【自然言語処理】【Python】有価証券報告書のテキストデータをt-SNEとPlotlyを使って可視化した
はじめに
t-SNEという手法を用いて、高次元の文章ベクトルを低次元に圧縮したうえで、 PythonライブラリーのPlotlyを用いてインタラクティブに可視化してみました。
t-SNEについて
ディープラーニングの父と呼ばれるジェフリー・ヒントンによって開発されたアルゴリズムです。(2008年発表)
高次元の世界におけるデータ間の距離を条件付き確率で求め、低次元の世界でも同様の確率分布を想定したうえでデータ間の距離を求めにいくものです。
具体的には、高次元・低次元の2つの分布間の距離の指標であるカルバック・ダイムラー情報量をコスト関数として、それを最小化するように低次元データを求めにいくイメージです。
ちなみに、高次元の世界は正規分布を前提としていますが、低次元の世界は自由度1のt分布を前提としています。これはt分布の方が、正規分布より裾野が広いため、近いデータはより近く、遠いデータはより遠くと特徴を捉えやすくするためです。t-SNEのtは、t分布から来ています。
文章データとモデルの準備
文章データについては、上場企業2,500社が有価証券報告書で公表している「事業等のリスク」(2022年3月期分)を使いました。
以下のリンクで、文章データとモデル(Doc2Vec)の取得方法についてご紹介していますので、ご覧ください
文章データ(有価証券報告書)の取得
モデルの取得
文章データの呼び出し
import pandas as pd
df = pd.read_csv("/content/2203有報セット.csv",index_col=0)
df
今回は、以下のようなデータフレームを準備しました。

モデルの呼び出し
import pickle
with open("/content/doc2vec_2203有報_事業等のリスク.pkl","rb") as f:
model = pickle.load(f)
