🙌
[中級者向け!] Write Skew を図でわかりやすく解説!
はじめに
Silo において validation phase で他のトランザクションがロックを取った場合、アボートするのはなぜだろうと思った方向けの記事です。
この記事の対象者
・トランザクション中級者
目次
- 前提知識
- serializable なスケジュールの場合
- write skew が発生している場合
1. 前提知識
ここでは、ハードウェアがどのようにデータを更新しているかを解説します。
1. CPU がデータを要求し、メモリからキャッシュにデータをコピーする
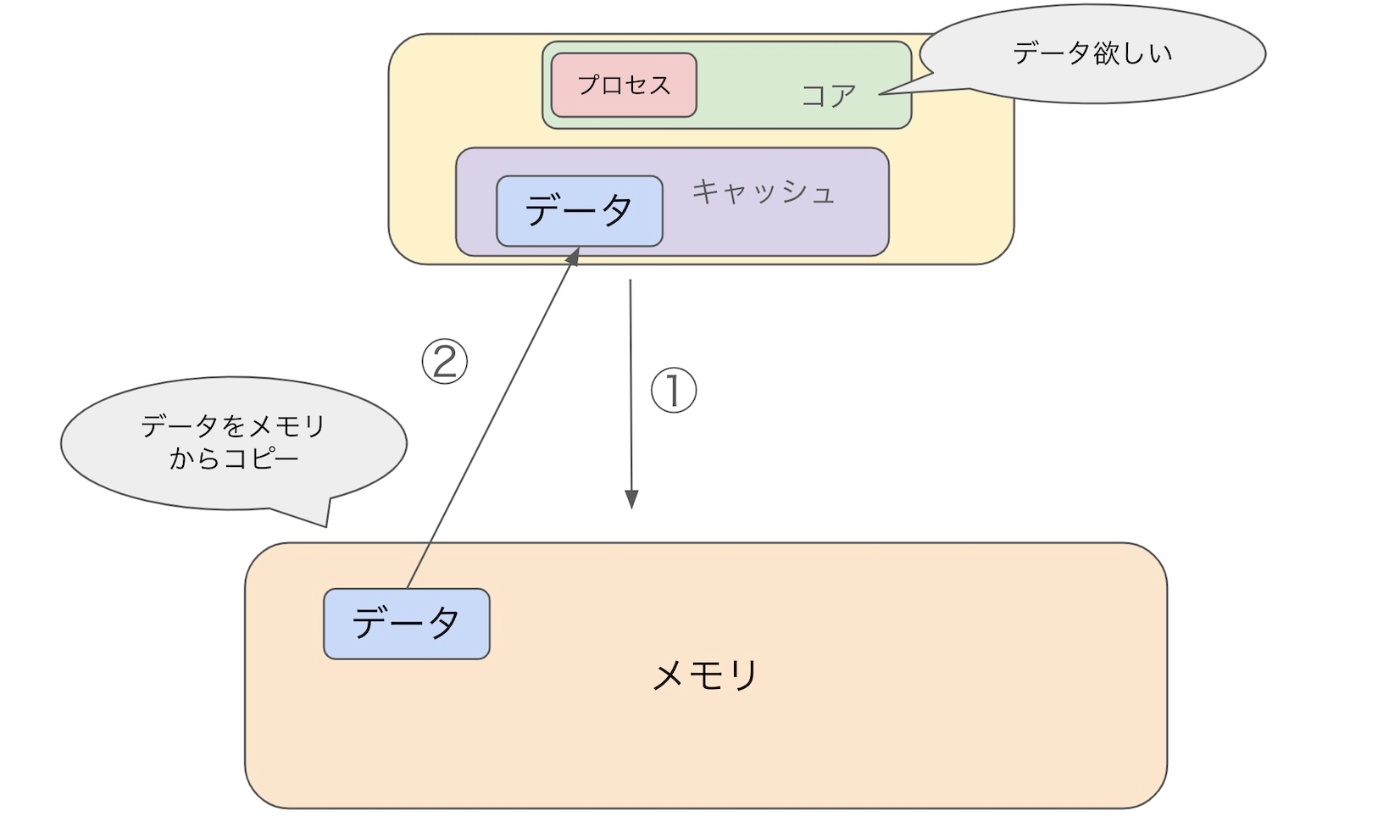
