【自然言語処理】【Python】トピックモデル(LDA)を実装し、PyLDAvisを使ってインタラクティブに可視化する
はじめに
SNSでのツイートや、ECサイトでの購買ビューから、消費者の行動や嗜好を分析するの使われる手法として、トピックモデルがあります。
ここでは、トピックモデルのうち最も有名なLDA(潜在的ディリクレ配分法) について、簡単な概要とともにPythonを使ってどのように実装していくのかを紹介していきます。
また実装結果について、PyLDAvisやワードクラウドを使って可視化していきたいと思います。
トピックモデル(LDA)とは
トピックモデルとは、文書が複数の潜在的なトピックから確率的に生成されると仮定したモデルです。トピックモデルでは、トピックごとに単語の出現頻度分布を想定することで、トピック間の類似性やその意味を解析できます。
これがトピックモデルの一般的な説明ですが、やや、わかりにくいですよね。
分かりやすく言うとこうです。
トピックモデルとは、文書を構成する各単語はトピックに基づいて作られると仮定したモデルです。トピックとは、テーマや主題、分野のようなものです。
例えば、アメリカのバイデン大統領と日本の岸田総理大臣がゴルフをしたという文書には、政治・スポーツ・国際の3つのトピックが入っていますね。
このように一つの文書は複数のトピックを持ちます。LDAでは各文書の単語ごとにトピックがあると仮定して、各単語はそのトピックからある確率で生成されたと考えます。つまり一つの文書に、政治っぽい単語があれば政治トピック、スポーツっぽい単語があればスポーツトピックのウェイトが高くなります。
なお、トピックモデルはある意味、クラスタリング(分類)の一種ですが、k-means法などと違って、分類ごとに重なりを許す構造となっています。
それではGoogleColabolatoryで実装していきましょう
MeCabと辞書(NEologd)のインストール
トピックモデルの実装においても、適切な形態素解析が大切になってきます。MeCabとともに、優秀な辞書であるNEoLogdを使っていきましょう。
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
必要なライブラリーのインポート
import pandas as pd
import MeCab
import re
from sklearn.feature_extraction.text import CountVectorizer
from gensim.corpora.dictionary import Dictionary
from gensim.models import LdaModel
from tqdm import tqdm
import numpy as np
データの準備
トピックモデルを使って分析を行うデータを用意します。
毎度のことですが、上場企業2,500社が開示している有価証券報告書の非財務情報を使いたいと思います。今回はこの中でも「経営方針」を分析対象とします。
df = pd.read_csv("/content/2203有報セット.csv",index_col=0).reset_index()
df.head(10)
このようなデータセットになります。

こちらも参考にしてください
形態素解析の実行