モデルに格納されている文章ベクトルを縦方向に連結します
import numpy as np
sentence_vectors = np.vstack(model.docvecs.vectors_docs)
ライブラリーのインストールとインポート
from sklearn.manifold import TSNE
import plotly.express as px
!pip install japanize_matplotlib
import japanize_matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
t-SNEで2次元に圧縮
引数:n_components=2で2次元に圧縮します。
vectors_tsne = TSNE(n_components=2).fit_transform(sentence_vectors)
Plotlyでインタラクティブに可視化
業種別に色をつけて可視化します。
hover_data = ['corp']とすることでカーソルを合わせた時に会社名が表示されるようにしています。
def tsne_2d_plotly(df,vectors):
df_2d = pd.DataFrame(vectors).reset_index()
df_2d["corp"] = df.reset_index()["会社名"]
df_2d["業種"] = df.reset_index()["提出者業種"]
fig = px.scatter(
df_2d, x=0, y=1,width=1000,height=1000,
color="業種",labels={"color":"業種"},hover_data = ['corp']
)
fig.update_traces(marker_size=5)
fig.update_layout(plot_bgcolor="white")
fig.show()
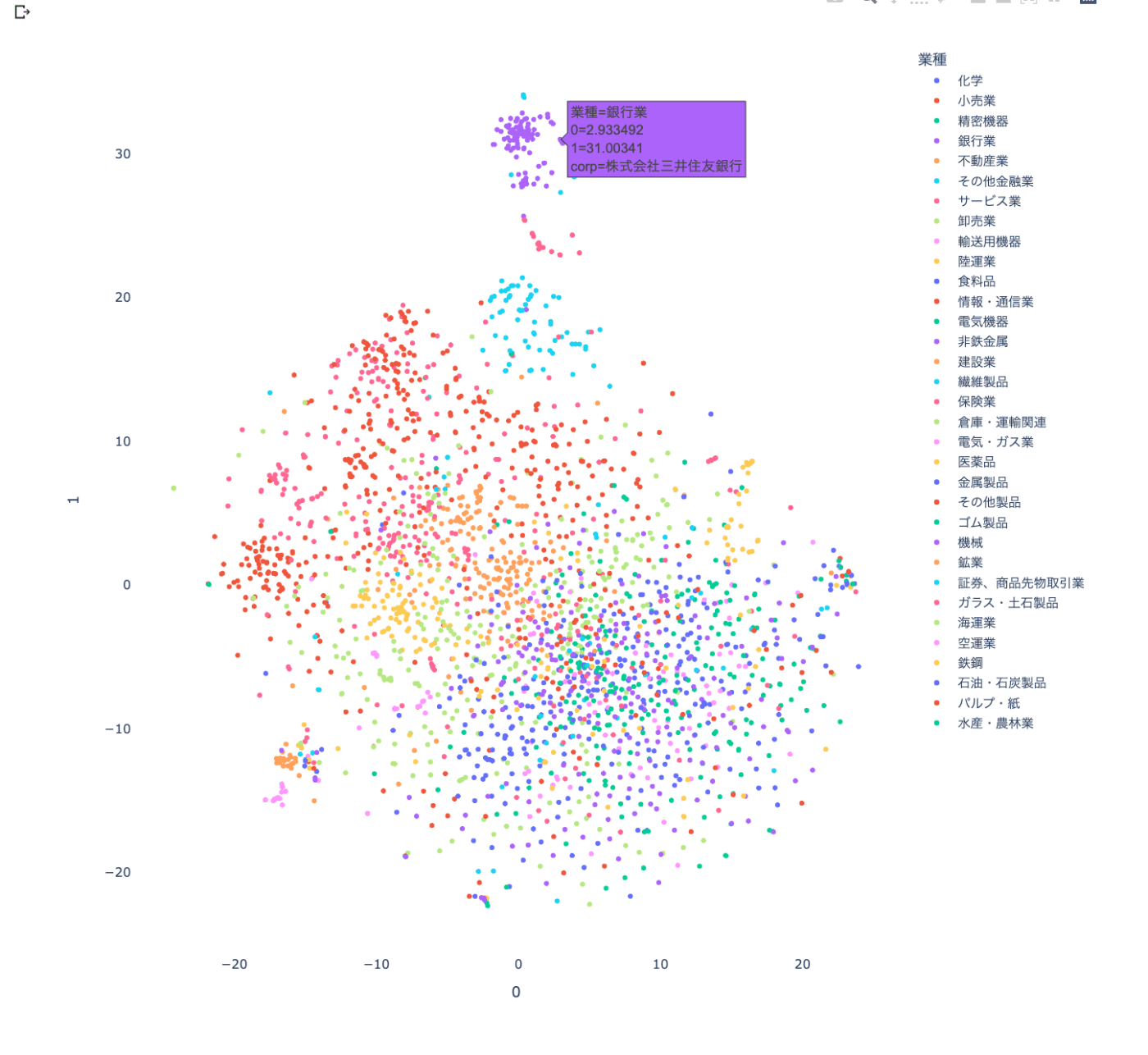
