医薬品副作用データセットを使って Google Cloud 上にデータ分析基盤を作る
コンテキスト
- Google Cloud を使ったデータ分析基盤構築に慣れておきたい
- 医薬品副作用に関するデータベースがあるのでこれを題材に使う
- BI による探索的解析とプログラミング言語による詳細解析のフローをまとめておきたい
- 特に FARES はデータサイズが大きいので Python や R で直接読み込むと後が厳しい
アーキテクチャ
BI 側から逆算:
- BI: 直感的に解析したいから
- DWH: BI の参照先として必要
- Data Source: 今回は RDB から抽出されたと思われるテキストファイル(配布物)
- ELT: 必要に応じてつくる
ツール
- BI: Looker Studio
- DWH: Big Query
- Data Source: なし?(csv の BigQuery へのアップロード)
JADER データのダウンロード
下記にアクセスして利用規約に同意すると zip 形式でダウンロードできる
中身:
❯ tree
.
├── demo202402.csv
├── drug202402.csv
├── hist202402.csv
├── reac202402.csv
├── 利用規約.txt
└── 初めにお読みください.txt
csv を Big Query にアップロード
"demo" データ

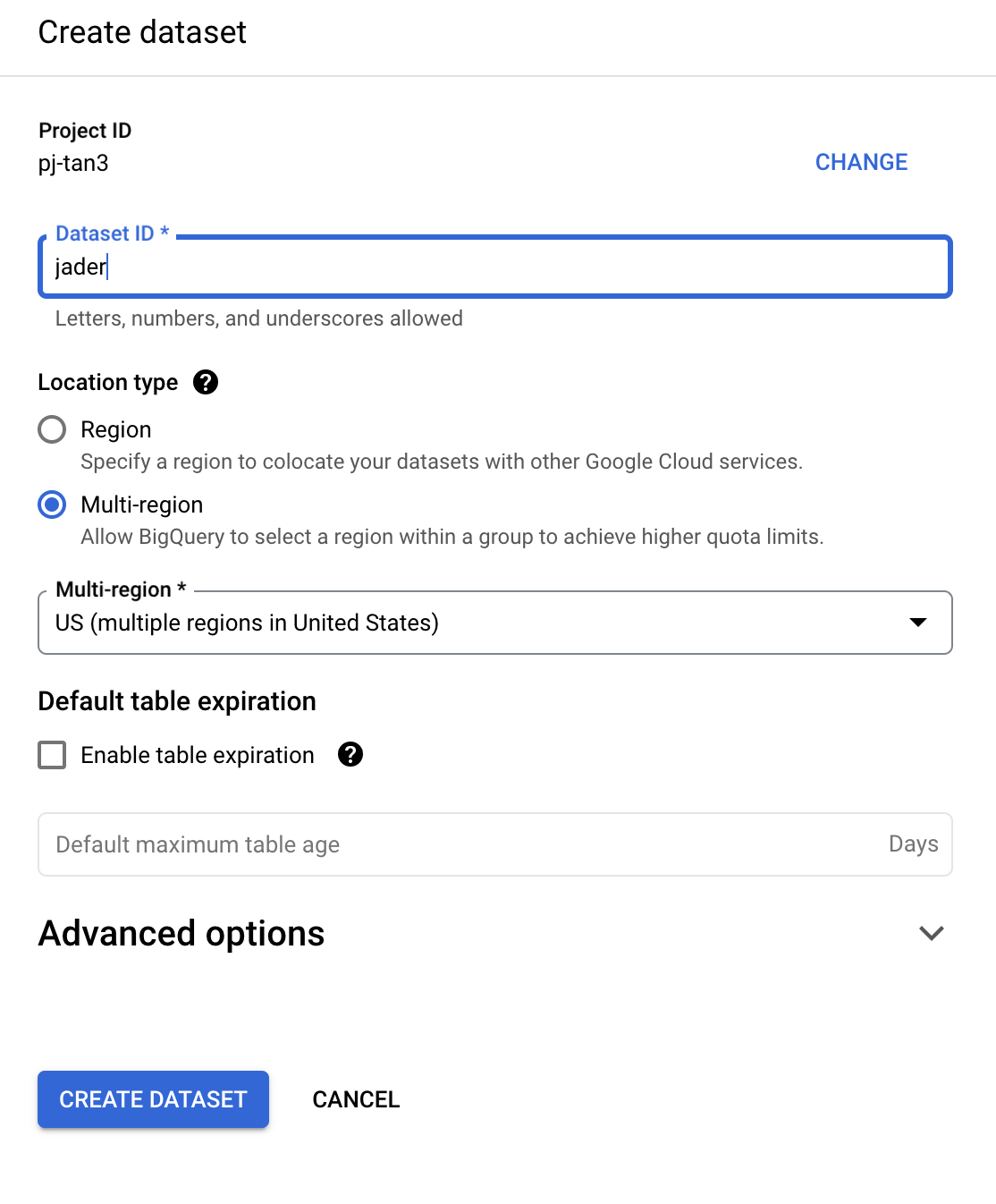
作成先データセットを選択し、テーブル名を入力。スキーマの自動検出を有効化しておく

パーティショニングはいらない
データセット内にテーブルができた
文字化けしてそう
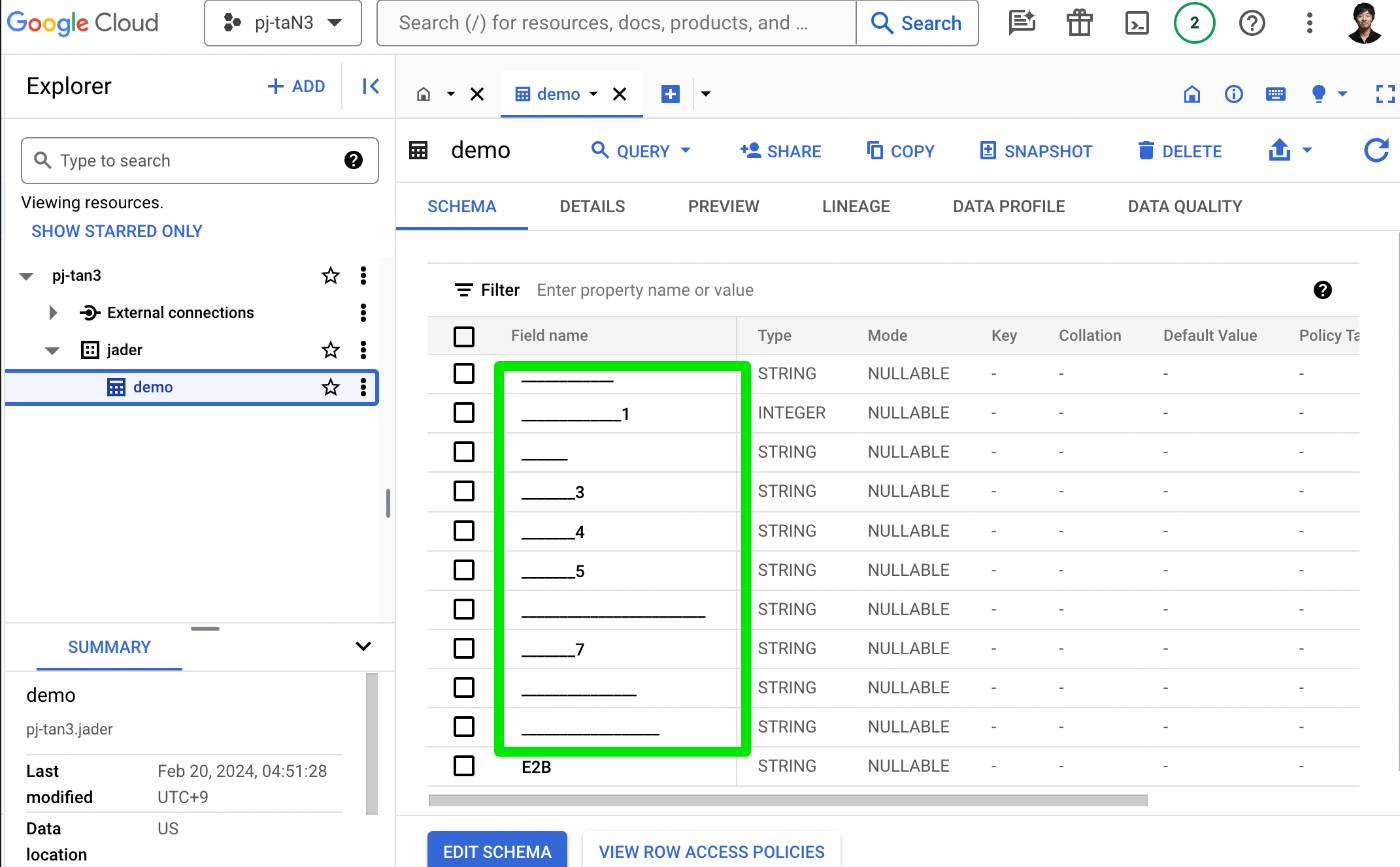
❯ nkf -g demo202402.csv
Shift_JIS
ShiftJIS のせいかも
