効率的なGANs [TinyML]
はじめに
Generative Adversarial Networks(GANs)は2010年代後半に登場し、画像生成・変換の分野で一躍注目を集めました。特にStyleGANシリーズなどはフォトリアリスティックな画像生成を可能にし、多くの研究や応用に繋がっています。
しかし近年はDiffusion Models(拡散モデル)の台頭により、GANは最先端ではなくなりつつあります。それでも、GANは生成モデル研究の重要な基盤であり、理解する価値は十分にあります。
そこで本記事では、MITの講義TinyML and Efficient Deep Learning ComputingのLecture 17をもとに、効率的なGAN手法を3つ紹介します。
なお、正確性には十分気をつけていますが、筆者はプロフェッショナルではないので間違いを含んでいる可能性があることをご了承ください。
GANの圧縮
Liら(CVPR 2020)は、Conditional GANの圧縮方法を提案しています。以下は提案手法を表した図であり、大きく3段階に分かれています。

Li et al., GAN Compression: Efficient Architectures for Interactive Conditional GANs. 2020 より
- 知識蒸留: 学習済み教師モデルの出力
G'(x) G(x) - より小さくて高性能なチャンネル幅の組み合わせを探索する
- 探索により得られた最良の構成をFine-tuningする
Reconstruction Loss・Distillation Loss・cGAN Lossはそれぞれ以下のように表されます。