OS が I/O ( CPU とメモリ間のやり取り)の制御をします
2. CPU がデータを更新する
3. 更新後のデータがメモリに戻る

2. serial schedule の場合
ここでは以下の例を考えましょう。
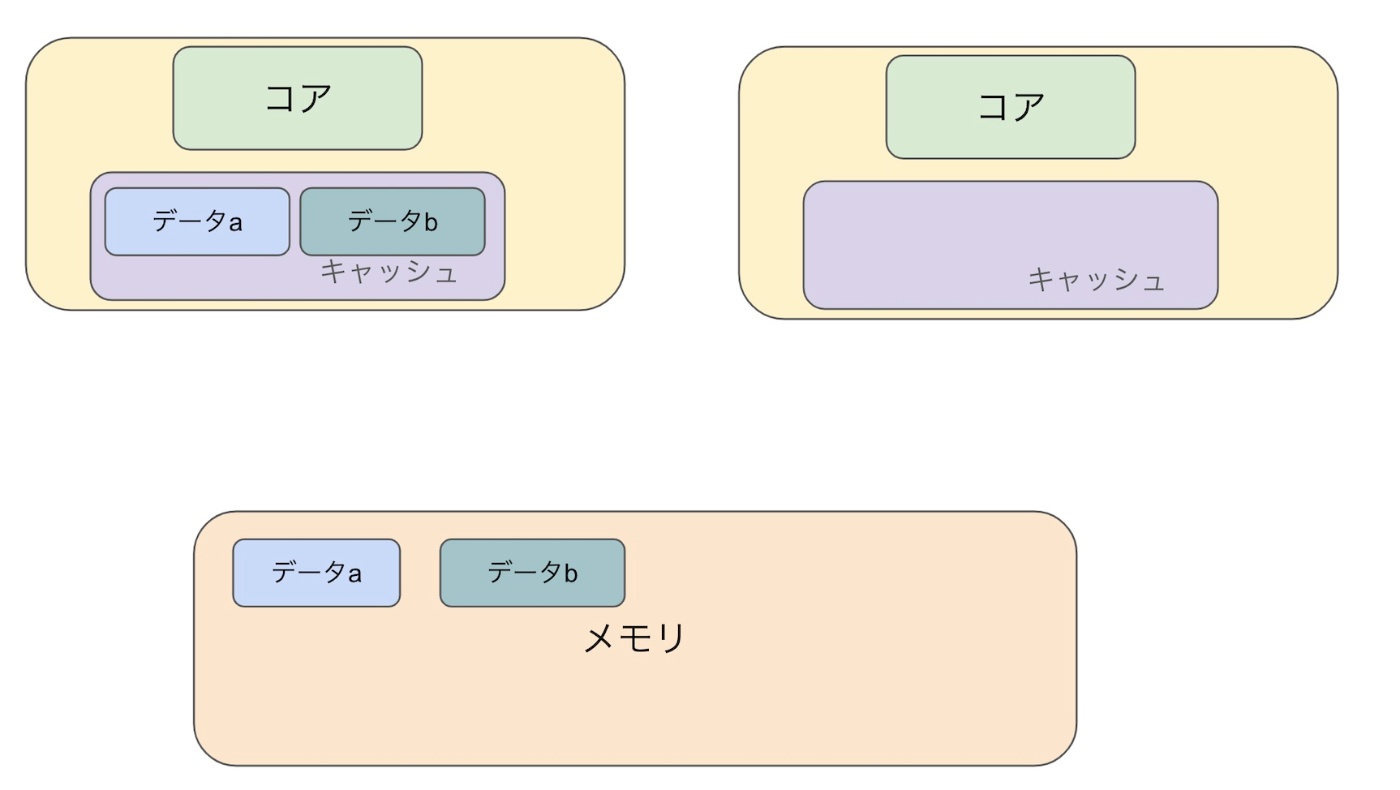
