話題の拡散言語モデルを理解しよう!
はじめに
2025年5月に開催された「Google I/O 2025」にて、Googleから拡散言語モデルの Gemini Diffusion が発表され、その驚異的な生成速度で大きな注目を集めました。特にコーディングタスクのように、これまで大規模言語モデルの応用が期待されながらも生成速度がボトルネックとなっていた領域で、ブレークスルーをもたらすと期待されています。
この発表をきっかけに 拡散言語モデル に興味を持ちましたが、その仕組みや背景については十分に理解していませんでした。そこで本記事では、筆者の学習も兼ねて、拡散言語モデルの基本概念と主要な先行研究を解説します。以下に挙げる代表的な3本の論文を通して、数式はできるだけ使わず、それぞれの核心的なアイデアを概念的に紹介していきます。
| 論文タイトル | 概要 |
|---|---|
| Masked Diffusion Language Model | マスク言語モデルの仕組みを拡散モデルに統合し、全トークンをマスクした状態から段階的に復元する手法を採用。拡散モデルとしてはシンプルながら高い精度を実現し、ARモデルに迫る性能を示した初期の成果。 |
| Large Language Diffusion Models | MDLMのアーキテクチャを大規模化し、事前学習と教師ありファインチューニングを通じて指示追従性や文脈理解を大幅に強化。双方向生成の利点を活かしつつ、逆転推論のようなARモデルの弱点も克服。 |
| Block Diffusion | テキストをブロック単位で自己回帰的に生成し、各ブロック内部は拡散プロセスで並列生成するハイブリッド構造を採用。任意長生成・高品質・高速処理を両立し、拡散モデルの実用性を大きく前進させた。 |
自己回帰モデル vs 拡散言語モデル
現在、ChatGPTやClaudeに代表される多くの高性能な大規模言語モデルは、自己回帰モデル(Autoregressive Model, ARモデル) を基盤としたアーキテクチャを採用しています。
自己回帰モデルは、テキストを生成する際に、まるで人間が文章を書き進めるように、トークンを一つずつ順番に予測し、生成していくのが特徴です。たとえば「今日は良い」という文脈が与えられた場合、モデルは次に「天気」、続いて「です」、「。」といった具合に、文法的に自然な形で文章を完成させます。
しかし、自己回帰モデルにはいくつかの構造的な課題も指摘されています。
- 一方向性: 左から右への順序でしか情報を処理できず、将来の文脈を考慮した生成が原理的に困難。
- エラーの蓄積: 一度誤ったトークンを生成すると、その後もその誤りに基づいて生成が続き、誤りが蓄積・伝播しやすい。
- 並列処理の限界: トークンを逐次的に生成するため、長文の生成に時間がかかり、大幅な並列化が難しい。
これに対して、拡散言語モデル(Diffusion Language Model) は、画像生成分野で大きな成功を収めた拡散モデルのアイデアを言語に応用した、比較的新しいアプローチです。
拡散言語モデルの基本的な考え方は、元のテキストに徐々にノイズ(例えば、一部のトークンを[MASK]のような特殊トークンに置き換えるなど)を加え、最終的に完全にノイズ化された状態にするプロセスに基づきます。そして、その逆の過程――ノイズだけの状態から徐々にノイズを取り除き、元のテキストを復元するプロセス――をモデルに学習させます。
このアプローチにより、拡散言語モデルは自己回帰モデルが抱えるいくつかの課題を克服できる可能性を秘めています。
- 双方向文脈の活用: 文全体の文脈を考慮して各トークンを予測できるため、より自然で一貫性のある生成が可能。
- 並列生成による高速化: 複数のトークンを同時に処理できるため、生成速度の大幅な向上が期待できる。
- 柔軟な生成制御: 生成ステップ数を調整することで、品質と速度のバランスを柔軟に制御できる。
次の章からは、拡散言語モデルの具体的な仕組みや進化の道のりを、主要な論文を通じて詳しく見ていきましょう。
Masked Diffusion Language Model
Simple and Effective Masked Diffusion Language Models(2024年6月11日)
この論文では、BERTに代表されるマスク言語モデル(Masked Language Model, MLM)のアイデアを拡散プロセスに統合した、マスク拡散言語モデル(Masked Diffusion Language Model, MDLM) が提案されました。これは、テキストのような離散的なデータに拡散モデルを適用する新しい試みで、自己回帰モデルに匹敵する高い言語性能を示しました。
MDLMの生成プロセスは、以下のサンプルを見ると直観的に理解しやすいです。全てのトークンがマスクされた状態から生成を開始し、モデルがマスクされた部分を予測したトークンへと段階的に置き換えていくことで、最終的なテキストを完成させます。