トークナイザー(関数)を作成し、dfに対して形態素解析を実行します。
実行結果はdocs_keiei_2203_ldaというリストに格納されます。
#stopwordsの指定
!wget http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt
with open("/content/Japanese.txt","r") as f:
stopwords = f.read().split("\n")
#Neologdによるトーカナイザー(リストで返す関数・名詞のみ)
def mecab_tokenizer(text):
replaced_text = text.lower()
replaced_text = re.sub(r'[【】]', ' ', replaced_text) # 【】の除去
replaced_text = re.sub(r'[()()]', ' ', replaced_text) # ()の除去
replaced_text = re.sub(r'[[]\[\]]', ' ', replaced_text) # []の除去
replaced_text = re.sub(r'[@@]\w+', '', replaced_text) # メンションの除去
replaced_text = re.sub(r'\d+\.*\d*', '', replaced_text) #数字を0にする
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
mecab = MeCab.Tagger(path)
parsed_lines = mecab.parse(replaced_text).split("\n")[:-2]
# #表層形を取得
# surfaces = [l.split('\t')[0] for l in parsed_lines]
#原形を取得
token_list = [l.split("\t")[1].split(",")[6] for l in parsed_lines]
#品詞を取得
pos = [l.split('\t')[1].split(",")[0] for l in parsed_lines]
# 名詞,動詞,形容詞のみに絞り込み
target_pos = ["名詞"]
token_list = [t for t, p in zip(token_list, pos) if p in target_pos]
# stopwordsの除去
token_list = [t for t in token_list if t not in stopwords]
# ひらがなのみの単語を除く
kana_re = re.compile("^[ぁ-ゖ]+$")
token_list = [t for t in token_list if not kana_re.match(t)]
return token_list
#df全体に対してmecab_tokenizerを適用し、形態素解析を行なったリストを返す関数
def make_docs(df,column_number):
docs=[]
for i in range(len(df)):
text = df.iloc[i,column_number]