トランザクションは2つあり、一つはデータ b を a に代入し、もう一つはデータ a を b に代入します

1.データ a,b をメモリからコピーする
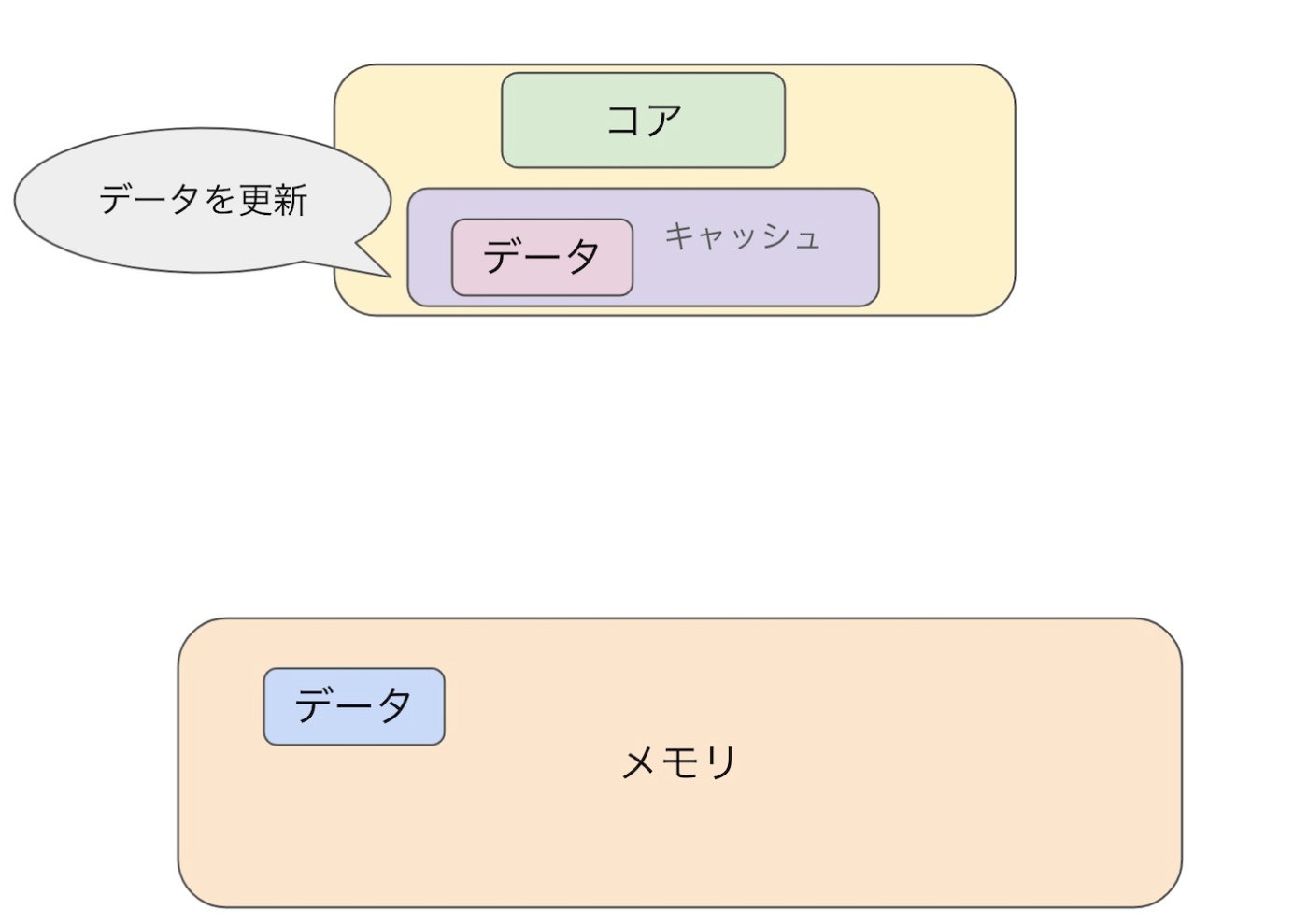
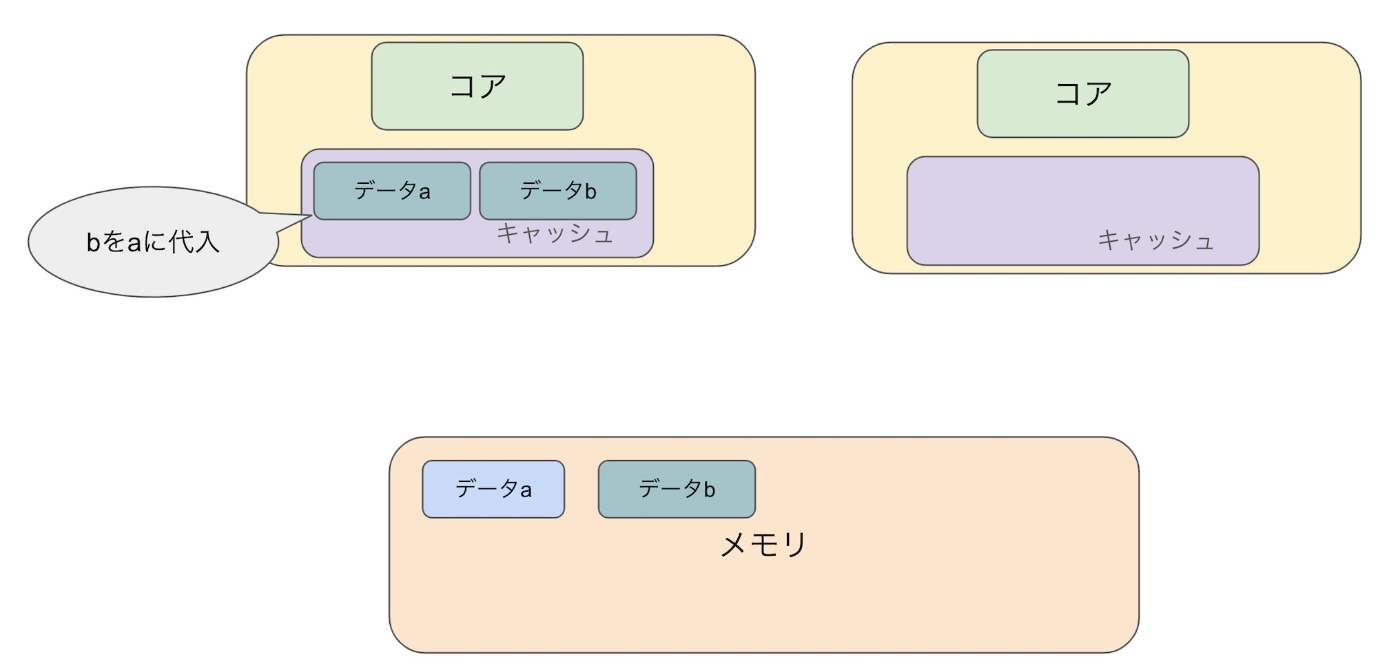
2. データbをaに代入する(値を更新する)
