GeminiでMulti-Modal RAGを実装した話
こんにちは、SlalomのD&Aチームに所属するRyoです。LinkedInプロフィール
昨年から弊社のMLチームでは、技術研鑽を目的としてLLMに関する勉強会などを行っています。それに関連して、今年から自分自身が興味のある分野(AI/MLだけでなく)を少しずつ記事としてアウトプットしていこうと思い、本取り組みを始めました。
記念すべき第1回目は、GCP上でGeminiを用いてMulti-Modal RAGを構築した事について書いていきます。
対象読者
・本記事は、GCPでGeminiを使ってMulti-Modal RAGを動かしてみたいな。という読者向けに書きましたので、アカデミックな内容やOps周り、本番レベルの実装を想定している方は、本記事をスキップしてください。
紹介する内容
・今回紹介する内容は、昨年末にGoogleからGeminiの利用が可能となったので、GCP上でGeminiを用いたMulti-Modal RAGを構築した事についてを紹介しようと思います。
語彙の説明
- Multi-Modal AI
・複数のデータモードに対応し現実問題をより正確に解釈できる人工知能のことです。長い間、機械学習は1つのデータモード(音声、画像、言語など)にしか対応されておらず、人間のように歌詞を見てリズムに乗りながら歌を歌うというような、複数のデータモードに対して対応できるようになることは、現実世界の問題を解くことにおいて重要な要素だとされていました。
-
Multimodality and Large Multimodal Models (LMMs)
・LLMにモダリティ性を追加することで生まれたモデルをLMMs(Large Multimodal Models)と言われる。(例:ChatGpt, Gemini, Flamingoなど)
※マルチモーダルシステムは、すべてLMMsでないことに注視してください。(Dall-EやStable-Diffusionなど) -
Retrieval-augmented Generation (RAG)
・RAGとは、モデルの外部から関連データを取得し、そのデータで質問者が入力した文章と組み合わせ出力を生成することを指します。RAGの思想は、2020年にMetaから発表されており、LLMが開発されて以降、より注目を浴びています。論文
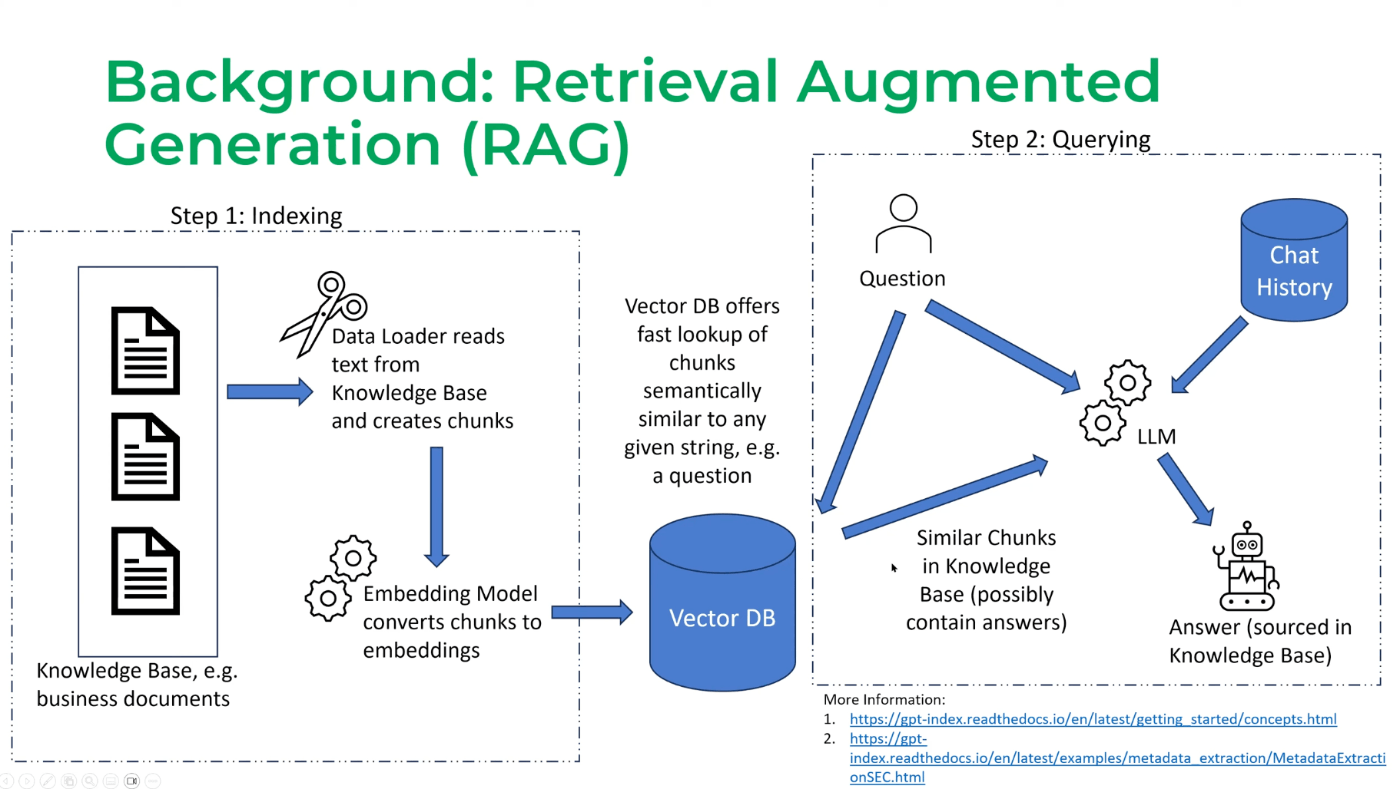
- Multi-Modal RAG
・Multi-Modal RAGは、複数のデータモードを使用して情報を検索し、ユーザーの質問と関連情報をもとに回答を生成することを指します。
デモ
-
デモの説明
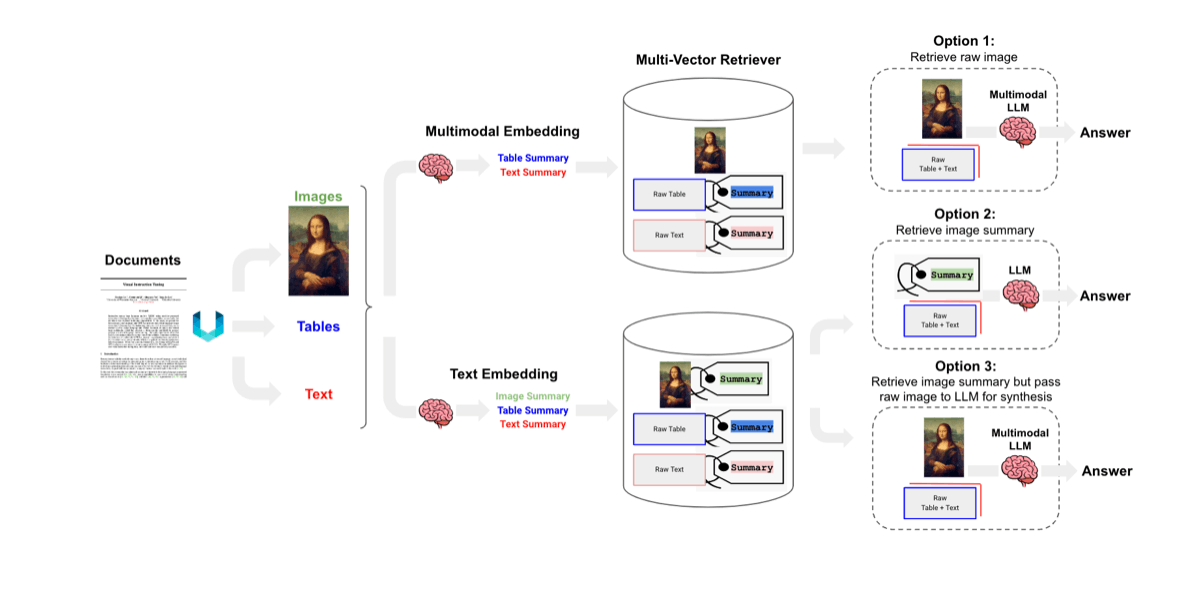
現状のMulti-Modal RAGの実装パターンには以下の3パターンが存在します。今回は、その中でもオプション3の手法を用いてデモを実施したいと思います。
- オプション1
・Multi-Modalモデル(CLIPなど)でテキストと画像をベクトル化
・クエリーと関連する情報を取得
・生画像とテキスト情報をMulti-Modal-LLMへ入力し回答を生成
-
オプション2
・テキストを生成するためにMulti-Modal-LLMを使用してベクトル化
・クエリーと関連する情報を取得
・関連文章とクエリーから回答を生成 -
オプション3
・画像からテキストを生成するためにMulti-Modal-LLM使用
・生成したテキストを使用して抽出
・Multi-Modal-LLMに画像とテキストデータを用いて解答を生成
-
実装
- 今回はこちらのPDFをデータセットとして使用しました。データセット
-
PDFファイルからテキスト、画像情報を取得
- PDFからデータタイプ毎にデータを取得するにあたり、fitzというモジュールを使用して、PDFから情報を取得しました。
import fitz
def get_pdf_doc_object(pdf_path: str) -> tuple[fitz.Document, int]:
"""
`fitz.open()`を使用してPDFファイルを開き、PDFドキュメントオブジェクトとページ数を返します。