https://cloud.google.com/bigquery/docs/loading-data?hl=ja#:~:text=BigQuery supports UTF-8 encoding,data only for CSV files. に下記のように書いてある
エンコード。BigQuery は、ネストされたデータまたは繰り返しデータとフラットデータの両方について UTF-8 エンコードをサポートします。CSV ファイルの場合のみ、フラットデータについて ISO-8859-1 エンコードもサポートします。
エンコーディングを UTF8 に変換して再アップロード
いまはとりあえず手でやる
❯ iconv -f CP932 -t UTF-8 demo202402.csv > demo202402_utf8.csv
Google Cloud Storage にアップロードして再ロード
しかし文字化けは直っていない
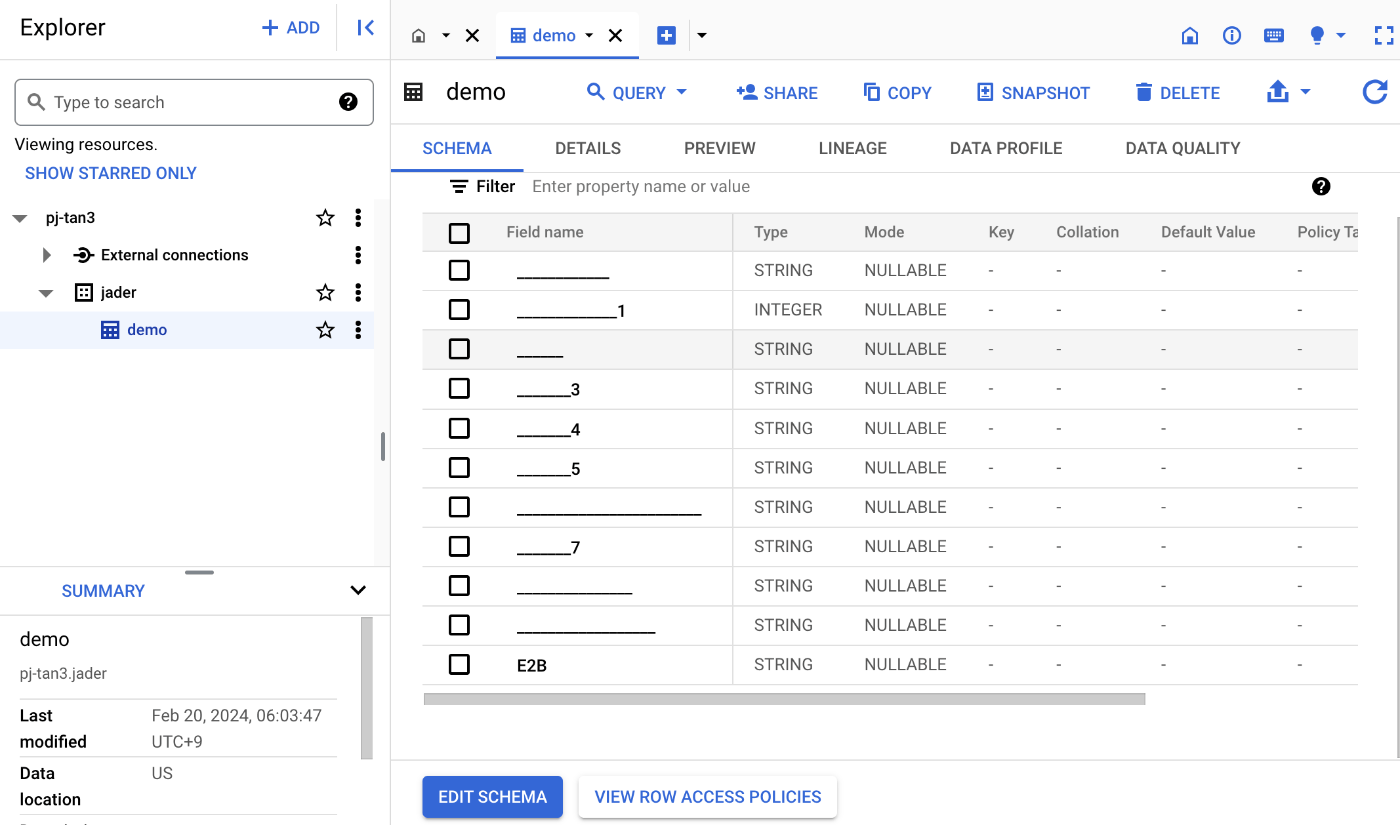
しまった、文字種の制約のせいだったか
列名には、英字(a~z、A~Z)、数字(0~9)、アンダースコア(_)を使用できます。
つまりスキーマをマニュアルで指定する必要がある。手でやりたくない。
