初めまして、rinna株式会社でインターンをしている中田 亘です。
今回インターンの中でNeural Audio Codecベースの音声合成モデルについて調査を行ったので、その内容を紹介します。
音声合成では、数秒の音声を合成するだけでも非常に長い系列を合成する必要があります。例えば24kHz、10秒の音声を合成する場合、24万サンプル持つ系列の合成が必要です。
こういった長い系列を深層学習を用いて合成するのは難しいため一般的には学習前に圧縮を行います。その圧縮方法として広く使われてきたのがメルスペクトログラムです。メルスペクトログラムを使用することにより、音声信号を画像という扱いやすい情報として扱うことが可能です。
一方で近年ではNeural Audio Codec (NAC) を用いた表現方法が注目を集めており、音楽合成や音声合成において有効な表現と報告されています。
今回は、NACを用いた音声合成モデルとして有名なVALL-Eの調査および性能改善に関する検討を行ったのでその内容について紹介します。
既存のNeural Audio Codecベースの音声合成モデルの日本語への適用
まず、既存のNeural Audio Codec (NAC) ベース音声合成モデルの日本語での性能を確認しました。
音声合成モデルにはVALL-Eを使用し日本語での性能を調査しました。
VALL-Eとは
VALL-Eは2023年にMicrosoft社が発表した音声合成モデルです。
このモデルの新規性としては主に2つ挙げられます。
一つ目の利点は、音声の中間表現としてNACから得られる音声トークンを利用している点です。音声合成で一般的に使用される中間表現はメルスペクトログラムです。これは、音声に対してSTFT(短時間フーリエ変換)を行い周波数軸をメル尺度(mel scale)で表現することにより取得できます。
メルスペクトログラムが使われてきた理由としてはその解釈可能性の高さと再合成品質の高さが挙げられます。一方で人間により設計されたメルスペクトログラムは計算機にとって最適な表現かどうかは分かりません。
このことを踏まえてVALL-Eでは、NACから獲得できる音声トークンを利用しています。音声トークンは音声波形の再構成タスクを学習することで獲得されたます。学習過程で自動的に獲得された表現であるため、より計算機にとって都合の良い表現であることが期待されます。また、音声トークンは離散的な表現であり非常に低いビットレートで音声を表現できます。VALL-EではMetaが提案したNACであるEncodecが使用されています。
二つ目の利点は言語モデリングに基づく音声合成モデルの学習です。これは1点目の利点として挙げた離散音声トークンを利用することにより実現されています。言語モデリングとは、近年話題となっているChatGPTなどでも使用されている学習方法であり、今までの文脈をもとに、次はどんな単語(実際にはtokenだが、簡単化のため単語としています)が来るか予測しています。タスク自体はシンプルですがChatGPTでも示されている通り、データセット、モデルをスケールアウトすることにより高い性能を持つモデルが学習可能です。VALL-Eでは、テキスト生成において有効であると示されている言語モデリングを用いて音声合成の学習を行っています。
実際にはNACから得られる離散音声トークンは毎フレーム(VALL-Eの実験設定では1/75秒)ごとに、80bitにもなります。これをそのまま言語モデリングで学習することは、言語モデルの語彙数の観点から非常に困難です。代わりに80bitのうち最も重要である最初の10bitのみを言語モデリングで学習し、残りの70bitを分類問題として学習しています。そのため前者の言語モデリングで学習を行うARモデル。後者の分類問題として学習を行うNARモデルの2つのモデルからVALL-Eは構成されています。
推論時には、1. プロンプト音声(合成したい話者の3秒の音声クリップ)に対応するテキスト、2. 合成したいテキスト、3. プロンプト音声 の3つをモデルに与えて続きをARモデルを用いて予測することにより、合成したい音声の音声トークン列の最初の10bitを合成することができます。残りの70bitはNARモデルを用いてARモデルと同一の入力+ARモデルの出力結果から予測を行います。
結果では、VALL-Eの有効性が自然性、話者類似度の観点から示されています。詳しい結果に関しては論文をご参照ください。
学習条件
実験条件を下表に示します。
| データセット | LibriTTS-R (多話者英語オーディオブック音声) + rinna内製データ (日本語多話者コーパス) |
| NACモデル | Encodec サンプル周波数 24kHz 音声トークン周波数 75Hz ckpt |
| 使用した実装 | Github上で公開されている非公式実装 |
| 英語 書記素音素変換(G2P) | espeak-ng |
| 日本語 書記素音素変換(G2P) | OpenJTalk 入力にはPP symbolを使用 |
| AR/NAR モデル学習エポック数 | 20エポック |
| GPU | A100 x4 |
| Transformerモデル構造 | 層数12 ヘッド数16 隠れサイズ1024 |
学習結果
合成は、rinna内製コーパスに含まれる複数の音声スタイルをpromptとして入力しました。また、入力テキストは「ラーメン食べたい」としています。各話者およびpromptは学習データに含まれているものですが、入力テキストは学習データに含まれていません。
結果はrinna内製コーパスに含まれているスタイルごとにここからご確認ください.