引数:
pdf_path: PDFファイルへのパス。
戻り値:
`fitz.Document`オブジェクトとPDF内のページ数を含むタプル。
"""
# PDFファイルを読み込む
doc: fitz.Document = fitz.open(pdf_path)
# PDFのページ数を格納
num_pages: int = len(doc)
return doc, num_pages
doc, num_pages = get_pdf_doc_object(FILE_PATH)
-
情報のベクトル化
- 各ページごとのテキストと画像情報を取得し、以降の処理で扱いやすいデータ形式に前処理を行います。本来は、以下の処理を一つにまとめて実装することもできるのですが、今回は各データタイプ毎の処理を明確にするために分割して実装を行いました。
-
テキスト:
- ページごとに文章の要約を作成し、Json形式で要約前後のデータのJSONを作成。
def summarize_text_data(text: str) -> str: """ gemini-proモデルを使用してテキストデータを要約 引数: text: 要約するテキスト 戻り値: 要約テキスト """ generate_contet_list = ["""You are an assistant tasked with summarizing text for retrieval. \ These summaries will be embedded and used to retrieve the raw text or table elements. \ Give a concise summary of the text that is well optimized for retrieval.""",text] model = GenerativeModel("gemini-pro") res = model.generate_content(generate_contet_list) text_sum = res.candidates[0].content.parts[0].text return text_sum #metadata定義 text_metadata = {} #ページごとにloop for page in doc: page_text = page.get_text() page_num = page.number + 1 print(f'Page num is {page_num}, Page text length is {len(page_text)}') summarized_page_text = summarize_text_data(page_text) text_metadata[page_num] = { "summarized_text": summarized_page_text, 'text':page_text, } -
画像:
- 画像のキャプションを生成し、生成した文章、画像のパス、画像データなどのメタデータと共にJSONを作成。
for page in doc: page_num = page.number + 1 print(f'Page num is {page_num}') # 画像処理 # ページに複数ある場合があるので、loopで処理 image_data = page.get_images() for image_no, image in enumerate(image_data): image_num += 1 # 画像を取得 xref = image[0] pix = fitz.Pixmap(doc, xref) # 画像情報をjpegに変換 data = pix.tobytes("jpeg") # 画像情報を保存 os.makedirs('./image/', exist_ok=True) image_name = f"./image/image_{page_num}_{image_num}_{xref}.jpeg" pix.save(image_name) # データを読み込む ImageData = Image.load_from_file(image_name) # 画像を読み込む image_content = open(image_name,'rb').read() encoded_content = b64encode(image_content).decode("utf-8") # 画像をテキスト化 generate_contet_list = ["""You are an assistant tasked with summarizing images for retrieval. \ These summaries will be embedded and used to retrieve the raw image. \ Give a concise summary of the image that is well optimized for retrieval.""",ImageData] res = model.generate_content(generate_contet_list) image_description = res.candidates[0].content.parts[0].text # 各画像にメタデータをJSON image_metadata[image_num] = { "image_num": image_num, "image_path": image_name, "image_description": image_description, "image":encoded_content }
-
-
データをデータベースに格納
・前項で作成した画像、テキストデータのJSONをデータベースに格納するために、LangChainとChromaのインメモリーデータベースを用いて情報のベクトル化、メタデータをデータベースに登録します。MultiVector Retrieverについて
import uuid
from langchain.embeddings import VertexAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
def create_multi_vector_retriever(
vectorstore: Chroma,
text_metadata: Dict[str, Dict[str, str]],
image_metadata: Dict[str, Dict[str, str]]
) -> MultiVectorRetriever:
"""
リトリーバーを作成
引数:
vectorstore (Chroma): ベクターストア
text_metadata (Dict[str, Dict[str, str]]): 'text'および'summarized_text'を含むテキストのメタデータ
image_metadata (Dict[str, Dict[str, str]]): 'image'および'image_description'などを含む画像のメタデータ
戻り値:
MultiVectorRetriever: 作成されたマルチベクトルリトリーバー
"""
# インメモリのストレージ枠を初期化
store = InMemoryStore()
id_key = "doc_id"
# Multi-vector retrieverを作成
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# vectorstoreとdocstoreへデータを入れる関数を作成
def add_documents(retriever, meta_data, raw_data):
doc_ids = [str(uuid.uuid4()) for _ in meta_data]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(meta_data)
]
retriever.vectorstore.add_documents(summary_docs)
# key valueのデータ(uuid,と要約前のテキスト)を格納
retriever.docstore.mset(list(zip(doc_ids, raw_data)))