Google Cloud Storage にファイルが置かれたらそれを検知して Big Query にアップロードする Cloud Functions を作る
"drug" データ
"demo" と同じ手順ですすめようとしたが早速ファイルサイズ上限にひっかかる
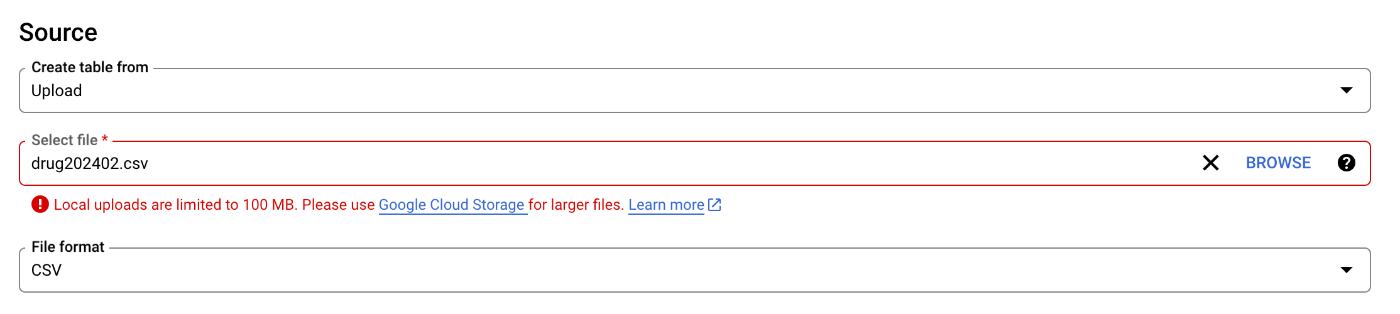
Google Cloud Storage 連携を使えとのこと
Cloud Storage に移動して Create Bucket(有効化されてなかったので有効化した)
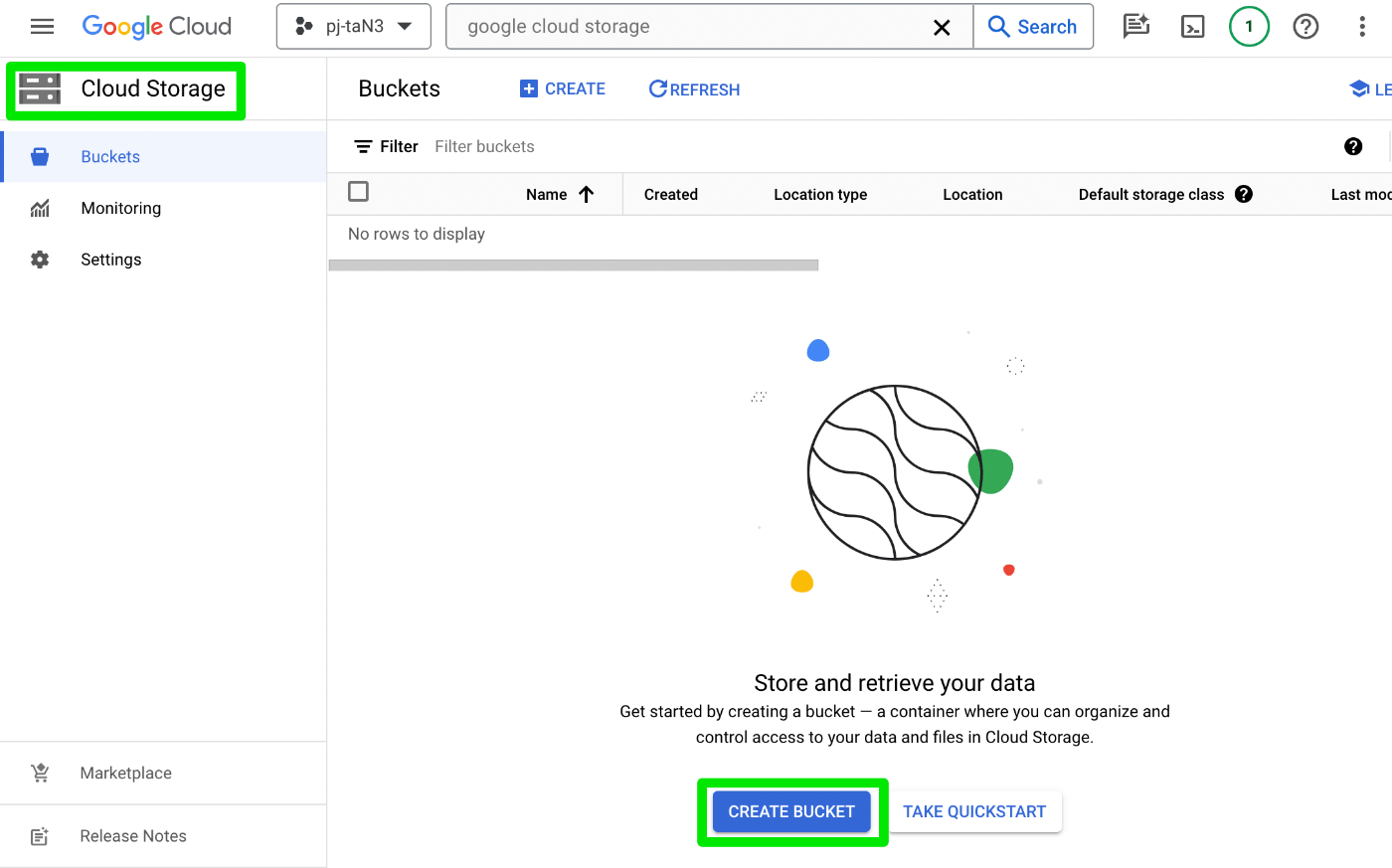