docs.append(mecab_tokenizer(text))
return docs
#形態素解析の実行
docs_keiei_2203_lda = make_docs(df,2)
辞書の作成
単語と単語IDを対応させる辞書を作成します。
また、出現頻度が極端に低い単語と、極端に高い単語を削除します。
最後にLdaModelが読み込める形式に変換します
#辞書の作成
dictionary = Dictionary(docs_keiei_2203_lda)
#出現がx文書に満たない単語と、y%以上の文書に出現する単語を極端と見做し削除する
x =500
y =0.5
dictionary.filter_extremes(no_below=x,no_above=y)
# LdaModelが読み込めるBoW形式に変換
corpus = [dictionary.doc2bow(text) for text in docs_keiei_2203_lda]
print(f"Number of unique tokens: {len(dictionary)}")
print(f"Number of documents: {len(corpus)}")
トークン数は237、文書数は2,573となっていますね。
Number of unique tokens: 237
Number of documents: 2573
LDAの実行
トピック数を指定してモデルを学習。ここではトピック数を8にしました。
num_topics =8
lda = LdaModel(corpus, id2word =dictionary, num_topics=num_topics, alpha=0.01)
実行結果
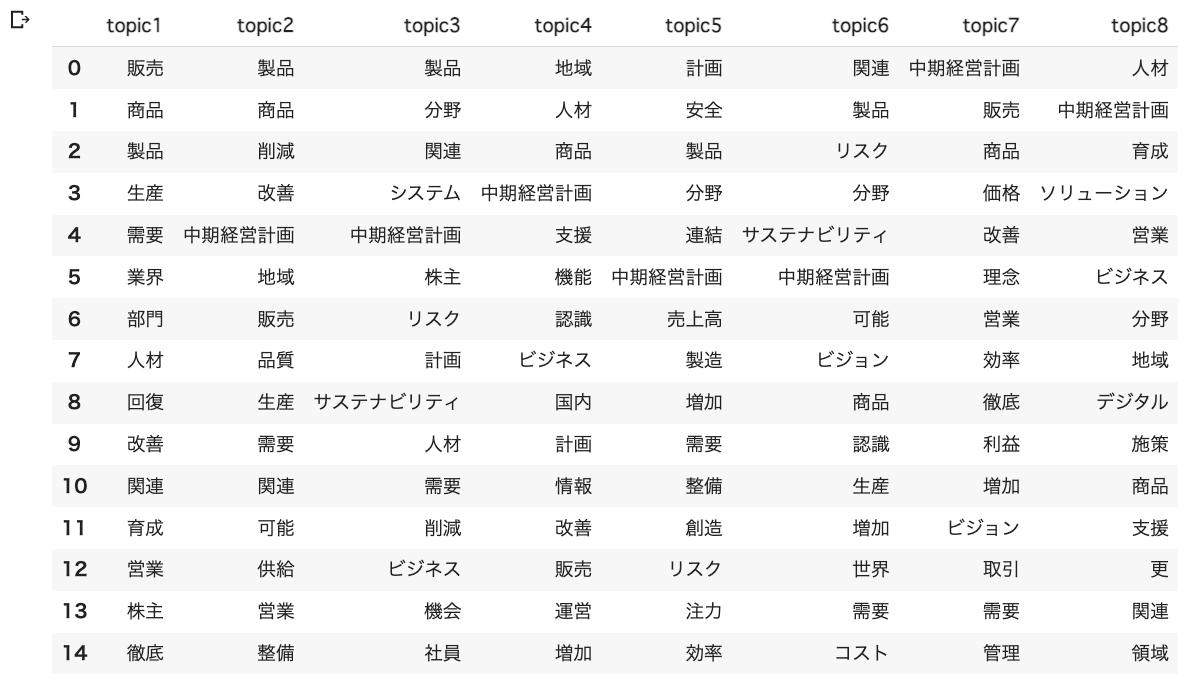
トピックごとに上位15単語(topn=15) をデータフレームで表示します。
df =pd.DataFrame()
for t in range(num_topics):
word=[]
for i, prob in lda.get_topic_terms(t, topn=15):
word.append(dictionary.id2token[int(i)])
_ = pd.DataFrame([word],index=[f'topic{t+1}'])
df = df.append(_)
df.T
なかなか解釈が難しいですね。
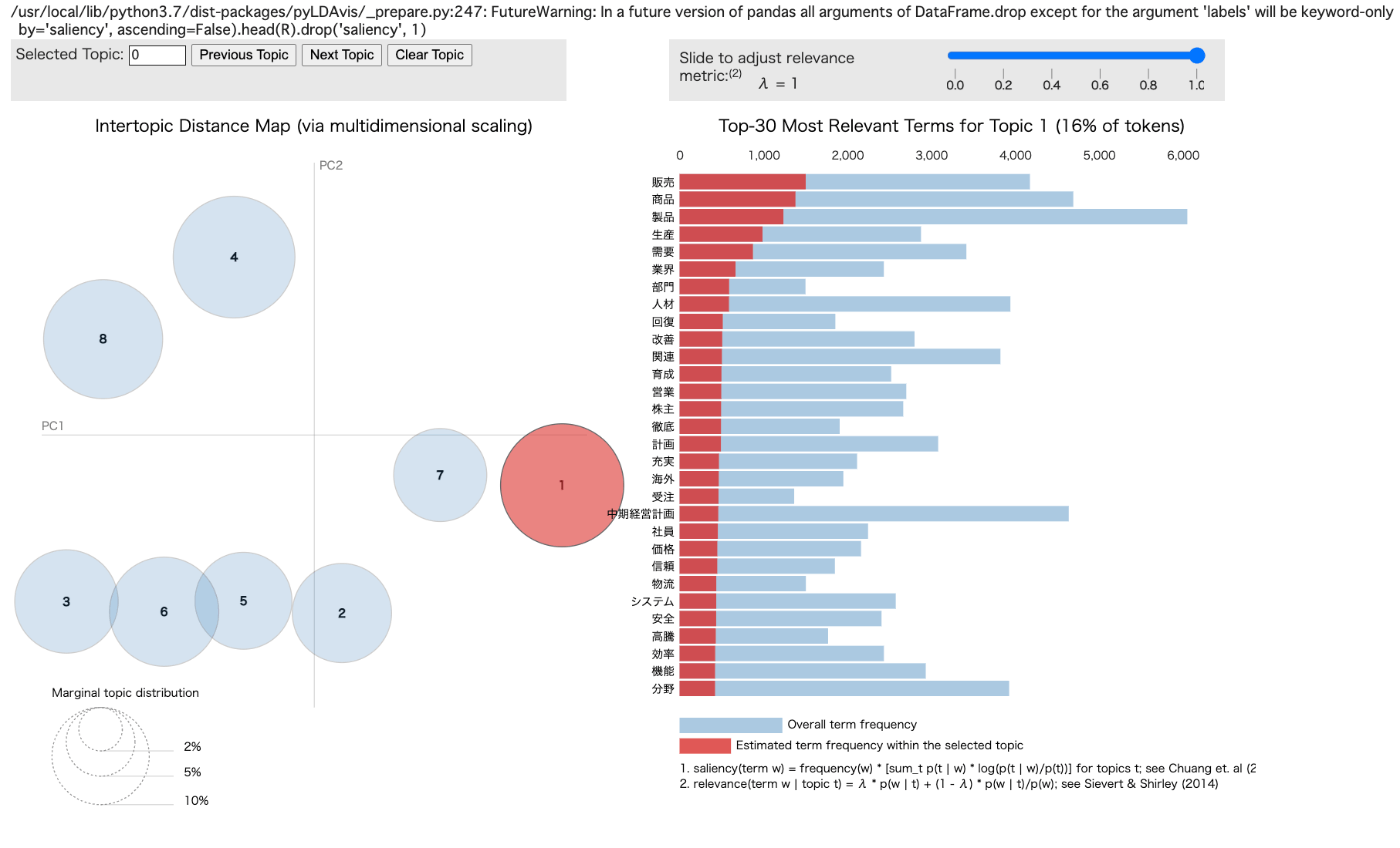
PyLDAvisでの可視化
PyLDAvisはトピックモデルをインタラクティブに可視化できるライブラリーです。
その威力を見てみましょう。
#ライブラリーのインストール
!pip install pyLDAvis
#ライブラリーのインポート
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
#PyLDAvisの実装
pyLDAvis.enable_notebook()
vis = gensimvis.prepare(
lda, corpus, dictionary, n_jobs = 1, sort_topics = False
)
pyLDAvis.display(vis)
実行結果です。
カーソルを左のグラフの円にあてると、右にそのトピックの単語が表示されます。
