Hugging Faceでデータセットを公開する
はじめに
Hugging Faceは機械学習のためのプラットフォームとして大きな存在感を示しています。
この記事では筆者の備忘録も兼ねて、データセットをHugging Faceで公開する流れを整理しました。
内容の正確性には注意していますが、誤りがある可能性もあります。もし気づいた点があれば、ぜひコメントなどでご指摘いただけると助かります。
リポジトリの作成
アカウント作成後、メニューから作成できます。
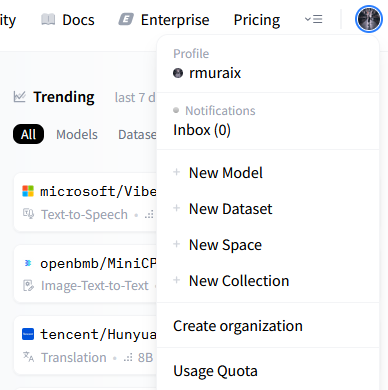
データセットをアップロードする
リポジトリを作成した段階ではまだ空の状態です。ここにローカルのデータをアップロードして初めて、他のユーザーが利用可能になります。
アップロードには「huggingface_hubを使う方法」と「Gitを使う方法」の2通りがあります。Pythonはスクリプト化に便利、Gitは大規模データや共同開発に向いています。どちらもアクセストークンによる認証が必要です(GitはHTTPSの場合)。
まずはアクセストークンページからリポジトリへの読み書き権限を持つトークンを生成します。Organization管理下のリポジトリを操作する場合は「Org permissions」も設定します。
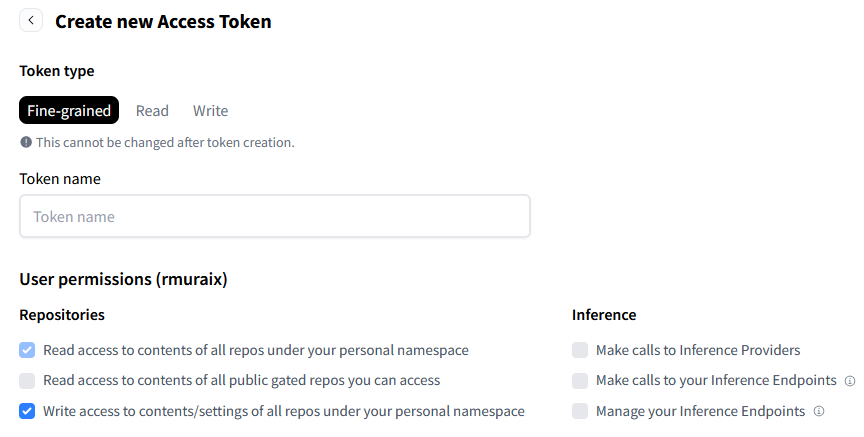

次にアクセストークンを使用して認証します。uvを使用する場合は以下のコマンドを実行します。
uvx --from huggingface_hub hf auth login
pipの場合は以下のコマンドになります。
pip install huggingface_hub
hf auth login
Pythonライブラリを使用する
huggingface_hubを使用してファイルのアップロード・更新・削除などを行えます。
PythonとCLIから利用できます。
ファイルをアップロードする
from huggingface_hub import HfApi
api = HfApi()
api.upload_file(
path_or_fileobj="/path/to/local/folder/README.md",
path_in_repo="README.md",
repo_id="username/test-dataset",
repo_type="dataset",
)
# Usage: hf upload [repo_id] [local_path] [path_in_repo]
uvx --from huggingface_hub hf upload username/test-dataset /path/to/local/folder/README.md README.md --repo-type=dataset
フォルダをアップロードする
from huggingface_hub import HfApi
