🚀
【画像生成】Python初心者でも話題のStableDiffusionを爆速で実装できた
はじめに
話題の画像生成AIStableDiffusionを、GoogleColaboratoryを使って爆速で実装することができました。(正味30分程度で実装できました)
ここでは、実装方法などについて、余計な説明なしに爆速でご紹介したいと思います。
StableDiffusionとは
テキストから画像を生成してくれるオープンソースのAIです。
いわゆるText to Imageというやつです。
2022年8月に英Stability AIが、HuggingFaceで無償公開しました。
それでは実装方法を見ていきましょう
HuggingFaceでのアクセストークンの取得
StableDiffusionを利用するには、HuggingFaceでアクセストークンを取得する必要があります。
以下の手順で、アクセストークンを取得していきましょう。
HuggingFaceでアカウントを作成する
こちらにアクセスしてアカウントを作成します

StableDiffusionモデルの利用規約に同意する
こちらにアクセスして記載内容を確認の上、チェックボックスにチェックを入れて承認します。

アクセストークンを取得する
承認後に右上のアイコンからsettingsを選択。
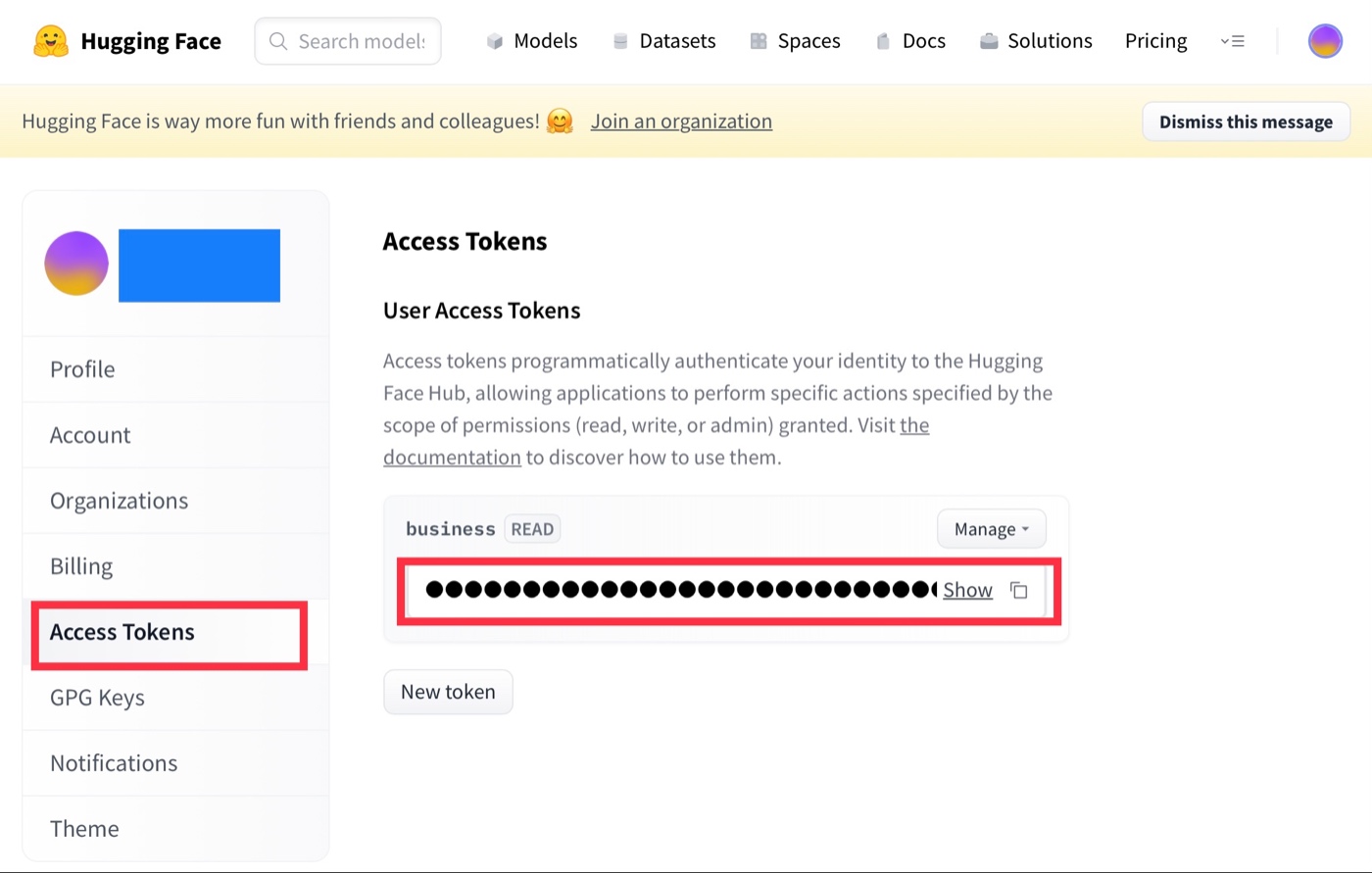
Access TokensからNewTokenを発行し、コピーしてどこかに貼り付けておきます。
ここからはGoogleColaboratoryで実装していきます。
ライブラリーのインストール
%cd /content
!pip install diffusers==0.2.4 transformers scipy ftfy
モデルの生成
# ライブラリーのインポート
from diffusers import StableDiffusionPipeline
import matplotlib.pyplot as plt
# アクセストークンの設定
access_tokens="ここに先ほどのアクセストークンを貼り付けます" # @param {type:"string"}
# モデルのインスタンス化
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=access_tokens)
model.to("cuda")
生成したい画像のテキストを入力
テキストを英語で入力します。
ここでは「シャガールが書いた東京スカイツリー」としました。
prompt = "Tokyo Sky Tree by Marc Chagall" #@param {type:"string"}
画像生成
画像出力のディレクトリを作成した上で、テキストに基づいて4つの画像を生成します。
画像ファイル名はpromptを参照しています。
# 画像出力のディレクトリ
!mkdir outputfile
# 画像のファイル名
import re
filename = re.sub(r'[\\/:*?"<>|,]+', '', prompt).replace(' ','_')
# 画像数
num = 4
for i in range(num):
# モデルにpromptを入力し画像生成
image = model(prompt,num_inference_steps=100)["sample"][0]
# 保存
outputfile = f'{filename} _{i:02} .png'
image.save(f"outputfile/{outputfile}")
for i in range(num):
outputfile = f'{filename} _{i:02} .png'
plt.imshow(plt.imread(f"outputfile/{outputfile}"))
plt.axis('off')
出力結果
シャガールが書いた東京スカイツリー①

シャガールが書いた東京スカイツリー②

フェルメールが書いた亀

ゴッホが書いた東京スカイツリー

ピカソが書いたado

その他①

その他②

さいごに
いかがでしたでしょうか。
GoogleColabであれば簡単に実装できると思います。
いやはや、この画像生成AIには大変驚かされました。
今後、Artの考え方がガラリと変わるかもしれませんね。
ぜひ、StableDiffusionをお楽しみください。
Discussion