[超初心者向け!] 分散アルゴリズム Raft の Log Replication を図でわかりやすく解説[その3]
はじめに
recovery phase における Raft プロトコルを解説してみようと思います!
この記事の対象者
・分散トランザクションに興味がある人
・分散アルゴリズムに興味がある人
紹介する論文 / 参考文献
Diego Ongaro, John Ousterhout (2014) "In Search of an Understandable Consensus Algorithm (Extended Version)",https://raft.github.io/raft.pdf
最初から読みたい方はこちらから:
目次
5.0 Raftとは?
5.1 基本情報
5.2 Election
5.3 Log Replication
5.4 Safety
5.2 Operation
今回扱うところは Operation の範囲です!(水色の矢印)
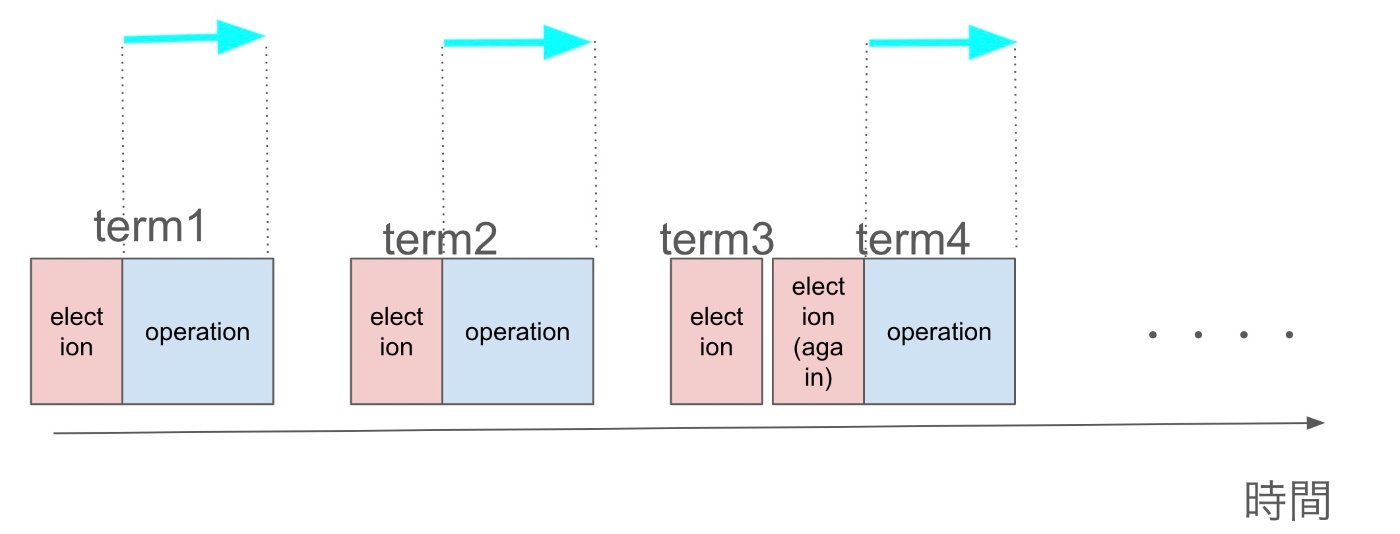
Election を読みたい人はこちらから
正常に処理できる場合
1. クライアントからの要求がリーダーに送信され、ログに追加される
クライアントからの処理の要求はリーダーに送られ、リーダーのデータベース内にあるログに追加されます
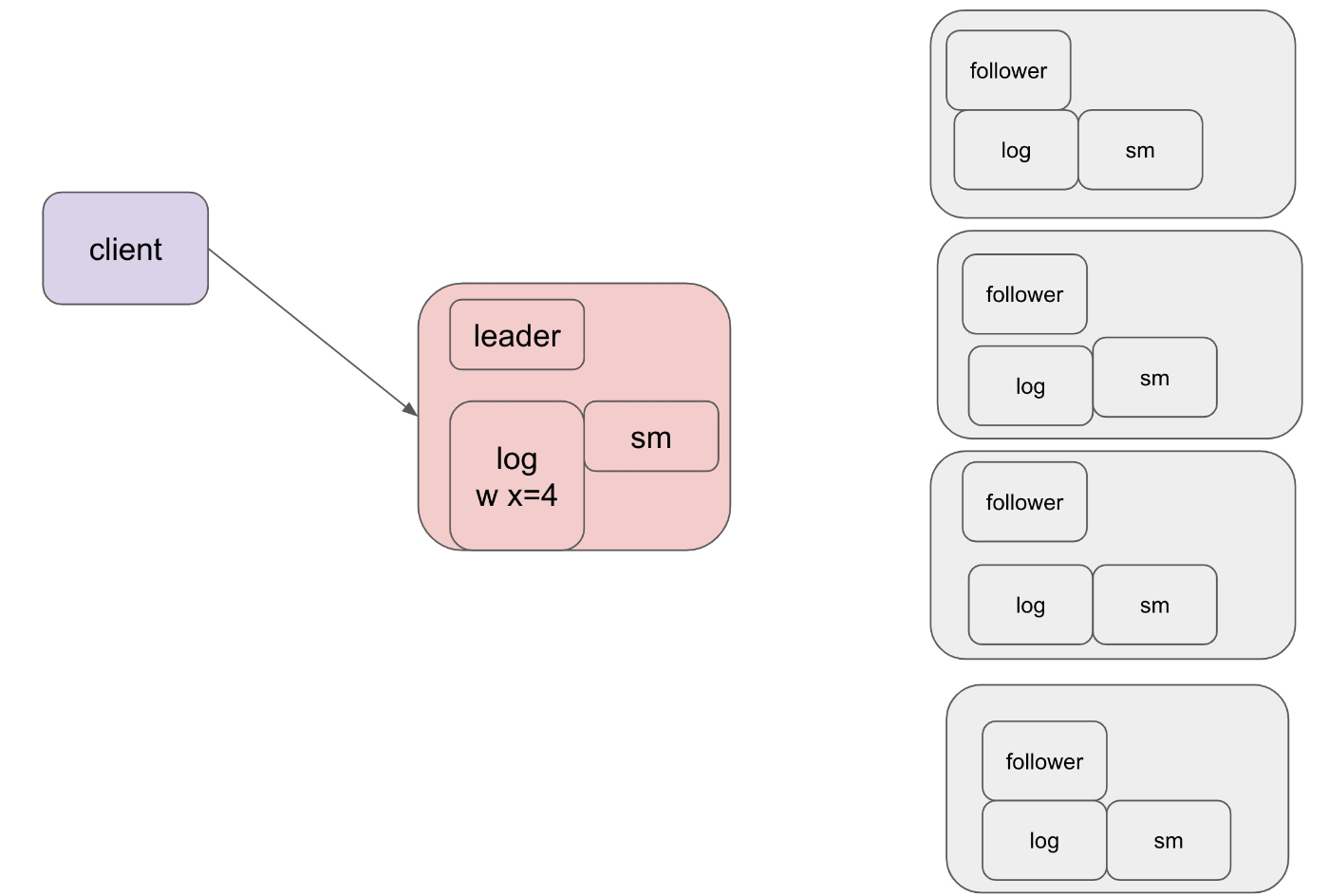
リーダーのログを更新する
2. フォロワーにRPCを送り、フォロワーもログを更新する