サンプル生成プロセス 出典:https://s-sahoo.com/mdlm/
MDLMの仕組み
MDLMは、主に以下の2つのプロセスから構成されます。
Forward Masking Process(情報の隠蔽)
まず、元の自然な文章を用意し、ランダムに選んだトークンを特殊トークン[MASK]に置き換えます。この「マスキング(情報の隠蔽)」の度合いを段階的に、またはランダムな割合で増やしていくことで、元の文章が持つ情報は徐々に失われます。この過程が、拡散モデルにおける 「ノイズ付加」 に相当します。
~例~
初期状態:今日は良い天気です。
Masking 1:今日は [MASK] 天気です。
Masking 2:[MASK] は [MASK] 天気 [MASK]
最終状態:[MASK] [MASK] [MASK] [MASK]
このようにして、文全体が[MASK]トークンによってノイズ化されます。どのトークンをどの順序・割合でマスクするかは、事前に定義されたスケジュールに基づいて制御されます。
Reverse Unmasking Process(情報の再構築)
次に、Forward Masking Processとは逆のプロセスを実行し、情報を再構築します。[MASK]によって情報が隠された状態(例えば、全ての単語が [MASK]である状態や、一部の単語が[MASK]である状態)から開始し、元の意味のある文章を復元しす。これが拡散モデルにおける 「デノイジング(ノイズ除去)」 に相当します。
この復元プロセスでは、言語モデル(この論文ではTransformerエンコーダベースのモデルを利用)が、現在の[MASK]を含む文全体を考慮し、それぞれの[MASK]された位置に本来どの単語が入るべきかを予測します。具体的には、モデルは各[MASK]トークンが元の文脈においてどの単語であったかの確率分布を推定します。
~例~
初期状態:[MASK] [MASK] [MASK] [MASK]
Unmasking 1:[MASK] は [MASK] 天気 [MASK]
Unmasking 2:今日は [MASK] 天気です。
最終状態:今日は良い天気です。
テキスト生成時には、全てのトークンが[MASK]である状態から始め、モデルが反復的に[MASK]トークンを具体的な単語に置き換えることで、徐々に文章を生成していきます。
モデルの学習方法
MDLMの学習目的は、拡散プロセスの各段階(タイムステップごと、つまり様々なマスキング率の状態)で、隠された元の単語をモデルが正確に予測する能力を獲得させることです。具体的な学習ステップは以下の通りです。
-
多様なマスキング状態の生成:元の文章に対し、様々な割合でランダムに単語を
[MASK]トークンに置き換えます。これにより、ごく一部のみがマスクされた状態から、大部分あるいは全てがマスクされた状態まで、拡散プロセスの様々なタイムステップに対応する多様なノイズレベルのデータが作られます。 -
マスクされた単語の予測:モデルは、これらの
[MASK]を含む文章を入力とし、各[MASK]の位置に本来どのような単語が入るべきだったかを予測します。このタスクは、従来のマスク言語モデル(例:BERTの事前学習)と非常に似ています。 - 損失計算と学習:各マスキング状態(タイムステップごと)において、モデルの予測と実際の正しい単語との間のクロスエントロピー損失を計算します。そして、拡散プロセス全体を通じて、様々なマスキング率で計算されたこれらの損失を特定の重み付けで平均化したものを最終的な目的関数とし、モデルのパラメータを更新します。

MDLMの学習過程 出典:論文Figure1
実験結果
言語モデリングの主要なベンチマークの一つである LM1Bデータセット において、MDLMは既存の拡散型言語モデルと比較して、顕著な性能向上を達成しました。
特に、先行研究の有力な拡散言語モデルSEDDが330億トークンの学習データで達成したPerplexity(PPL)が 32.79 であったのに対し、MDLMは同程度の学習量(330億トークン)で 27.04、さらに学習量を3270億トークンまで増やすことで 23.00 というPPL値を記録し、大幅な改善を示しました。

