【サーベイ】大規模言語モデル時代の「データ中心の自動運転モデル」
私は自動車業界に関わり、自動運転に関する研究に関わっており、その中で非常に興味深い Survey 論文を見かけました。
こちらは、「データ中心の自動運転技術」にフォーカスして、歴史的な流れから自動運転の手法について様々な角度からピックアップしている論文です。しかし、こちらの論文だけを読んでいると、派生する論文なども読む必要があり、前提知識が求められてしまったので、自動運転関連の近年の取り組みに関する論文について特に私が着目しているものを中心に要約していきます。翻訳や解釈の正確さを保証するものではありませんので、適宜原文と照らし合わせてご確認いただければと思います。
また、内容はさまざまな論文から引用しており、都度引用論文を明記しております。私個人の解釈については私の意見であることも文章中に明記しております。
Introduction
現在、自動運転アルゴリズムの性能には限界があり、限界を克服する鍵は「データ中心の自動運転技術」にあるとされています。
この「データ中心」というところが非常に重要なキーワードになっていまして、従来は、データセットが固定されていてその中の学習方法で強いモデルを作っていくというような方法でモデルの精度を上げていくというようなイメージがあるのではないでしょうか。例えば、Kaggleなんかはまさにその形式ですが、データセットの方は固定されていて、学習手法だったりを工夫することでモデルの精度を上げていく。というようなものになっています。
「データ中心」の世界では、学習方法の方が固定されていて、用意するデータを高品質かつ大量にすることでモデルの精度を上げていくという考え方です。
実際の世界では、学習の手法よりも学習に用いるモデルの方がデータの精度に大きく寄与する。ということが冪乗則で示唆されているのではないかと思います。
大規模言語モデルのみならず、自動運転の世界でも「データ中心」のアプローチが近年取り入れられております。
特に実世界の運転作業で問題となるのがこちらの論文( https://arxiv.org/pdf/2202.11233 )で言及されている、ロングテールの問題です。
実世界の交通環境には、滅多に起こらないが対応には高度な判断能力が求められる。このような稀な状況はトレーニングデータに含まれず、結果的に適切な対応を取れないモデルとなる可能性が高くなります。
また、別の論文( https://arxiv.org/pdf/2311.16038 )では、1000億マイルの走行距離がビッグデータとして必要であるとも示唆されています。しかし実際にはこれだけのデータを用意しそれを学習に活用するのは現実的ではありません。
では、先ほどから言及しているロングテール分布の問題をどのように解決するのでしょうか。
アプローチ1: 自動運転用データセットと生成AI
