AWS EMR Serverlessにsparkジョブを投げる
これまでCERN ROOTを使って行ってきた解析をApache Sparkに移行する一つの理由としてAmazon Web Serviceのようなクラウドコンピューティングサービスを効率的に使うことができるという点がある。
AWSでROOTを使った解析をするためには、EC2という仮想サーバサービスを利用して環境を構築しなければならい。
この場合、インスタンスを立てていた時間とインスタンスのスペックに応じて課金が発生するので、コストを抑えるためには起動している時間を効率的に活用する必要がある。
一方で、サーバレスのサービスであればジョブを投げるだけで処理に使ったリソース分だけ課金されるので、コストを抑えることができる。
Amazon EMR Serverles は比較的新しいサービスのようで、試してみたらかなり簡単にSparkジョブを投げることができたので、記事にしてみる。
Amazon EMR Serverless のセットアップ
まずはAWSのコンソールからEMRを開く。実験データのオフライン解析は日本とのpingを気にすることはないので、右上から料金の安いUSのサーバを選択。
左のタブからEMR Studioを選択し、"Create Studio" ボタンを押す。

Setup optionsからBatch jobsを選択し、"Create Studio and launch applications"を押す。

EMR Studio が開く

一旦AWSのストレージであるS3のコンソールを開き、解析用のバケットを作る。
リージョンがEMR Studioと同じであることを確認して作成。

data/ と code/ のフォルダを作成し、それぞれにファイルをアップロードする。

data/ には parquet ファイル

code/ にはpysparkの解析コードをzipしたものと、main.py、必要なCSVファイルなどを置く。

バッチジョブを作成
main.py
from pyspark.sql import SparkSession
from sparkOEDOModules.procModules import mapper
from sparkOEDOModules.detectorProcs.dia import diaMain
from sparkOEDOModules.detectorProcs.srppac import srppacMain
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--input", help="input file name", required=True)
args = parser.parse_args()
if __name__ == '__main__':
# Initialize Spark session
spark = SparkSession.builder.getOrCreate()
# Read the parquet file
raw_df = spark.read.parquet("s3://spark-analysis/data/"+args.input+".parquet")
exploded_df = mapper.ExplodeRawData(raw_df)
LoadCSVFiles(spark)
detector_df = diaMain.Process(exploded_df, full=False, require="dia3")