LM1Bデータセットにおける各モデルのPerplexity比較 出典:論文Table1
LM1Bデータセットとは?
LM1B(One Billion Word Language Model Benchmark) は、自然言語処理分野で広く利用されている大規模な英語テキストデータセットです。Google Newsコーパスから収集された約10億語の文章で構成され、言語モデルの学習および評価における標準的なベンチマークとして用いられています。
この論文では、LM1Bを以下のように活用しています。
学習(Training)
データセット全体の99%を用いてMDLMを訓練し、モデルに自然な英語の構造や単語の出現パターンを学習させます。
評価(Evaluation)
残りの1%のテストデータを使用し、モデルの予測性能をPerplexityという指標で測定します。
Perplexityとは?
Perplexity(PPL) は、言語モデルの予測精度を評価するための指標で、モデルが次の単語を予測する際に「どれだけ迷っているか」を数値で表します。値が低いほど、モデルが次に来る単語を高い確信を持って予測できていることを意味し、より高性能であると評価されます。
直感的には、Perplexityの値は「モデルが予測する際に平均していくつの単語の候補で迷っているか」と解釈できます。
Perplexity = 1 : モデルがほぼ確実に1つの単語を予測できている状態。
Perplexity = 10 : 平均して約10個の候補の中から1つを選ぶ程度の迷いがある状態。
Perplexity = 100 : 平均して約100個の候補に迷っている状態。
文全体の生成確率は、文が長くなるほど指数関数的に非常に小さな値になるため、人間が直感的に理解したり比較したりするのが困難です。Perplexityは、この微小な確率を幾何平均と逆数を用いて変換することで、人間にとって理解しやすいスケールの数値に置き換えた指標です。
まとめと課題
MDLMは、拡散モデルのフレームワークにマスク言語モデルの利点を融合させることで、比較的シンプルな設計ながら高性能なテキスト生成を実現しました。特に、従来の拡散モデルよりも優れたPerplexityを達成し、自己回帰モデルに迫る性能の可能性を示しました。
一方で、以下のような課題も残されています。
- 自己回帰モデルとの性能差: 同じ計算資源を用いた場合、最先端の自己回帰モデルには依然として性能で及ばない。
- 長文生成の品質: 長文における文脈の一貫性や表現の繊細さに関しては、さらなる検証と改善の余地あり。
- 計算コスト: 拡散モデル特有の反復的な生成プロセスにより、依然として計算コストが高くなりがち。
Large Language Diffusion Models
Large Language Diffusion Models(2025年2月14日)
前述のMDLMのコンセプトを基盤に、さらに大規模モデルへとスケールアップさせた研究として、次に紹介するのが LLaDA (Large Language Diffusion with mAsking) です。この論文では、Masked Diffusionベースで学習された80億パラメータ規模のLLaDAが紹介されており、スクラッチからの学習によってMeta社のLLaMA3 8Bと競合する性能を示しました。さらに、自己回帰モデルが苦手とする「逆転の呪い」を克服するなど、注目すべき成果を上げています。
LLaDaの仕組み
LLaDAの学習は、事前学習と教師ありファインチューニングの2段階で構成されます。
Pre-training(事前学習)
まず、インターネットから収集された2.3兆トークンにも及ぶ膨大なテキストデータを用いて事前学習を行います。この段階では、MDLMと同様に、学習データ内の文章の各トークンが、ランダムな確率で[MASK]トークンに置き換えられます。
LLaDAの中心はTransformerベースのアーキテクチャであり、マスクされた文章全体を一度に入力として処理します。自己回帰モデルのような左から右への逐次的な予測順序に制約がないため、単語の前後双方の文脈を同時に活用できます。これにより、全てのマスク箇所に対して元の単語を並列に予測できます。そして、予測結果と元の正解データを比較し、その誤差を最小化するようにモデルの内部パラメータを調整します。この学習サイクルを繰り返すことで、LLaDAは単語の意味、文法規則、文脈依存関係、さらにはテキストに含まれる広範な知識を学習していきます。