jader_csv という名前でバケットを作成し、"UPLOAD FOLDER" した
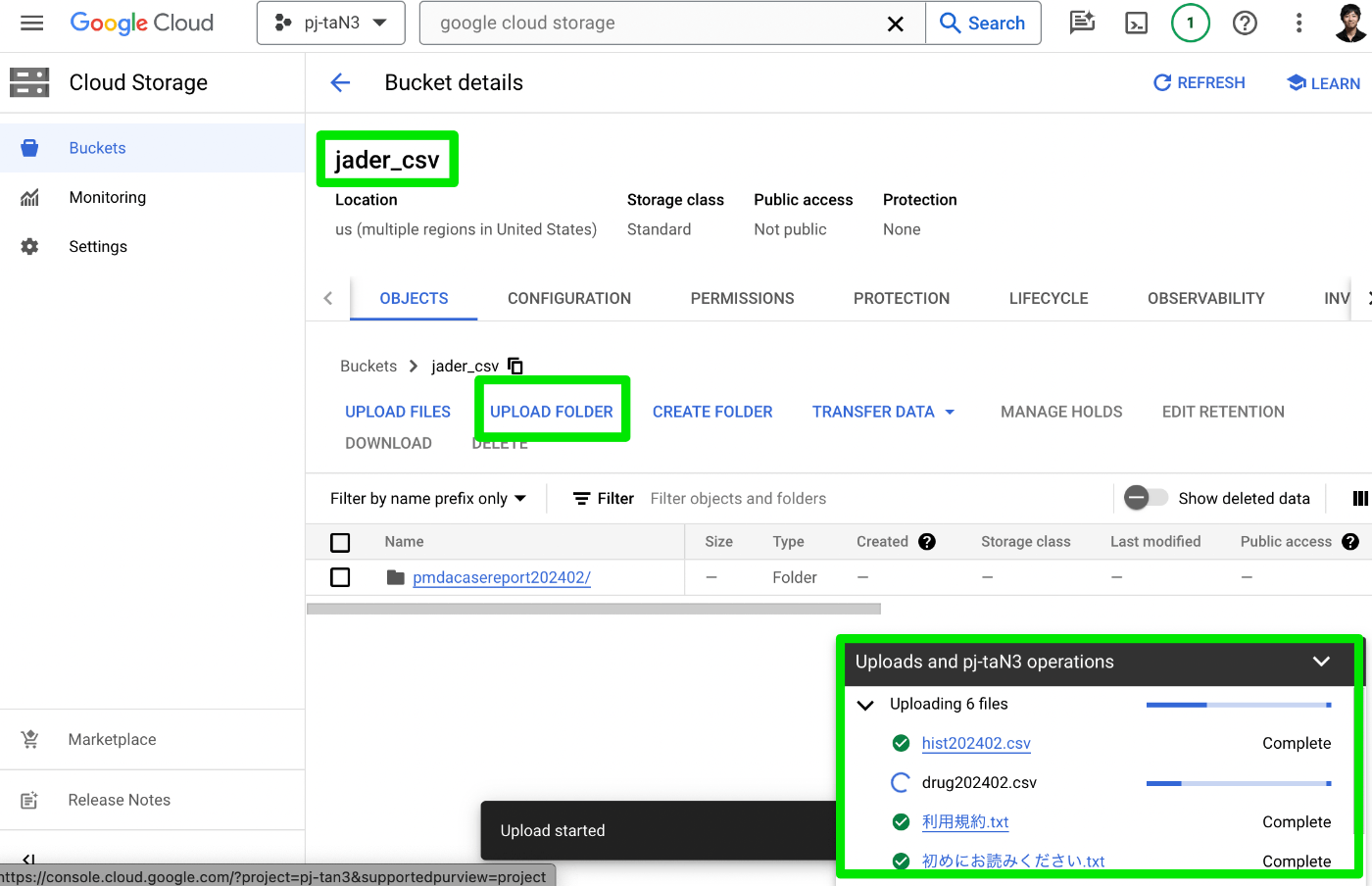
Big Query に戻り、Google Cloud Storage からのロードを試みる
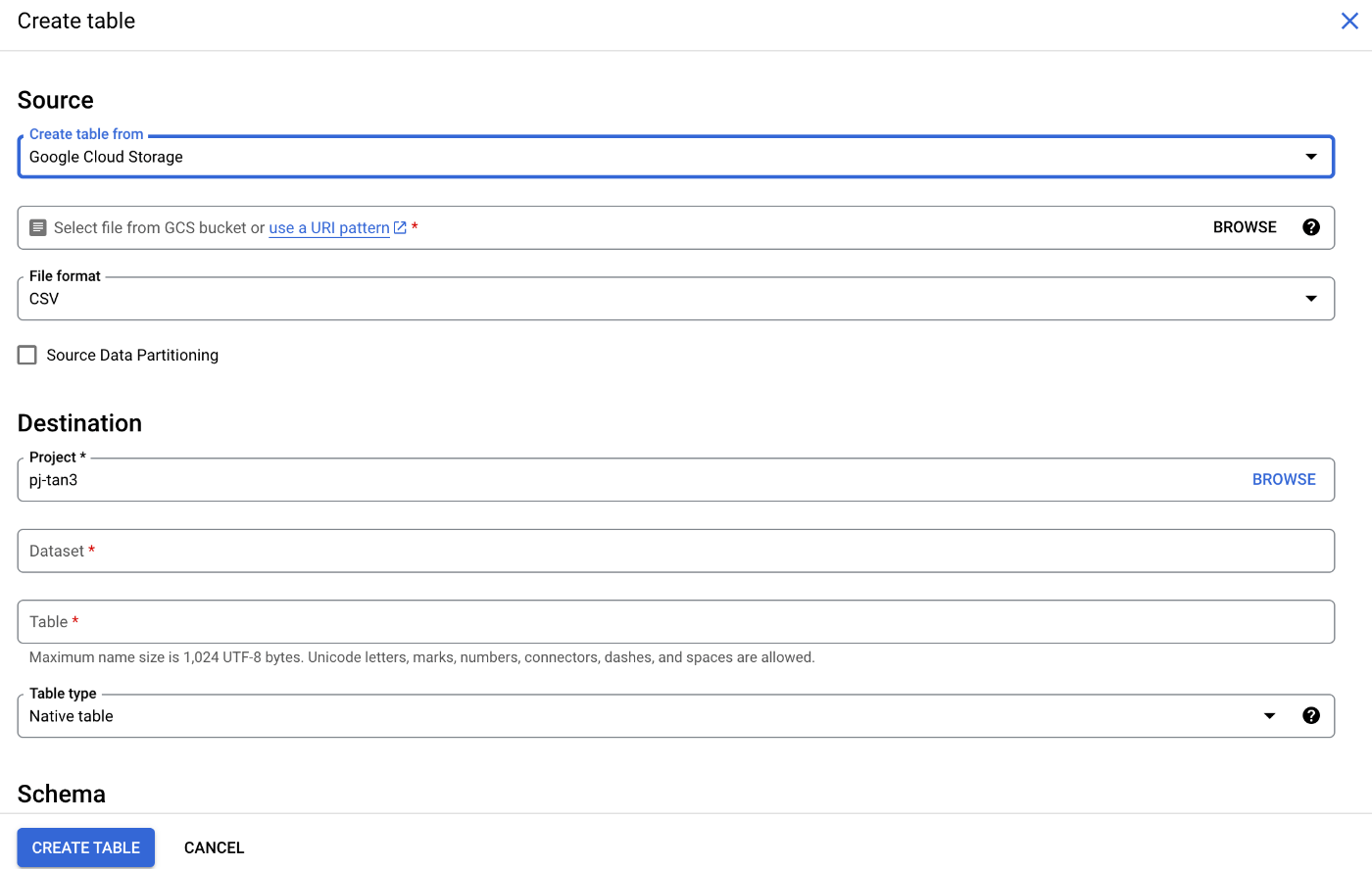
Cloud Storage 内の "drugXXXX.csv" を選択
1 次データ整形が必要でうまくロードできなかったが、できたところまで記事にした
失敗含むので Qiita にした