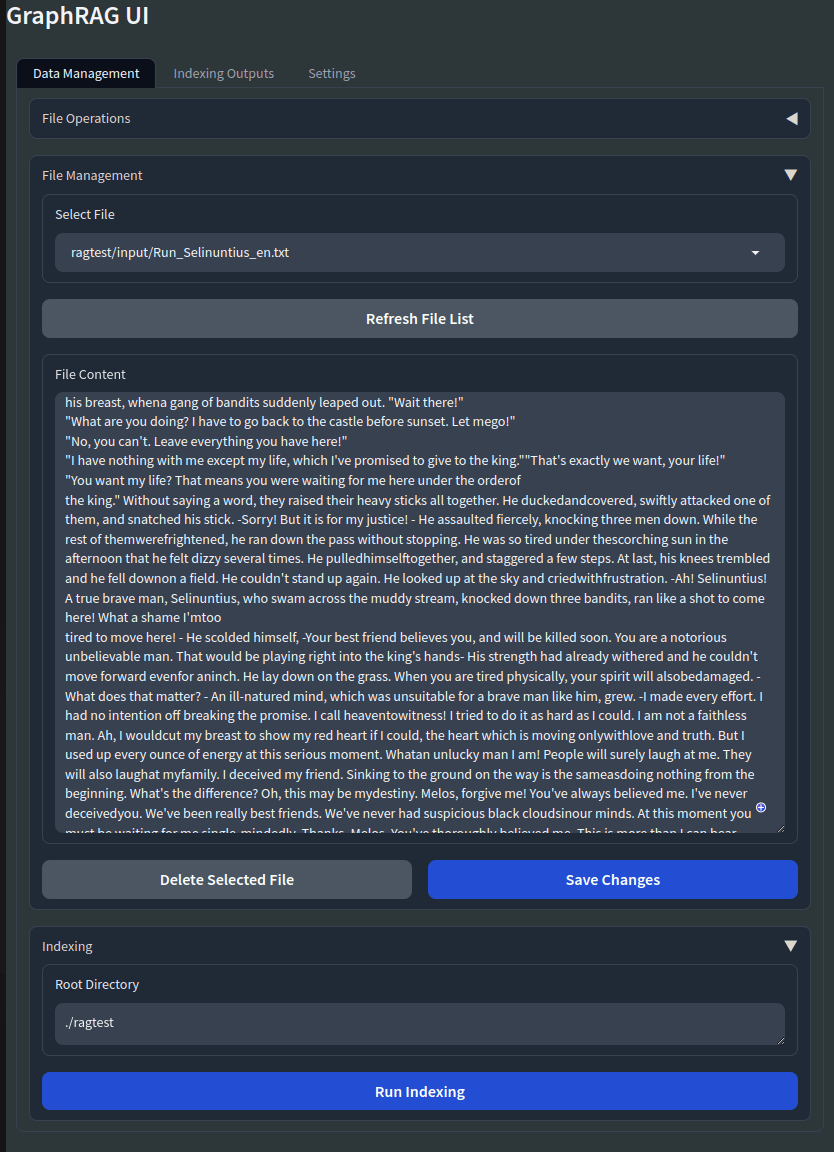
Save Changesをクリックする。
- Indexing
gradio下部のRun Indexingをクリックすると、Indexingがスタートします。
文書のトークン数やモデルパラメータ数、GPU等に依存しますがこの工程はかなり時間がかかります。ちゃんと測定していませんが、私の環境では10分〜1時間程度はかかったと記憶しています。
無事に終われば、gradio左下のLogsウィンドウに下記のようなメッセージが出力されます。
Running indexing command: python -m graphrag.index --root ./ragtest
Indexing completed
問題なく完了していれば、Graphを可視化したり右側のWindowで質問することができるようになります。
Graphの可視化
gradio上でもグラフは描画できるのですが、正直小さくて見にくいので端末から実行しています。
$ python visualize-graphml.py
ただし、visualize-graphml.pyの下記の部分は適宜修正してください。
# Load the GraphML file
graph = nx.read_graphml('output/20240708-161630/artifacts/summarized_graph.graphml')
得られたグラフは下記の通り。
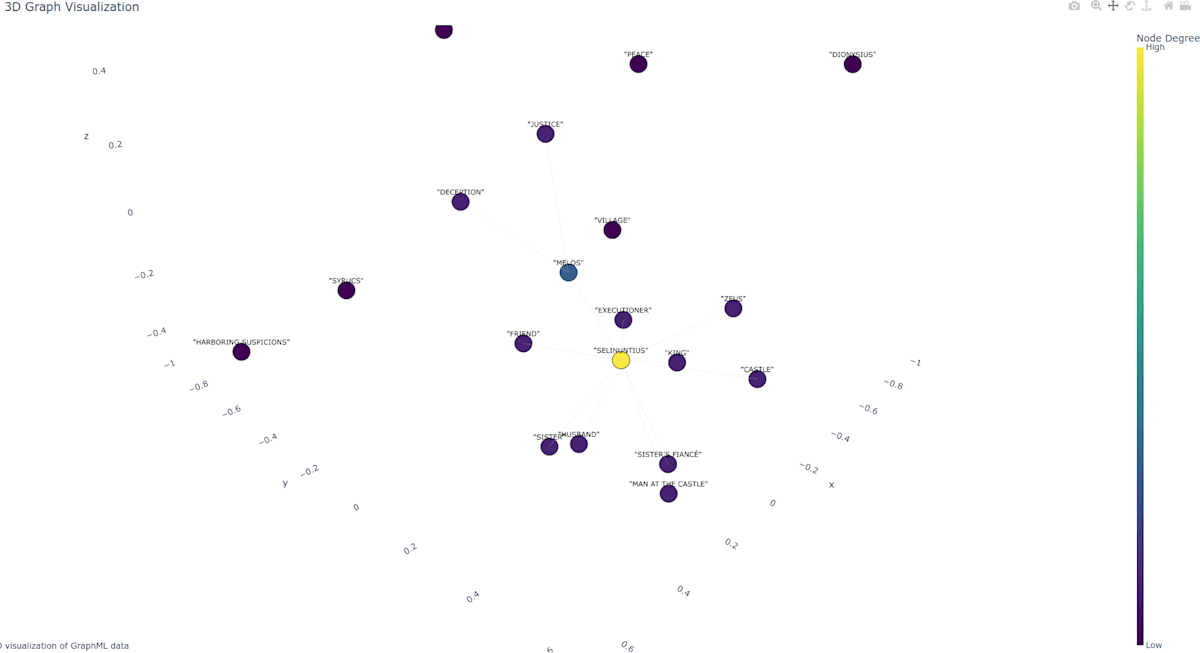
この話ではMelosではなくSelinuntiusが主人公なので、Selinuntiusが真ん中に来ています。
SelinuntiusとMelosのNode Degreeが高いですが、これが何を意味しているのかはまだ説明できるほど理解できていません。。。機会があれば別の記事で紹介します。
質問と回答
RAGとして機能しているかを確認するために、いくつか質問してみました。
- 質問1
なぜセリヌンティウスは走っていたのですか?
SUCCESS: Global Search Response: セリヌンティウスが走っていた主な動機は二つありました。
まず、彼の最良の友人が人質に取られているという深刻な状況がありました。この危険から友人を解放するためには迅速な行動が必要であり、これが彼が全力で走った第一の理由でした [Data: Reports (4)]。
次に、セリヌンティウスは時間内に城へ到着しなければならなかったという制約がありました。これは彼の友人の命運に関わる期限であり、この要件を満たすためにも彼は走り続けました [Data: Reports (4)]。
これらの理由から、セリヌンティウスは全力で走り続け、その目的達成に向けて努力しました。
→間違っていなさそうです。
- 質問2
メロスはどうして捕らえられたのでしょうか。
