0からつくるDeepな推薦システム~SASRec~
はじめに
Sequential Recommendationに初めてAttentionを導入したモデル、SASRecの実装をしました。
元論文はこちらです。
Self-Attentive Sequential Recommendation(ICDM'18)
本記事にで説明したコードは以下の実装がベースです。外部データのアップロード等は不要なので、とりあえずSASRecを動かしてみたいという方はぜひ触ってみてください!
Github:
Notebook:
Sequential Recommendationとは
Sequential Recommendationとは、あるユーザのクリック履歴や購入履歴が与えられた時に、ユーザが次にクリックしたり購入しそうなアイテムを予測する、というタスクです。
下の画像のように、青枠で囲まれたアイテムの系列情報が与えられた時に水筒を予測する、ということを行います。

引用:https://session-based-recommenders.fastforwardlabs.com/
しかし、ユーザの好みや興味は時間と共に変化するのがほとんどなので、アイテムの系列をうまく特徴に落とし込む必要があります。
以下の図では、前半にベビー用品を見ており、後半はベビー用品とは無関係なアイテムを見ているため、それに合わせて推薦を行う必要があります。

引用:https://session-based-recommenders.fastforwardlabs.com/
そして、このような問題設定は自然言語処理のタスクに落とし込むことができます。
(各アイテムを単語、アイテムの系列を文章として見てみると、入力文から次の単語を予測するNext Token Predictionにかなり似ている問題設定だということがわかると思います。)
そのため、NLPのモデルであるword2vec[1]やGRU[2]、BERT[3]をSequential Recommendationに導入した手法が提案されています。
本記事では初めてAttentionを導入した手法であるSASRecを解説します。
元論文の引用数は今現在2483で、推薦システムにTransformerを組み合わせた研究の草分け的な論文になってます。
SASRecの解説
SASRecのモデルはかなりシンプルで、大まかな処理の流れは以下の3つです。
- アイテム系列の埋め込み
- Self-Attentionによるアイテム系列の処理
- ユーザが次にクリックするアイテム予測
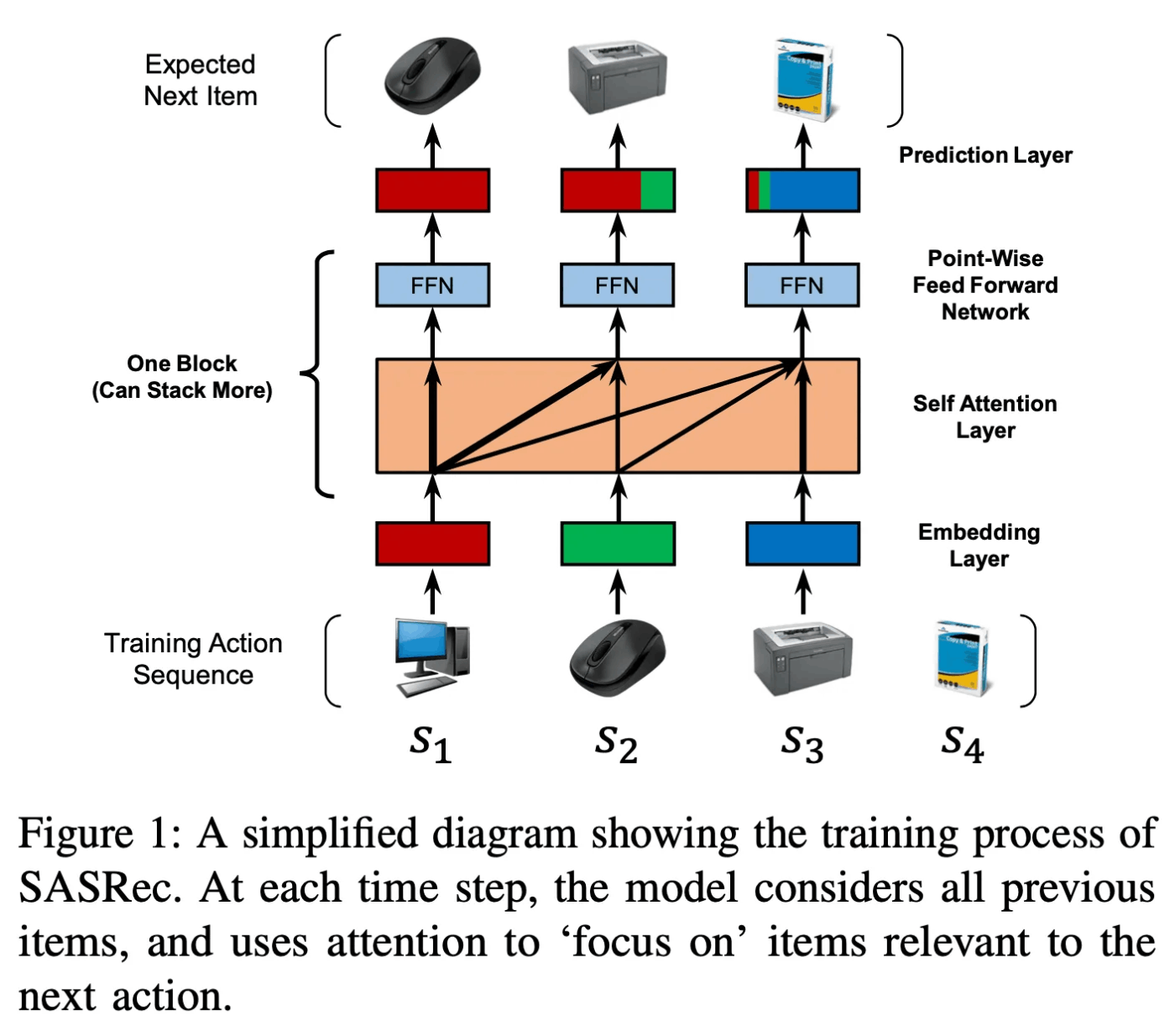
元論文より引用
アイテム系列の埋め込み
入力の系列は、
実際の系列の長さが
系列の各アイテムは、埋め込み行列
また、Transformerと同様に位置埋め込み
最終的に作られる埋め込みは以下のようになります。
Self-Attentionによるアイテム系列の処理
Self-Attention
Transformerと同様の方法でscaled dot-product attentionを以下のように計算します。
これにより、現在の位置よりも先の位置(
クエリ、キー、バリューの値は以下のように計算されます。
Point-Wise Feed-Forward Network
Transformerと同様に、アテンションで得た表現に対して、Point-Wise Feed-Forward Networkでの処理も行います。
実際の処理では、アテンションのブロックは繰り返されるため以下のような形になります。
ユーザのアイテム予測
Self-attentionによって、過去の系列からユーザ表現を獲得することができましたが、元々の目標は「過去形列から次のアイテム予測」をすることです。
SASRecでは、ユーザ表現とアイテムの埋め込み表現を使用することで、アイテムのスコアを算出します。
つまり、ユーザの表現とアイテム表現の類似度がそのままアイテムのスコアになります。
SASRecの実装
データセットの作成
元論文に習ってMovieLensという映画レビューのデータセットを使用してます。
MovileLensではユーザがレビューをした時間もタイムスタンプとして記録されています。
今回はタイムスタンプをもとに、データ並び替えてモデルに入力します。
import random
import torch
from torch.utils.data import Dataset
class MovielensDataset(Dataset):
def __init__(self, df, max_len, num_items, train_flag):
self.df = df
self.max_len = max_len
self.num_items = num_items
self.seq_data = []
self.train_flag = train_flag
self.item_set = set(range(1, num_items + 1))
for i in range(len(df)):
row = self.df.iloc[i]
movie_sequence = row.movie_list[:-1]
input_ids, labels = self.padding_sequence(movie_sequence)
self.seq_data.append(
{
"orig_movie_sequence": movie_sequence,
"input_ids": input_ids,
"labels": labels,
}
)
def __len__(self):
return len(self.seq_data)
def __getitem__(self, idx):
data = self.seq_data[idx]
orig_movie_sequence = data["orig_movie_sequence"]