Pre-training(事前学習) 出典:論文Figure2(a)
Supervised Fine-Tuning(教師ありファインチューニング)
SFT段階では、人間が作成した約450万組の「指示(プロンプト)」と「模範的な応答」のペアからなるデータセットを用いてモデルを微調整します。LLaDAの場合、SFTの過程でもMasked Diffusionの仕組みが活用します。具体的には、ユーザーからの「指示」は常に完全な形でモデルに与え、モデルが生成すべき「応答部分」のみをマスクし、拡散モデルによってその部分を生成するように学習します。
このSFTを通じて、LLaDAは単に知識を提示するだけでなく、ユーザーの意図を正確に把握し、それに沿った協力的かつ安全な応答を生成する能力、すなわち「アライメント(整合性)」を高めていきます。例えば、複数ターンにわたる対話データを学習することで、文脈を保持しながら一貫したやり取りを行う能力も獲得できます。
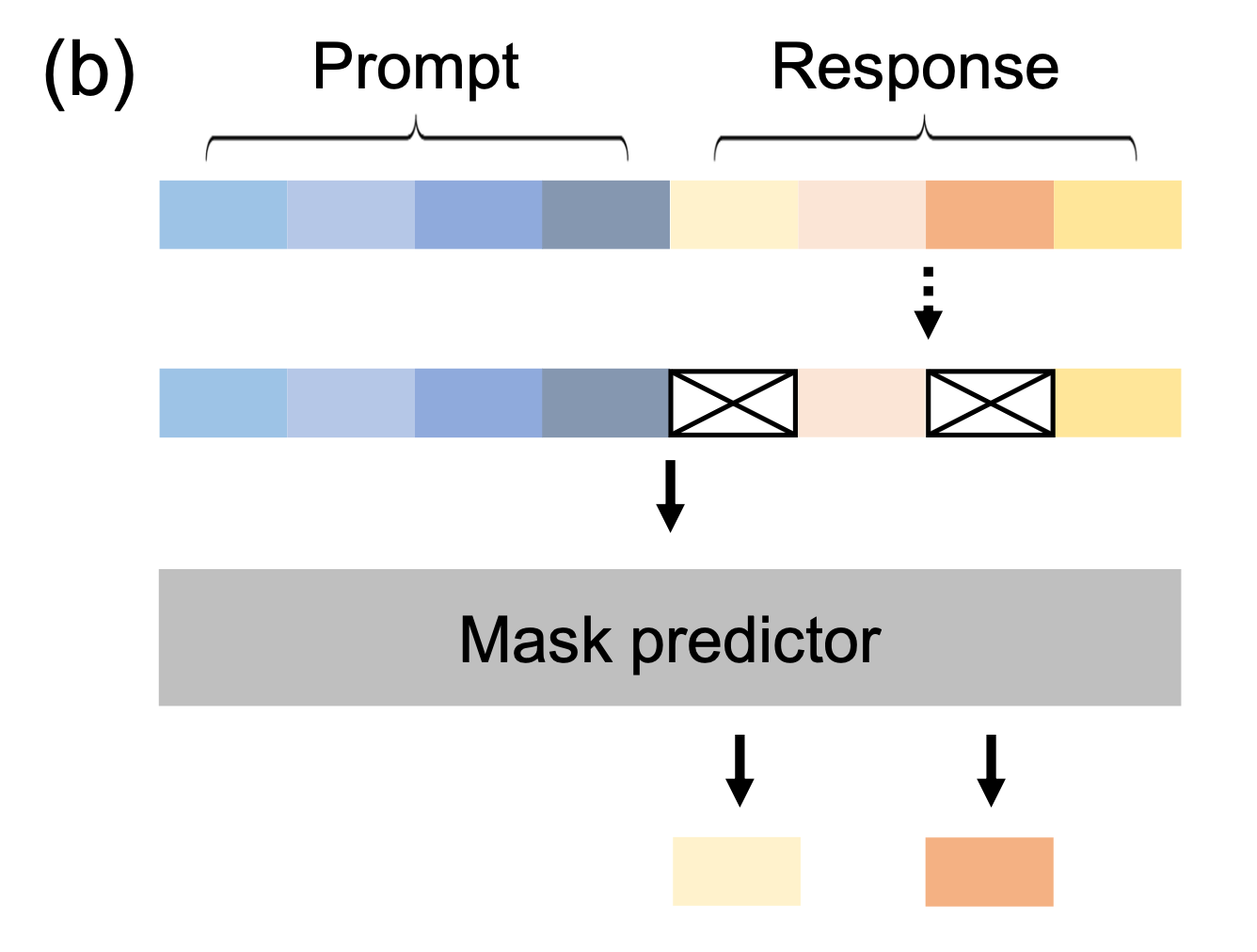
Supervised Fine-Tuning(教師ありファインチューニング) 出典:論文Figure2(b)
Inference(テキスト生成)
ユーザーからプロンプトを受け取ると、LLaDAはまず応答の目標長さに対応する[MASK]トークンのシーケンスを生成します。これは情報を一切持たない「完全なノイズ」状態を意味し、ここから生成を開始します。続いて、あらかじめ設定されたステップ数にわたり、反復的な生成プロセスを実行します。各ステップで、モデルは現在の[MASK]を含むトークン列とプロンプトを基に、全ての[MASK]箇所に対して最も適切と思われる単語を並列に予測します。