api = HfApi()
# path_in_repoを指定しない場合はリポジトリルートに配置される
api.upload_folder(
folder_path="./",
repo_id="username/test-dataset",
repo_type="dataset",
)
uvx --from huggingface_hub hf upload username/test-dataset . . --repo-type=dataset
詳細は以下の公式ドキュメントを参照してください。
Gitを使用する
Hugging FaceはGitをサポートしています。個人的にはコミットが簡単にできるGitのほうが扱いやすいと感じます。
Gitの使用にはGit LFSのインストールが必要です。
# Homebrew
brew install git-lfs
# apt/deb
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
インストール後、リポジトリをクローンします。
git clone https://huggingface.co/datasets/username/test-dataset
Pull Requestを作成する
ソフトウェア開発において、チームや公開リポジトリで共同作業する場合はPull Requestが活用されています。
Hugging FaceでもGitHubなどと同様に、Pull Requestを作成しコラボレーションを行うことができます。
ただし、Push前にドラフトPull Requestを作成しなければならないことに注意が必要です。
まず、リポジトリのCommunityタブから「New pull request」をクリックします。
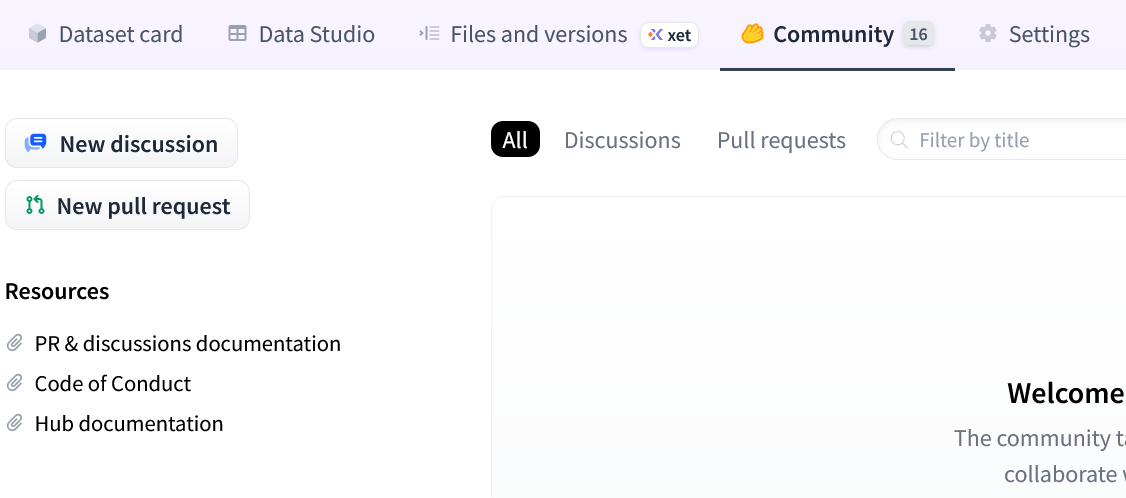
「On your machine」にPull Requestのタイトルを入力し、「Create PR branch」をクリックします。
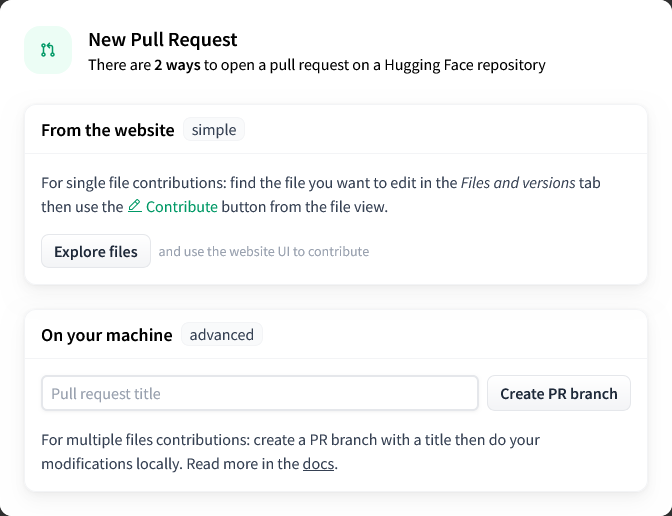
今回のPR用のブランチが作成されたのでローカルに反映させ、チェックアウトします。
# PR番号が1だった場合
git fetch origin refs/pr/1:pr/1
git checkout pr/1
コミット後、リモートにPushします。
git push origin pr/1:refs/pr/1
リモートに変更をプッシュしたら、UI上で「publish」をクリックしマージ可能状態に移行します。
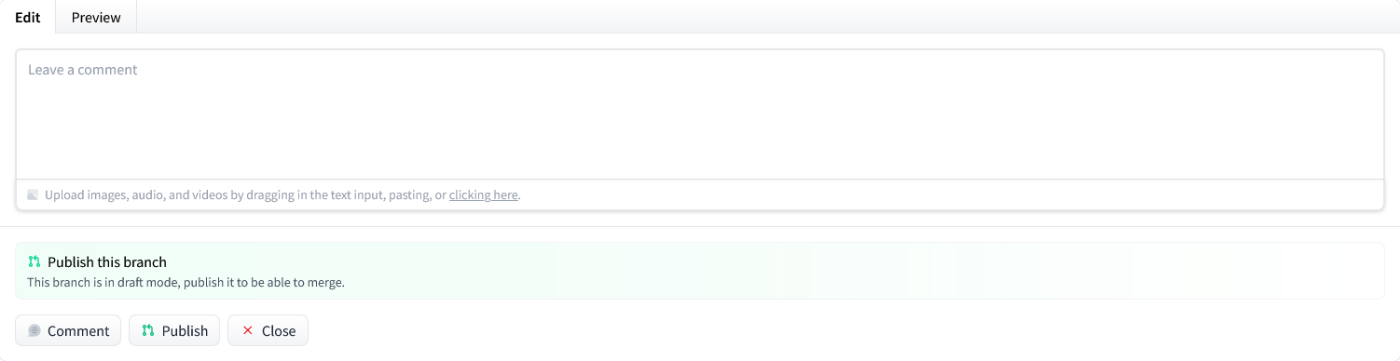
Dataset Cardを書く
GitHubなどと同様に、HuggingFaceでもREADME.mdがデータセットを説明する役割を担っています。
