LoRA+のざっくりとした論文解説


こんにちは、初めましての方は初めまして。rkです。最近の論文を気軽に読めたらなってことでなるべくこのアカウントでは、わかりやすく大雑把に論文をまとめていくつもりです。
誤字、訂正等あればお知らせください。
この記事では、「LoRA+: Efficient Low Rank Adaptation of Large Models」(以降、LoRA+ として参照)の解説を行います。この記事では、LoRA+ってのは要するにLoRAの改良版で、ざっくり言うと精度が1~2%、速度が2倍まで上がりましたよって感じです。
速度2倍って本当?ってことで後で検証していきます。
そもそもLoRAとは?
そもそもLoRAとは?って方もいると思うですが、ざっくりいうとFine-tuning手法です。
ChatGPTやGeminiなど生成系AIが最近すごいっすよね。でも例えば「社内の情報向けにもっと精度上げたいよ」、みたいな方のためにFine-tuningというAIモデルのパラメータを弄くるものがあります。
例えばGPT-3モデルのパラメータ数は1750億(人間の脳のニューロンで1000億)なので、これらを弄くるのはめっちゃ大変だよね?ってことで、めちゃめちゃ楽にFine-tuningしちゃおうってものがLoRAです。
詳しくはこちらのページにて載っていますが、一応、大雑把な解説をしときます。
図1
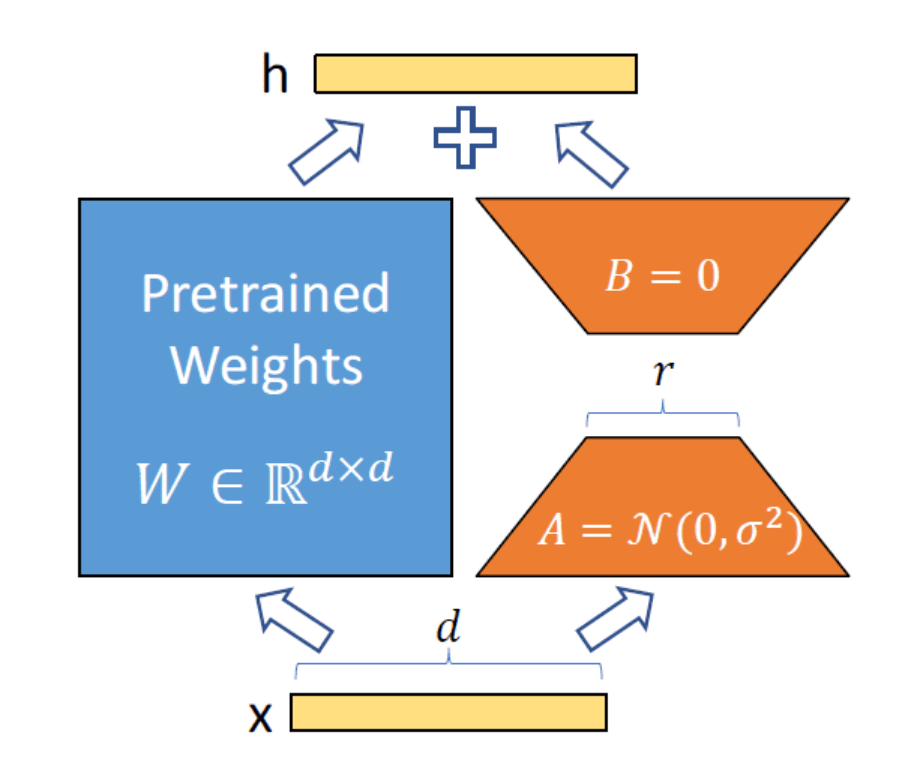
例えばW(10×10行列)をパラメータだと思ってイメージしてください。これらの行列の中の値をすべていじるのは10×10=100個いじらなきゃですよね?