# テキストと画像情報を格納
if len(text_metadata)>0:
texts = [s['text'] for s in text_metadata.values()]
meta_data = [s['summarized_text'] for s in text_metadata.values()]
add_documents(retriever, meta_data, texts)
if len(image_metadata)>0:
images = [s['image'] for s in image_metadata.values()]
meta_data = [s['image_description'] for s in image_metadata.values()]
add_documents(retriever, meta_data, images)
return retriever
# ベクターストアーの初期化
vectorstore = Chroma(
collection_name="multimodal_rag_demo",
embedding_function=VertexAIEmbeddings(model_name="textembedding-gecko@003"),
)
# retrieverの作成
retriever_multi_vector_img = create_multi_vector_retriever(
vectorstore,
text_metadata,
image_metadata
)
-
関連情報の取得
-
構築したデータベースにアクセスし、ユーザークエリーに関連する情報が取得できているかを確認していきます。
- サンプルクエリー1
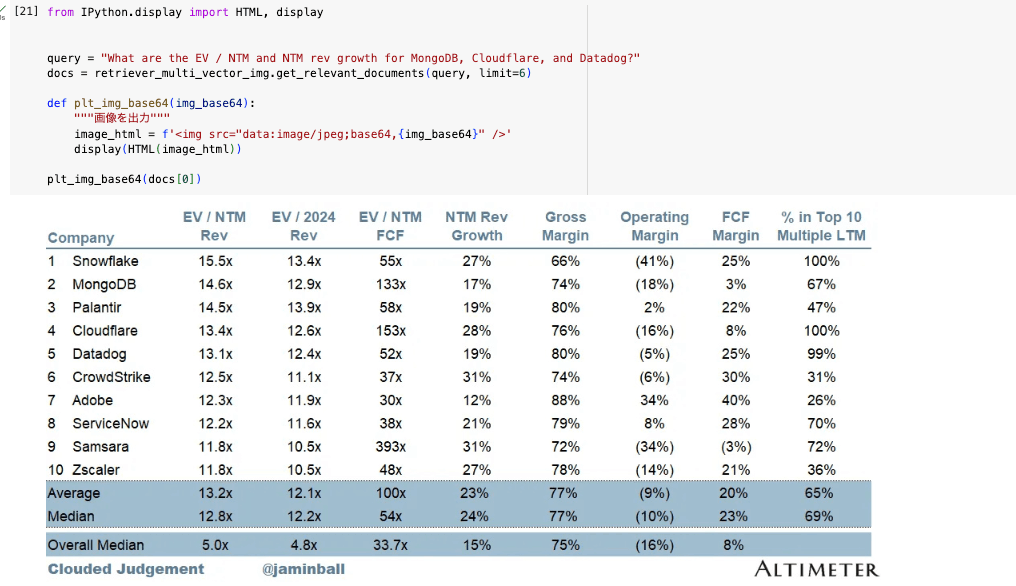
- サンプルクエリー2
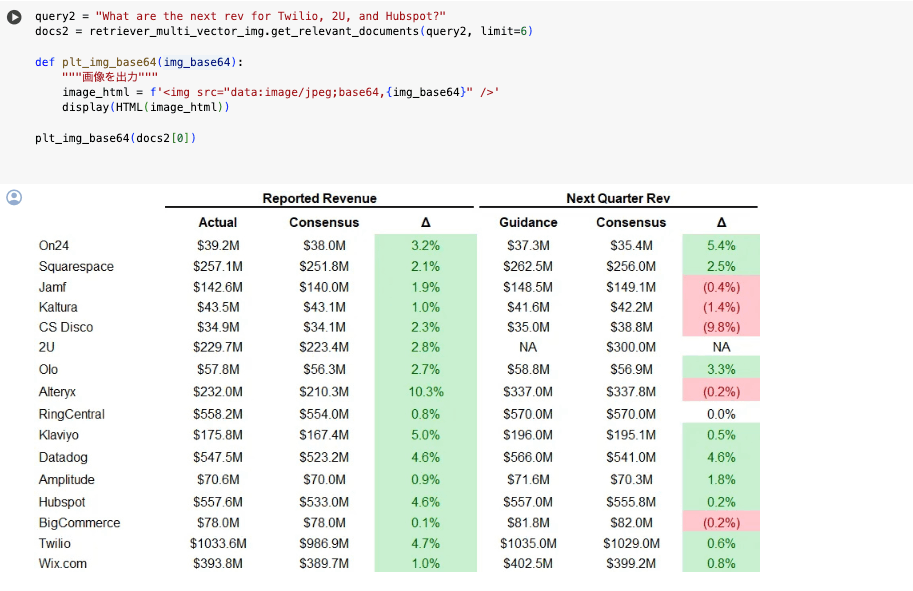
以上の結果から、クエリーに対して尤もらしいデータが取得できていることが確認できました。
-
文章生成
- ここまでで情報のretrieveができたので、最後にユーザークエリーと取得した情報を用いて回答の生成を行なってみたいと思います。※今回は、プロンプトエンジニアリングはスコープ外なので控えています
def is_image_data(b64data):
"""
引数のデータが画像データかどうかを判定
"""
image_signatures = {
b"\xFF\xD8\xFF": "jpg",
b"\x89\x50\x4E\x47\x0D\x0A\x1A\x0A": "png",
b"\x47\x49\x46\x38": "gif",
b"\x52\x49\x46\x46": "webp",
}
try:
header = base64.b64decode(b64data)[:8] # デコードして、最初の8 bytes取得
for sig, format in image_signatures.items():
if header.startswith(sig):
return True
return False
except Exception:
return False
def is_text_data(data):
"""
テキストデータかどうかを判定
"""
return isinstance(data, str)
# 文章生成処理
def process_data(data):
if is_image_data(data):
# 画像データの処理
data = Image.from_bytes(base64.b64decode(docs[0]))
elif is_text_data(data):
# テキストデータの処理
pass
else:
# 未知のデータ型に対する処理
raise ValueError("対応できないデータタイプです")
# 回答の生成
return generate_output(data).candidates[0].content.parts[0].text
サンプルクエリーは、「4」で使用したクエリーと取得データを元に確認していきたいと思います。