合成結果から、VALL-Eは日本語においても高品質な音声合成が可能なことが分かりました。
また、多様なプロンプトの発話スタイル応じて合成音声の発話スタイルが適切に変化することが分かりました。
改善方法の検討
上記の通り日本語においてもVALL-Eを使うことで高品質な音声合成が可能であることが分かりました。
一方でいくつかの問題点も存在します。
まず、Encodecの公式モデルは75Hzで音響トークンを出力しますが、これにより合成時の計算量が大きくなってしまいます。
また、ARモデルとNARモデル両方を使用するため、ARモデルの推論が完了するまでNARモデルを駆動できず、特にテキストが長い場合には合成全体に時間がかかってしまいます。
これら問題に対処するため、以下の改善方法を検討しました。
なお、ここからの実験ではLibriTTS-Rのみを用いて実験しています。
音声に絞ったNACの学習
VALL-Eでは、Metaが公開しているEncodec重みを使用しています。
しかしながら、これは音一般(音楽、音声、など)を用いて学習された汎用的なモデルであり、そこから得られる表現は音声よりも広い空間を表現していると考えられます。
Encodecを音声のみを用いて再学習することでより少ないビットレートで高品質な再合成が可能になるのではないかと考え、音声のみを用いた再学習を行いました。
この検討では、EncodecのコードブックサイズやResidual Vector Quantization (RVQ) の数を変更した条件を用意し、それらのモデルからの再合成音声をSI-SNR, PESQの評価指標を用いて評価しました。
まず、音声で学習しているモデル(コードブック数32、コードブックサイズ1024)とMetaが公開しているモデルを比較した図を以下に示します。

この結果を見ると、音声のみで学習することにより、SI-SNR, PESQ両方の指標において、大きく品質を改善できることが確認できます。このことから、音声合成においては公式から配布されているモデルをそのまま使うのではなく、音声のみにドメインを絞ったデータセットで学習することが重要そうです。
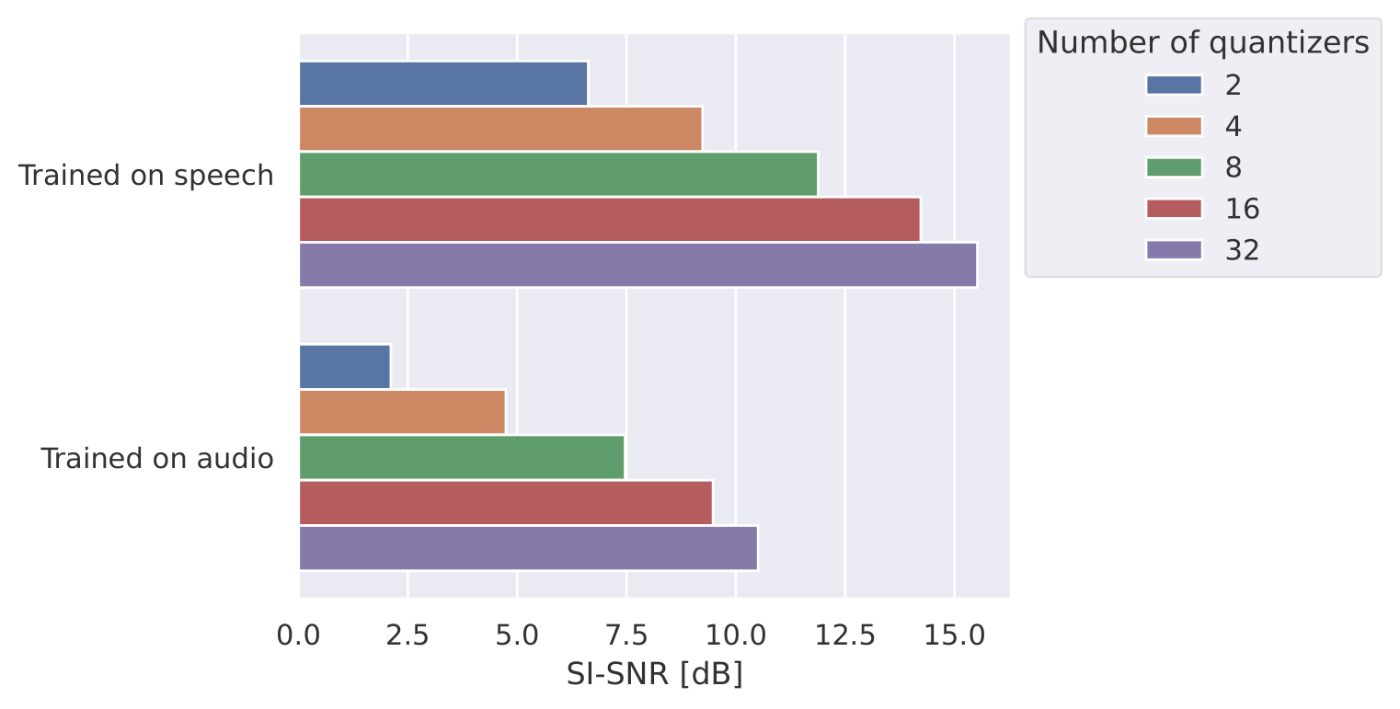
また、学習時に使用するQuantizerの数(total codebooks)による合成音声の品質変化に関する図を以下に示します。ここでは、Quantizerの数が2,32の条件において双方のモデルの最初のQuantizer2個を使い、再合成を行いました。


この結果から、NAC学習時のQuantizerの数2個の場合が若干品質が改善しているものの、その差はあまり大きくありません。使用するQuantizerの数が事前に決まっている場合にはNACを学習した方がよく、決まっていない場合には多めのQuantizerの数で学習を行ったほうが良いでしょう。
加えて、今回学習したモデルの全条件+ Metaが公開しているEncodec重みによる結果を下表に示します。なお、空欄は同上を示しています。
| Quantizerの数 | コードブックサイズ | 再合成に使用したQuantizerの数 | 音声トークン出力周波数 | SI-SNR | PESQ |
|---|---|---|---|---|---|
| 2 | 128 | 2 | 37.5 | 1.96 | 1.78 |
| 256 | 2 | 15.0 | -5.42 | 1.32 | |
| 37.5 | 2.94 | 1.94 | |||
| 75.0 | 6.18 | 2.44 | |||
