GPT-4Vを活用して、"パッと見の雰囲気"で大量の検索結果を評価する
(関係者の方へ)以下、いくつかの実サービスでのスクリーンショットや評価結果が出てきます。もし不都合等ありましたらお教えいただければ記事から削除します。また、評価データが欲しいということがありましたら、全データお渡ししますのでX(旧Twitter)などでご連絡いただければと思います。
概要
本記事では、検索結果の「パッと見の雰囲気」を大規模言語モデル(LLM)を活用して自動的かつ客観的に評価する方法を提案します。キーワードとペルソナを生成し、検索結果ページのスクリーンショットをGPT-4Vで解析することで、アイテムの見た目に関する関連性や視覚的魅力、ユーザーエクスペリエンスを0〜10で評価します。GoogleやYouTubeなどの実際のウェブサイトを対象に評価を行い、その結果と手法の詳細を紹介します。この方法によって、主観的になりがちな見た目での評価を定量化し、改善点を明確にする新たなアプローチを示します。
はじめに
検索結果の「見た目」や「雰囲気」は、ユーザーエクスペリエンス(UX)に大きな影響を与えます。しかし、特に視覚情報が重要な検索サービスでは、その影響は一層大きくなります。
画像や動画、商品の写真など、視覚的な情報が検索結果の中心となるサービス—例えば、Eコマースサイト、動画共有プラットフォーム、画像検索エンジンなど—では、検索結果の関連性だけでなく、全体の見た目や視覚的な質がユーザーの満足度に直結します。
実務において、視覚情報の質やアイテムの配置を改善することは、ユーザー満足度やコンバージョン率の向上につながります。しかし、その評価は主観的な要素が強く、定量的な評価が難しいという課題があります。
そこで本記事では、視覚情報が重要な検索サービスを評価するために、大規模言語モデル(LLM)、特に画像を入力として活用できるモデルを用いて、検索結果の「パッと見の雰囲気」を自動かつ客観的に評価する方法を検討します。
評価方法の概要
ざっくり、以下のような流れで評価を行っていきます。
インプットとして検索サービスの概要を入力し、アウトプットとして検索されそうなキーワード別の定性的な検索結果の見た目評価を出力します。
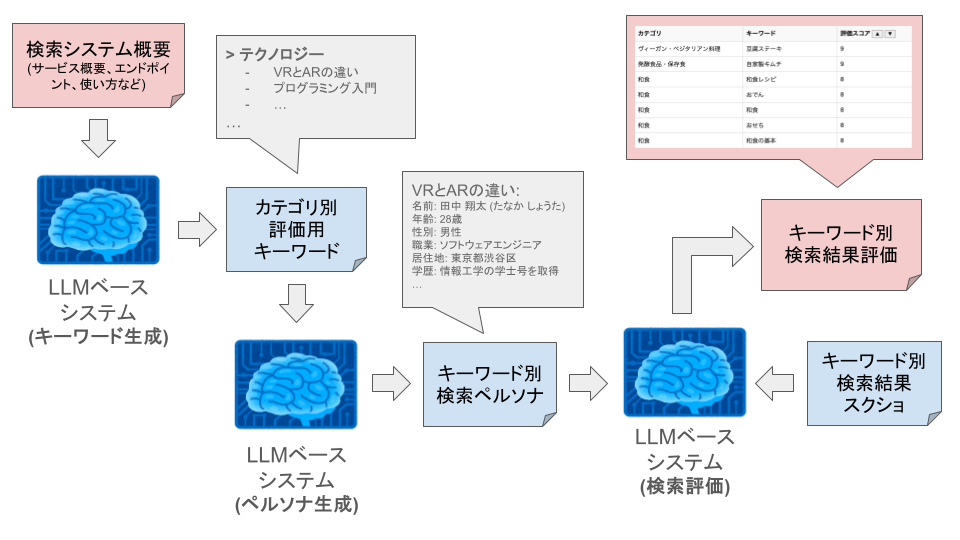
以下のようなステップを採用しています。
1. キーワード生成