tsne_2d_plotly(df,vectors_tsne)
出力結果
銀行業やその他金融はちゃんと分かれていますね。
その他の業種は分かりにくいですね。
t-SNEで3次元に圧縮
引数:n_components=3で3次元に圧縮します。
vectors_tsne_3d = TSNE(n_components=3).fit_transform(sentence_vectors)
Plotlyでインタラクティブに可視化
def tsne_3d_plotly(df,vectors):
df_3d = pd.DataFrame(vectors).reset_index()
df_3d["corp"] = df.reset_index()["会社名"]
df_3d["業種"] = df.reset_index()["提出者業種"]
fig = px.scatter_3d(
df_3d, x=0, y=1, z=2,width=1200,height=1000,
color="業種",labels={"color":"業種"},hover_data = ['corp']
)
fig.update_layout(plot_bgcolor="white")
fig.update_traces(marker_size=2)
fig.show()
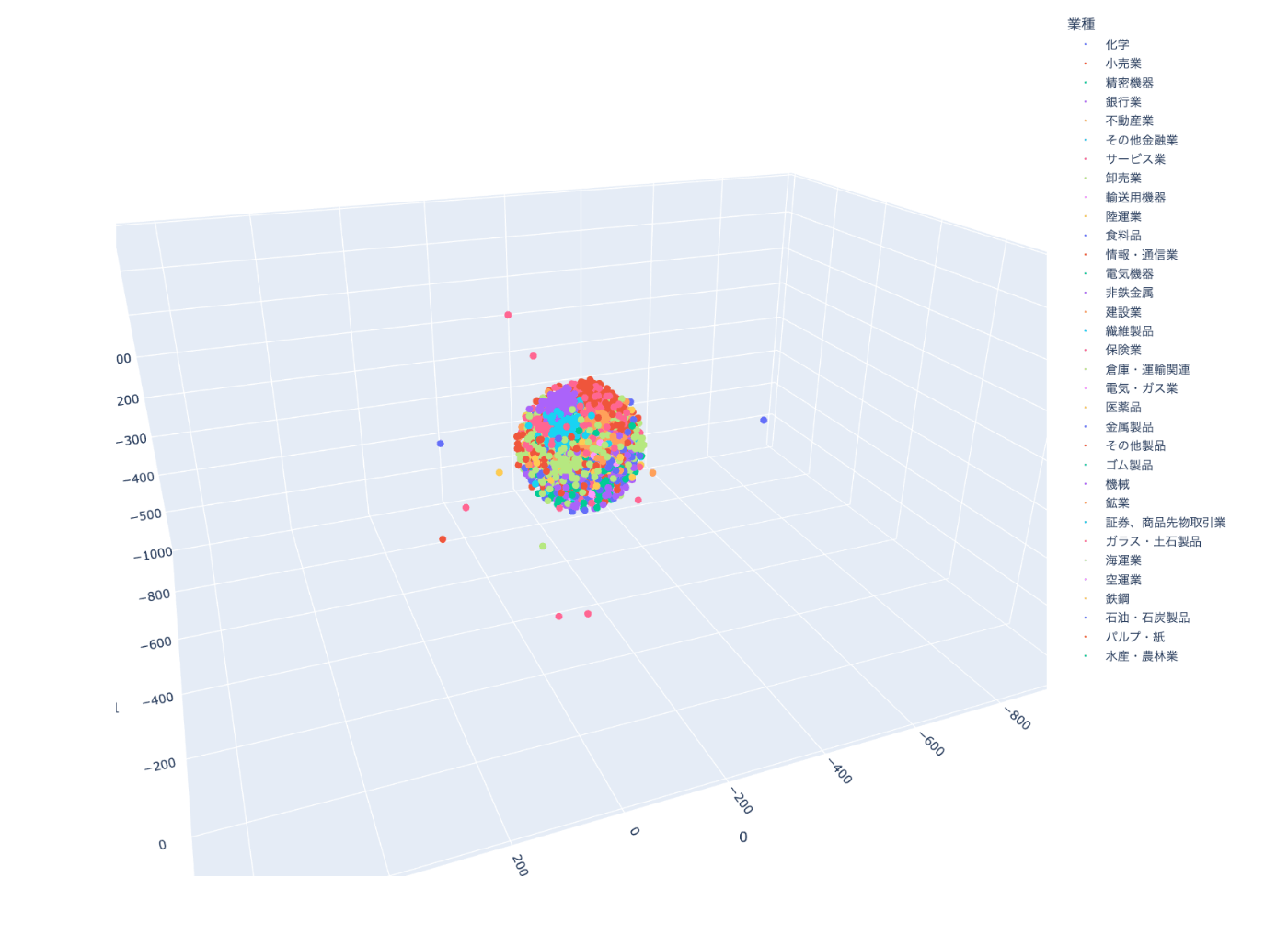
tsne_3d_plotly(df,vectors_tsne_3d)
出力結果
2次元より分かりにくですね。
しかし、全体として綺麗な球体になることは驚きでした。
これは何を意味するのでしょうか。
見る角度を変えたり
ズームにしたりできます
もう少し分かりやすく可視化する
さきほどの2次元圧縮のパターンですが、一つのグラフに33業種を詰め込んでしまったので、かえって、分かりにくくなってしまいました。
業種別に文章ベクトルの散布図を作成することで、もう少しわかりやすく可視化してみたいと思います。