| 3 | 32 | 2 | 37.5 | -0.35 | 1.48 |
| 32 | 256 | 2 | 75.0 | 5.54 | 2.26 |
| 4 | 75.0 | 8.25 | 3.02 | ||
| 8 | 75.0 | 10.79 | 3.62 | ||
| 16 | 75.0 | 12.92 | 3.98 | ||
| 32 | 75.0 | 14.08 | 4.13 | ||
| 1024 | 2 | 75.0 | 6.62 | 2.52 | |
| 4 | 75.0 | 9.24 | 3.22 | ||
| 8 | 75.0 | 11.88 | 3.76 | ||
| 16 | 75.0 | 14.22 | 4.09 | ||
| 32 | 75.0 | 15.52 | 4.21 | ||
| facebook encodec 24kHz | 1024 | 2 | 75.0 | 2.11 | 1.60 |
| 4 | 75.0 | 4.74 | 2.12 | ||
| 8 | 75.0 | 7.46 | 2.76 | ||
| 16 | 75.0 | 9.47 | 3.36 | ||
| 32 | 75.0 | 10.50 | 3.69 |
全体的な傾向としては、ビットレートと再合成品質の間にはトレードオフの関係が確認できます。
上の結果がNAC学習のハイパーパラメータ選択の一助となれば幸いです。
音声トークンの入力方法変更
上記の検討でより低いビットレートでも高品質な音声再合成が可能になることが分かりました。
この結果を踏まえ、NARモデルが不要となる新しい音声の表現方法を検討しました。
そもそもVALL-EでARモデルとNARモデルの双方が使われているのは、コードブックサイズ1024、Quantizer数8個の離散化結果
この考えをもとにコードブックサイズ256、Quantizer数2個の離散化結果をもちいて65536通りの音声トークンを予測するモデルを構築しました。
上記の変更の結果、NARモデルは不要となりARモデルのみで完結させられます。また、ARモデルの構造はGPTとほぼ同じなため、GPTでの学習の知見が非常に有用そうです。
GPT学習の知見を音声合成に適用することを目的として、様々な最適化が施されているGPT-neoxを用いた学習も検討しました。
比較した手法は以下の通りです。
- Ground Truth
LibriTTS-Rに含まれる原音声[^1] - VALL-E nq8 meta
Metaが公開しているEncodec重みを用いたVALL-E 8コードブックを使用 - VALL-E nq8
音声のみで学習したEncodec重みを用いたVALL-E 8コードブック使用 - VALL-E nq2
音声のみで学習したEncodec重みを用いたVALL-E 2コードブック使用 - VALL-E nq2 with neox
GPT-neoxを用いて学習したARモデルを使用したVALL-E nq2 - Proposed
Encodecの2コードブックを提案する手法で表現したVALL-E
GPT-neoxを用いて学習 - Proposed with data augmentation
↑の条件においてデータ拡張を行ったもの。データ拡張では同一話者の異なる発話音声及び発話テキストを連結した。
また、評価指標には合成の成功率、ASR(音声認識)結果の単語誤り率 (WER) 及びUTMOSを使用しました。
合成の成功率は、失敗を1フレームも出力されないもしくは20秒以上合成しても終了されない場合を失敗とし、成功をその補集合として定義し、計算しました。