この手法による圧縮結果を示しています。代表的な条件付きGANであるCycleGAN・Pix2pix・GauGANについて、推論速度とモデルサイズの大きな改善を達成しました。
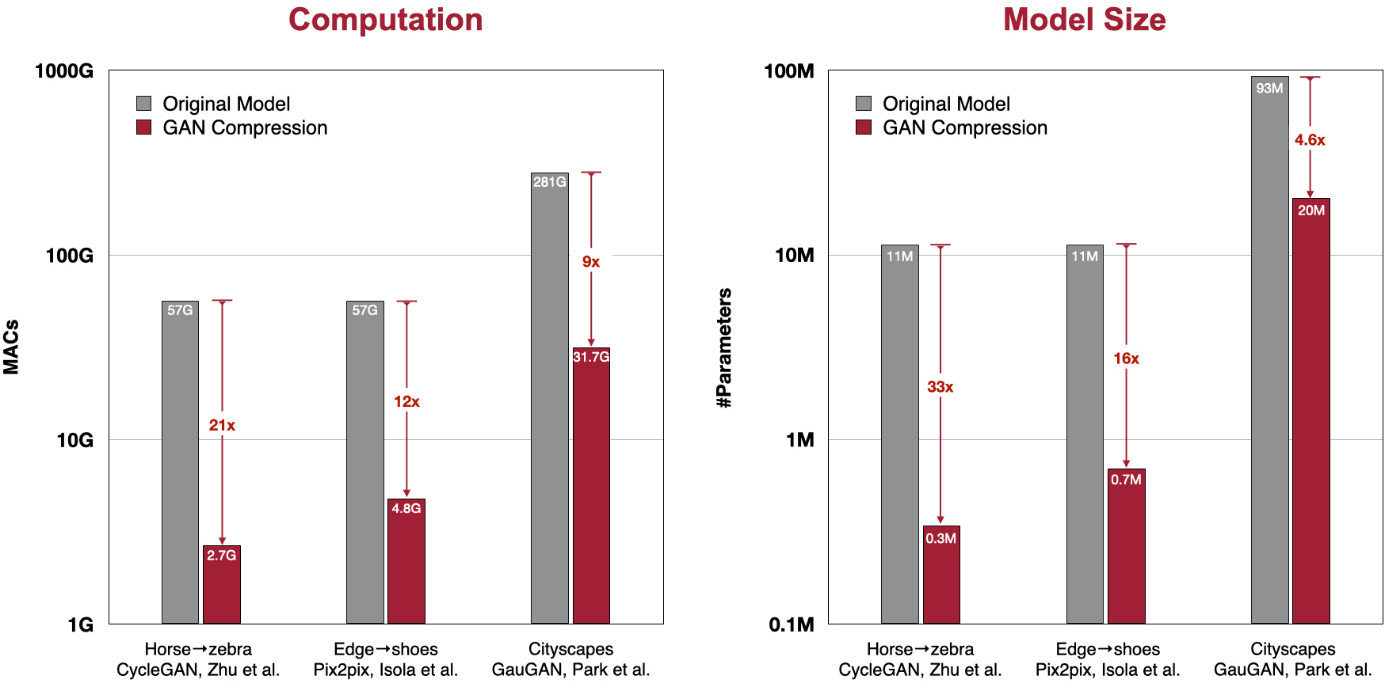
https://hanlab.mit.edu/projects/gancompression
また手法による生成結果の例を以下に示しています。pix2pixとCycleGANのどちらにおいても多少のFIDの悪化が見られますが、引き換えに大きく推論速度を改善しています。その一方で、本手法を用いずに単にチャンネル数を0.25倍した場合(画像右下)ではFIDが大きく上昇し、シマウマへの変換が完全ではないことがわかります。

https://hanlab.mit.edu/projects/gancompression
FIDとは
FIDは Fréchet Inception Distance の略で、生成画像と実画像の分布の距離を測る指標です。
画像認識モデルであるInception v3を使って画像を特徴ベクトルに変換し、それらを多次元ガウス分布に近似したうえでFréchet距離を計算します。
-
\mu_r, \Sigma_r -
\mu_g, \Sigma_g
つまり、FIDが小さいほど「見た目の質と多様性が高い」生成モデルとみなされます。
AnyCost GAN
GANは、ランダムベクトルや入力画像を潜在空間(latent space)にマッピングし、その潜在表現を変化させることで出力画像を制御できます。潜在空間の操作によって、顔画像であれば「表情」「髪型」などの属性を編集できることが知られています。しかしその生成速度が遅いため、潜在ベクトルを少しずつ変化させながら結果を確認するような、インタラクティブなアプリケーションには適さないという課題がありました。