業種ラベルの作成
2203有報データ.csvに収納されている業種ラベル(数字)を取得し、np.array化します。
#ラベルの作成
def make_label(df,column_number):
labels=[]
for i in range(len(df)):
labels.append(df.iloc[i,column_number])
return labels
#業種ラベルの作成
labels = make_label(df,7)
labels = np.array(labels)
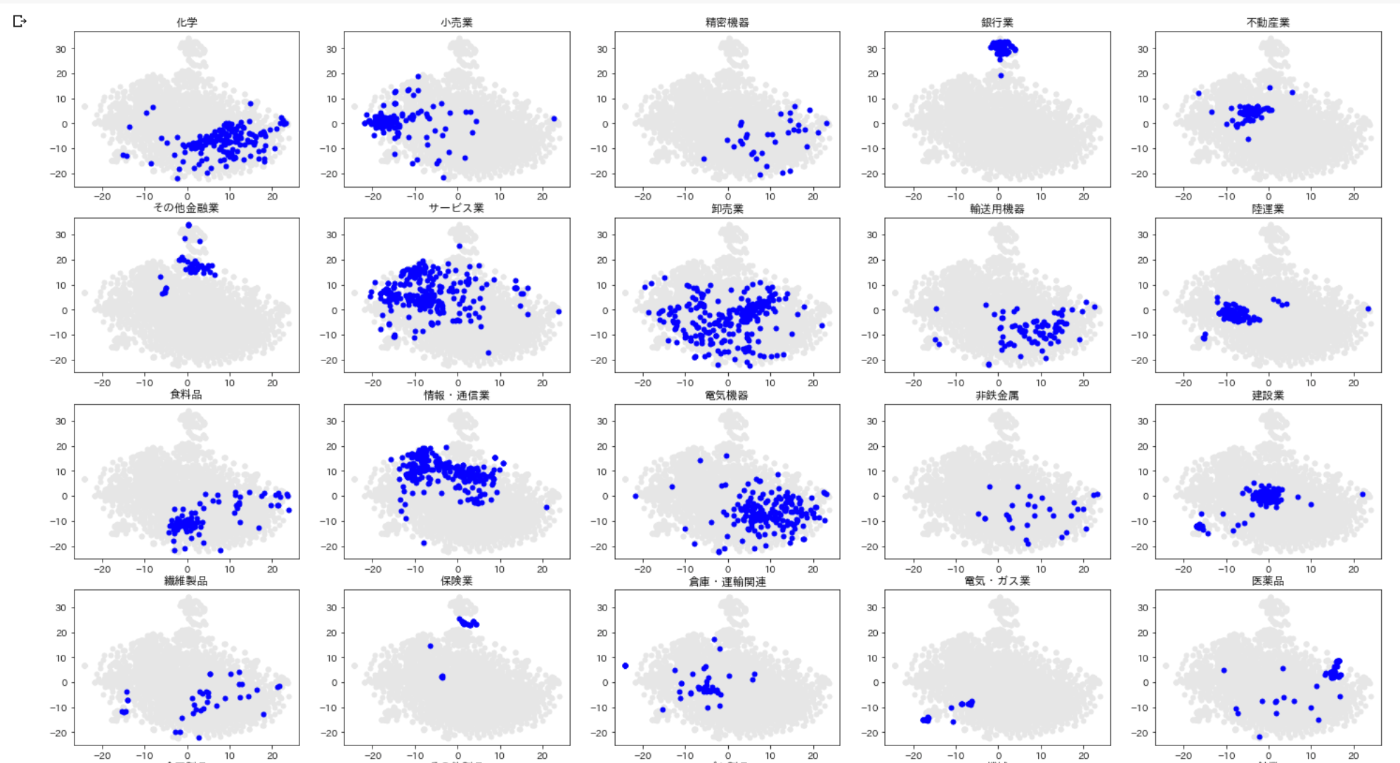
matplotlibで業種別に可視化
def tsne_2d(df,vectors,labels):
list = df["提出者業種"].unique().tolist()
plt.figure(figsize=(15,45))
for label in range(len(list)):
plt.subplot(11, 3 , label +1)
index = labels ==label
plt.plot(
vectors_tsne[:, 0],
vectors_tsne[:, 1],
'o',
markersize = 5,
color = [0.9,0.9,0.9]
)
plt.plot(
vectors_tsne[index,0],
vectors_tsne[index,1],
'o',
markersize = 5,
color ='b'
)
plt.title(list[label])
出力結果
こちらの方が視覚的には分かりやすいですね。

さいごに
いかがでしたでしょうか。
plotlyは簡単で、しかもインタラクティブな可視化ができて便利ですね。
しかし、時と場合によっては、plotolyに頼らず、愚直にひとつひとつの動きを細かくみていくのが良い時がありそうです。使い分けのバランスが大事ですね。
Discussion