はじめに
言語モデルを用いたテキストの生成にはtransformersライブラリが広く使われていますが、transformersライブラリは幅広いモデルに対応する一方で、テキスト生成の速度やメモリ効率には十分に最適化されていません。そこでこの記事ではテキスト生成の効率を上げるためのツールを紹介します。
今回はPyPIから簡単にインストールできるDeepSpeedとvLLM、CTranslate2を比較します。
モデルはrinna/japanese-gpt-neox-3.6b-instruction-ppoを使います。プロンプトのフォーマットやトークナイザ等の使い方についてはモデルカードをご覧ください。
この記事ではColabのT4 GPUタイプを利用してテキスト生成の速度を測定しています。それぞれのツールを試すノートブックと、Colabで開けるリンクを載せているので参考にしてみてください。
基本的な使い方
transformers
まずはtransformersでの通常の生成速度を確かめます。
モデルは torch.half (float16) で読み込みます。
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
torch_dtype=torch.half,
device_map="auto",
)
同条件で速度を測るために max_new_tokens と min_new_tokens の両方を128に設定して出力するトークン数を固定します。
ノートブックではこれを10回繰り返して処理時間を計測しています。
outputs = model.generate(
**inputs,
max_new_tokens=128,
min_new_tokens=128,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
)
![]()
11.5秒程度で生成されました。

消費したGPUメモリは8.3GBでした。
DeepSpeed
ここではDeepSpeed-Inferenceの機能を利用します。
transformersで読み込んだモデルをdeepspeed.init_inferenceに渡してDeepSpeedのInferenceEngineを初期化します。
engine = deepspeed.init_inference(
model,
dtype=torch.half,
replace_with_kernel_inject=True,
max_out_tokens=2048,
)
生成にはtransformersのgenerateメソッドをそのまま使用できます。
![]()
5.2秒程度で生成されました。transformersの二倍以上のスピードで生成できています。
消費したGPUメモリは10.4GBでした。transformersよりも2GBほど増えています。
vLLM
APIサーバのスループットが高いことがアピールされていますが、ここでは他との比較のために Offline Batched Inference[1]を使い単発のテキスト生成にかかる時間を測ります。
モデルはfloat16で読み込みます。
llm = LLM(
model=model_name,
dtype="float16",
)
SamplingParamsを設定してテキスト生成のパラメータを設定できるのですが、現時点では min_new_tokens 相当の機能が実装されていなかったため、ignore_eos を有効にして出力するトークン数をmax_tokensの128に固定します。eosトークン (</s>) の後は関連のないテキストが生成されるため通常に利用するときは ignore_eos は無効にしましょう。
sampling_params = SamplingParams(
ignore_eos=True,
max_tokens=128,
)
vllm.LLMのgenerateメソッドにprompt_token_idsとしてトークンIDのリストと、SamplingParamsを渡すと生成が始まります。
inputs = tokenizer(
["ユーザー: 機械学習とは何ですか?<NL>システム:"],
add_special_tokens=False,
)
output = llm.generate(
prompt_token_ids=inputs.input_ids,
sampling_params=sampling_params,
use_tqdm=False,
)
![]()
4.5秒程度で生成されました。DeepSpeedよりも若干速い結果となりました。

消費したGPUメモリは13.8GBでした。ただしvLLMはPagedAttention[2]という仕組みを利用して生成の中間結果をキャッシュしているのでその分が含まれていると思われます。実際にはより少ないメモリのGPUでも動く可能性があります。
CTranslate2
ここでは ct2-transformers-converterコマンドでモデルを変換します。Colabで動かすためにノートブックでは変換スクリプトを一部修正していますが、メモリが十分にある環境では修正不要です。
テキスト生成に利用するデータ型は compute_type 引数で指定できますが、float16 では正常に生成されなかったため、今回は int8_float16[3] を指定しました。
generator = ctranslate2.Generator(
"/content/ct2-model",
device="cuda",
compute_type="int8_float16",
)
生成にはctranslate2.Generatorのgenerate_batchメソッドを使用します。こちらでも min_length と max_length の両方を128に設定して出力するトークン数を固定します。
outputs = generator.generate_batch(
[tokens],
max_length=128,
min_length=128,
sampling_topk=0,
include_prompt_in_result=False,
)
![]()
3.3秒程度のスピードで生成されました。int8に量子化しているため回答の品質が気になりますが、ぱっと見ではtransformersの回答結果と遜色ありませんでした。