このような課題に対し、Linら(CVPR 2021)はBlenderやMayaなどのレンダリングソフトウェアでのアプローチに目をつけました。レンダリングソフトウェアでは、光の計算(レイトレーシング)の際に計算する光の量を減らすことで高速なプレビューを実現しています。

TinyML and Efficient Deep Learning Computingより
このような手法をGANに適用し、画像編集の際は軽量なモデルを使い、満足したらフルサイズモデルで高品質な結果を得れば良いと考えたのです。
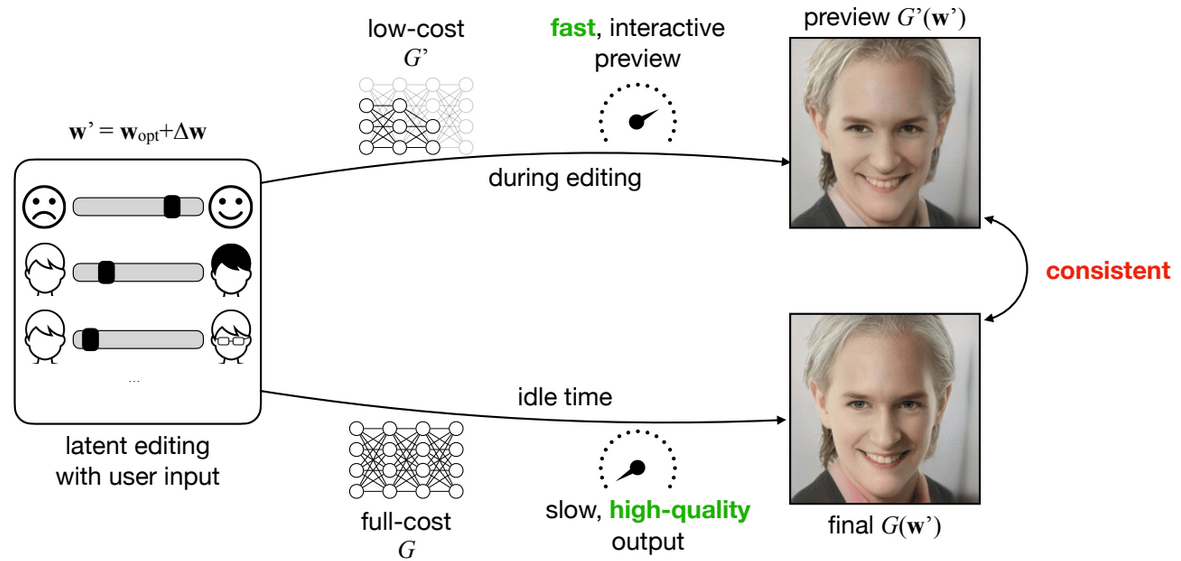
TinyML and Efficient Deep Learning Computingより
これを実現するには異なる解像度・異なるチャンネル数で一貫した出力が得られるようにしなければなりません。以下にその方法をまとめます。
マルチ解像度学習
通常のStyleGAN2では中間層の出力をそのまま低解像度画像にすると不自然になります。
AnyCost GANでは、学習時に解像度をランダムサンプリングし、各解像度で自然な画像を出力するように訓練します。

TinyML and Efficient Deep Learning Computingより
アダプティブチャンネル学習
計算コストをさらに下げるため、各層のチャンネル数をランダムに削減して訓練します。
重要度の高いチャンネルを優先的に保持し、削減後でも出力品質を維持できるよう工夫しています。