ワードクラウドでの可視化
古典的な手法ですが、ワードクラウドでも可視化してみましょう。
#ライブラリーのインストール
!pip install -q japanize-matplotlib
!apt-get -yq install fonts-ipafont-gothic
!ls /usr/share/fonts/opentype/ipafont-gothic
#ライブラリーのインポート
from wordcloud import WordCloud
from PIL import Image
import matplotlib.pyplot as plt
#フォントパスの指定。今回はGoogleフォントを使用しました。
font_path = '/content/ShipporiMincho-Regular.ttf'
fig, axs = plt.subplots(ncols=2, nrows=4, figsize=(12,12))
axs = axs.flatten()
def color_func(word, font_size, position, orientation, random_state, font_path):
return 'darkturquoise'
#ワードクラウドを楕円形にするためのイメージをmaskとして取得します。
mask = np.array(Image.open("/content/phpYSbfIJ.png"))
for i, t in enumerate(range(lda.num_topics)):
x = dict(lda.show_topic(t, 30))
im = WordCloud(
font_path=font_path,
background_color='white',
colormap="hsv",
mask=mask,
random_state=0
).generate_from_frequencies(x)
axs[i].imshow(im)
axs[i].axis('off')
axs[i].set_title('Topic '+str(t))
plt.tight_layout()
plt.show()
実行結果はこちら。
ワードクラウドが一番分かりやすい感じがします。

さいごに
いかがでしたでしょうか。
今回は有価証券報告書の非財務情報を分析対象としました。
昨今、企業に対して非財務情報の開示を求める動きが国際的に強まってきています。
その背景には、企業を取り巻く環境変化のスピードが増したため、財務情報だけでは企業が将来にわたって継続的に収益をあげられるかの判断が難しくなってきたことや、財務情報だけでは投資家以外の多様なステークホルダーからの評価を維持できなくなってきたことが挙げられます。
こうした中、企業が有価証券報告書等で開示する非財務情報を適切に分析することが重要となりますが、これらの情報は分析対象としては取り扱いが困難です。いわゆるテキストデータと存在しており、数字などの構造化されたデータではないからです。
こうしたテキストデータのような非構造化データの分析を容易にする技術が自然言語処理となるわけですが、自然言語処理の中でも、大量のテキストデータを適切に分析できる手法としてトピックモデルを活用する場面が今後増えると思います。
Discussion