SUCCESS: Global Search Response: 具体的な詳細については提供されたデータには含まれていません [Data: Reports (4, 5)]。そのため、メロスがなぜ捕まえたのかについての明確な回答を提供することはできません。
以上のことから、メロスがどうして捕らえられたのかという問いに対しては、現段階では確定的な答えを与えることができません。詳細な情報が必要な場合は、関連するレポート (4, 5) を参照してください。
入力した物語では、捕まったのはセリヌンティウスで、メロスは人質という役割です。
明確な回答がないという説明は、正しいか間違っているかと言うと微妙なところですね。
質問があまり良くなかったかもしれません。
- 質問3
セリヌンティウスは、どんな災難にあったのでしょうか?
SUCCESS: Global Search Response: ## セリヌンティウスの試練と冒険
友人の危機
セリヌンティウスが直面した最も深刻な事態は、彼の最良の友人が人質に取られたことでした [Data: Reports (4)]. この状況を解決するため、彼は一連の困難と試練に立ち向かう旅に出ました。
旅行中の挑戦
セリヌンティウスが城へ向かう道中で遭遇した困難は数多くありました。時間の制約や敵対的な存在からの脅威を克服する必要がありました [Data: Reports (4)]. 彼の旅は単なる移動以上のものであり、彼自身の勇気と決断力が試される場でした。
バンディットとの戦い
バンディットたちから身を守るためには、セリヌンティウスは勇敢さを発揮しなければなりませんでした。これらの敵は王の命令で彼を排除しようとしていましたが、彼は彼らに打ち勝ちました [Data: Reports (5)]. この戦いは彼の生存だけでなく、その意志と力の証でもありました。
王との対立
セリヌンティウスはさらに王自身と対峙し、その歪んだ性格に対抗しなければなりませんでした。この対立は単なる生存の問題ではなく、彼が自身の安全を確保するために提案した取引も含まれていました [Data: Reports (5)]. この状況下でセリヌンティウスは、自分の目的と信念を守り抜く決意を固めました。
上記は、かなり正しい回答になっているのではないでしょうか?
まとめ
今回は、ローカルLLMでGraphRAGを使えるか試してみました。
結論としては、下記のとおりです。
- GraphRAG-Ollama-UIを使うことで、かなり簡単に環境構築ができた。
- 英語文書のRAGには成功。精度としては、悪くない印象。
日本語文書のRAGに成功しなかったことなど、実用上はいくつか課題があります。
embeddingモデルや可視化されたGraphの見方など、引き続き理解を深めていきたいと思います。
ここまで見ていただきありがとうございました。次回もぜひ、よろしくお願いします。
Discussion