detector_df = detector_df.join(srppacMain.Process(exploded_df, full=False, require="sr0"), on=["event_id"], how="inner")
detector_df.write.mode("overwrite").parquet("s3://spark-analysis/data/"+args.input+"_processed.parquet")
main.py --input [ファイル名]
でS3上のファイル(s3://spark-analysis/data/[ファイル名].parquet)を開いて解析するコード
モジュールsparkOEDOModulesはzipしたもの。
中身は以下のリポジトリを参照
EMR Studioから黄色の"Submit job run"を押す。
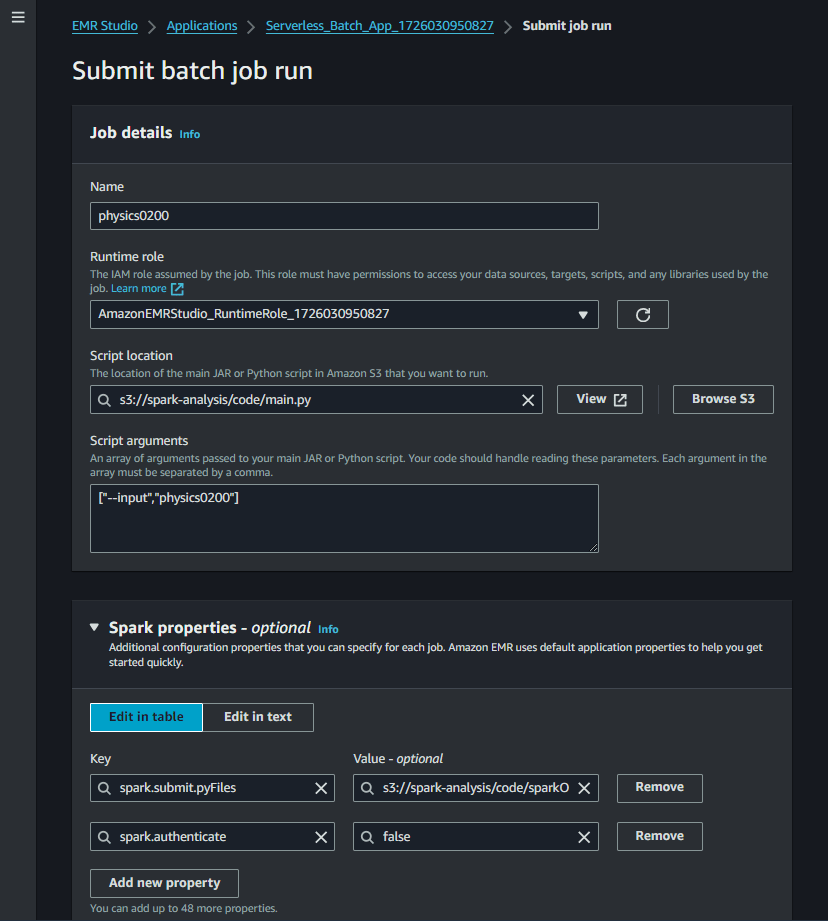
Runtime roleは自動で生成されたものを選ぶ。
"Script location" に main.py のs3 URLを指定。
引数のリストを "Script arguments" に指定。
"Spark properties" に
spark.submit.pyFiles としてzipファイルを指定。
spark.authenticate を false に。
以上でSubmitする。
少しすると statusが "scheduled" から "running" になるはず。
緑色の"Success" になったら終了
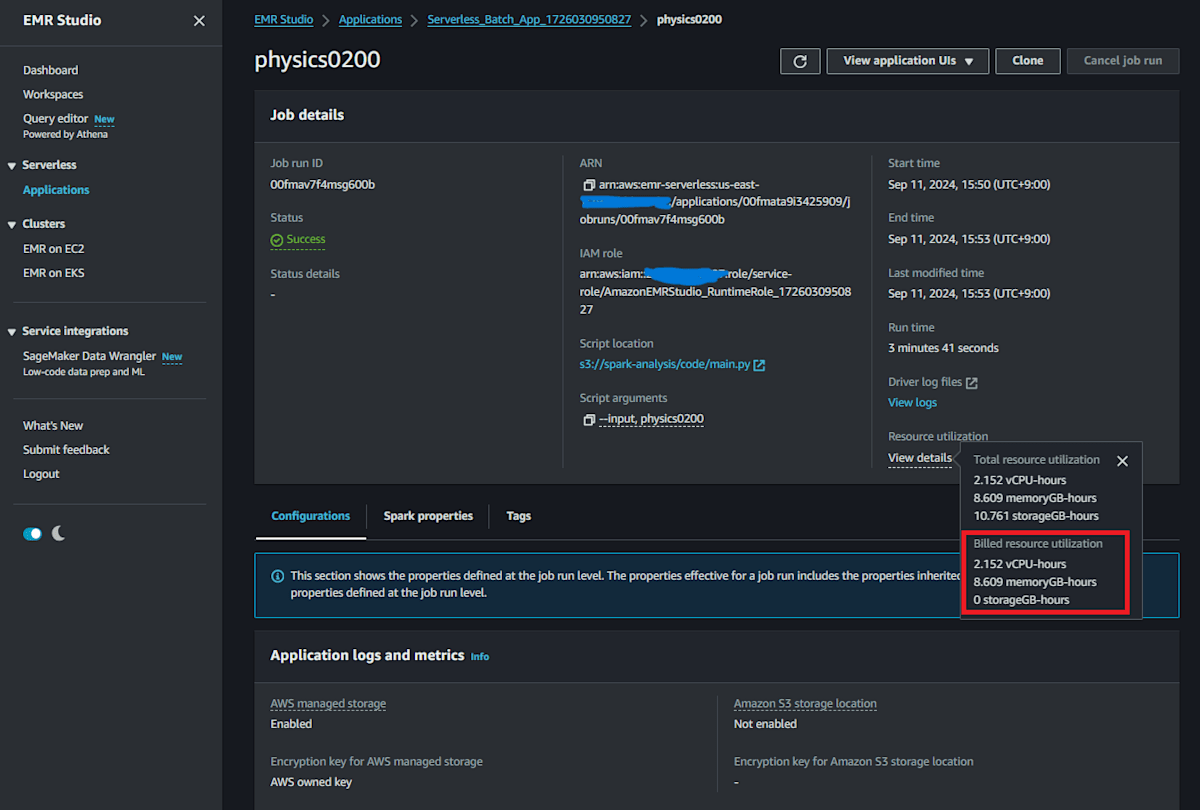
Resource utilizationのBilledを確認する。
2.152 vCPU-hours, 8.609 memoryGB-hours
US East-1 の料金はそれぞれ 0.052624 USD per vCPU per hour, 0.0057785 USD per memoryGB per hour なので、0.16 USD 掛かった。
AWS CLI からジョブを投げる
AWS CLI を使うとコマンドラインからAWSの操作ができる。
インストール後、
aws configure
でアクセスキーとデフォルトリージョンの設定をする。(詳細省略)
aws emr-serverless list-application
とすると、アプリケーションの一覧が表示される。
ジョブのsubmitには以下のコマンドを使う。
aws emr-serverless start-job-run \
--application-id アプリケーションid \
--execution-role-arn arn:aws:iam::アカウントid:role/service-role/AmazonEMRStudio_RuntimeRole_ロールid" \
--name physics0201
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-analysis/code/main.py",
"entryPointArguments": [
"--input",
"physics0201"
],
"sparkSubmitParameters": "--conf spark.submit.pyFiles=s3://spark-analysis/code/sparkOEDOModules.zip --conf spark.authenticate=false"
}
}'
3つjobをsubmitしてみた。