ASRモデルにはOpenAI社Whisperのlarge-v2モデルを使用しました。テストセットにはLibriTTS-Rのtest-cleanセットを使用しています。
結果を以下に示します。



まず、VALL-E nq8 metaとVALL-E nq8を比較してみます。VALL-E nq8では合成品質が劣化していることが分かります。(UTMOS値が下がり、WERが上がっている)これは音声に絞ったNACの学習での結果と反している結果です。考えられる原因としては、VALL-E nq8ではより多くのコードブックに音声に関する情報が分布している一方で、VALL-E nq2ではコードブックの最初の方に音声に関する情報が集中していると予想できます。一方で学習に使っている損失関数では、その情報の偏りを考慮していないため、学習が困難になり品質を劣化していると考えています。実際にVALL-E nq2とVALL-E nq8を比較するとVALL-E nq2ではすくないコードブック数にもかかわらず合成音声の品質が大きく改善しています。このことから、VALL-Eの学習に使用するコードブック数は使用するNACモデルに大きく依存しており、適切なコードブック数の選択が肝要であると言えます。
次に VALL-E nq2とVALL-E nq2 with neoxを比較すると、VALL-E nq2 with neoxで合成音声の品質が改善していることが確認できます。VALL-E nq2 with neoxではGPT-neoxを用いて学習を行っており、GPT-neoxで行われている様々な最適化によって合成音声の品質が改善していると考えられます。
一方で、合成の成功率は大きく低下していることが確認できます。これは、様々な理由が考えられますが、位置エンコーディング手法の違いなどにより発生しているのではないかと考えています。
また、VALL-E nq2 with neoxと Proposedを比較すると、
UTMOSではVALL-E nq2 with neoxとほぼ同等の値を出せているものの、合成の成功率が低下してしまっています。
Proposedでは2個のコードブックを結合して学習をしているのですが、これによりTransformerの語彙数が256倍になり学習が難しくなっているからと考えています。
最後にProposedとProposed w/ data augmentationではProposed w/ data augmentationが大きく改善しており、最も原音声と近い評価結果となっています。このことからデータ拡張は有効であると言えます。
[^1] : これは自然音声ではなく、LibriTTSに対してMiipherを適用し、ノイズ除去を行った音声である。
まとめ
今回はNACベースの音声合成について調査しました。まず、NACベースの音声合成手法VALL-Eを日本語へ適用し、高い品質で合成が可能であることが確認できました。また様々なプロンプトを入力することで多様な出力が得られることが確認できました。
次に、VALL-Eを改善する手法として1. Encodecの学習を音声ドメインで実施 2. より効率の良い音声トークン圧縮手法の検討を行いました。結果から、1. では、より小さいビットレートでより原音声に近い音声再合成可能となることが確認できました。
また2. ではより原音声に近い音声合成が可能となった一方で、合成の成功率は低下し合成が不安定になってしまいました。今後の課題としては、合成を安定させる方法の検討が挙げられます。

Discussion