3.更新後のデータがメモリに戻る
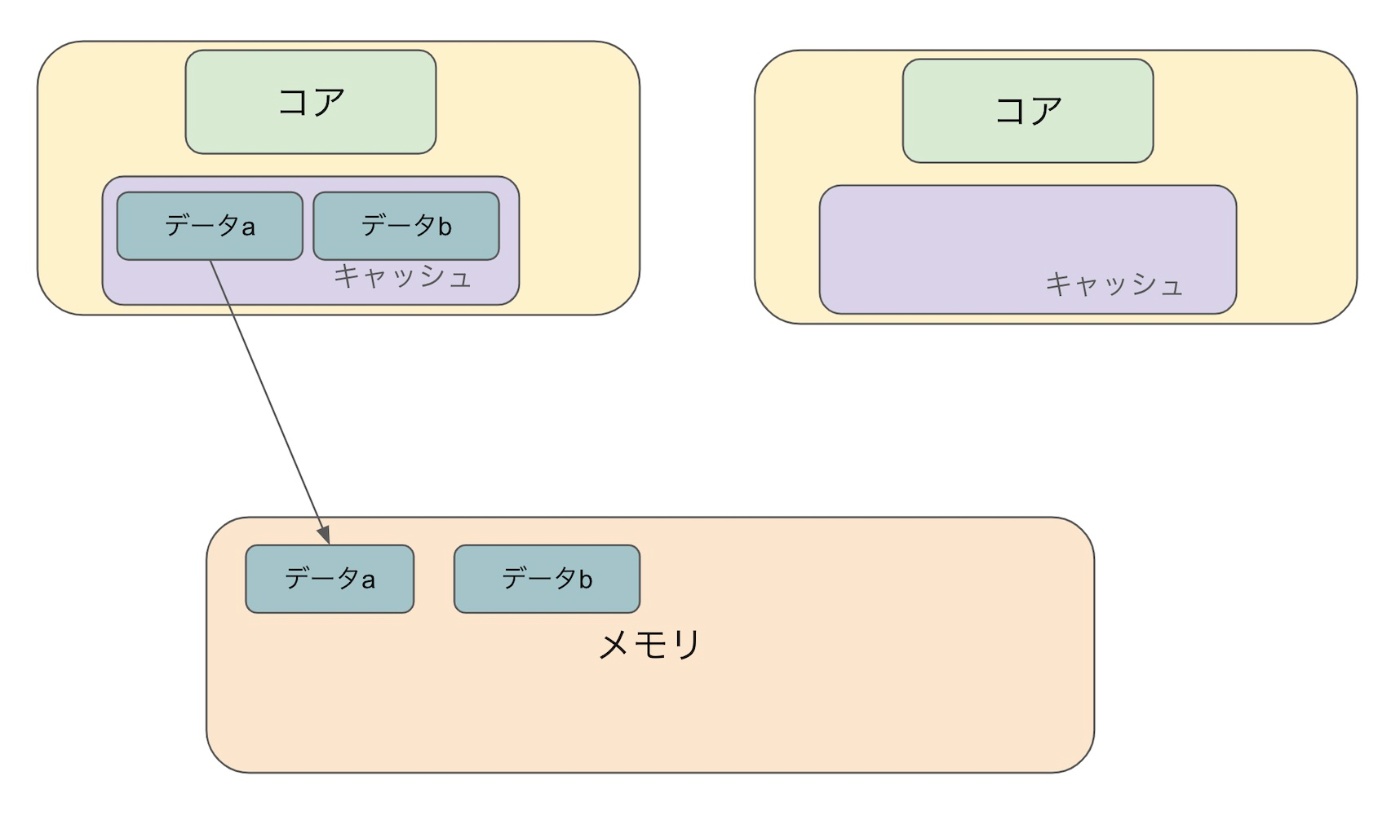
4.データa,bをメモリからコピーする(別の CPU )
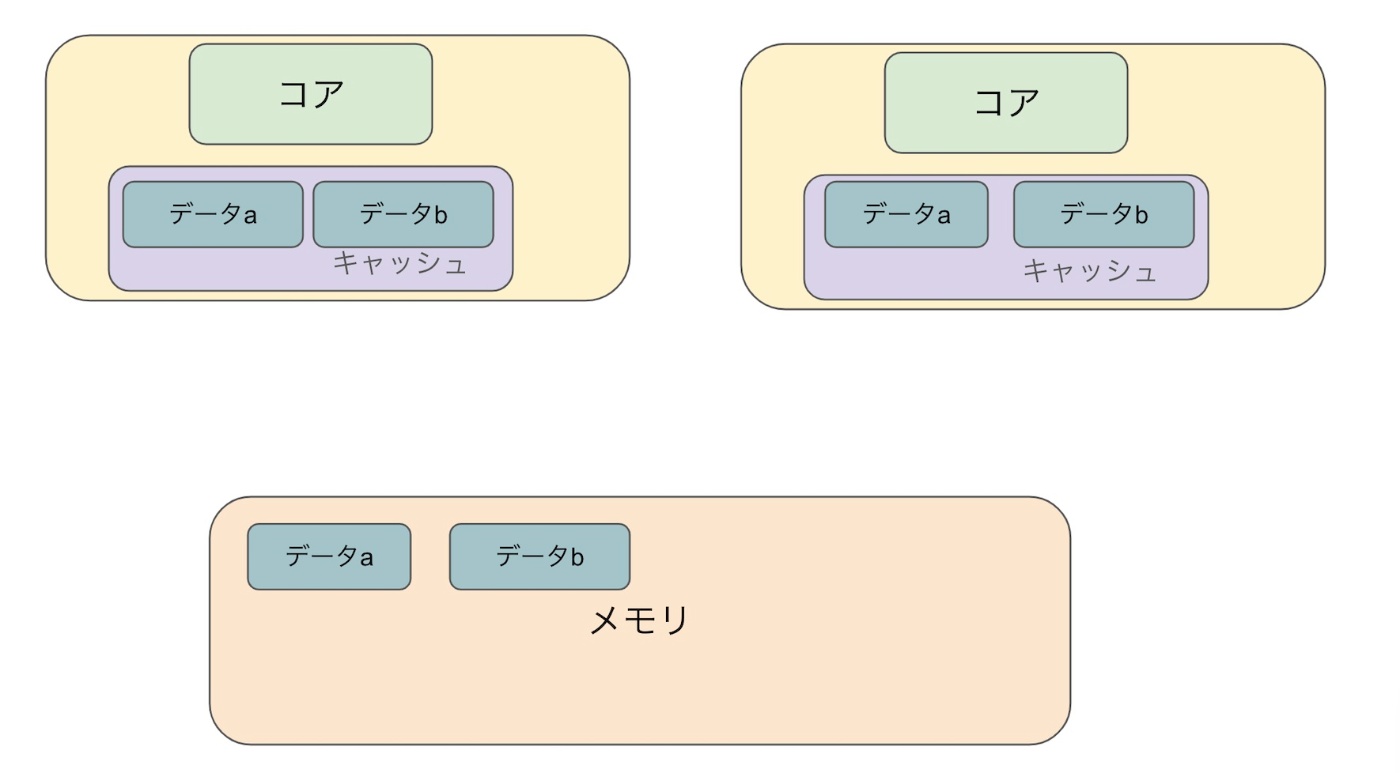
5.データaをbに代入する(値を更新する)

値はいずれにしても同じですね!