それぞれ"Running"になっている。
自前のサーバだとリソースの制限で複数のジョブを一度に回すことが出来なかったが、クラウドでは好きなだけ使えるので、データをS3に置いてさえしまえば解析はかなりスピードアップできそう。
デフォルトのApplication設定では、400 vCPU、メモリ3TBのリミットが設定されているが、変更して増やすこともできる。
EMR Studio notebook でデータを確認する
EMR Studio には Jupyter notebook を使って spark を使えるようなので試してみた。
まずは インタラクティブ用の EMR Studio をデフォルト設定で作成する。
また、こちら(
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-studio-user-permissions.html) の説明に従って、"EMR Serverless interactive policy"の部分を IAM User に追加しておく。
"Dashboard" から "Use fully-managed Jupyter notebooks" の "Create workspace"を押す。

こんな感じでnotebookが開く
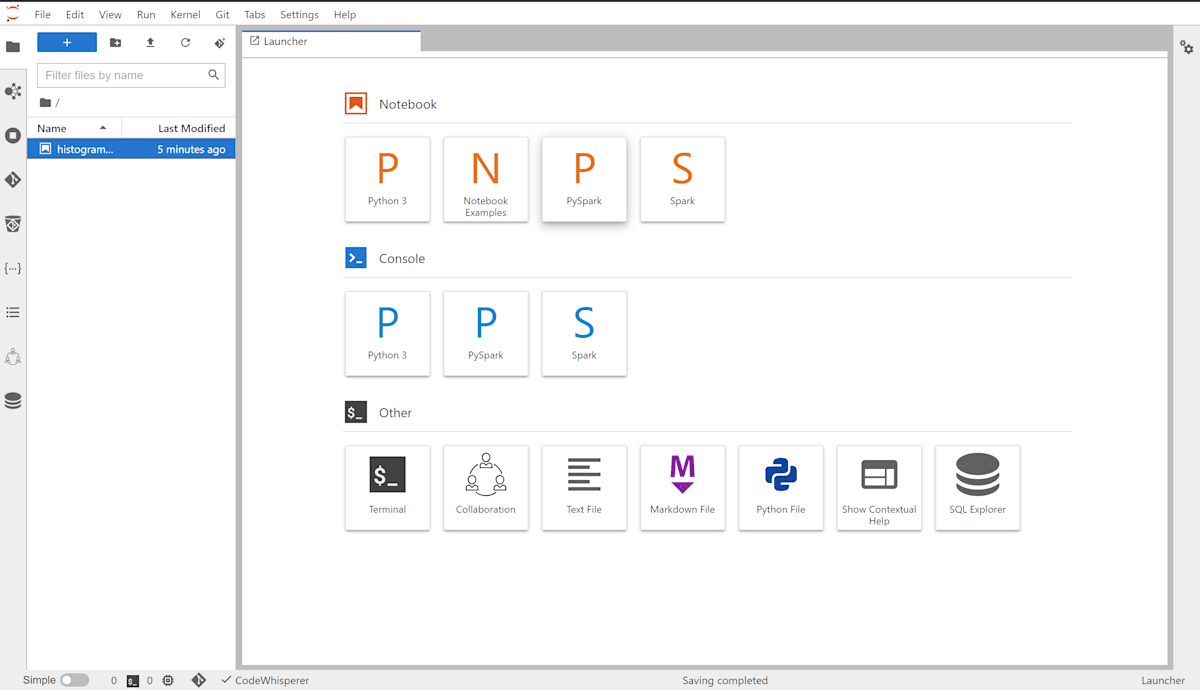
左のタブから "Compute" を開き、"Compute type" として "EMR Serverless application"を選択。Application として、自動で作成されたinteractive用の application と role を選択し、Attachする。