すべてのサブネットワークを同時に訓練し、低コスト版とフル版を重み共有しています。

TinyML and Efficient Deep Learning Computingより
しかし、チャンネル削減だけではフル版と結果がズレしまいます。そのため、MSE損失とLPIPSを組み合わせて、サブネット出力とフルモデル出力が近づくよう学習させます。
ジェネレータ条件付き識別器
多様な解像度・チャンネル設定を同時に訓練すると、通常の識別器では対応しきれません。
AnyCost GANでは、識別器に「ジェネレータの構造情報」を入力し、それに応じて特徴マップを変調します。例えば、「このサブネットは0.5×チャンネル構成」と識別器に知らせることで、すべてのサブネットに適切なフィードバックを与えられるようになります。
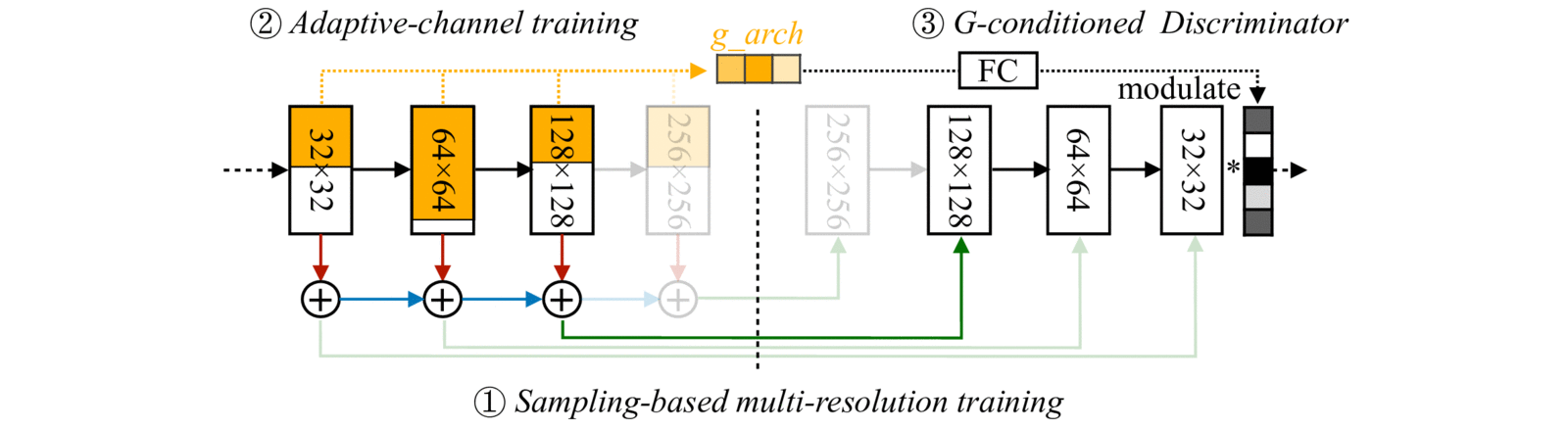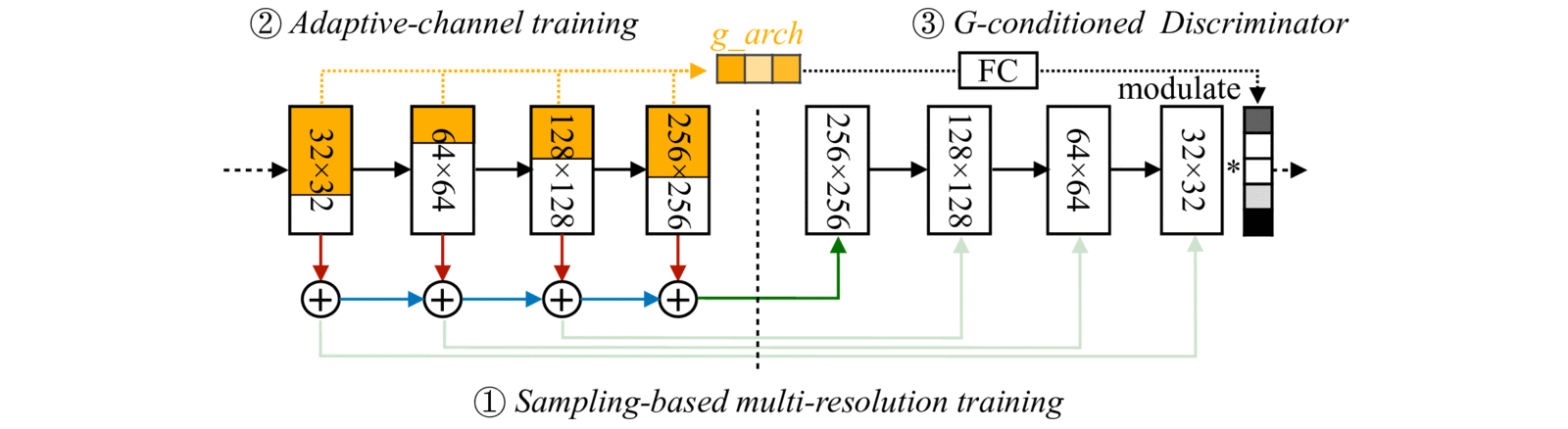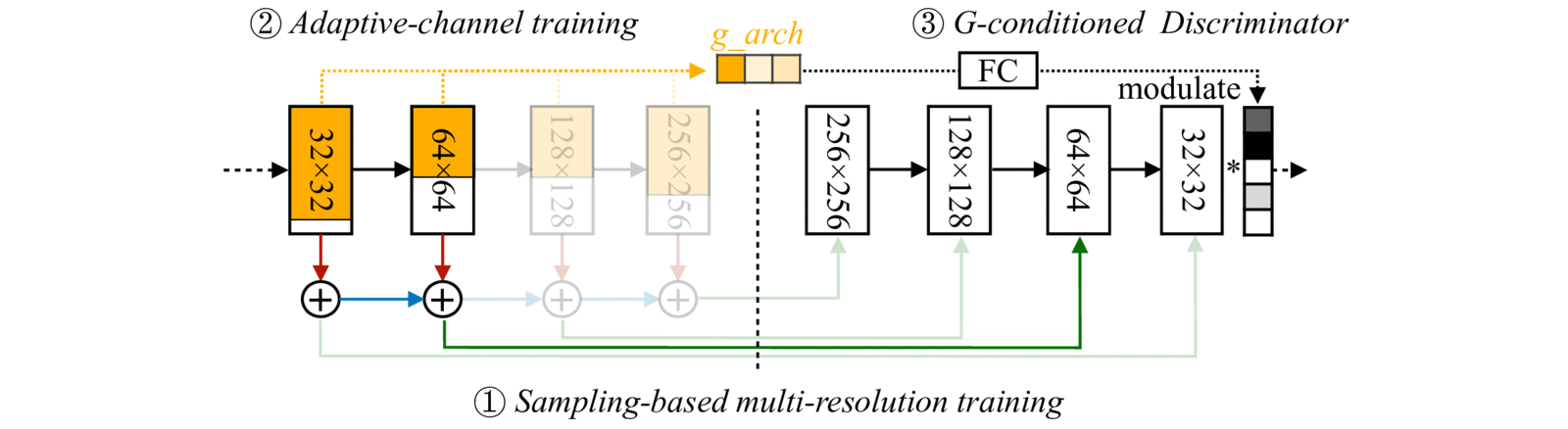
https://hanlab.mit.edu/projects/anycost-gan
結果
以下のように、異なる解像度・モデルサイズにおいて、一貫した出力を得ることに成功しました。

https://hanlab.mit.edu/projects/anycost-gan
微分可能なデータ拡張
一般的な深層学習モデルと同様に、GANにおいてもデータの量が重要になります。少データでは識別器が過学習を起こし、生成画像が崩壊します。このようなデータの不足に対し、一般的にはデータ拡張が有効であると考えられていますが、GANの文脈ではどのように適用すれば良いでしょうか。いくつか考えてみます。