- サンプルクエリー1
<プロンプト>
本文:
You are an IT market analyst. Please answer the question based on the provided data.', 'Question: What are the EV / NTM and NTM rev growth for MongoDB, Cloudflare, and Datadog? Provided data:', <vertexai.generative_models._generative_models.Image object at 0x7f7bb83d8550>
日本語訳:
あなたはIT市場アナリストです。提供されたデータに基づいて質問に答えてください: MongoDB、Cloudflare、DatadogのEV / NTMとNTM Revの伸びは?提供されたデータ:',<vertexai.generative_models._generative_models.Image object at 0x7f7bb83d8550>
<回答>
本文:
The EV / NTM Rev and NTM Rev Growth for MongoDB, Cloudflare, and Datadog are as follows:\n\n
- MongoDB: EV / NTM Rev = 14.6x, NTM Rev Growth = 17%\n
- Cloudflare: EV / NTM Rev = 13.4x, NTM Rev Growth = 28%\n
- Datadog: EV / NTM Rev = 13.1x, NTM Rev Growth = 19%
日本語訳:
MongoDB、Cloudflare、DatadogのEV / NTM RevとNTM Rev Growthは以下の通り。
- MongoDB: EV / NTM Rev = 14.6倍、NTM Rev Growth = 17%n
- Cloudflare EV / NTM Rev = 13.4x, NTM Rev Growth = 28%n
- データドッグ EV / NTM Rev = 13.1倍、NTM Rev成長率 = 19
DeepL.com(無料版)で翻訳しました。
- サンプルクエリー2
<プロンプト>
本文:
You are an IT market analyst. Please answer the question based on the provided data.', 'Question: What are the next rev for Twilio, 2U, and Hubspot? Provided data:', <vertexai.generative_models._generative_models.Image object at 0x7f7bb861eec0>
日本語訳:
あなたはIT市場アナリストです。提供されたデータに基づいて質問に答えてください、
質問: Twilio、2U、Hubspotの売上は?
提供されたデータ:'<vertexai.generative_models._generative_models.Image object at 0x7f7bb83d8550>
<回答>
本文:
The next revenue for Twilio is $1035.0m, for 2U is $300.0m, and for Hubspot is $552.0m.
日本語訳:
Twilioの次の売上は1億3,500万ドル、2Uは3億ドル、Hubspotは5億5,200万ドル。
DeepL.com(無料版)で翻訳しました。
これらの結果から、クエリーは画像データを参照し、回答していることがわかります。
まとめ
- 今回は、Geminiを使用したMulti-Modal RAGのデモを行いました。
LLMの事例やノウハウが増えてきている中で、今後はLMMsの事例も小売やヘルスケアなどを中心に増えてくると思います。その中で、こちらの記事が読者の知見に何かしらの役に立つことができれば幸いです。
Discussion