リーダーはフォロワーに AppendEntriesRPC を送信します
このRPCにはリーダーのログが含まれていて、フォロワーはそのログを確認しログを更新します
(フォロワーが死んでいる場合、ログを更新することはできません)
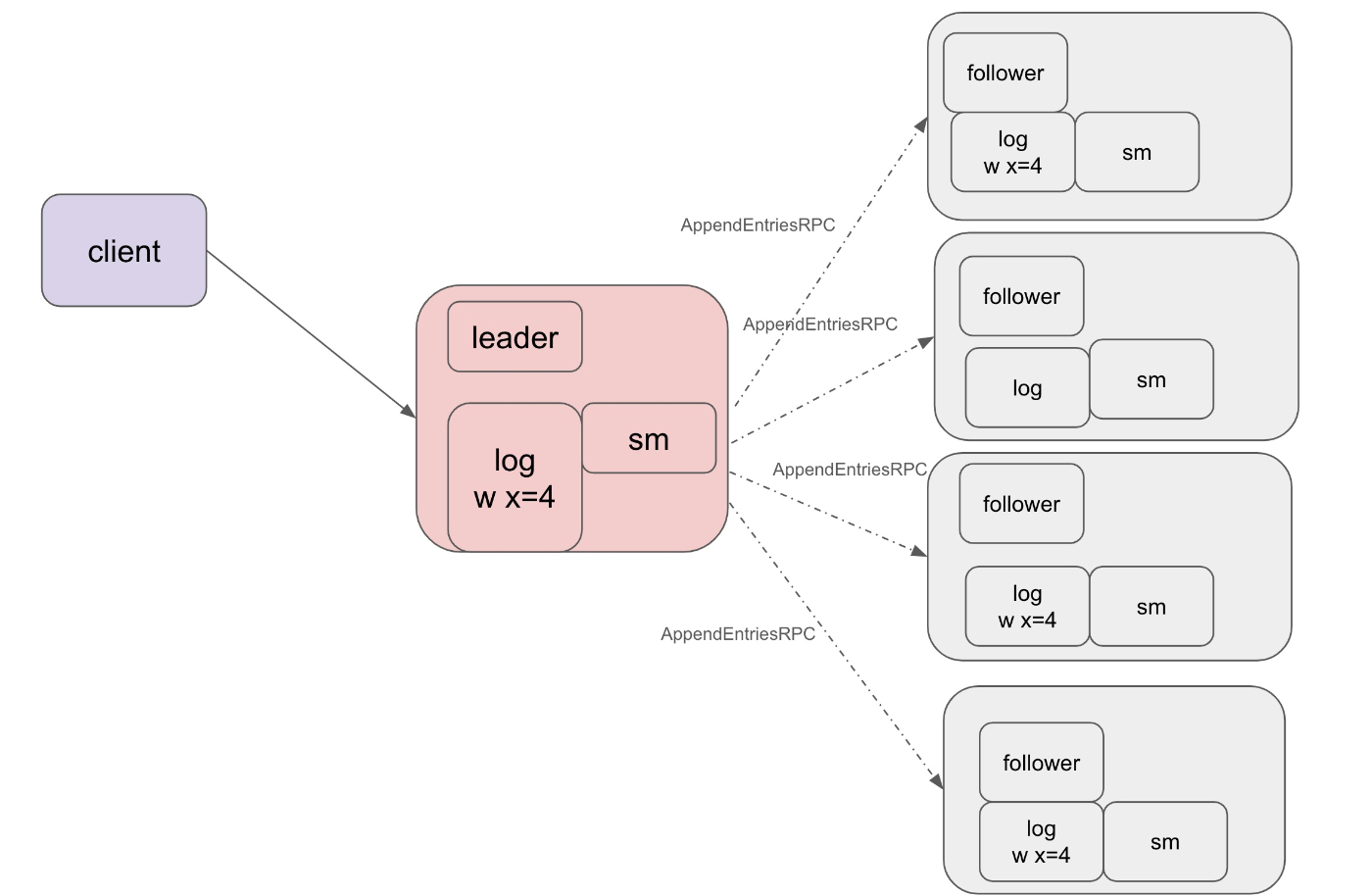
フォロワーのログを更新する
3. 過半数の ack を受け取ったリーダーは処理をコミットする
フォロワーはログを複製できたらリーダーに ack を返します
過半数のフォロワーから ack を受け取ったらリーダーは処理をコミットします
クライアントに処理結果を伝え、データベースを更新します

過半数のフォロワーが更新したため、処理が成功した
4. フォロワーもデータベースを更新
再びリーダーは AppendEntriesRPC を送信します