GitHubと異なるのは、データセットに関するメタデータを記述できることです。データセットのライセンス・対応タスク・タグなどを記載することで、利用者がデータセットを正しく理解し、再利用しやすくなります。
以下に基本的なメタデータフィールドを示します。
---
license: other # https://hf.co/docs/hub/repositories-licenses
license_link: LICENSE.md # license = other の場合、リポジトリ内の「LICENSE」または「LICENSE.md」を指定するか、ライセンスへのURLを指定
tags:
- fingerspelling
- sign-language
pretty_name: ub-MOJI
task_categories:
- video-classification
---
完全版は以下を参照してください。
リポジトリを構造化する
Hugging Face Hubにデータセットを公開する際は、単にファイルを置くだけでなく、datasetsライブラリから直接ロードできる構造に整えておくことが推奨されています。これによりユーザーは次のように利用できます。
from datasets import load_dataset
dataset = load_dataset("username/my-dataset")
基本構造
以下のようにすることで、trainとtestを区別できます。
my_dataset_repository/
├── README.md
├── train.csv
└── test.csv
他のファイル名を使用するときは、README.mdのメタデータを記載することで区別できます。
my_dataset_repository/
├── README.md
├── data.csv
└── holdout.csv
---
configs:
- config_name: default
data_files:
- split: train
path: "data.csv"
- split: test
path: "holdout.csv"
---
ディレクトリ名による分割も可能です。
my_dataset_repository/
├── README.md
└── data/
├── train/
│ └── bees.csv
├── test/
│ └── more_bees.csv
└── validation/
└── even_more_bees.csv
詳しくは以下を参照してください。
画像/映像データセット
画像/映像データには、キャプションなどの追加情報を与えられることがあります。そのような追加情報はfile_name列を持つmetadata.csvに記載できます。例えば、以下のようにファイルを配置したとします。
train/metadata.csv
train/0001.png
train/0002.png