まず、評価対象となるウェブサイトに関連するキーワードを生成します。これは、サイトのタイトルや説明文をもとに、LLMを使用して自動的に生成します。キーワードは、多様なユーザーの検索意図を反映するため、複数のカテゴリに分けて作成します。
2. ペルソナ生成
次に、各キーワードに対してペルソナを作成します。ペルソナとは、特定のニーズや行動パターンを持つ仮想のユーザー像です。LLMを用いて、キーワードを検索する典型的なユーザーの属性や期待を詳細に描写します。
3. 検索結果の取得と画像解析検索結果の評価
生成したキーワードとペルソナをもとに、ウェブサイト内の検索機能を使用して検索結果ページを取得します。そのページのスクリーンショットを撮影し、LLMの視覚機能(GPT-4V)を利用して、画像としての検索結果ページ入力とし、ペルソナの視点から検索結果ページを0〜10のスコアで評価します。評価基準は以下の通りです。
- 関連性:検索キーワードと結果の一致度
- 視覚的魅力:デザインやレイアウトの美しさ、見やすさ
- ユーザーエクスペリエンス:情報の整理度や操作性
実際の評価結果
ここでは、具体的なウェブサイト(Google、YouTube、クックパッド、国会図書館サーチ)を対象に評価を行った結果を紹介します。