このプロセスの鍵となるのが、LLaDA独自の リマスキング戦略 です。モデルは、全ての予測結果を一度に確定させるのではなく、予測の信頼度が低いトークンを再び[MASK]トークンに戻し、次のステップで再度予測させます。一方で、信頼度が高いと判断されたトークンはそのまま保持します。これにより、文脈的に判断しやすい部分から先に確定させ、より難解な箇所は周囲の文脈が明確になった後のステップで再度予測するという、人間が文章を推敲するプロセスにも似た効率的な生成を実現します。
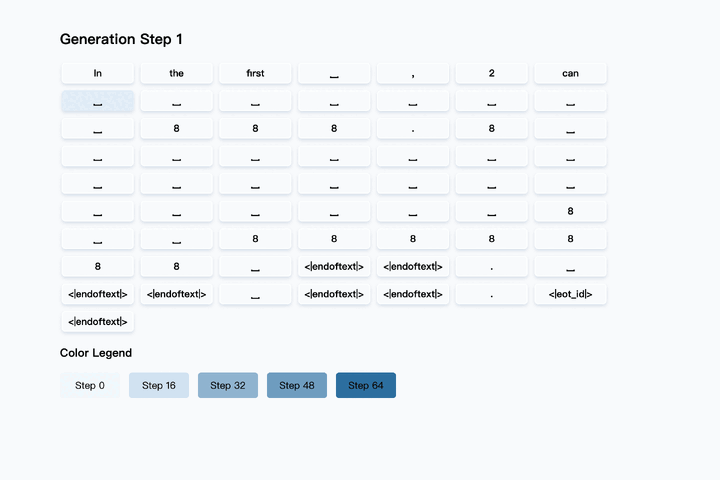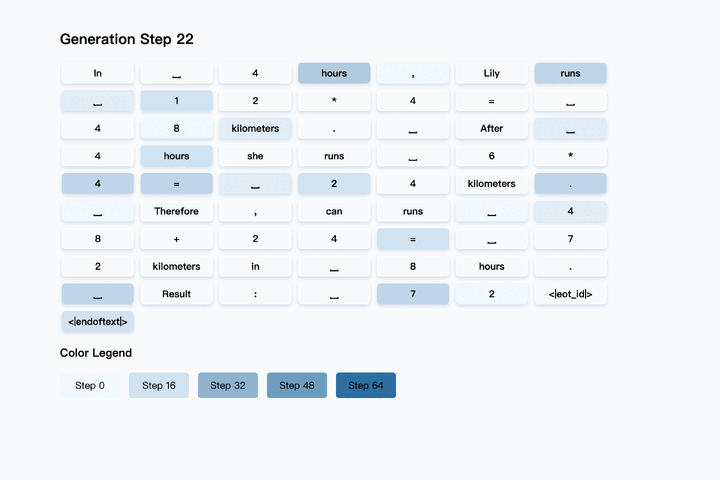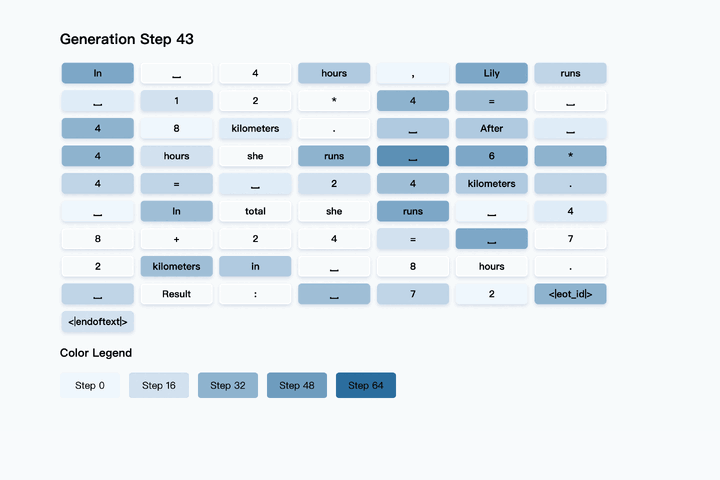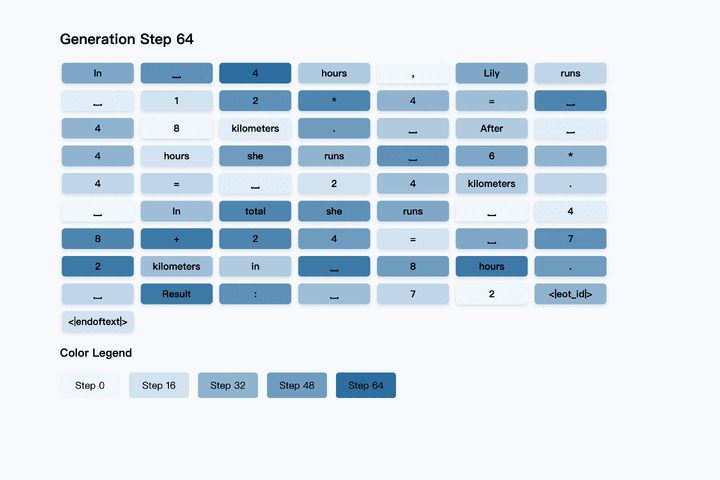
反復生成のイメージ 出典:https://github.com/ML-GSAI/LLaDA
この予測とリマスキングのサイクルを規定回数繰り返すことで、最終的には全ての[MASK]トークンが確定し、洗練された応答文が完成します。さらに、このプロセスは多くの部分を並列処理できるため、将来的には専用ハードウェアなどによる大幅な高速化も見込まれます。また、ステップ数を調整することで、生成品質と処理速度のバランスを柔軟に制御できるという実用上の利点も備えています。

