テキスト生成の為のデコーディング方法の紹介
こんにちは、SlalomのD&Aチームに所属するRyoです。LinkedInプロフィール
前回は、Geminiを用いたLMMs RAGのデモをさせて頂きました。今回は、デモではなくAIがテキスト生成するときのデコーディング方法についての紹介をしていきたいと思います。
対象読者
今回は、テキスト生成を行うときにAIがどのように出力するかを理解したい読者向けに記載しております。
紹介する内容
LLMが出現し、ChatGPTなどで誰でも簡単にAIを使えるようになった一方で、未だハルシレーションや一貫性の無い出力などをすることがあります。
これらに対する対処法は、ウェブ上に多くありますが、そもそもAIがどのようにテキストを生成しているかが記載された情報が少ないと感じました。
ですので今回は、AIがテキスト生成をするためのデコーディング方法についての概要を参照リンクの情報を元に紹介していきたいと思います。
言語生成
よくある深層学習の例にある犬や猫の分類問題を考えたときに、出力結果として犬が20%、猫が80%などの確率値を出力し、分類パターンが最大値の結果を取得します。しかし、言語生成の場合は、自己回帰的に単語ごとに尤もらしい値を連続で出力していきます。(今後、自己回帰型言語生成と呼ぶ)
つまり、自己回帰型言語生成とは、単語列の確率分布が条件付き単語分布の積に分解できるという仮定に基づいていると言えます。

以降、この手法が元となる様々なデコーディング手法がありますので、紹介していきたいと思います。
Greedy Search(貪欲法)
Greedy searchは、次の単語を選ぶ際に、最も高い確率値を持つ単語を選択していく手法です。
以下の例の場合、"The nice woman"が選ばれます。
この手法は、かなり高速ですが、今回の例にある条件付確率が0.9と最も高いと言われる "has "は "dog "の後ろに隠れているので、Greedy searchだと選択を逃してしまいます。さらに、同じ単語を選択するリスクも存在します。
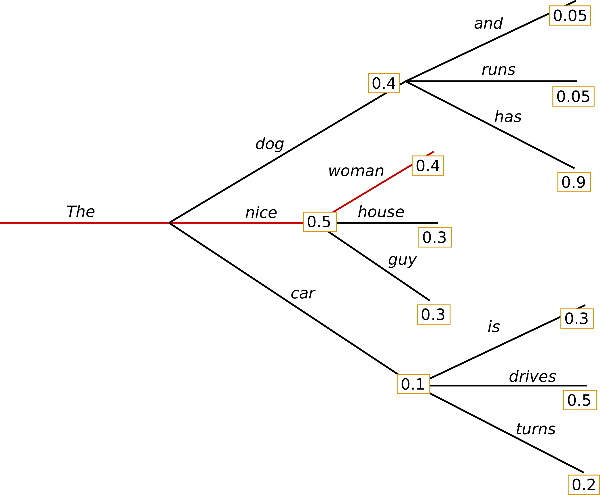
Beam Search(ビームサーチ)
Greedy Searchにあった文字列の繰り返しや、後ろに隠れている高い確率値の見逃しを抑制する方法として、Beam Searchがあります。これは、最も高い確率の単語だけでなく、Top-Kの単語を選択することで、複数の候補を作成し、最終的に最も高い確率値を持つ単語列を選択します。この場合、"The nice woman"ではなく、"The dog has"という単語列が選択されます。
(全ての単語が選択されるわけではありません。)

同じくBeam Searchにも弱点があります。人間の文章に比べてランダム性と出力に多様性がないため、ほとんど同じ出力になってしまうという問題があります。論文
同じ出力が選択され続ける例:

Sampling
前述の2つのデコーディング手法は、確率値に基づいて決定論的に次の単語が選択されていましたが、Samplingの場合、条件付き確率分布P(w|"The")から単語("car")がサンプリングされ、続いてP(w|"The", "car")から("drives")がサンプリングされます。つまり、出力にランダム性を与えてより創造的にしていくことを元に生まれました。

Temperature
しかし、Samplingにも、まだ人間と比べ創造的な文章を生成する可能性が低くなることがあります。例えば、"The car drives"と言う文章を生成されるために、P(w|"The")から単語("car")は10%の確率でサンプリングされますが、一般的には"nice"や"dog"の方がサンプリングされる確率が高くなります。(出力確率の重み付によって)これを回避するために稀な単語がサンプリングされる確率を上げ、一般的な単語の確率を下げることで、より創造的な文章を作成するために"Temperature"を使用して調整をします。
以下の図は、上記の図の結果に対してTemperatureをより低い値に設定したときの結果となっています。(より鋭い分布にすることで、ランダム性を抑制される)