ここには SM=4 という情報も含まれており、フォロワー達もデータベースを更新します
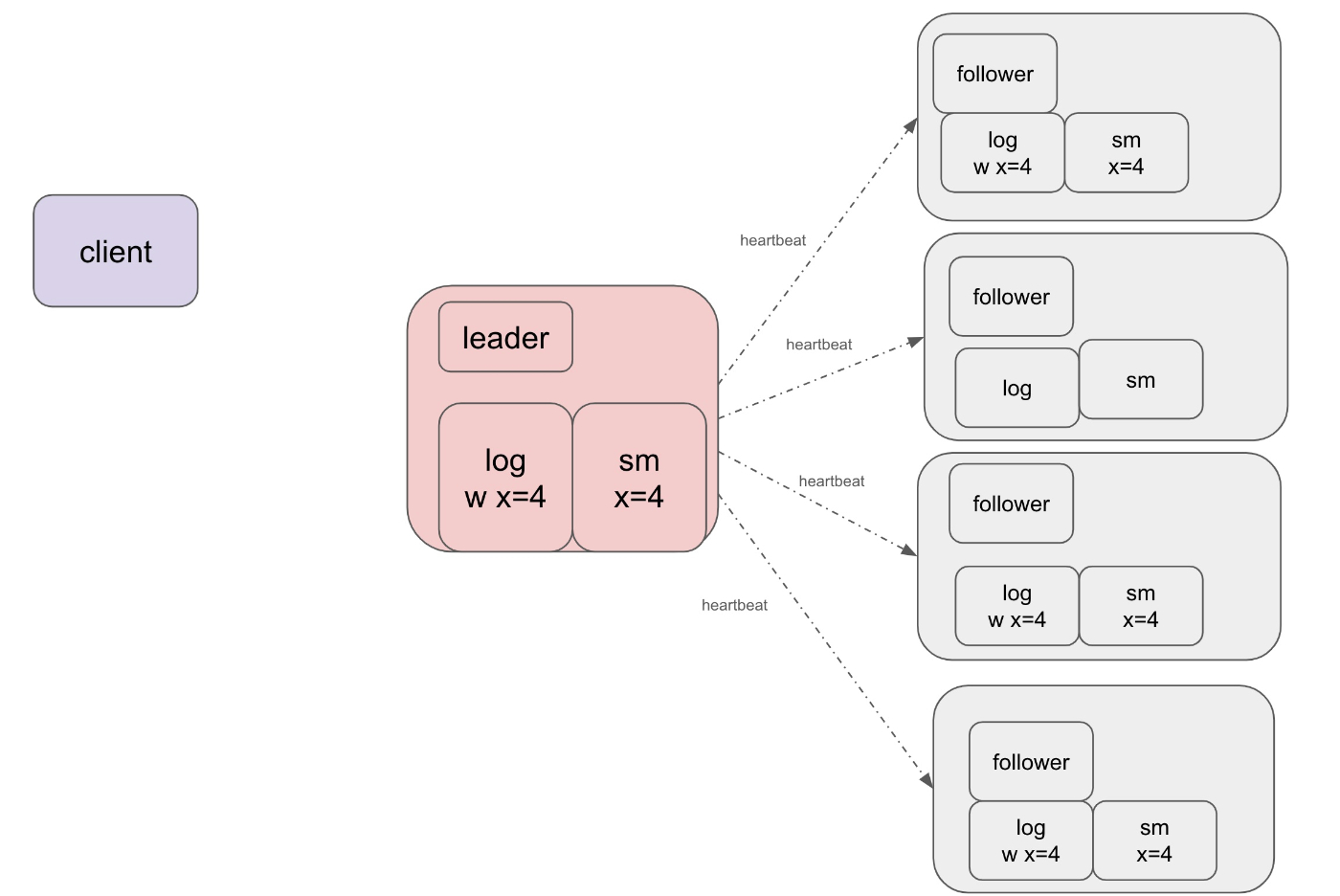
フォロワーのSMを更新する
正常に処理できない場合
正常に処理できない場合もあります
論文に記されていた悪化した場合のフォロワー達についてまとめます
なぜ悪化したか
どういった経緯で更新が止まっているかを説明します
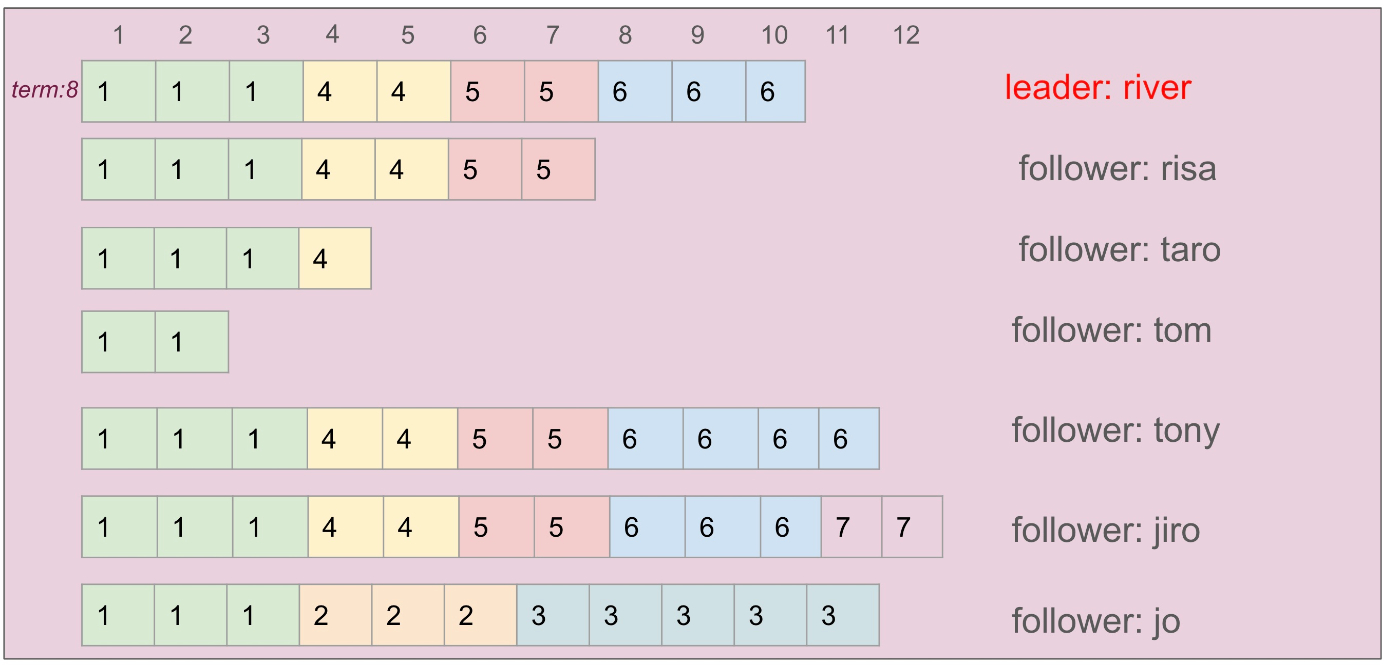
risa: term6 で死んだ
taro: term4 の途中で死んだ
tom: term1 の途中で死んだ
tony: term6 のリーダーだったけど、その後死んでそのまま
