Apache Kafka でDAQからストリーミングする
Apache Kafka について
Apache Kafka とは、オープンソースの分散型データストア・ストリーミングプラットフォームで、複数のサーバーを用いることで大量のデータを処理することができ、世の中の様々なサービスで使われているらしい。調べるとLINEとかの記事がでてきたりする。
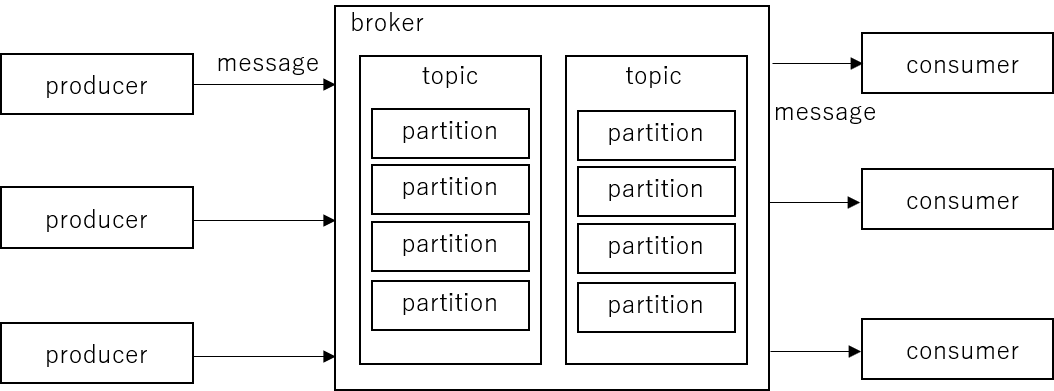
基本はbrokerというデータを配信するサービスが仲介役になることで、データを送る側と受け取る側はお互いのことを知ることなくbrokerとだけやり取りすれば済むという構造のようだ。いくつかKafka特有の語彙をリストしておく。
- Message: Kafkaでやり取りするデータの一単位
- Producer: メッセージを送るクライアント側のコンポーネント
- Consumer: メッセージを受け取るクライアント側のコンポーネント
- Broker: メッセージを仲介するサーバー側のコンポーネント
- Topic: Messageの種類毎に用意するコンテナ
- Partition: Topic内を分割したコンテナ
- Replication factor: 複数のbrokerを立てた時に、一つのメッセージを何個複製して別々のbrokerに書き込むかの設定。テストの時は別に1でもよさげ。障害耐性が必要なら最低3必要。Broker数より多くしても意味がない。
- Acknowledgment: producerがメッセージを送る時に、受け取り確認しない:0、少なくとも1つのbrokerに受信されたことを確認する:1、全てのbrokerが受信したことを確認する:all、の中から必要に応じて選択するオプション。1とallの違いは、1だと完全にreplicationが終わっているか保証されてないので、障害が発生した瞬間に複製が終わっていなかったメッセージが失われる可能性がある、ということらしい。万が一障害が発生した際に1イベントでも失いたくない場合と違って、実験のDAQなら1で問題なさそう。
- Time based retention: broker側が送られたメッセージを指定時間以上経過したものから削除していく設定。
- Size based retention: broker側が送られたメッセージのサイズが指定容量以上になった時に古いメッセージから削除していく設定。
ストリーミングDAQとしてKafkaを使う
Kafkaはバイトデータをメッセージとして送れるので、DAQ(データ収集系)上の生のバッファデータをそのまま1ブロック1メッセージで送ってしまえば良さそう。続いて生のバッファデータをデコードして検出器の時間情報、電荷情報、波形情報などをApache Arrowに詰めて再びストリーミングする。デコーダの部分は既存のC/C++のコードがあることや、新たに作る場合にも、バッファデータのビットマスクやビット演算を多用するのでC/C++での実装が適当となるであろうことから、一旦デコーダプロセスを挟む形式にしたいと考えている。その後はparquetファイルに保存するなり、Sparkと連携して更なる解析もストリーミングするなりすれば良い。

Kafkaにはpartitionといって一つのトピックのメッセージを分割したコンテナに保管していくことができる。よって、partition数を増やせばそれに対応してデコーダのプロセス数を増やすことができ、必要に応じて並列処理が簡単に可能となる。また、複数のマシンにデコーダプロセスを立てて仕事を分散させることも簡単にできる。
Producer側がtopicにメッセージを送る際には、自動的に各partitionに分散して送ることもできるし、指定したpartitionに送ることもできる。DAQのイベントデータは自動で分配すれば良いが、DAQのスタート時にRUN情報を記録したヘッダーを送ることがある。このRUN情報のメッセージについてはpartiton数だけ複製してRUNの最初に全てのpartitionに送ることで、デコーダ側のプロセスそれぞれがRUNの切り替わりを知ることができる。

と、思ったのだが、図のようにpartition数よりデコーダのプロセス数が少ないとRUNの最後を受け取りきる前に次のヘッダー情報が届いてしまう可能性があるので、partitionの数は合わせておく必要がありそう。
Kafkaサーバを立ててみる
本番環境では複数のKafkaサーバを立ててクラスタを作ることになるかもしれないが、ここではとりあえず開発用にシンプルな構成でKafkaサーバを立てる。基本的にはQuick Start [https://kafka.apache.org/quickstart] に従えばよろし。筆者の環境はUbuntu 22.04を使っている。
インストール
- Java環境を入れる
sudo apt install default-jre
sudo apt install default-jdk
- Kafka用にユーザーを切る(わかりやすいよう)
sudo adduser kafka
su kafka
- Kafka のダウンロード
mkdir ~/Downloads; cd ~/Downloads
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz
mkdir ~/kafka; cd ~/kafka
tar -xvzf ~/Downloads/kafka_2.13-3.8.0.tgz --strip 1
起動
クラスタIDをランダムで設定しておく。
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
ターミナルを開いてzookeeperとkafka-serverをそれぞれ起動する。
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
config/*.propertiesで各種設定をする。
複数brokerを立てる場合はserver.propertiesのbroker.idを変更する。
後はlogの保存場所やretention、デフォルトのtopic設定なども同じファイルで設定する。
とりあえずテストなのでこの辺はいじらない。
Topicの作成
Test Topicを作る。
bin/kafka-topics.sh --create --topic test --partitions 1 --bootstrap-server localhost:9092