しかしA(10×1行列)とB(1×10行列)を用意してW=ABの形にしてあげて、AとBの方をいじったら1×10×2=20個だけで良くてHappyだよねーってことです。
提案手法:LoRA+
LoRA+は、行列AとBに対して異なる学習率を設定するといいことがあるらしい。
図2
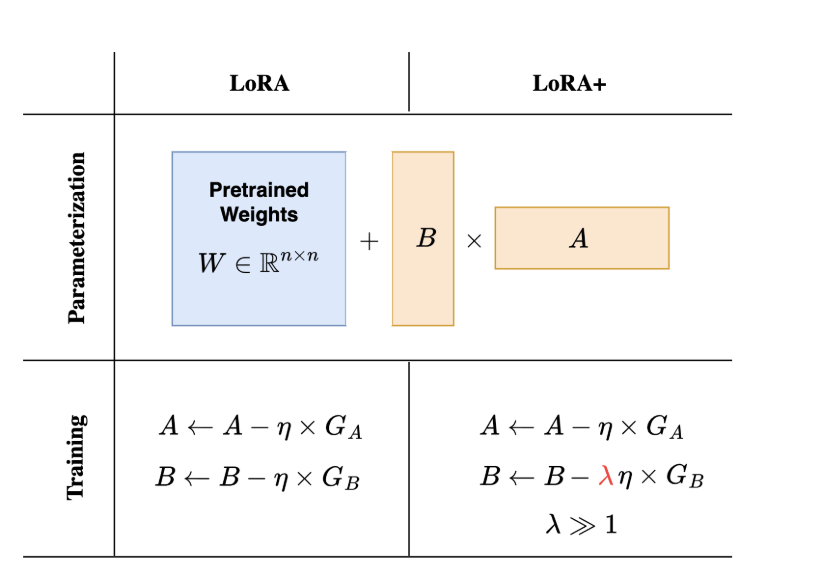
例え話
学習率について読む前により皆さんの理解が深まる例を出しておきます。
シナリオ
想像してみてください。あなたは大規模な工場のマネージャーです。この工場では、原材料を受け取って、最終製品を作り出すという複雑なプロセスを管理しています。この工場には2つの主要なチームがあります。
Aチーム(行列A): 原材料を細かく分析し、品質をチェックするチーム
Bチーム(行列B): 分析結果を基にして、最終製品を組み立てるチーム
初期値
Aチームは、さまざまな分析機器を持っており、最初からこれらの機器を使って原材料を詳細に分析します。つまり、彼らはすでに何かしらの経験やツールを持っています(正規分布に従って初期化)。
Bチームは、最初は何も持っていません。彼らはAチームの分析結果を待って、それに基づいて仕事を始めます(0で初期化)。
学習率の設定
Aチームの学習率: Aチームは分析の精度を徐々に向上させる必要があります。彼らが急に新しい方法を試すと、結果が不安定になってしまいます。したがって、彼らは少しずつ学びながら、分析の精度を高めていきます(低い学習率)。
Bチームの学習率: Bチームは、分析結果を受け取ったら迅速に行動する必要があります。彼らが遅いと、工場全体の生産効率が下がってしまいます。したがって、彼らは素早く学び、効率的に最終製品を組み立てる必要があります(高い学習率)。
なぜ異なる学習率?
役割の違い: Aチームは慎重に原材料を分析し、徐々に精度を上げていく必要があります。一方、Bチームはその分析結果を基に迅速に行動し、最終製品を効率的に組み立てる必要があります。
効率と安定性: Aチームが急に変化すると分析結果が不安定になり、Bチームが遅いと工場全体の生産が遅れます。異なるペースで学習することで、工場全体が安定して効率的に運営されます。
実際の提案手法
1. 行列Aの学習率(ηA)
Aの学習率は低く設定する必要があります。これにより、Aは特徴量を細かく調整し、安定して学習することができます。
設定方法
- 公式: ηA = Θ(n^−1)
- 説明: n:モデルの幅(ニューラルネットワークの層の数)です。θの意味は、反比例するという意味。つまりAの学習率は、モデルの幅に反比例して設定されます。
2. 行列Bの学習率(ηB)
Bの学習率は高く設定する必要があります。これにより、Bは迅速に学習し、特徴量を効果的に組み合わせることができます。
設定方法
- 公式: ηB = λ * ηA
- 推奨値: λ ≈ 24
- 説明:Bの学習率はAの学習率の24倍程度に設定するのが良い。
実験結果
図3
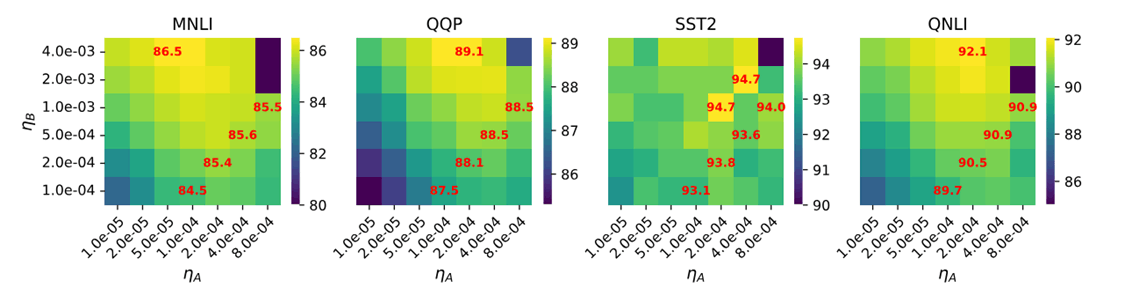
図の見方としてはだんだん薄い色に行けば行くほどスコアが良くなる。
確かに結果はその通りなんだけど、面白いのはタスクによって学習率が異なるってことだね。
というかめちゃめちゃいろんな学習率で実験してるけどどうやってやったんだ?地道に?
まとめ
LoRA+は、大規模モデルのファインチューニングを効率化するための新しい手法です。異なる学習率を設定することで、特に従来よりも早くfine-tuning可能+精度も保証されています。
Discussion