S3 上に作成された parquet ファイルを開き、Serverless application を使って操作することができる。

EMR Studio notebook からヒストグラムをプロットする。
Serverless application 上では matplotlib を使ってプロットを表示することができないようなので、マジックコマンドを駆使してプロット部分はローカルのカーネルで行う必要がある模様。
%%help
と入力するとコマンドの一覧が出力される。

%%local
とすることで、Cellの以下の部分がローカルで実行される。
%%pyspark -o VAR_NAME
とすると、以下の部分がpyspark上で実行され、VAR_NAMEで指定したspark DataFrameがPandas dataframeとして利用できる、と書いてある。
ということで、まずはlocalからpysparkを呼ぶ部分。
%%local
%%pyspark -o data
from pyspark.sql.functions import DataFrame, explode
from pyspark.ml.feature import Bucketizer
import numpy as np
import pandas as pd
def Hist1D(dataFrame, colName, nbins, range):
# Define bin edges (n bins between -range[0] and range[1])
bin_edges = np.linspace(range[0], range[1], num=nbins).tolist()
# Add underflow and overflow bins to an extended list
ex_bin_edges = bin_edges.copy()
ex_bin_edges.append(np.inf)
ex_bin_edges.insert(0, -np.inf)
# Create a Bucketizer with the extended list of bins
bucketizer = Bucketizer(splits=ex_bin_edges, inputCol=colName, outputCol="bin")
# Apply the Bucketizer to the DataFrame
binned_df = bucketizer.transform(dataFrame.select(colName))
# Group by bin and count the occurrences in each bin and remove Null bins
histogram_df = binned_df.groupBy("bin").count().orderBy("bin")
histogram_df = histogram_df.filter(histogram_df["bin"].isNotNull())
# Collect the histogram data from Spark to local
histogram_data = histogram_df.collect()
bin_edges = np.linspace(range[0], range[1], num=nbins)
counts = np.zeros(len(bin_edges)-1)
# Populate the counts array based on the histogram data
# Also, counts statistics for under/overflowed bins
underflow = 0