C/C++ で Kafka producer/consumerを作る
librdkafkaを使う。CとC++それぞれのヘッダーがあるのでどちらでも使えるが、今回は既存のDAQにも実装することを考えてCの方を使う。
インストール
sudo apt install librdkafka-dev
producer
"This is a test message." というテストメッセージを送るCのコード
#include <stdio.h>
#include <librdkafka/rdkafka.h>
int main(int argc, char **argv)
{
// Producer initialization
char errstr[512];
rd_kafka_conf_t *conf = rd_kafka_conf_new();
rd_kafka_conf_set(conf, "bootstrap.servers", "localhost:9092", errstr, sizeof(errstr));
rd_kafka_topic_conf_t *topic_conf = rd_kafka_topic_conf_new();
rd_kafka_t *rk = rd_kafka_new(RD_KAFKA_PRODUCER, conf, errstr, sizeof(errstr));
rd_kafka_topic_t *topic = rd_kafka_topic_new(rk, "test", topic_conf);
// Produce a test message
char test_message[128] = "This is a test message.";
rd_kafka_produce(topic, RD_KAFKA_PARTITION_UA, RD_KAFKA_MSG_F_COPY, test_message, sizeof(test_message), NULL, 0, NULL);
// Call flush() to wait for message delivery (timeout: 1000 ms)
rd_kafka_flush(rk, 1000);
rd_kafka_topic_destroy(topic);
rd_kafka_destroy(rk);
return 0;
}
librdkafkaは自動でメッセージをバッファリングして送っているので、最後にflushを呼ぶことで確実に送信される。rd_kafka_conf_set()でbatch.num.messagesを変えれば最大値を制限できる。
consumer
Consumer側のテストコード
ポーリングして新しく届いたメッセージをprintfする。
#include <stdio.h>
#include <librdkafka/rdkafka.h>
int main(int argc, char **argv)
{
// Consumer initialization
char errstr[512];
rd_kafka_conf_t *conf = rd_kafka_conf_new();
rd_kafka_conf_set(conf, "group.id", "testConsumer", errstr, sizeof(errstr));
rd_kafka_conf_set(conf, "bootstrap.servers", "localhost:9092", errstr, sizeof(errstr));
rd_kafka_topic_conf_t *tconf = rd_kafka_topic_conf_new();
rd_kafka_topic_conf_set(tconf, "auto.offset.reset", "latest", errstr, sizeof(errstr));
rd_kafka_conf_set_default_topic_conf(conf, tconf);
rd_kafka_t *rk;
rk = rd_kafka_new(RD_KAFKA_CONSUMER, conf, errstr, sizeof(errstr));
rd_kafka_poll_set_consumer(rk);
rd_kafka_topic_partition_list_t *topic = rd_kafka_topic_partition_list_new(1);
rd_kafka_topic_partition_list_add(topic, "test", RD_KAFKA_PARTITION_UA);
auto err = rd_kafka_subscribe(rk, topic);
if (err)
printf("%s\n", rd_kafka_err2str(err));
rd_kafka_topic_partition_list_destroy(topic);
// polling loop
while (true)
{
// Set polling with timeout = 500ms
rd_kafka_message_t *rkmessage = rd_kafka_consumer_poll(rk, 500);
if (rkmessage)
{
if (rkmessage->err == RD_KAFKA_RESP_ERR__PARTITION_EOF)
continue; // Continue if partition is empty
if (rkmessage->err)
{
printf("%s\n", rd_kafka_err2str(rkmessage->err));
break; // Break in case of other errors
}
size_t size = rkmessage->len; // message size
char *buffer = (char *)rkmessage->payload; // message content
printf("%.*s\n", (int)size, buffer);
rd_kafka_message_destroy(rkmessage);
}
}
return 0;
}
500msのタイムアウトでポーリングをループする。
実行結果
kafkaConsumer を実行した状態で別ターミナルからkafkaProducerを実行すると、Consumer側にテストメッセージが表示された。
$ build/sources/kafkaConsumer
This is a test message.