train/0003.png
metadata.csvにはfile_name列を作成し、csvからの相対パスを記載します。
file_name,additional_feature
0001.png,This is a first value of a text feature you added to your images
0002.png,This is a second value of a text feature you added to your images
0003.png,This is a third value of a text feature you added to your images
このようにすることで、ライブラリやHubが、動画像と追加情報の関連を認識できるようになります。
詳しくは以下を参照してください。
アクセスを制限する
Hugging Face HubではGated Accessと呼ばれる、アクセスを制限する仕組みも提供しています。Gated Accessを有効にすると、データセットの利用には申請が必要になります。
設定方法
データセットページの「Gated user access」から設定できます。
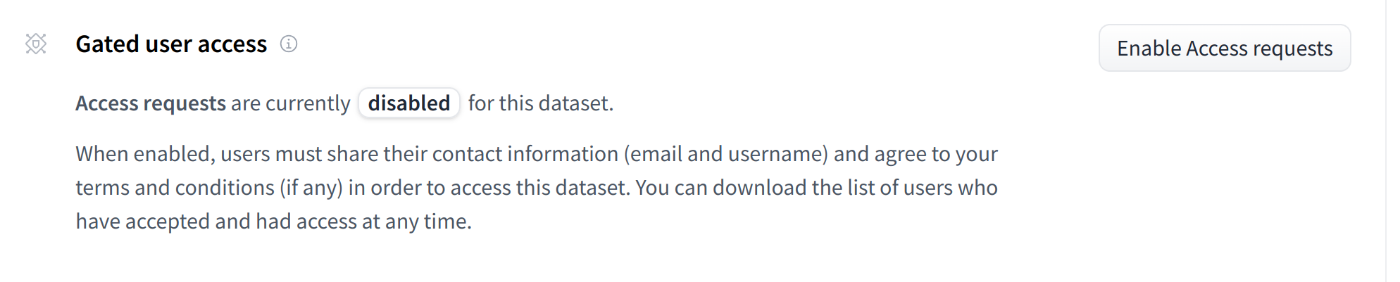
有効後、申請の自動/手動承認の切り替えや、申請者リストをダウンロードできます。

申請画面をカスタマイズする
Gated Access有効時、デフォルトでは以下のような申請画面が表示され、申請時に自動的にユーザ名とメールアドレスが収集されます。

追加の情報を求めたり、表示される文章を変更するには、README.mdのメタデータを追加します。
---
# 表示される文章を変更
extra_gated_prompt: "You agree to not use the dataset to conduct experiments that cause harm to human subjects."
# 追加の情報を求める
extra_gated_fields:
Company: text # 自由入力形式
Country: country # 国選択形式
Specific date: date_picker # 日付選択形式
I want to use this dataset for: # 選択形式
type: select
options:
- Research
- Education
- label: Other
value: other
I agree to use this dataset for non-commercial use ONLY: checkbox # チェックボックス形式
---
メタデータはyaml形式ですので、extra_gated_promptで改行を扱うには例えば以下のようにします。
extra_gated_prompt: >- # この記号が大事