overflow = 0
inrange = 0
for row in histogram_data:
bin_index = int(row['bin']) # Get the bin index
if bin_index == 0: # The underflow bin
underflow = row['count']
if bin_index == nbins: # The overflow bin
overflow = row['count']
else:
counts[bin_index-1] = row['count'] # Populate the count for the bin
inrange = inrange + row['count']
# Print statistics
print("Total entries: {}, Underflow: {}, Inside: {}, Overflow: {}".format(inrange+underflow+overflow, underflow, inrange, overflow))
return counts
df = spark.read.parquet("s3://spark-analysis/data/physics0200_srppac.parquet")
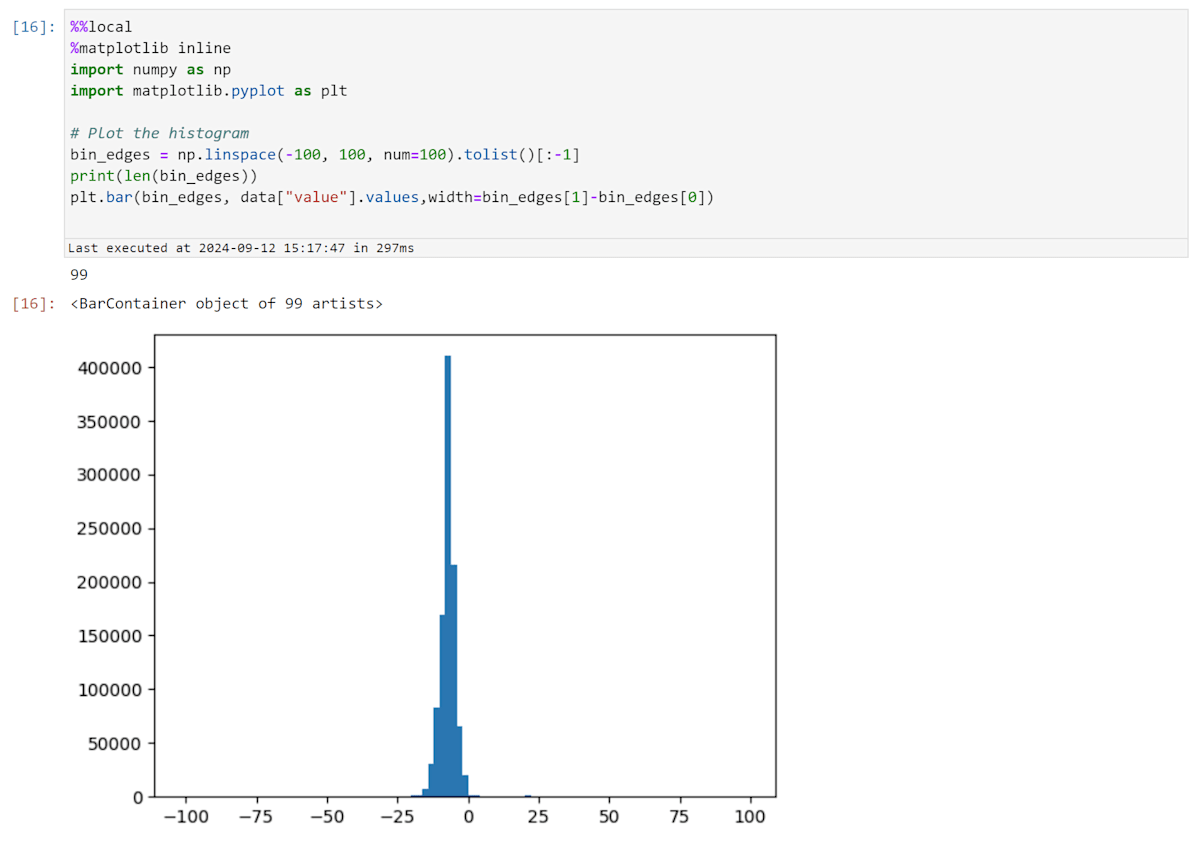
counts = Hist1D(df, "sr0y_pos", 100,[-100,100])
data = spark.createDataFrame(counts)
Hist1D関数ではヒストグラムのビン毎のカウントを numpy array として返すようにする。
data = spark.createDataFrame(counts)
の行でカウントの numpy array を spark dataframe に変換。
Serverless アプリケーション側から ローカルに移動するデータはtoJSON()されてから取得しているようなので、spark dataframe しか使えない模様。
次のセルでは local から data を確認する。
helpの説明通り Pandas dataframe になっている。
local で matplotlib を使ってヒストグラムをプロットする。
おわりに
Spark でデータ解析ができるようになると、AWS上でも比較的簡単にjobを投げられるということが分かった。料金は発生するものの、初期費用なしでクラスターを使って大規模データの解析が可能になるので、自前でサーバを買って環境を整え運用するのに比べてこちらの方が良いというケースも多いのではないかと感じた。
EMR Studio 上で Jupyter notebook を使う際には、Serverless application 上で走らせる spark コマンドの部分と、プロットを表示するといったローカル部分を分ける必要があり、その間のデータ移動は spark dataframe から Pandas dataframe というように決まっているので多少考えて実行する必要があった。
ただ、これが使えればクラウド上で閉じた解析ができるのでかなり便利であることは間違いないと感じた。
もちろん、batch job でひたすら parquet ファイルを生成し、後は全部ダウンロードして自分のマシン上のSparkで解析するのもアリかなと思う。
Discussion