input_ids = data["input_ids"]
labels = data["labels"]
negatives = self.negative_sampling(orig_movie_sequence, input_ids)
if self.train_flag:
return torch.tensor(input_ids), torch.tensor(labels), torch.tensor(negatives)
else:
last_item_id = labels[-1]
negative_set = self.item_set - set(orig_movie_sequence)
negative_indices = random.sample(list(negative_set), 100)
# 101 items in total (1 positive item, 100 negative items)
eval_item_ids = [last_item_id] + negative_indices
return torch.tensor(input_ids), torch.tensor(labels), torch.tensor(negatives), torch.tensor(eval_item_ids)
def padding_sequence(self, orig_movie_sequence):
sequence = orig_movie_sequence[-(self.max_len + 1) :]
inputs = sequence[:-1]
labels = sequence[1:]
seq_len = min(len(sequence) - 1, self.max_len)
inputs = (self.max_len - seq_len) * [0] + inputs
labels = (self.max_len - seq_len) * [0] + labels
return inputs, labels
def negative_sampling(self, orig_movie_sequence, input_ids):
negative_set = self.item_set - set(orig_movie_sequence)
sequence = orig_movie_sequence[-(self.max_len + 1) :]
seq_len = min(len(sequence) - 1, self.max_len)
negatives = (self.max_len - seq_len) * [0] + random.sample(list(negative_set), seq_len)
return negatives
-
__getitem__における処理について- 訓練時:入力のIDの系列(input_ids)、正例(labels)、負例(negatives)を返しています。負例も返すのは、SASRecに負例(ユーザが今後クリックしないアイテム)に対する予測値も出力させて学習を行うからです。
- 評価時:上記に加えて、評価用のデータ(eval_item_ids)を出力させています。元論文ではSASRecを評価する際に、「ある系列に対して1個の正例+100個の負例を用意して、スコアで並び替えた時に正例のスコアを上位に出せるか?」という方法をとっています。それに倣い、評価用のデータを追加で返しています。
- 入力の系列と正例の系列について
- SASRecの入力は、実際のユーザのクリックの系列です。そして、**その系列を一つ後ろにずらしたデータが正例になります。**一個ずらしたデータ(未来のクリック)をうまく予測できるか?という方法でSASRecを学習させていきます。
モデル
SASRecのモデルはかなりシンプルで、大まかな処理の流れは以下の3つです。
- アイテム系列の埋め込み
- Self-Attentionによるアイテム系列の処理
- ユーザが次にクリックするアイテム予測
(元論文より引用)
実装は以下の通りです。
import numpy as np
import torch
import torch.nn as nn
class SASRec(nn.Module):
def __init__(self, num_items, hidden_units, max_len, num_heads, num_layers, dropout_rate, device):
super().__init__()
self.max_len = max_len
self.num_items = num_items
self.hidden_units = hidden_units
self.num_heads = num_heads
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.device = device
self.item_emb = nn.Embedding(num_items + 1, hidden_units, padding_idx=0)
self.pos_emb = nn.Embedding(self.max_len, hidden_units)
self.input_dropout = nn.Dropout(self.dropout_rate)
self.norm = nn.LayerNorm([self.hidden_units])
encoder_layer = nn.TransformerEncoderLayer(
d_model=hidden_units,
nhead=1,
dim_feedforward=hidden_units,
dropout=dropout_rate,
batch_first=True,
norm_first=True,