By requesting access, you agree to the following conditions:
- Commercial use is prohibited
- Use for identification of individuals or invasion of privacy is prohibited
- Redistribution, transfer, or sublicensing is prohibited
- You are responsible for compliance with the laws of your country
- You may be required to delete the dataset if you violate the terms
DOIを発行する
学術論文などのデジタルコンテンツに付与される国際的な識別子であるDOI(Digital Object Identifier)の発行ができます。DOIを付与することで学術的に引用可能となり、研究成果としての価値や再現性の担保につながります。
Hugging FaceでDOIを発行するに当たり、いくつか注意点があります。
- DOIを発行するとデータセットのリネームや移転ができなくなる。
- DOIは現在のリビジョンに対して発行され、永続的なDOIには未対応。
永続的なDOIへの対応についてはIssueが立てられていますが、記事執筆現在では進展はないようです。
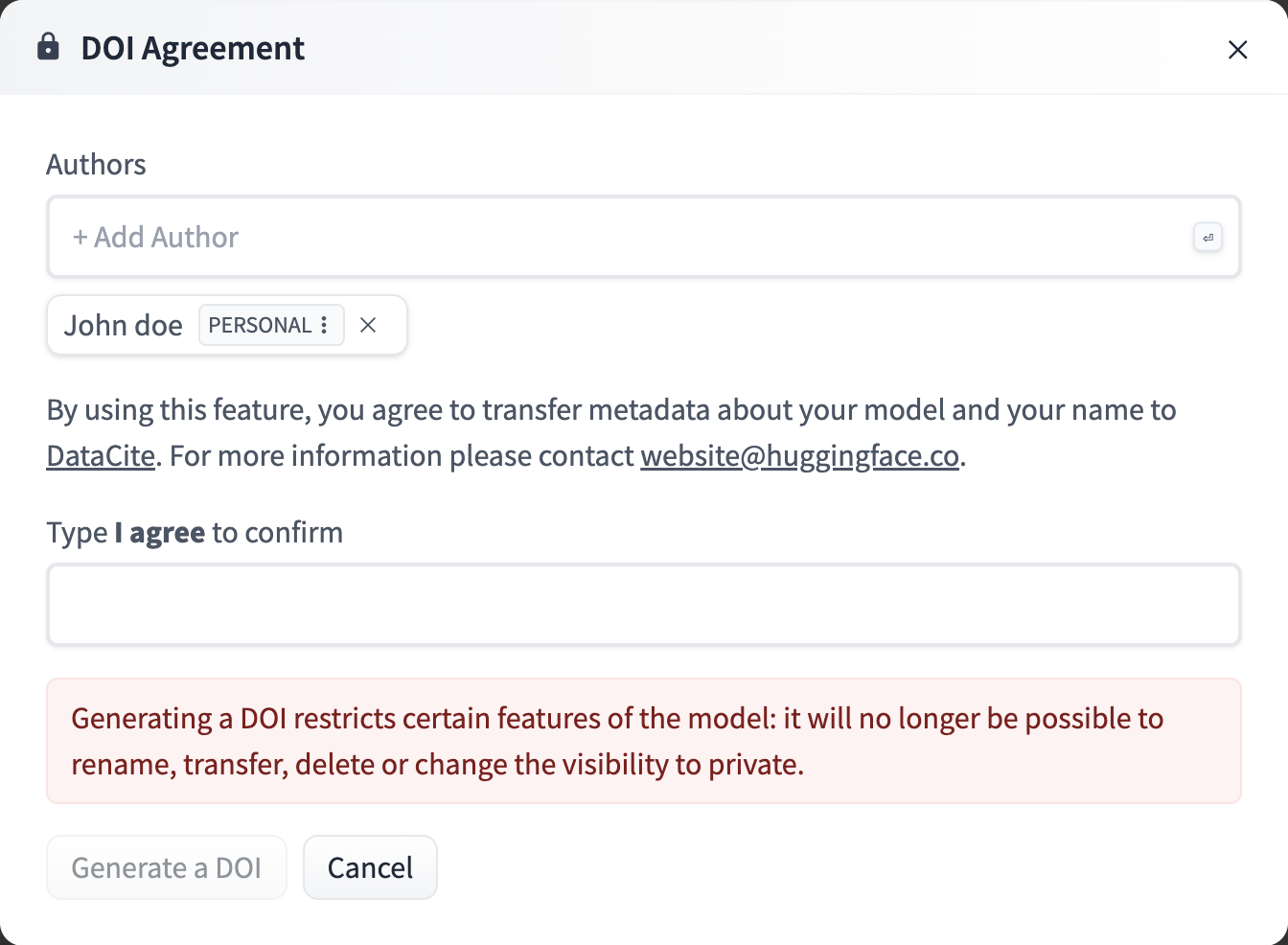
発行方法
データセットの設定から発行できます。

Authorには著者全員の名前を記載します。
まとめ
本記事では、Hugging Face Hubにデータセットを公開するための一連の流れを紹介しました。
- リポジトリ作成によって、データセットを管理・共有するための専用スペースを確保できる。
- アップロードを行うことで初めて他のユーザーが利用可能となり、Python/CLIはスクリプト化や自動化に、Gitは大規模データやチームでの運用に適している。
- Dataset Card を整備することで、利用者がデータセットの性質を正しく理解し、再利用できる環境を整えられる。
-
リポジトリを構造化することで
load_dataset("username/dataset")のように即座に利用可能となり、再現性と利便性が向上する。 - Gated Access を活用すれば、倫理的・法的に配慮すべきデータを承認制で共有でき、公開の幅が広がる。
- DOI の発行によって、学術的な引用や再現性の担保が可能となり、研究成果としての価値も高まる。
これらを適切に組み合わせることで、単なるファイル共有を超えた、再現性・共同研究・責任あるデータ公開を実現できます。本記事がHugging Faceを活用するための助けになれば幸いです。
Discussion