消費したGPUメモリは3.8GBでした。int8に量子化しているためfloat16のtransformersの半分程度です。
バッチ生成を試す
transformersを始め多くのツールでは、複数のプロンプトを同時に渡して一度にまとめてテキスト生成するバッチ生成に対応しています。特にGPUを使っている場合には1つのプロンプトから生成する場合とあまり変わらない処理時間で複数候補が得られるので便利です。
たとえば同じプロンプトで複数の回答を生成したい場合に有用ですし、また既にある多数のプロンプトから生成したい場合はメモリに収まる範囲でバッチ化すると合計の処理時間を短縮できます。
transformers & DeepSpeed
今回は同じプロンプトを4つ渡してみます。transformersとDeepSpeedではトークナイザにプロンプトのリストを渡してpaddingを有効にすると適切にトークン長が調整されます。generateメソッドの呼び出しは特に変更する必要はありません。
tokenizer.padding_side = "left"
inputs = tokenizer(
[
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
],
padding=True,
return_tensors="pt",
add_special_tokens=False,
).to(model.device)
generateメソッドの戻り値はトークンIDのリストのリストになっています。tokenizer.batch_decodeでまとめてデコードできます。
vLLM
vLLMではトークンIDのリストを渡しますがトークン長を揃える必要はありません。
generateメソッドにはさきほどと同様にinputs.input_idsをそのまま渡せます。
inputs = tokenizer(
[
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
],
add_special_tokens=False,
)
generateメソッドの戻り値はRequestOutputのリストになっています。RequestOutputにはデコード済みのテキストなどが含まれています。
CTranslate2
vLLMとほぼ同様ですがCTranslate2ではトークンIDではなくトークン文字のリストを渡す必要があるのでtokenizer.convert_ids_to_tokensを用いて変換します。
inputs = tokenizer(
[
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
"ユーザー: 機械学習とは何ですか?<NL>システム:",
],
add_special_tokens=False,
)
batch_tokens = [tokenizer.convert_ids_to_tokens(ids) for ids in inputs.input_ids]
generate_batchメソッドを呼び出す際には[tokens]の代わりにbatch_tokensを渡します。戻り値はGenerationResultのリストになっています。GenerationResultには生成されたトークンやトークンIDのリストが含まれています。
まとめ
T4 GPU上でDeepSpeedとvLLM、CTranslate2をrinna 3.6bモデルに適用してテキスト生成の速度を比較しました。最後にこれまでの結果をまとめた図を載せます。左のプロットがバッチ生成なし(1つのプロンプトのみ)、右のプロットがバッチ生成(4つのプロンプト)での処理時間です。またこれまでの例では15トークンの短いプロンプトを使っていましたが、比較のために525トークンの長いプロンプトでの結果もプロットしています。
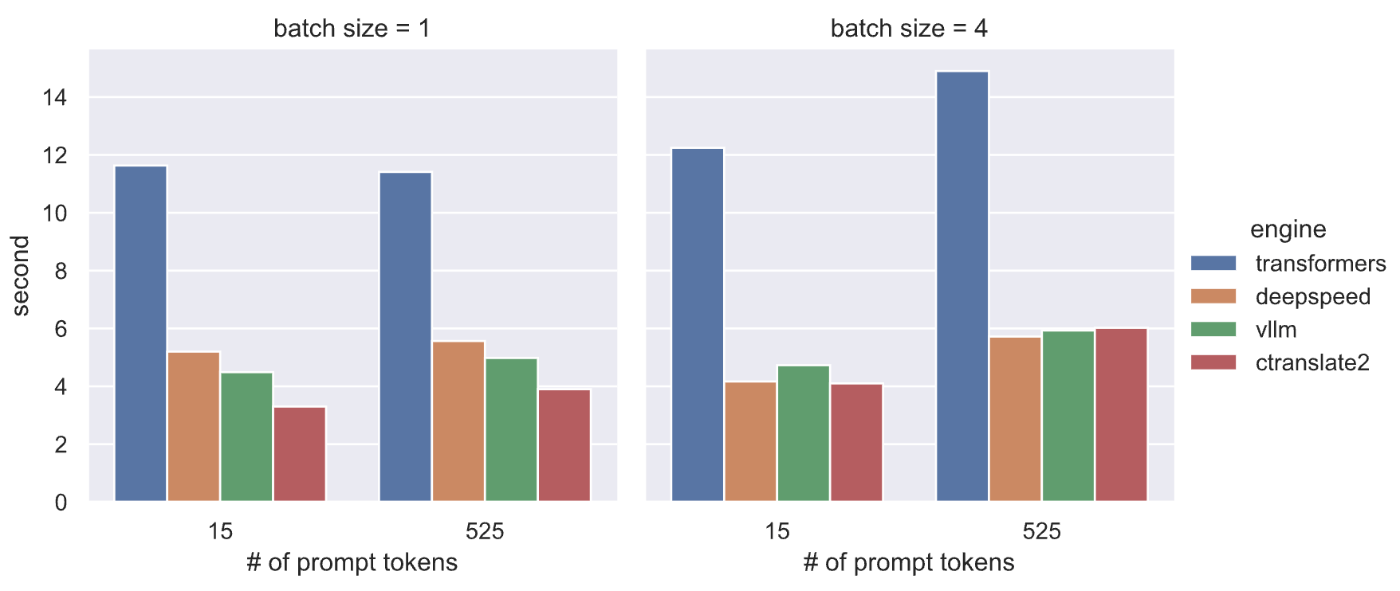
条件によって最適なツールは変わってくるので用途や使い勝手に合わせて選ぶと良さそうです。今回は単発のテキスト生成を想定して比較しましたが、次回以降ではAPIサーバでホストすることを想定してvLLMのAPIサーバ[4]やDeepSpeedベースのAPIサーバ DeepSpeed-MII、NVIDIAのFasterTransformerとTriton Inference Server によるAPIサーバなどを紹介していきたいと思います。
次回→ テキスト生成APIサーバのスループットを高めるbatching algorithms
-
https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html#offline-batched-inference ↩︎
-
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention ↩︎
-
https://opennmt.net/CTranslate2/quantization.html#mixed-8-bit-integers-and-16-bit-floating-points-int8-float16 ↩︎
-
https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html#api-server ↩︎

Discussion