6.更新後のデータがメモリに戻る
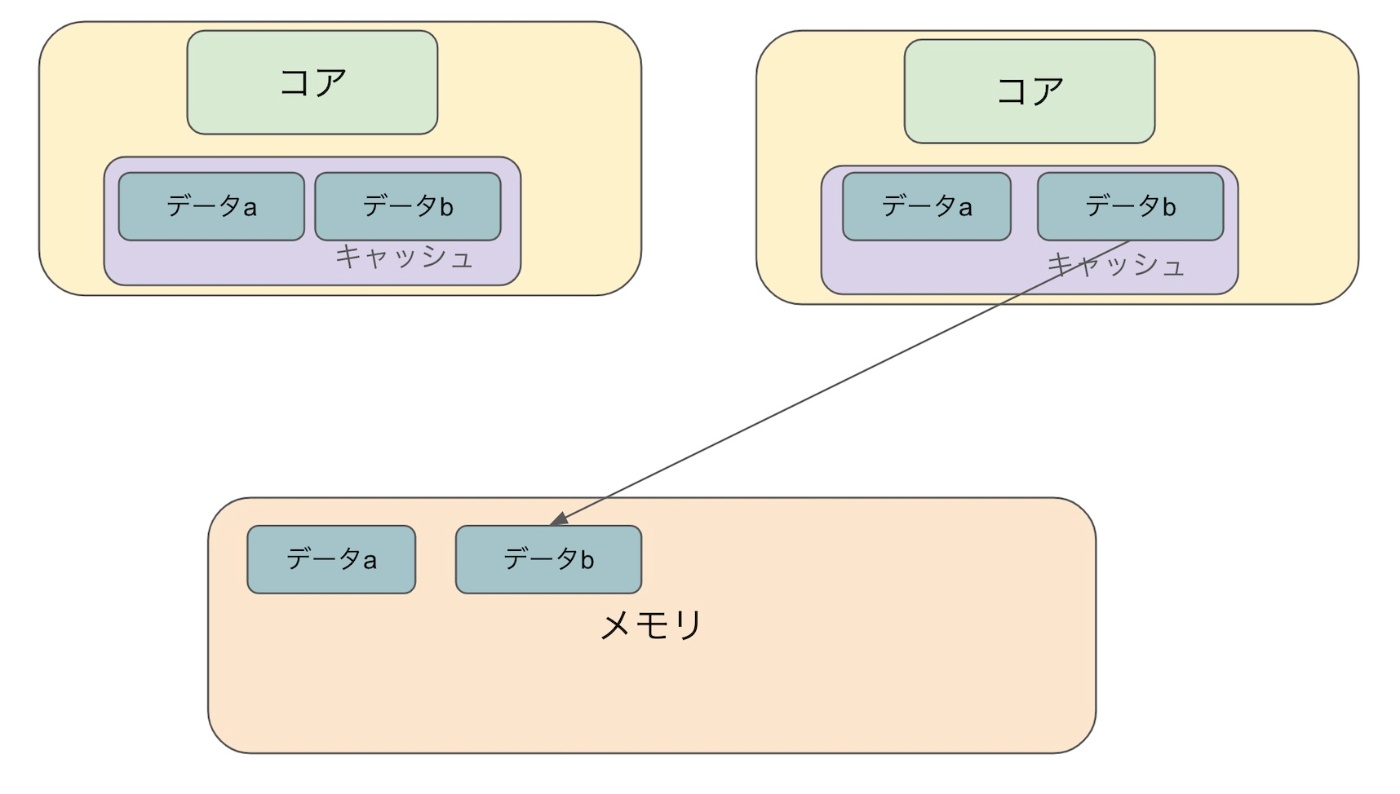
順序が逆になる場合もあります。(どちらも10になるか、20になる場合が存在します)
3. write skew が発生している場合
write skew が発生しているスケジュール例です

1.データa,bをメモリからコピーする
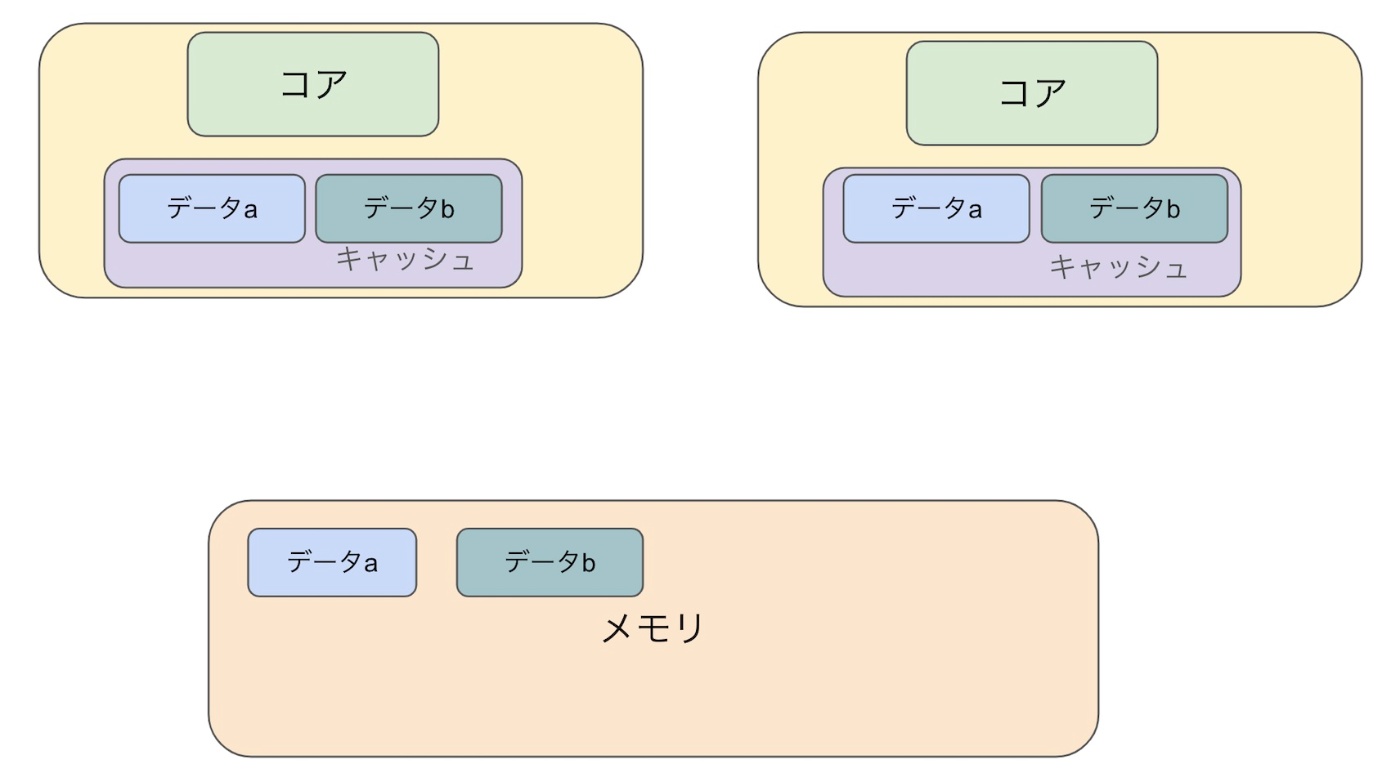