本物の画像のみを拡張する
識別器に入力されるデータのうち、「本物の画像」にのみカラージッターなどのデータ拡張を施した場合、どのような問題が起こるでしょうか。
結論から言うと、生成画像にデータ拡張の効果そのものが現れてしまい、学習がうまくいかなくなります。
理由は、識別器が「本物」と「偽物」を比較して識別しているためです。識別器は本物と偽物を区別する手がかりを探し、生成器は本物らしい画像を出力して識別器を欺こうとします。
このとき本物の画像だけにデータ拡張を施すと、生成器は「拡張の痕跡(CutOutやカラージッターなどの効果)」を模倣するほうが有利になります。その結果、生成器は拡張の効果を含んだ不自然な画像を生成し、識別器を欺く方向に学習が偏ってしまうのです。

TinyML and Efficient Deep Learning Computingより
識別器の入力を拡張する
では、本物の画像だけでなく、生成画像にもデータ拡張を施してから識別器に入力したらどうなるでしょうか。
一見すると公平に見えますが、実はこれもうまくいきません。理由は、生成器がデータ拡張に一切関与していないため、生成器と識別器の間で学習のバランスが崩れるからです。
生成器の立場からすると、自分の出力した画像がそのまま識別器に渡されると思っています。しかし実際には、識別器に入力される直前でデータ拡張によって画像が加工されてしまいます。その結果、識別器が返すフィードバックは「生成器が出力した画像」ではなく、「拡張後の画像」に基づくものとなります。
つまり、生成器からすれば「自分の知らないところで勝手に書き換えられた画像」に対して評価を受けている状態です。この不一致が、生成器にとって正しい改善方向を学ぶ妨げとなり、最終的に訓練が不安定になります。