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=self.num_layers, norm=self.norm)
def forward(self, input_ids, pos_ids, neg_ids):
input_ids = input_ids.to(self.device)
pos_ids = pos_ids.to(self.device)
neg_ids = neg_ids.to(self.device)
seq_len = input_ids.size(1)
position_ids = torch.arange(seq_len, dtype=torch.long, device=self.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
item_embeddings = self.item_emb(input_ids) * np.sqrt(self.hidden_units)
item_embeddings += self.pos_emb(position_ids)
item_embeddings = self.input_dropout(item_embeddings)
mask = self.create_causal_mask(seq_len, self.device)
output = self.encoder(item_embeddings, mask)
pos_embs = self.item_emb(torch.tensor(pos_ids, device=self.device))
neg_embs = self.item_emb(torch.tensor(neg_ids, device=self.device))
pos_logits = output * pos_embs
neg_logits = output * neg_embs
return pos_logits.sum(dim=-1), neg_logits.sum(dim=-1)
def predict(self, input_ids):
input_ids = input_ids.to(self.device)
seq_len = input_ids.size(1)
position_ids = torch.arange(seq_len, dtype=torch.long, device=self.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
item_embeddings = self.item_emb(input_ids) * np.sqrt(self.hidden_units)
item_embeddings = item_embeddings + self.pos_emb(position_ids)
mask = self.create_causal_mask(seq_len, self.device)
output = self.encoder(item_embeddings, mask)
return output
def create_causal_mask(self, seq_len, device):
causal_mask = torch.triu(torch.ones(seq_len, seq_len, device=device) * -1e9, diagonal=1)
return causal_mask
モジュールごとにポイントを解説します。
__init__()
def __init__(self, num_items, hidden_units, max_len, num_heads, num_layers, dropout_rate, device):
super().__init__()
self.max_len = max_len
self.num_items = num_items
self.hidden_units = hidden_units
self.num_heads = num_heads
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.device = device
self.item_emb = nn.Embedding(num_items + 1, hidden_units, padding_idx=0)
self.pos_emb = nn.Embedding(self.max_len, hidden_units)
self.input_dropout = nn.Dropout(self.dropout_rate)
self.norm = nn.LayerNorm([self.hidden_units])
encoder_layer = nn.TransformerEncoderLayer(
d_model=hidden_units,
nhead=1,
dim_feedforward=hidden_units,
dropout=dropout_rate,
batch_first=True,
norm_first=True,
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=self.num_layers, norm=self.norm)
ここではSASRecのためのパラメータやレイヤーを定義しています。
-
self.item_emb = nn.Embedding(num_items + 1, hidden_units, padding_idx=0):- アイテムのための埋め込み層を用意します。入力の数を
num_items+1としているのは、アイテムのIDに加えてpaddingも入力するためです。アイテムの系列の長さは常に一定とは限らないため、系列長を揃えるためにpaddingで埋める、という処理を行った後にSASRecに入力します。また、paddin_idx=0としている通り、入力の値が0の時はpaddingとして処理されます。