Inference(テキスト生成) 出典:論文Figure2(c)
実験結果
スケーラビリティの検証では、LLaDAがモデルサイズや計算量の増加に応じて着実に性能を向上させることが確認されました。特に、数学的能力を評価する「GSM8K」や、広範な知識を問う「MMLU」といったベンチマークでは、同規模の自己回帰モデルと比較して同等以上のスケーリング特性を示しました。

LLaDAのスケーリング則 出典:論文Figure3
さらに、主要なLLMとの直接比較でも、LLaDA 8Bは顕著な成果を挙げています。Meta社が開発したオープンソースモデル「LLaMA 2 7B」に対しては、評価対象となったほぼ全てのタスクで優れた性能を示しました。加えて、その後継モデル「LLaMA 3 8B」と比較しても、全体として同等の競争力を発揮し、特に数学や中国語関連のタスクでは優位性が確認されました。
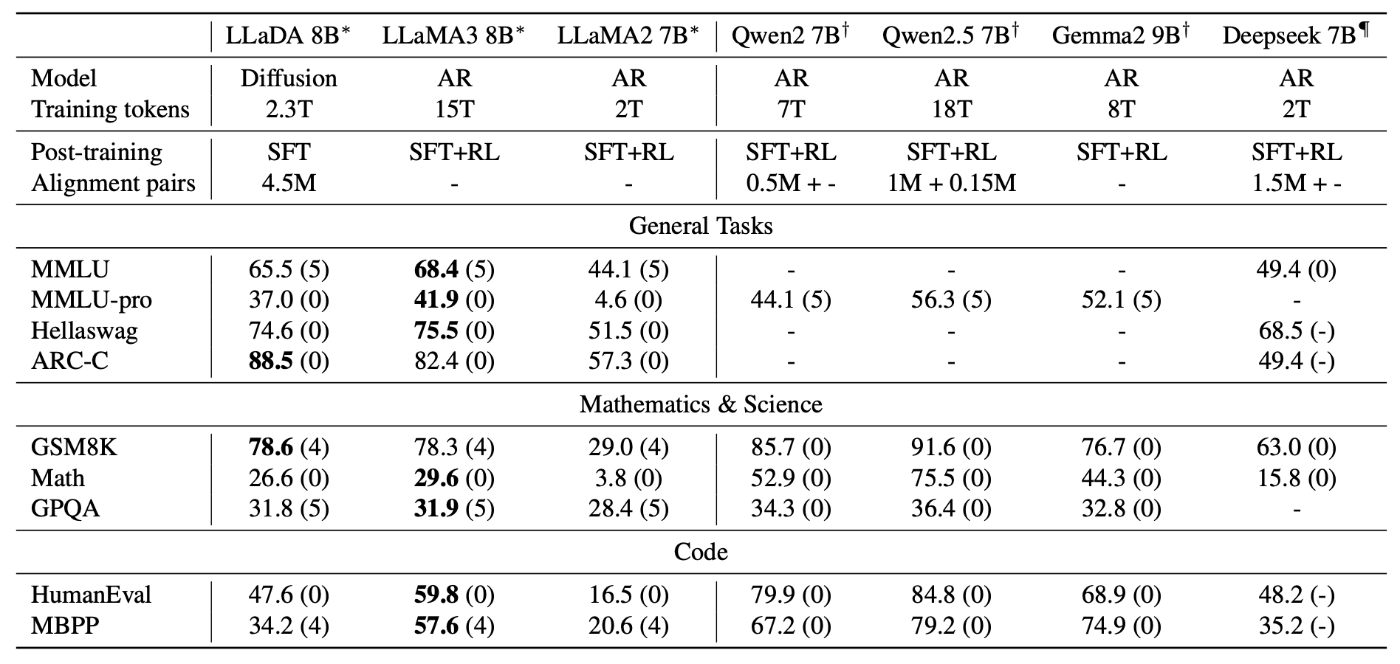
事後学習後におけるLLaDA 8Bと他の主要なベースモデルとの性能比較 出典:論文Table2
特筆すべき成果の一つが、「逆転の呪い」の克服 です。これは、「AはBである」と学習しても「BはAであるか?」という逆方向の推論が苦手という、特に自己回帰モデルに見られる弱点です。中国の古詩における前句と後句の相互補完タスクで、GPT-4oを含む他の強力なモデルが逆方向の推論に苦戦する中、LLaDAは逆方向でも高い性能を発揮しました。これは、双方向の文脈理解を可能にするLLaDAのアーキテクチャ上の特長が、このような構造的な弱点を克服する上で大きな利点となることを示唆しています。