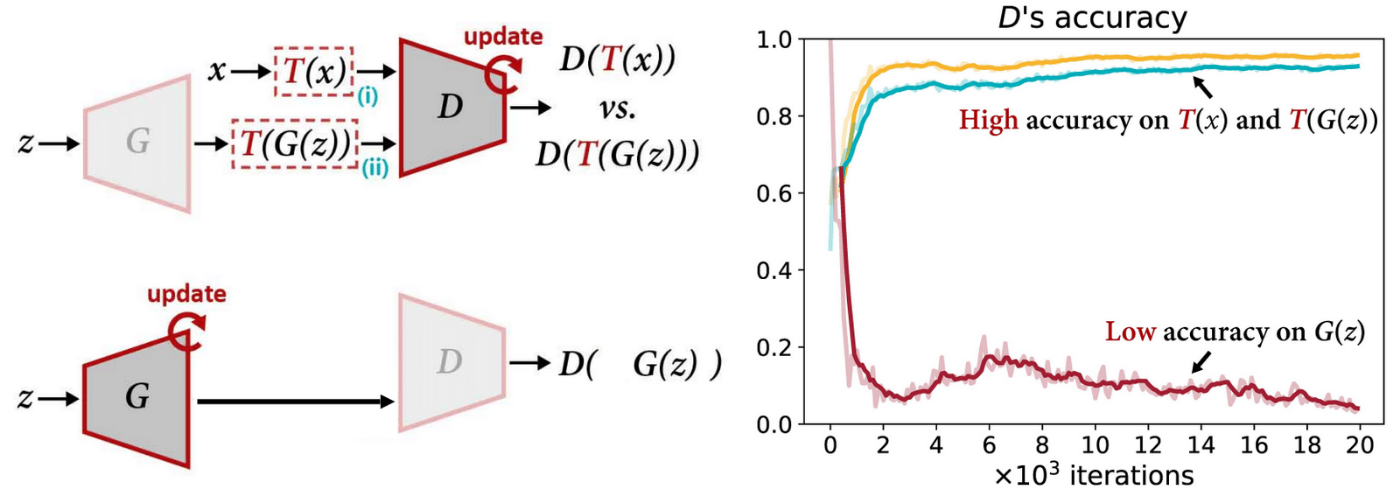
TinyML and Efficient Deep Learning Computingより
Differentiable Augmentation
Zhaoら(NeurIPS 2020)は、本物画像と生成画像の両方に、かつ生成器にも勾配が伝わる形で拡張を適用する方法を提案しました。
具体的には識別器の更新時には

https://hanlab.mit.edu/projects/diffaug
このようなアプローチにより、データ効率が大幅に改善し、極小データセットでも高品質な生成が可能になりました。以下の右は、100-shotによる生成結果です。

https://hanlab.mit.edu/projects/diffaug
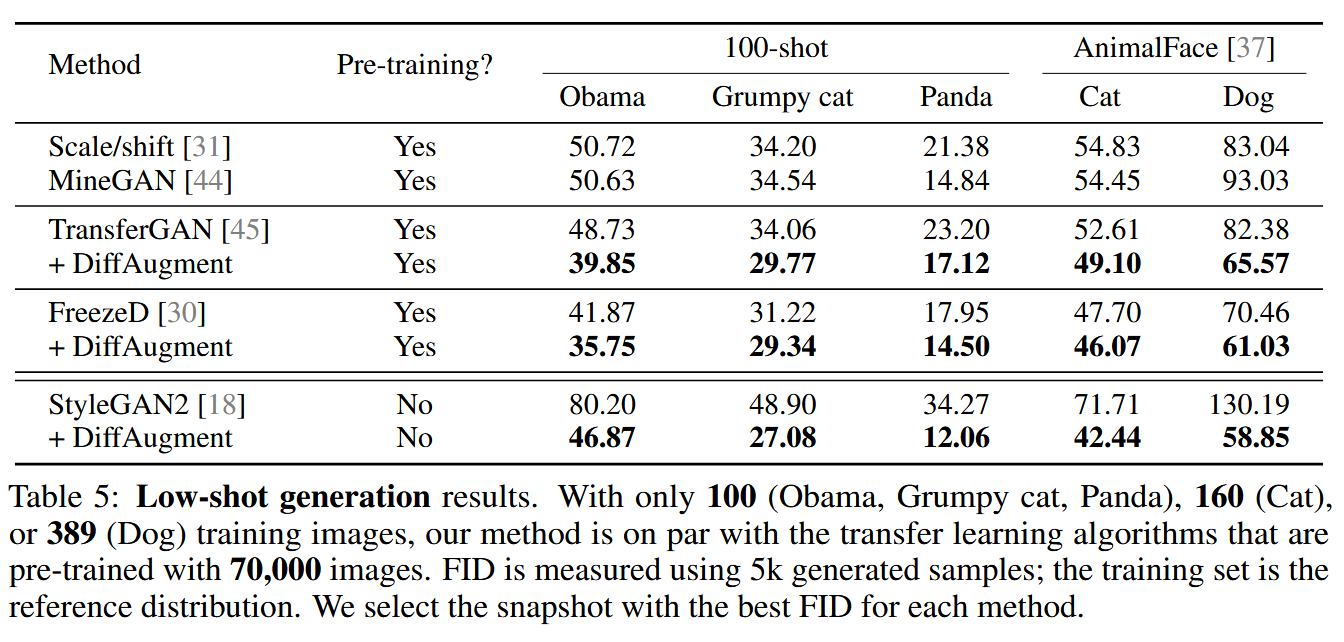
Zhao et al., Differentiable Augmentation for Data-Efficient GAN Training. 2020 より
まとめ
本記事では、MITの講義 TinyML and Efficient Deep Learning Computing をもとに、効率的なGANに関する3つの代表的な研究を紹介しました。
これらの研究は、GANをより軽量かつデータ効率よく利用するためのアプローチを示しています。拡散モデルが主流となりつつある現在でも、GANは生成モデル研究の重要な基盤であり、その効率化に向けた取り組みは引き続き価値のあるテーマです。
Discussion