評価用にツールを作ったので、まずはその評価ツールを紹介します。その後、評価ツールによるスクリーンショットを貼り付けていきます。
評価用ツール
5ステップでWebサービスの評価を行うツールです。
1. ベースURLの入力
キーワードを引数とする、その後ろに検索クエリをくっつけると検索URLとなるURLを入力する。

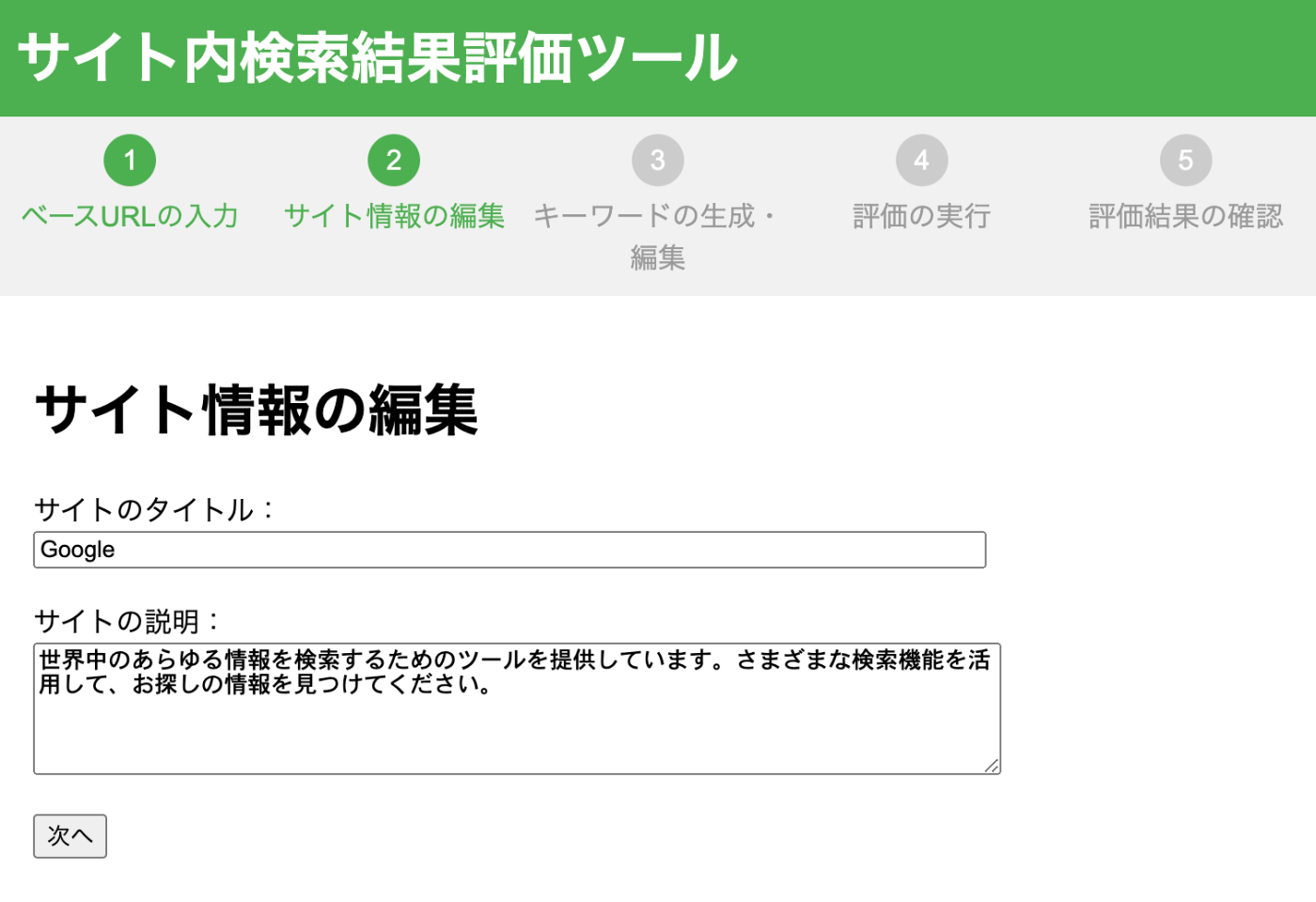
2. サイト情報の編集
入力したURLからTitleとDescriptionを取得します。ここで説明を追加すると、生成される評価用キーワードがより賢くなります。
3. キーワードの生成・編集
サイト情報から、「検索されそうなキーワード」をカテゴリに分けて生成します。だいたい10~20くらいのカテゴリ、それぞれのカテゴリで10~30くらいのキーワードを生成します。だいたい300個くらいのキーワードが生成されます。
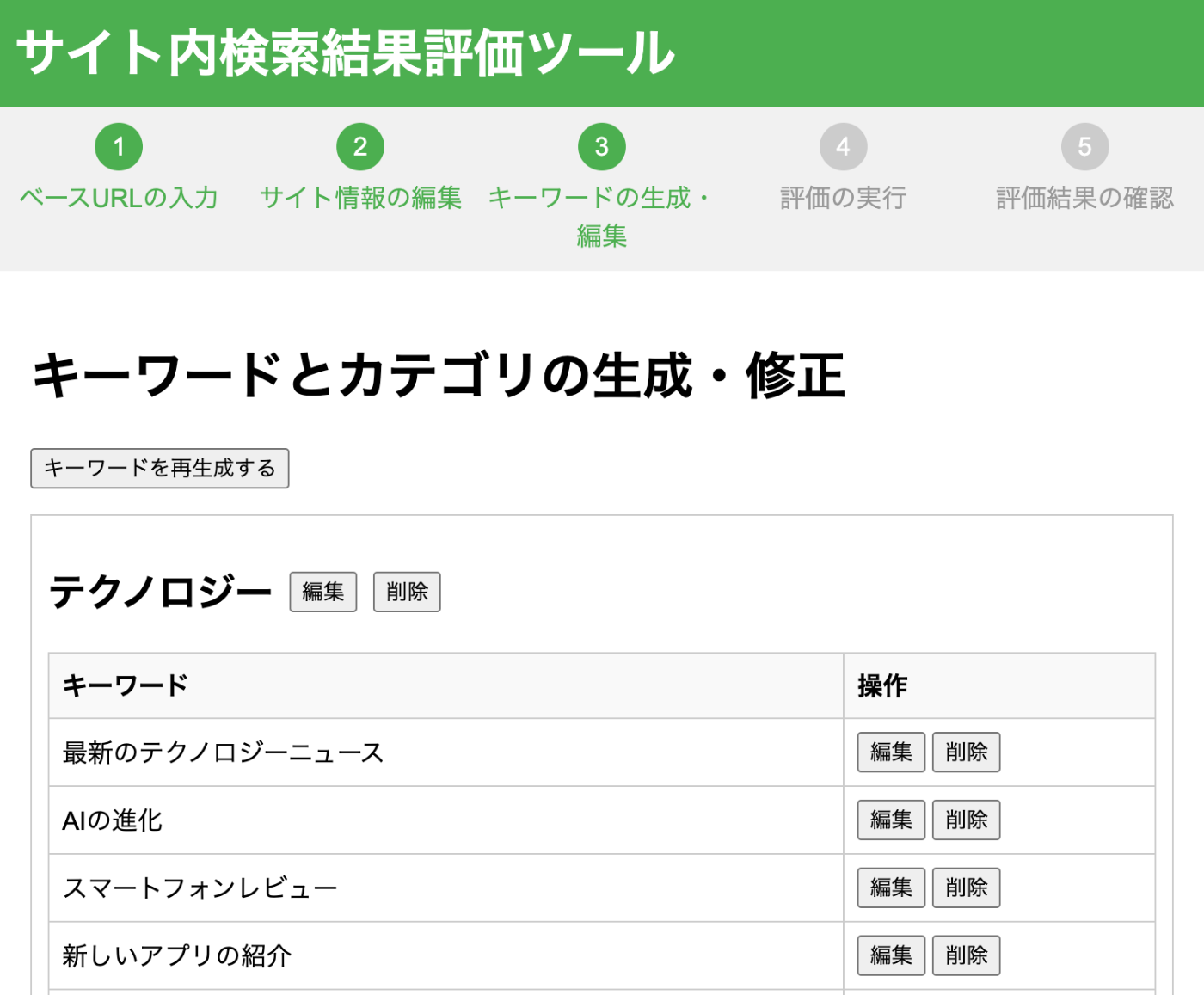
気に入らなかったら、追加・削除・編集できます。
5. 評価結果の確認
評価中はプログレスバーが表示されますが評価が終わると、以下のような、カテゴリごとの平均評価が出ます。
下にスクロールするとキーワードごとの評価スコアが見れます。