2. データbをaに代入する&データaをbに代入する(値を更新する)
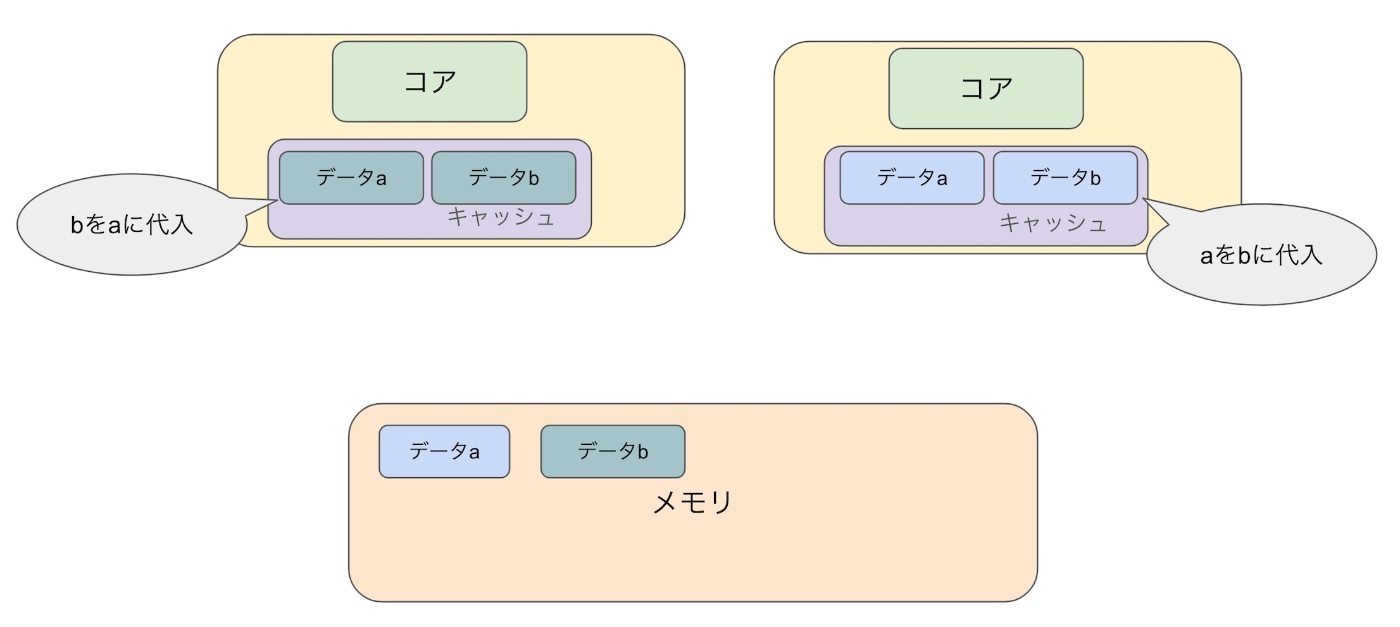
3.更新後のデータがメモリに戻る
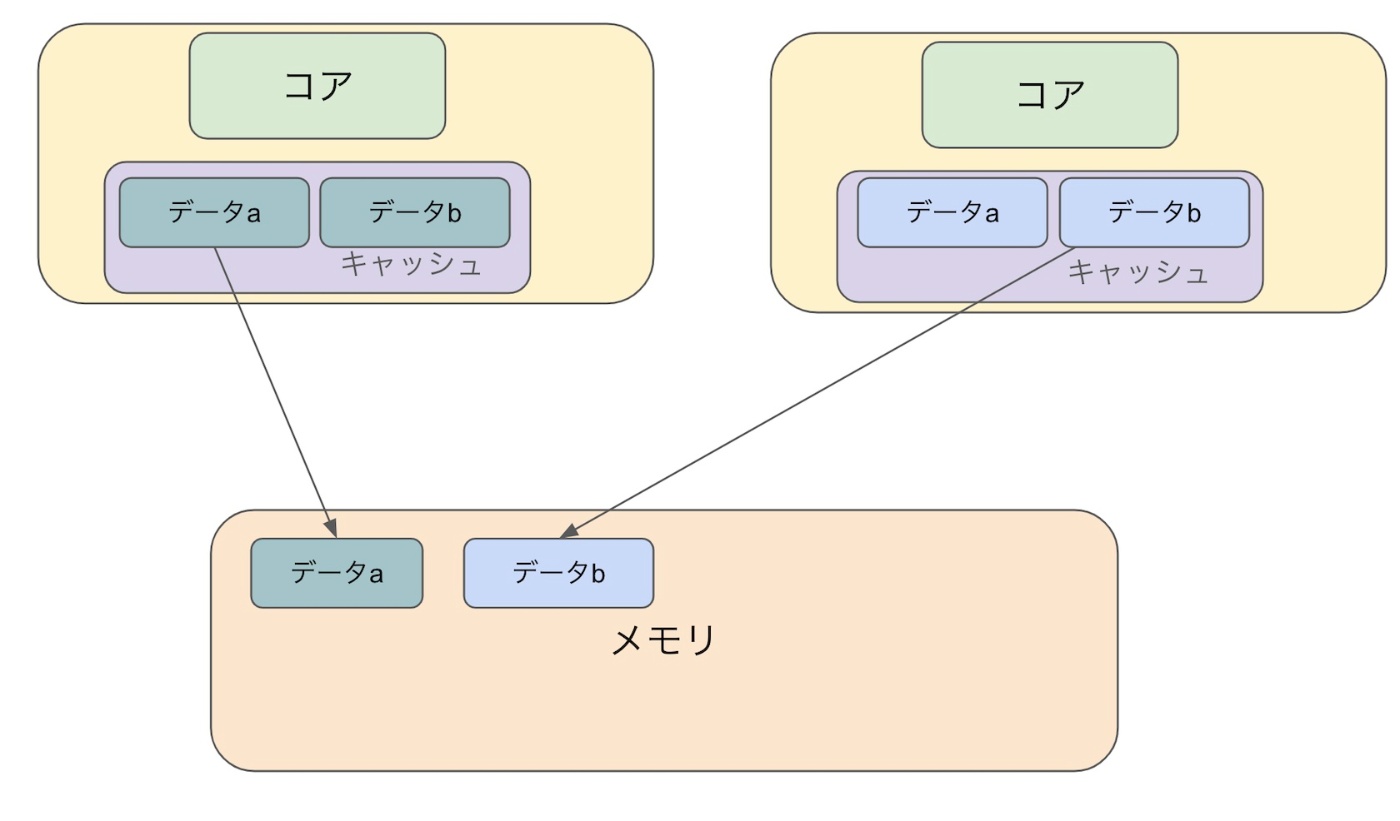
serial schedule の場合は、データaとbが同じ値になるのに対して write skew のアノマリーが発生してる時は違う値になってしまいましたね
そのため serializable にするためには、ロックを用いて更新できるコアを制限する必要があります
まとめ
・write skew はマルチコアにより複数の CPU が同時にデータを更新することで起こるアノマリーである
・write skew が起こらないようにするにはロックを用いて更新できる CPU を制限する必要がある
最後まで読んでくださりありがとうございました!
Discussion