jiro: term7 のリーダーだったけど、その後死んでそのまま
jo: term2,3 のリーダーだったけど、フォロワーの誰も更新してくれないまま死んだ
どうやってフォロワーのログとリーダーのログを一致させるか
1. リーダーがRPCを送り、フォロワーが false を返す
リーダーが AppendEntriesRPC を送ります
ここにはnextIndex という、リーダーがそのフォロワーに送る次のログエントリのインデックスが含まれています
リーダーになった際に、リーダーは全てのnectIndex 値を自分のログの最後のエントリの直後に初期化します(ここでは10ですね)
インデックス10においての term 数が違うため、フォロワーは false を返します
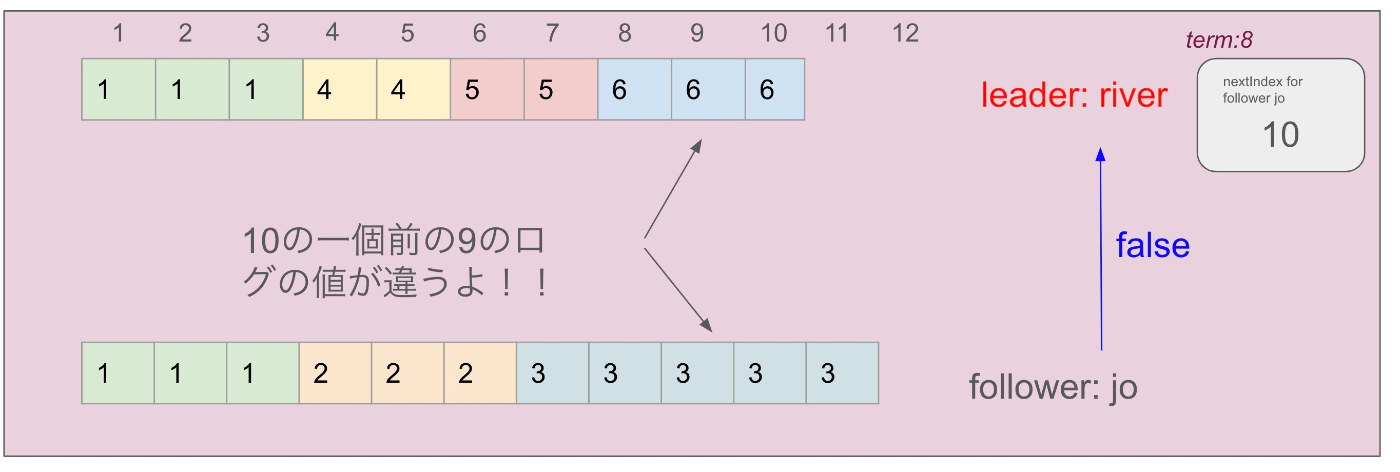