各評価スコアの行はクリックすると、以下のような感じで詳細がみれます。

それでは、ここから各サービスの評価結果を見ていきます。
このツールでは課題の発見が優れていると思うので、課題がありそうなキーワードをメインに見ていくとしましょう。
世界最大の検索エンジンであり、検索結果のデザインやUXのベンチマークとして適切でしょう。
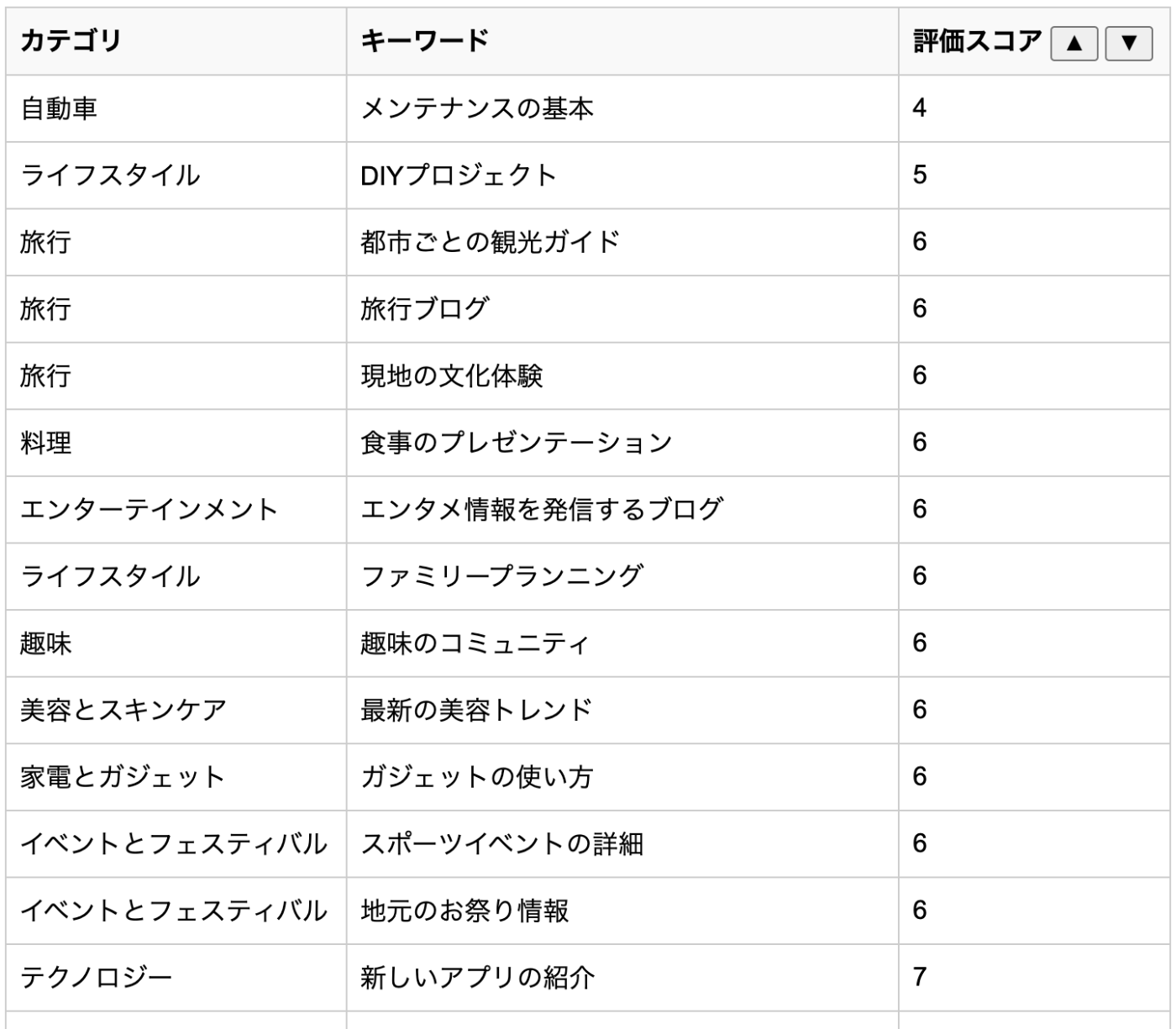
キーワード別評価 (低い順、一部)
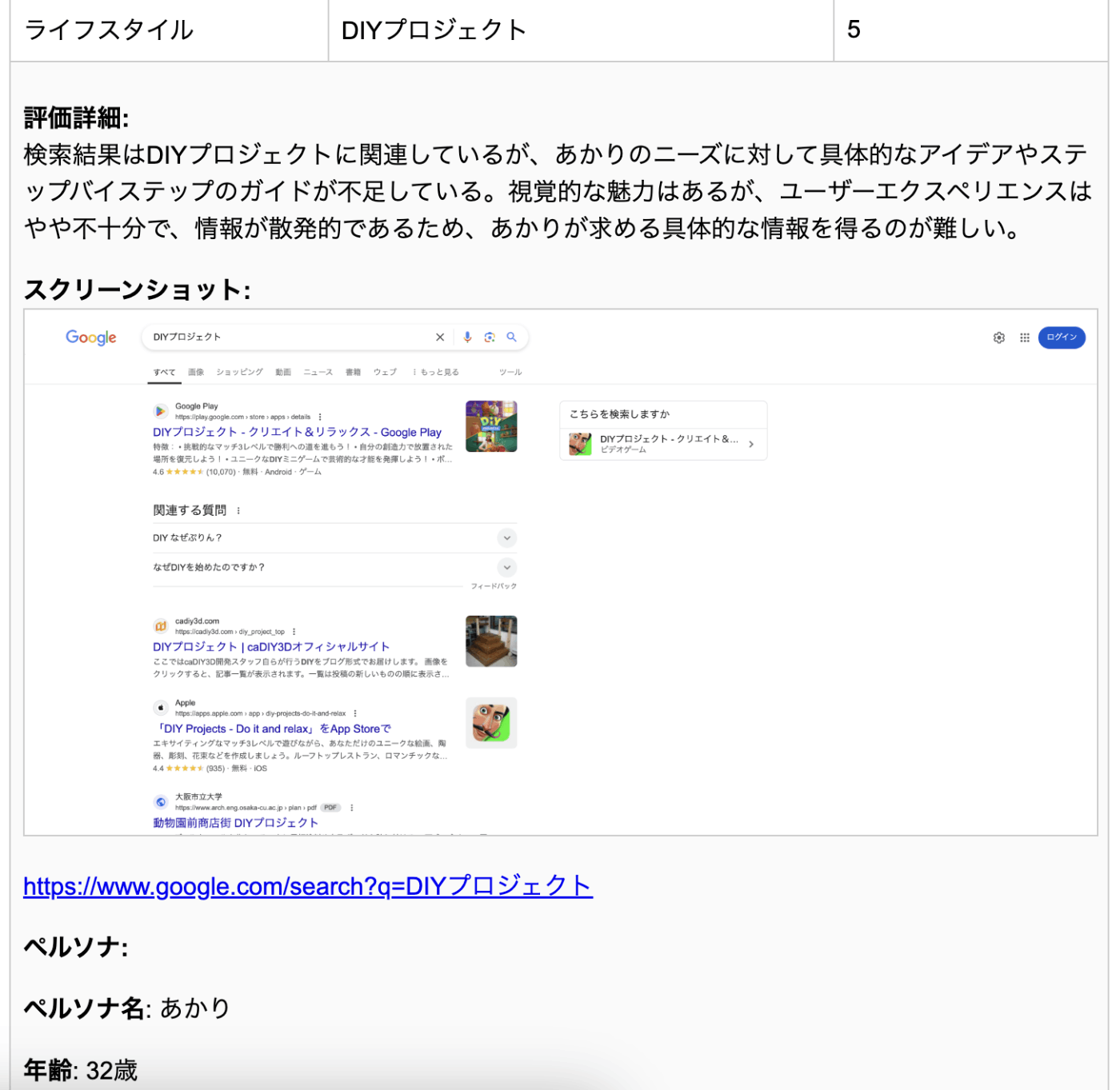
キーワードの評価詳細 (一部)
DIYプロジェクト

ブロックチェーン技術

YouTube
動画検索に特化しており、サムネイルや関連動画の表示方法が特徴的です。
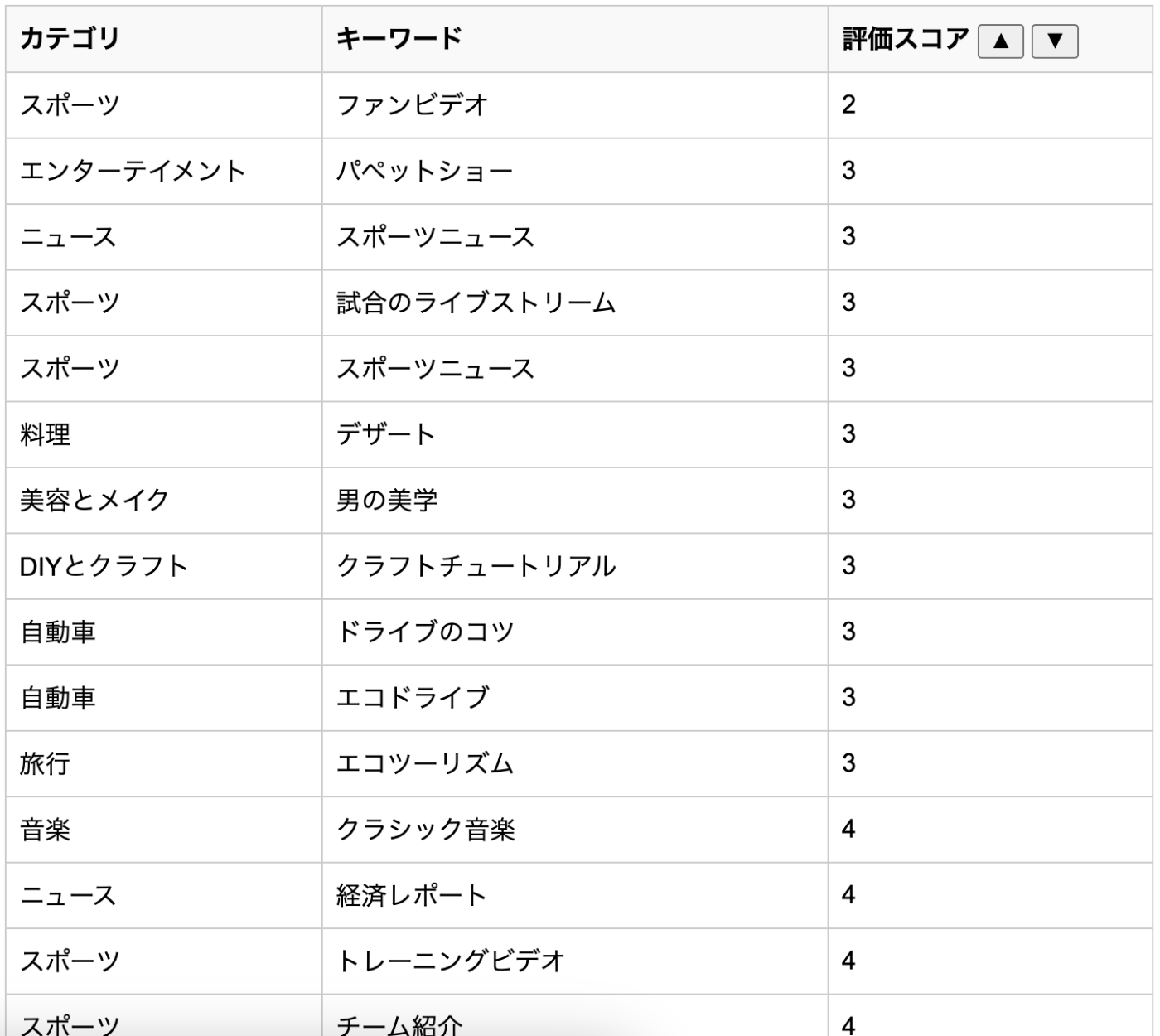
キーワード別評価 (低い順、一部)
キーワードの評価詳細 (一部)
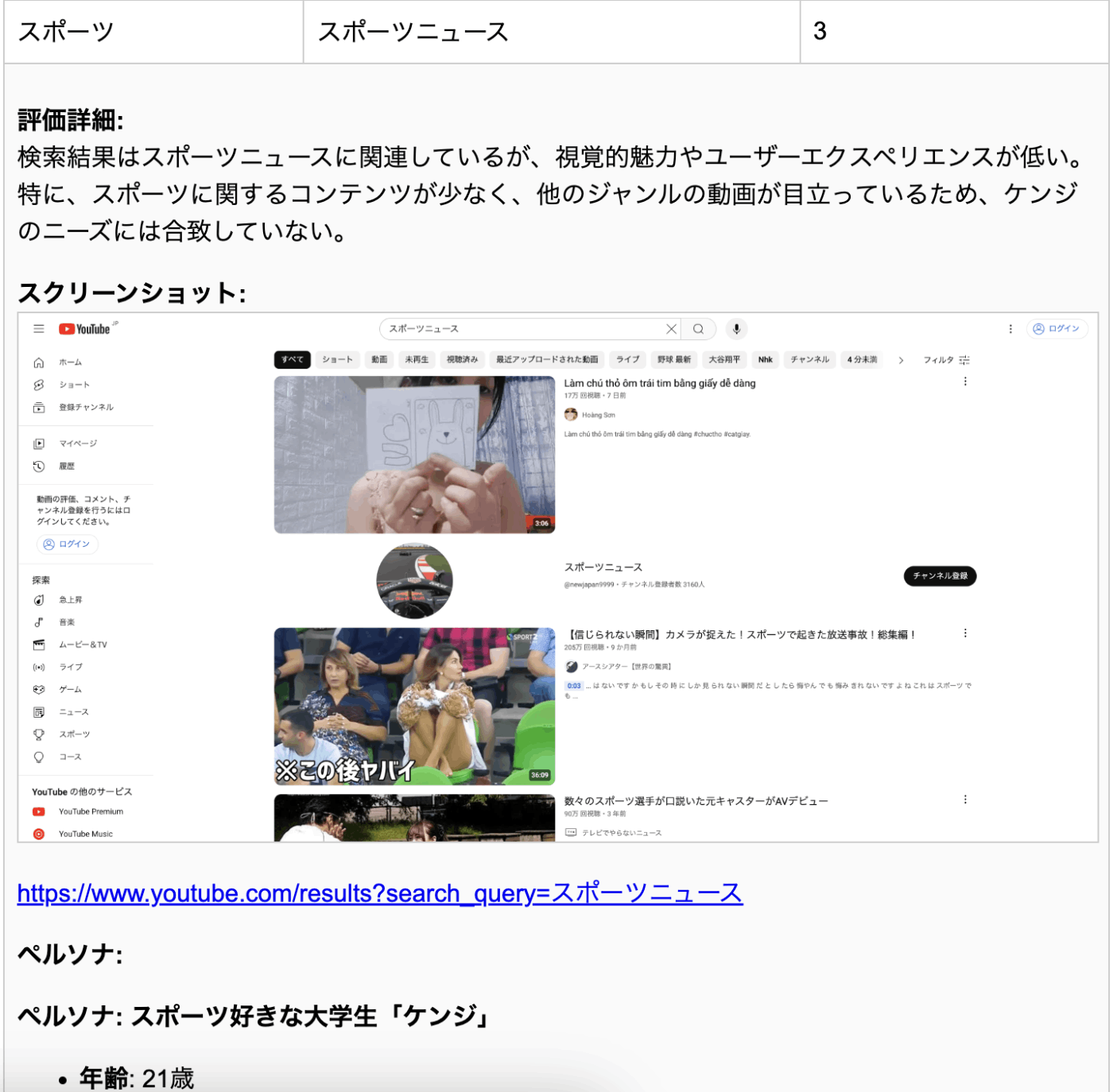
クックパッド
レシピ検索サイトであり、料理画像や手順の表示が重要となります。
キーワード別評価 (低い順、一部)

キーワードの評価詳細 (一部)