古代中国の詩における逆転の呪いに関する評価 出典:論文Table3
まとめと課題
LLaDAは、MDLMのアーキテクチャを大規模化し、事前学習と教師ありファインチューニングを通じて指示追従性や文脈理解を大幅に強化することで、高性能なテキスト生成を実現しました。双方向的な文脈理解に基づく生成プロセスは、従来の自己回帰モデルとは異なる新しい可能性を提示し、スケーラビリティ、指示追従性、そして逆転の呪いの克服といった面で非常に有望な成果を上げています。
一方で、今後の発展に向けて取り組むべき課題も明確になっています。
- 自己回帰モデルとの性能差: MDLMと同様に、現時点では同等の計算資源下において、最先端の自己回帰モデルに対して性能が劣る場合がある。
- 推論速度の課題: 反復的な生成プロセスにより推論速度が低下する傾向があり、さらなる高速化に向けた最適化が必要。
- 高度なアライメントの必要性: RLHFなどの高度なアライメント手法を導入することで、安全性と有用性のさらなる向上が期待される。
Block Diffusion
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models(2025年3月12日)
これまで両立が難しいとされてきた自己回帰モデルの高い生成品質と、拡散モデルの並列処理能力。この2つの長所を融合する画期的な技術として登場したのが Block Diffusion です。
Block Diffusionは、テキストをブロック単位で自己回帰的に生成しつつ、各ブロック内部は拡散モデルで並列処理するという、新しいハイブリッドアプローチを採用しています。これにより、任意の長さのテキストに対しても高品質かつ効率的な生成が可能となり、従来の拡散モデルを上回る性能を実現しました。
以下に、自己回帰モデル、従来の拡散モデル、そしてBlock Diffusionの生成プロセスの違いを視覚的に示します。
自己回帰モデル: ✅ 高品質 ✅ 任意長生成 ✅ KVキャッシュ利用可 ❌ 並列処理不可

拡散モデル: ❌ 低品質 ❌ 固定長生成が基本 ❌ KVキャッシュ利用不可 ✅ 並列処理可能

Block Diffusion: ✅ 高品質 ✅ 任意長生成 ✅ KVキャッシュ利用可 ✅ 並列処理可能

Block Diffusionの仕組み
Block Diffusionのコンセプトは、「ブロック間は自己回帰、ブロック内は拡散」 と非常に明快です。
具体的には、以下のように動作します。
- テキスト全体を、例えば16トークンずつのブロックに分割します。
- 最初のブロックを拡散モデルで生成します。このブロック内のトークンは、全て
[MASK]の状態からスタートし、反復的なデノイジングプロセスを経て並列的に生成されます。 - 次のブロックを生成する際は、直前に生成したブロックをコンテキストとして与え、それを条件に新しいブロックを拡散モデルで生成します。このブロック間の処理は自己回帰的です。
- ステップ3を繰り返し、ブロックを繋げていくことでテキスト全体を生成します。
このハイブリッドなアプローチにより、以下のメリットが生まれます。
- 任意長の生成: ブロックを順次接続していくことで、学習時のコンテキスト長を超える長文も自然に生成可能。
- 効率的な推論: 生成済みブロックの計算結果をKVキャッシュとして再利用できるため、自己回帰モデルと同等の推論効率を実現。
- 並列サンプリング: 各ブロック内のトークンを並列に生成できるため、自己回帰モデルよりも高速な生成が期待される。
性能向上と安定化の鍵: 「Clipped Schedule」
Block Diffusionは、理論上は自己回帰モデルに匹敵する性能を出せるはずでした。しかし初期の実験では性能にギャップがあり、この論文ではその原因を深く掘り下げ、「勾配の分散 (Gradient Variance)」 が問題の根源であることを突き止めました。
拡散モデルの学習は、データにノイズ(マスキング)を加えて、それを元に戻すタスクです。このとき、加えるノイズの量(マスク率やノイズスケジュール)が重要になります。
- ノイズが少なすぎる(マスク率が低い): 元のトークンがほとんど見えているため、モデルにとってはタスクが簡単すぎ、効果的な学習にならない。
- ノイズが多すぎる(マスク率が高い): 元のトークンに関するヒントがほとんどなく、効率的な学習につながらない。
学習には適度な難易度のノイズレベルが重要ですが、従来のランダムなノイズスケジュールでは、学習に非効率な両極端のケースが多く発生していました。その結果、勾配(学習の方向を示す指標)が不安定になり、学習が非効率になっていました。
そこで、学習に最も効果的と考えられる 中間的なマスク率の範囲だけを重点的にサンプリングする「Clipped Schedule」 という手法を考案しました。これは、ノイズスケジュールの両端(簡単すぎる部分と難しすぎる部分)をカットし、学習に「おいしい」中間部分だけを使うイメージです。さらに、この最適なマスク率の範囲を、ブロックサイズなどに応じて学習中に動的に探索・調整する仕組みも導入しました。これにより学習が劇的に安定し、性能が大幅に向上しました。
実験結果
Block Diffusionは、言語モデリングの標準的なベンチマークで目覚ましい成果を上げています。
-
Perplexityで既存の拡散モデルを凌駕
- LM1Bデータセットにおいて、既存の拡散言語モデル(MDLM、SEDDなど)を最大13%上回るPerplexityを達成しました。
- ARモデルとの性能差を大幅に縮めることに成功しました。