リーダーのログが更新される
2. nextIndex が一致するまでリーダーは RPC を送り続ける
今度はインデックスを9に下げてからその時のログを送りますが、リーダーは6なのに対してフォロワーは3であるためフォロワーは再度 false を返します
一致するまでインデックスを下げます
nextIndexが4の時、どちらも一致するためフォロワーはリーダーからの AppendEntriesRPC に対して true を返します
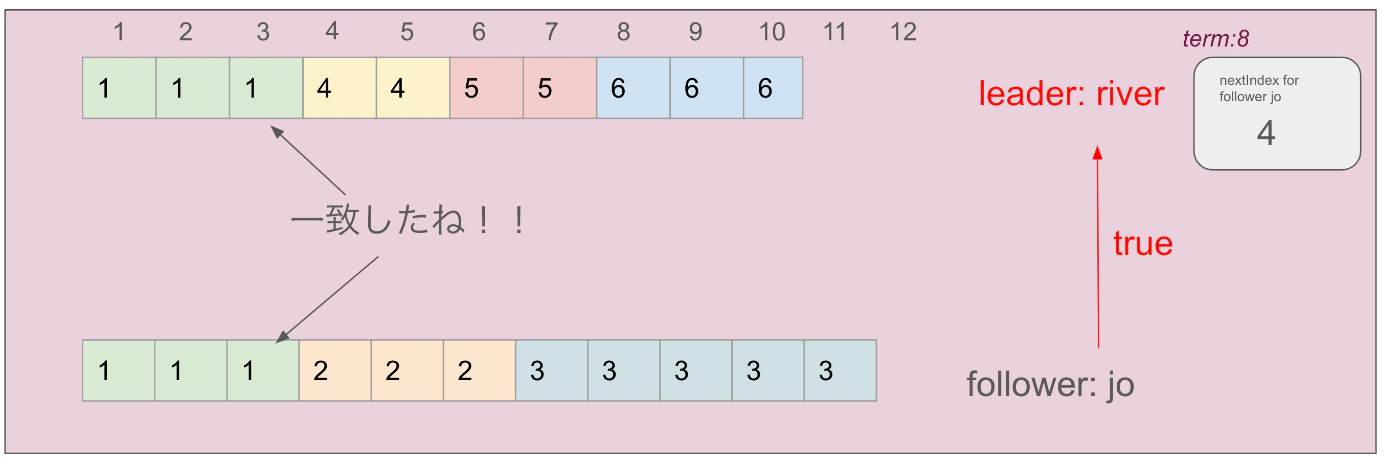
フォロワーが true を返す
3. フォロワーのログを削除
フォロワーはリーダーと一致しなかったインデックス値3以降のログを全て削除します