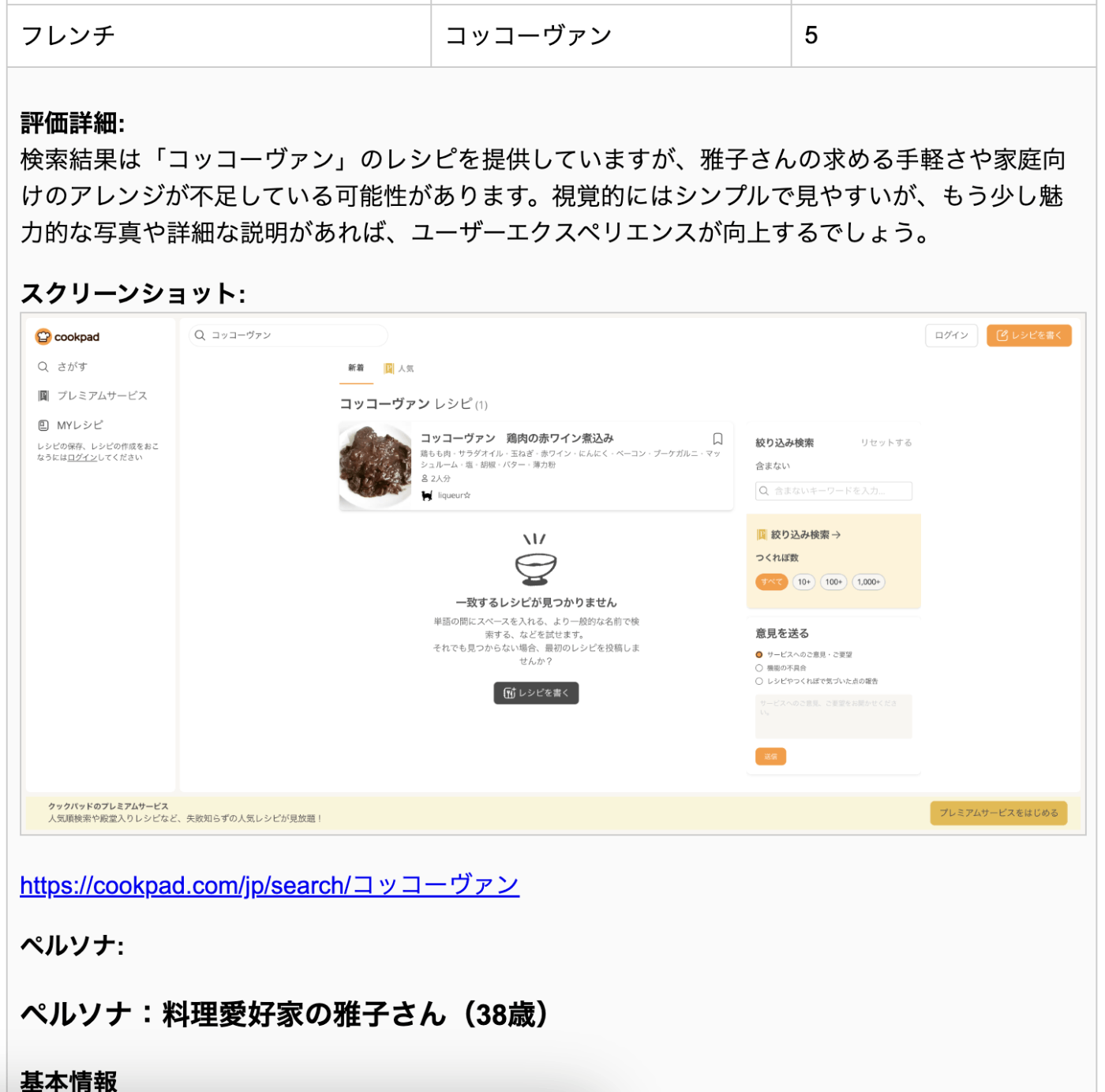

国会図書館サーチ
専門的な資料検索が可能で、情報の整理と提示方法に特徴があります。
キーワード別評価 (低い順、一部)
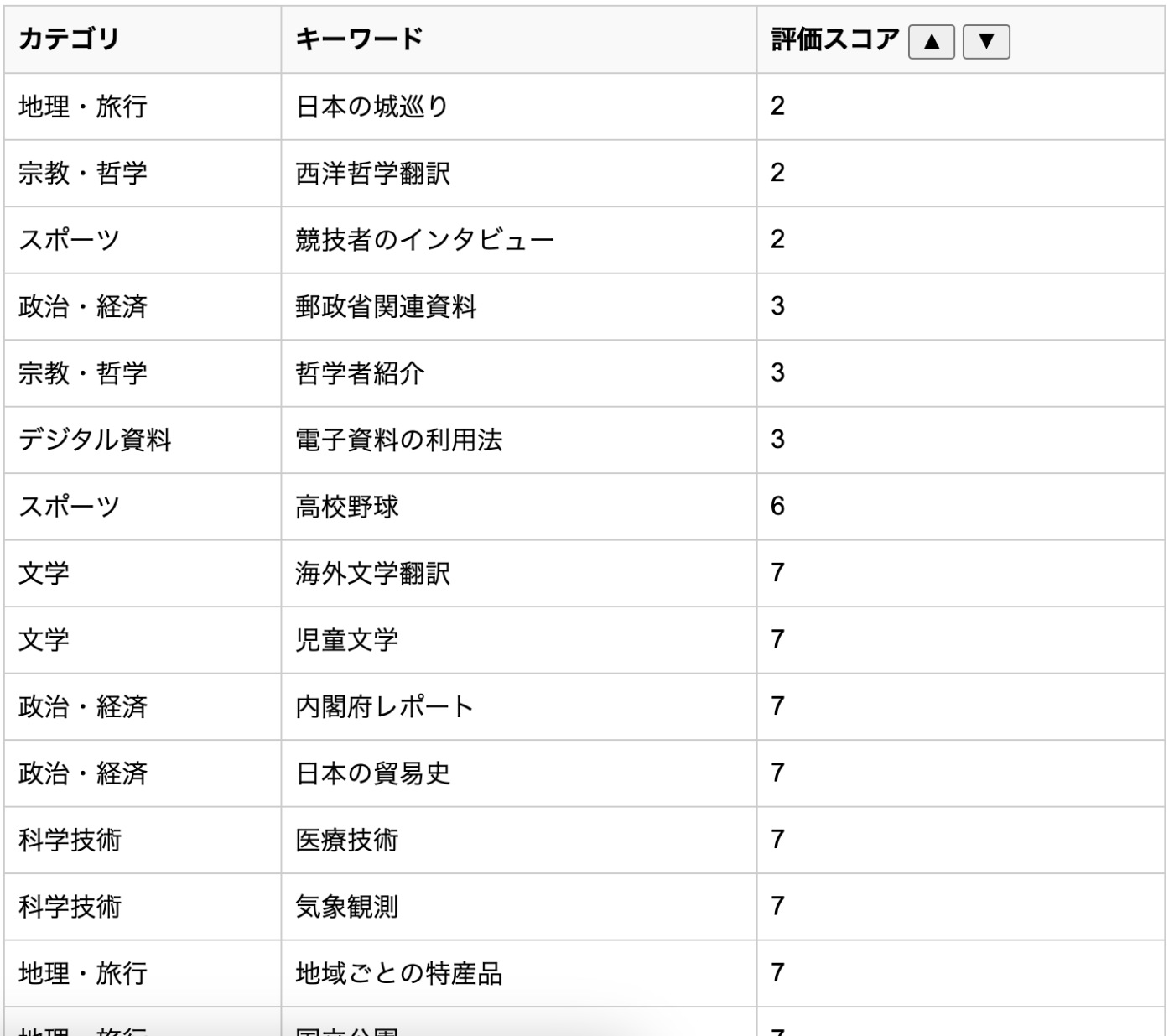
キーワードの評価詳細 (一部)
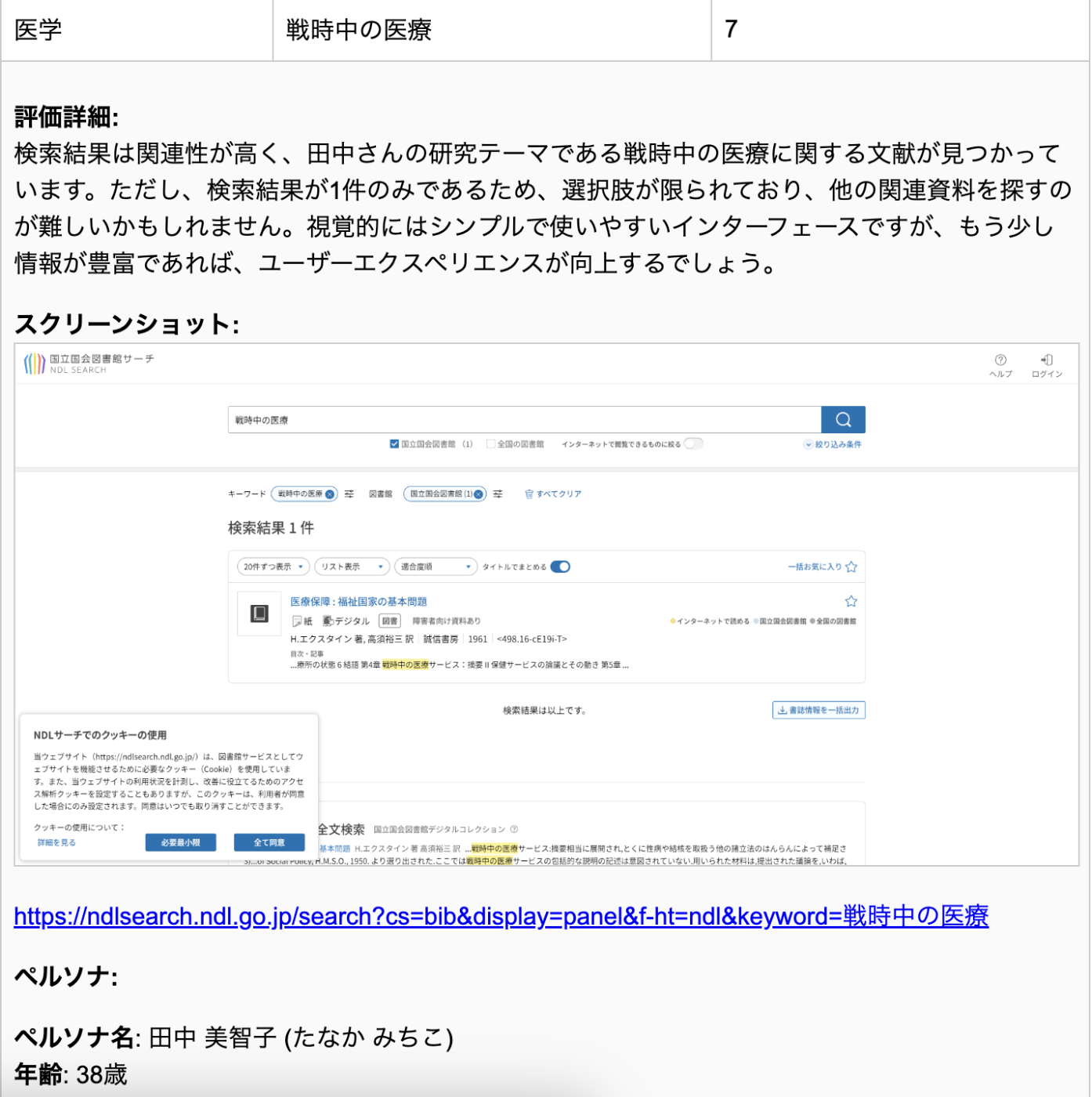

評価に利用したプロンプト詳細
以下に、各ステップで使用したプロンプトの詳細を紹介します。
1. キーワード生成のプロンプト
model="gpt-4o"
prompt = f"以下のWebサイトの検索結果について評価を行います。そのWebサイトで検索されるであろうコンテンツの10〜20カテゴリを検討し、それぞれのカテゴリに関連する10〜30の実際にサイト内で検索されそうなキーワードを提案してください。キーワードの選定にあたっては架空のペルソナを想定し、想定ペルソナが実際にサイト内で検索するであろうクエリを生成してください。各カテゴリ内のクエリは、ビッグワードからテールワード(明確なニーズに基づく複数キーワードで構成されるクエリや具体的な商品名のクエリなど)までバランスよく生成してください。\nサイト情報:タイトル「{title}」、説明「{description}」"