LM1BデータセットでのPerplexity比較 出展:論文Table3
-
優れた長文生成能力
- 学習時のコンテキスト長(1024トークン)の約10倍にあたる約10,000トークンのシーケンスを、品質を落とさずに生成できることを実証しました。
- 生成を
[EOS]か低エントロピー区間が出現するまで継続し、トークン数をカウント

長文生成におけるトークン数 出展:論文Table6
-
高いサンプル品質と効率
- 他のブロックベース拡散モデル(例:SSD-LM)と比較して、桁違いに少ない計算コスト(論文によれば1/40以下)で、より高品質なサンプルを生成できることを示しました。

他のブロックベース拡散モデルとの比較 出展:論文Table7
まとめと課題
Block Diffusionは、「ブロック間は自己回帰、ブロック内は拡散」というアプローチによって、自己回帰モデルの高品質・任意長生成と、拡散モデルの並列処理というメリットを両立させました。また、拡散モデルの性能を制限していた要因の一つである 「勾配の分散」 という学習上の根本問題を特定し、「Clipped Schedule」という独創的な手法でこれを抑制することで、学習を安定させ、性能を飛躍的に向上させました。
この非常に有望なアプローチにも、克服すべきいくつかの課題が残されています。
- 学習コストの増加: Block Diffusionでは、過去の文脈(クリーントークン)と現在のブロック(ノイズ付きトークン)の両方を処理する必要があり、単純な拡散モデルに比べて学習アルゴリズムが複雑化する傾向がある。論文内で効率化は提案されているものの、計算負荷は依然として課題。
- 逐次性とブロックサイズの制約: ブロック間の生成は自己回帰的であるため、完全な並列化は困難。特にブロックサイズが小さい場合、自己回帰モデルと同様の逐次的なボトルネックが発生する。
- 生成モデル共通の課題: ハルシネーション、著作権リスク、有害コンテンツの生成といった、他の大規模言語モデルと共通する倫理的・社会的課題も引き続き存在しており、継続的な対策が求められる。
Gemini Diffusionとは
最後に、Gemini Diffusionについて簡単に紹介し、本記事を締めくくりたいと思います。
Gemini Diffusionは、Google DeepMindが開発中の実験的なテキスト拡散型言語モデルです。2025年5月開催の「Google I/O 2025」で正式に発表されました。現在は一部ユーザー向けにデモ版が公開されており、ウェイトリスト登録制で利用可能です。
Gemini Diffusionの特徴
Gemini Diffusionは、コーディングや数学のベンチマークにおいて、自己回帰型モデル(Gemini 2.0 Flash-Lite)と同等かそれ以上の優れた性能を発揮しています。

ベンチマーク比較 出展:https://deepmind.google/models/gemini-diffusion/
Gemini Diffusionのもう一つの特徴は、その生成スピードです。以下の図はレスポンス速度を示しています。参考として、gpt-4oの生成速度は162トークン/秒程度のようです。(情報源)

生成速度 出展:https://deepmind.google/models/gemini-diffusion/
実際に使用した感想としては、びっくりするほど速く、プロンプトへの応答も非常にスムーズでした。ただ、生成精度については今後の改善に期待という印象も受けました。(なお、筆者はウェイトリスト登録から2日ほどで利用可能となりました。気になる方は早めに登録しておくといいと思います。)
Gemini Diffusionを試した実際のレビューは、以下の記事にまとめられています。から確認できます。コード生成、数学問題の解答、画像との連携などにおける実施例が紹介されていますので、興味のある方はご参照ください。
おわりに
本記事では、現在注目を集める拡散言語モデルについて、その基本的な仕組みから主要な先行研究までを辿ってきました。まだまだ発展途上という印象は否めませんが、近い将来、私たちの想像を超える進化を遂げ、自己回帰型から拡散型への移行が進むということがあるかもしれません。今後もこの分野の動向に注目し、新たな発見や進展があれば、改めて記事としてまとめていきたいと思います!
最後までお読みいただき、ありがとうございました。
参考資料
- Simple and Effective Masked Diffusion Language Models
- Large Language Diffusion Models
- Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
- Masked Diffusion Modelの進展
- 【DL輪読会】 Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
- Mercury CoderとLLaDA: 拡散言語モデルによる高速文章生成
Discussion