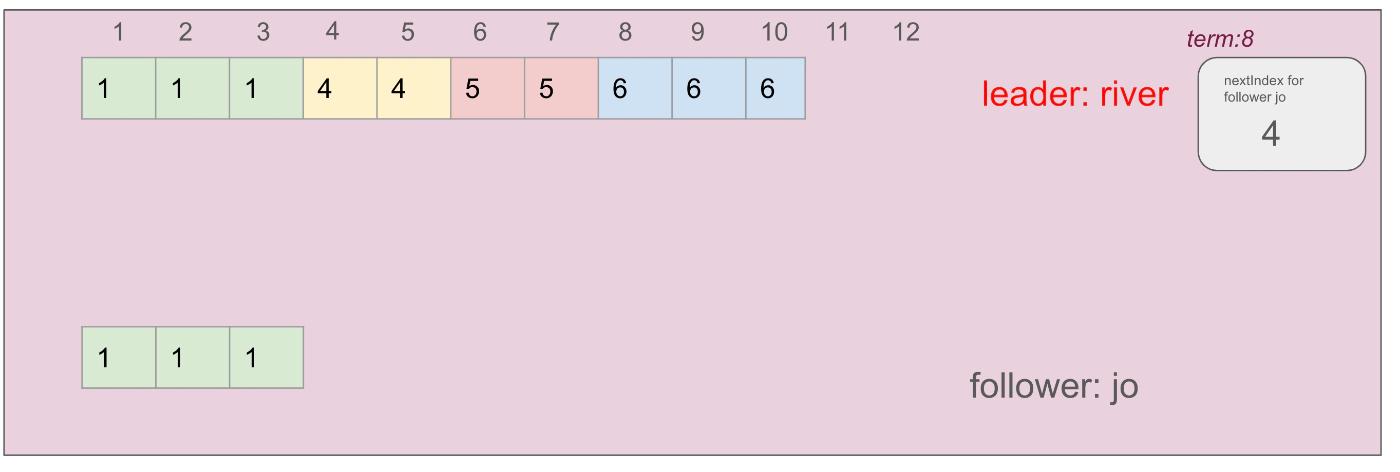
フォロワーのログは削除される
4. フォロワーのログを複製
リーダーのログをフォロワーに複製します
またnextIndex値も11に引き上げます
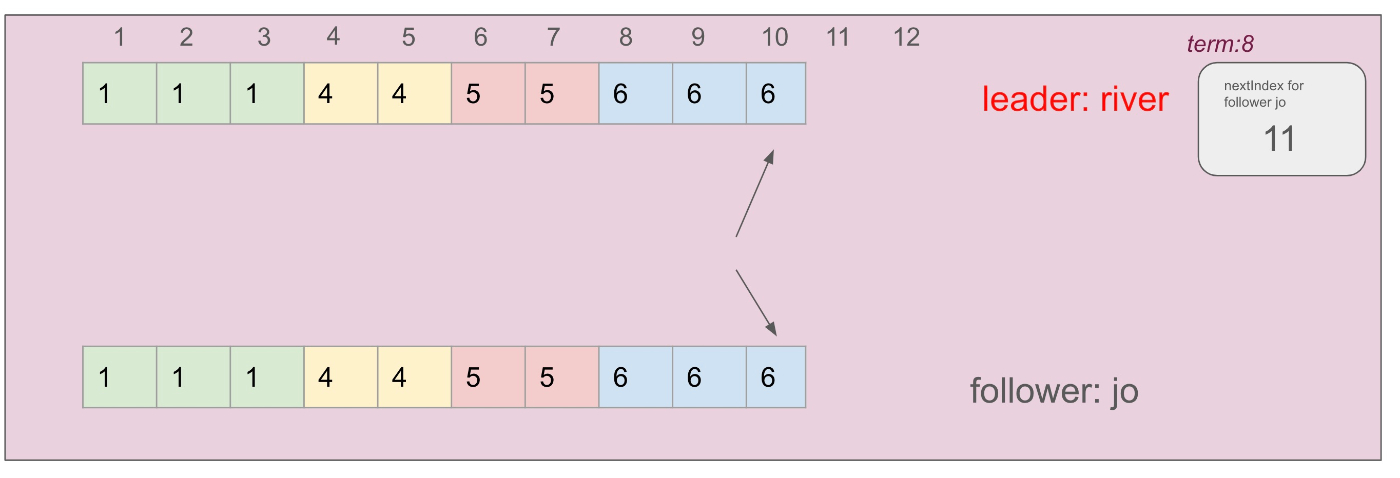
フォロワーのログが複製される
まとめ
・リーダーが選出されたら、クライアントからのリクエスト処理を始める
・クライアントからのリクエストが過半数のサーバのログに書き込まれたらコミットする
なお、実際には障害が起こる可能性は低く、最適化は不要と考えられている
一応 最適化の方法は考えられている
最後まで読んでくださりありがとうございます!
次は5.4 Safety です!
Discussion