Top-K Sampling
Top-K Samplingは、出力分布の高い確率の上位K個を取得し、そこからサンプリングする方法です。GPT2はこのサンプリング方式を採用しており、これがストーリー生成で成功した理由の1つとなっています。
例えばK=6としたときに、以下の図にあるp(w|"The")では、全出力の2/3の単語から次の値をサンプリングします。しかし次の出力では、99%の確率分布を網羅しており、残りの(not,the,small,told)などの値は、適切に排除されていますが、確率値の低い単語(a,down)なども含まれていることで、望ましくない出力がされる可能性があります。

Top-P Sampling
Top-K Samplingとは違いTop-P Samplingは、上位K個の中から出力を選択するのではなく、確率分布を降順に並べ、累積値がPまでの値から出力を生成します。
例えば、P=0.92を設定すると、Top-P Samplingは、累積確率値がp=0.92までの単語から選びます。この例では、最も可能性の高い9つの単語が含まれていたのに対し、2番目の例では92%を超えるために上位3つの単語から選択されます。これは、P(w∣"The") のように、次の単語が予測しにくい単語を広範囲に抽出し、P(w∣"The", "car") のように、次の単語が予測しやすい単語だけが抽出されます。

Stop Condition
自己回帰言語モデルは、次々とトークンを生成することによって、トークンのシーケンスを生成します。なので結果として、長い出力シーケンスは時間がかかり、計算コスト(お金)がかかるため、モデルのシーケンスを停止する条件を設定したい。という場面が多々あります。
停止する1つの簡単な方法は、一定のトークン数の後に生成を停止するようにモデルに要求することです。この欠点は、出力が文の途中で切れてしまう可能性が高いことです。もう1つの方法は、停止トークンを使うことである。例えば、"<EOS>"に遭遇したときに生成を停止するようモデルに命令します。停止条件を設けることで、出力の待ち時間とコストを抑えることができます。
構造化アウトプット
ユースケースによっては、次のようにモデルの出力結果を構造化データで持ちたい場合があります。
- text-to-SQL, text-to-regexなど、クエリーや正規化をするとき
- "こちらがその文章です"のようなバッファテキストなしで商品情報などのように特定のキーを持ちたいとき
このケースに対して、OpenAIはテキスト生成においてJSON modeを提供しています。
しかしJSONモードは:
- JSON出力を有効にしますが、JSONの中身は保証しない
- トークンサイズが長すぎると途中のJSON出力中にも関わらず、停止条件によって切り捨てられます。一方で、最大トークンが長すぎた場合も、モデルのレスポンスが遅くなりコストも高くなるので、適切な長さを選ぶ必要がある
とされているので、実装する際は要検討です。
また、出力を構造化させる独立したツールとして、guidanceやoutlinesのようなサービスも誕生しています。
OpenAIによる構造化データの出力例:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
response_format={ "type": "json_object" },
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
)
print(response.choices[0].message.content)
上記のプロンプトは、以下のアウトプットとなります。
"content": "{\"winner\": \"Los Angeles Dodgers\"}"`
構造化データの生成方法
構造化データを出力する方法として、ファインチューニング、サンプリング、プロンプトチューニングの3つのレイヤーで調整することができます。
プロンプトチューニングは、最も簡単な方法ですが、常にプロンプト通りの結果が出るとは保証できないため確実性に欠けます。
ファインチューニングは、モデルが自分の望むフォーマットで出力を生成するための最も一般的なアプローチです。モデルのアーキテクチャを変更していても、しなくても、ファインチューニングを行うことができます。しかし、この方法も常に期待されたフォーマットを出力することを保証するわけではありませんが、これはプロンプトを表示するよりも信頼できます。また、プロンプトに望ましいフォーマットの説明や例を含める必要がなくなるため、推論コストを削減できるという利点もあります。
しかし今後は、最小限のプロンプトで自分の望むフォーマットで出力を得ることができ、これらのテクニックの必要性は低くなっていくと考えます。
まとめ
以上で、今回はAIが文章を生成するときのデコーディング方法についてご紹介させて頂きました。今後、ますます簡単に構造化データでの出力に対応できるようになることで、既存or新規システムに対してLLMが組み込まれるユースケースなどが増えると考えます。その時に、本記事が実装の助けになれれば幸いです。
Discussion