- アイテムのための埋め込み層を用意します。入力の数を
forward()
def forward(self, input_ids, pos_ids, neg_ids):
input_ids = input_ids.to(self.device)
pos_ids = pos_ids.to(self.device)
neg_ids = neg_ids.to(self.device)
seq_len = input_ids.size(1)
position_ids = torch.arange(seq_len, dtype=torch.long, device=self.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
item_embeddings = self.item_emb(input_ids) * np.sqrt(self.hidden_units)
item_embeddings += self.pos_emb(position_ids)
item_embeddings = self.input_dropout(item_embeddings)
mask = self.create_causal_mask(seq_len, self.device)
output = self.encoder(item_embeddings, mask)
pos_embs = self.item_emb(torch.tensor(pos_ids, device=self.device))
neg_embs = self.item_emb(torch.tensor(neg_ids, device=self.device))
pos_logits = output * pos_embs
neg_logits = output * neg_embs
return pos_logits.sum(dim=-1), neg_logits.sum(dim=-1)
ここでは、入力が与えられた時に、モデルがどう処理するかを定義しています。
-
pos_ids・neg_ids- SASRecの学習では、正例と負例のアイテムIDを同時に入力します。そして、正例は予測確率が高くなり、負例は予測確率が低くなるように学習していきます。
-
mask = self.create_causal_mask(seq_len, self.device)- Transformerではモデルが未来のの情報を見ないようにマスクをかける処理を行います。
SASRecでも同様に、ユーザが未来にクリックするアイテムを隠して処理するようにmaskを作成したうえでTransformerに入力します。
- Transformerではモデルが未来のの情報を見ないようにマスクをかける処理を行います。
pos_logits.sum(dim=-1), neg_logits.sum(dim=-1)- 上で説明したように、SASRecにおける学習では正例と負例のアイテムIDを同時に入力します。正例の予測だけではなく、負例の予測値が低くなるように学習を行うため、正例と負例の予測値をモデルに出力させます。
モデルの学習
for epoch in range(CFG.num_epochs):
running_loss = 0.0
for i, batch in enumerate(train_dataloader):
inputs, pos_ids, neg_ids = batch
pos_logits, neg_logits = model(inputs, pos_ids, neg_ids)
pos_labels, neg_labels = torch.ones(pos_logits.shape), torch.zeros(
neg_logits.shape
)
indices = np.where(pos_ids != 0)
pos_logits = pos_logits.to(CFG.device)
neg_logits = neg_logits.to(CFG.device)
pos_labels = pos_labels.to(CFG.device)
neg_labels = neg_labels.to(CFG.device)
optimizer.zero_grad()
loss = bce_loss(pos_logits[indices], pos_labels[indices])
loss += bce_loss(neg_logits[indices], neg_labels[indices])
for param in model.parameters():
loss += 0.00005 * torch.norm(param)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Train [{epoch+1} / {CFG.num_epochs}] Loss : {running_loss}")
ここではデータの取得、モデルの学習を行います。
-
model(inputs, pos_ids, neg_ids)- paddingを含めた系列と、正例・負例を入力します。
-
bce_loss()- 正例と負例をBinary Cross Entropyで学習させます。正例のラベルは1、負例のラベルは0です。
負例については、1エポックごとにユーザがインタラクションしなかったアイテムの中からランダムに取得しています。詳細な実装はdatasetのクラスをご確認ください。
このようなNegative Samplingを行うことでSASrecは単に正例を当てるだけでなく、ユーザが興味を持たない可能性が高いアイテムも識別できるようになります。
学習結果
今回はデータセットユーザのうち80%をtrain、20%をvalidに分割しました。
train/validの損失はこちらです。しっかり下がっていますね!

Discussion