こんな感じでDAQのコードから直接バイトデータを送ってしまえば後は比較的簡単にストリーミングできそう。
babirlからKafkaにストリームする
以降は主に理研で使われているDAQのbabirlにproducerを実装する話。新しくストリーミングDAQを作るといっても、当面はやはり従来のDAQと合わせて使うことになると思われるので、babirlからデータをストリーミングできるようにする。
ちなみにbabirlはこちらで公開されている。[https://ribf.riken.jp/RIBFDAQ/index.php?DAQ%2FDownload]
今回はbabirl240601をベースに使う。こちらはUbuntu22.04でもコンパイルできる。
最終的な改造後のbabirlのコードはこちら
DAQ START時に producerを初期化する
daq_start()関数内でproducerを初期化。hdlist[i].pathはファイルの保存先を指定したリストだが、これにコロン":"が含まれている場合はKafkaのbootstrap.serverだと思うようにしてみた。 init_kafka_producer()は初期化部分で関数化してkafka.hの中に定義したもの。
if (contains_colon(daqinfo.hdlist[i].path))
{
if (&rk)
delete_kafka(&rk, &topic);
char efn[4];
char topicName[128];
sprintf(efn, "%d", daqinfo.efn);
sprintf(topicName, "ridf-%d", daqinfo.efn);
printf("Kafka server %s", daqinfo.hdlist[i].path);
init_kafka_producer(&rk, &topic, efn, daqinfo.hdlist[i].path, topicName);
mxfd[i] = NULL;
}
ヘッダー情報を送る。
mkcomment() 関数内でRUNのヘッダー情報をファイルに書く部分があるので、ヘッダー情報を各partitionに送る部分を実装する。
これには、topicからmetadataを取得→partition数を取得→各partitionに同じヘッダー情報を送る→Flushを呼んで待つ、という手順を踏む。
if (&rk)
{
// Send header messages to all the partitions so all the pararell decoder processes receives runinfo.
// Get the number of partitions for the topic
const rd_kafka_metadata_t *metadata;
if (rd_kafka_metadata(rk, 0, topic, &metadata, 5000) != RD_KAFKA_RESP_ERR_NO_ERROR)
{
lfprintf(lfd, "Failed to fetch metadata\n");
return;
}
int partition_count = metadata->topics[0].partition_cnt;
lfprintf(lfd, "Number of partitions: %d\n", partition_count);
for (int i = 0; i < partition_count; ++i)
{
if (rd_kafka_produce(
topic, i,
RD_KAFKA_MSG_F_COPY,
commentbuff, idx,
NULL, 0,
NULL) == -1)
{
lfprintf(lfd, "Failed to produce message to partition %d\n", i);
}
else
{
lfprintf(lfd, "Produced message to partition %d\n", i);
}
}
// Wait for all messages to be delivered
lfprintf(lfd, "Flushing message...\n");
rd_kafka_flush(rk, 10 * 1000); // Wait for max 10 seconds
}
ブロックデータを送る
ebblock()内でブロックデータをファイルに書き込む部分があるので、そこでKafkaに送る。
/* Store data to storage */
if (runinfo.runstat == STAT_RUN_START)
{
lfprintf(lfd, "runstat START: rk %d\n", rk);
for (i = 0; i < MAXHD; i++)
{
if (mxfd[i])
{
// flock(fileno(hdfd[i]), LOCK_EX);
fwrite(ebbuf.data, 2, bsz, mxfd[i]); // Write into HD
// flock(fileno(hdfd[i]), LOCK_UN);
}
}
if (&rk)
{
kafka_produce(topic, 2 * bsz, ebbuf.data);
lfprintf(lfd, "sent data to kafka server\n");
}
}
daq_close()でFlushし、rd_kafkaをデリートする
if (&rk)
{
// Flush final messages
rd_kafka_flush(rk, 10 * 1000); // Wait for max 10 seconds
delete_kafka(&rk, &topic);
}
テスト
改造したbabildをイベントビルダー上で起動した上で、babiconを立ち上げる。
HD listにKafkaのbootstrap.serverを指定する。
sethdlist 2 path localhost:9092
getconfigしてHd listの 2番がONになっていることを確認。
HD list
0 /home/daq/data (off) 4.8TB free
1 /home/103test/ridf_103test (on) 4.8TB free
2 localhost:9092 (on) 0.0GB free
ちなみに、ローカルディレクトリを別のHD番号に指定して、そちらもONにしておけばrawdataをファイルに書きつつストリーミングすることができる。
あとはstart/stopができればOK
おわりに
以上、Apache Kafkaを使ってDAQからのデータをストリーミングする方法のまとめと実装についてまとめてみた。続いては、rawdataのストリームをデコードしてparquet fileにする、あるいはKafkaにストリームする部分についてまとめたいと思う。
Discussion