2. ペルソナ生成のプロンプト
model="gpt-4o-mini"
persona_prompt = f"以下のWebサイトで、キーワード「{keyword}(カテゴリ:{cateogry})」を検索する典型的なユーザーのペルソナを作成してください。アウトプットはペルソナの記述のみを含めること。\nサイト情報:タイトル「{title}」、説明「{description}"
3. 検索結果評価のプロンプト
model="gpt-4o-mini"
prompt = f"以下のユーザーのペルソナとスクリーンショットに基づいて、検索結果を0〜10で評価してください。評価基準は関連性、視覚的魅力、ユーザーエクスペリエンスです。\nペルソナ:{persona}"
(スクリーンショット画像を別途添付)
結論・まとめ
本記事では、大規模言語モデル(LLM)を活用して、検索結果の「見た目」や「雰囲気」を客観的に評価する手法を提案しました。具体的には、キーワードとペルソナを生成し、LLMの画像解析機能を用いて視覚的な検索結果ページを評価することで、主観的になりがちなUX評価を定量化しました。
この手法の主なメリットは以下の通りです。
- 客観性の向上:機械的な評価により、評価者の主観に左右されない結果を得ることができます。
- 効率性の向上:大量のキーワードやページを自動的に評価でき、時間とコストの削減につながります。
- 改善点の明確化:具体的なスコアやフィードバックにより、どの部分を改善すべきかが明確になります。
一方で、以下の課題も存在します。
- 特定コンテクストでの評価:1つのキーワードには通常、複数のコンテクストが存在します。この評価方法で評価できるのは複数考えられる1つのコンテクストのみなため、より正確な評価を行うためには1つのキーワードに対して複数のコンテクストを検討し、その総合評価を行う必要があります。
- ログイン情報の利用:現代的なサービスではパーソナライズされている場合が多く、より正確に評価するためにはペルソナだけでなく会員情報とログインが必要です。
検索結果の「見た目」はユーザーの第一印象を左右する重要な要素です。本手法は、LLMを活用した新たなUX評価のアプローチとして、ウェブ開発やデザインにおける大きな可能性を秘めています。今後、この手法を活用し、より良いユーザー体験の提供に役立てていきたいと考えています。
Discussion