知らない状況/コーナーケースに遭遇すると、ADアルゴリズムは信頼性がなくなり、誤った決定を下す可能性があります。しかし、そのようなケースはでは極めてまれであり、実世界から十分な量の学習データを取得するのが現実的ではありません。ここで白羽の矢が立ったのが、自動運転データセットの進歩です。
アプローチ2: 閉ループ駆動型アプローチ
ロングテール分布の問題を自動的に緩和することに重点を置いた、閉ループデータ駆動型アプローチも現代で非常に注目されているアプローチです。
閉ループデータ駆動型アプローチとは、システムの出力が入力に直接フィードバックされ、継続的にデータを収集・分析・学習することで、システムの性能を向上させる手法です。自動運転の文脈では、車両の実際の走行データを常に収集し、それを基にAIモデルを改善し続けるプロセスを指します。
自動運転用データセットと生成AI
自動運転データセットの進化は、この分野における技術の進歩と野心の高まりを反映しています。過去20年間でセンサー技術、計算能力、高度な機械学習アルゴリズムの進歩により、大きな前進がありました。ディープラーニングの力を得て、コンピュータビジョンベースの手法がインテリジェントな知覚を支配してきました。ディープ強化学習とその変種が、インテリジェントな計画立案と意思決定に重要な改善をもたらしました。最近では、大規模言語モデル(LLM)と視覚言語モデル(VLM)が、シーン理解、運転行動の推論と予測、インテリジェントな意思決定において高い正確性を示し、自動運転の将来的な発展に新たな可能性を開いています。
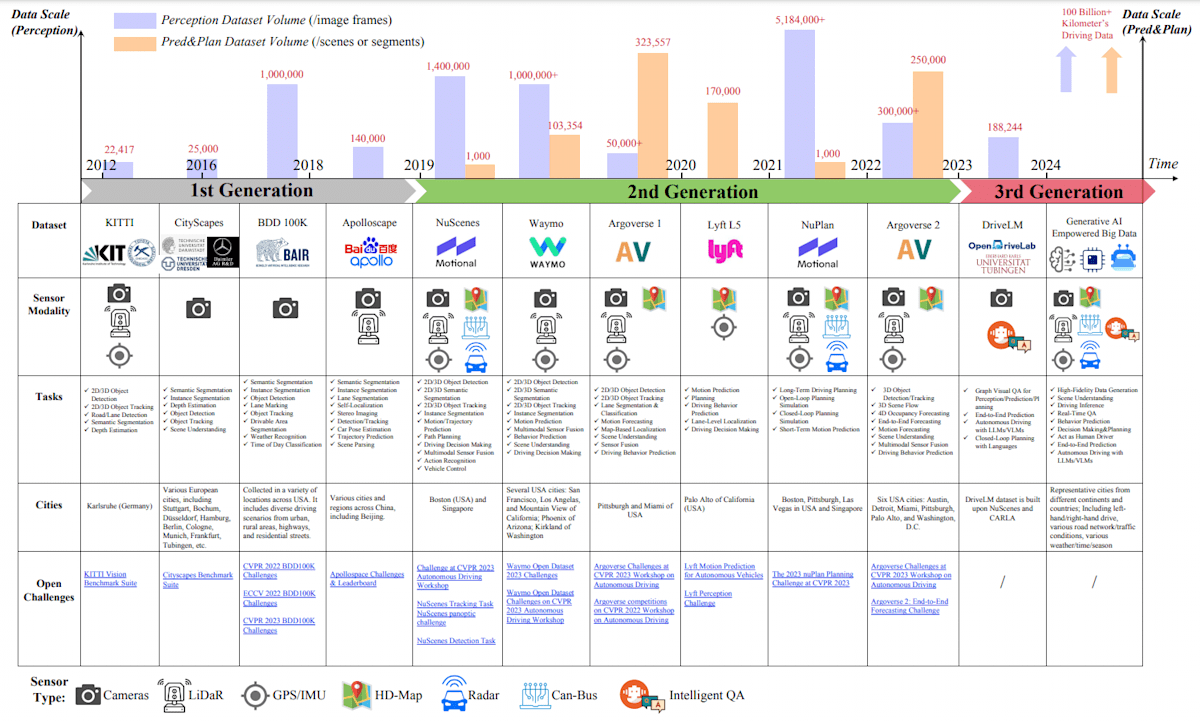 図の出典: Xu et al. "State-of-the-art Autonomous Driving Datasets: Classification and Development." arXiv preprint arXiv:2401.12888 (2023).
図の出典: Xu et al. "State-of-the-art Autonomous Driving Datasets: Classification and Development." arXiv preprint arXiv:2401.12888 (2023).
図の説明: この図は、主要な世代を特徴とするオープンソース自動運転データセットの発展を包括的に示しています。センサーモダリティ、適切なタスク、データセット収集場所、関連する課題が強調されています。
こちらの論文では、データセットは3つの世代に分類できると主張します。
2012年に始まった初期段階である第1世代は、KITTIやCityscapesが主導し、知覚タスク用の高解像度画像を提供し、視覚アルゴリズムの進捗を評価する上で基礎となりました。第2世代に進むと、NuScenes、Waymo、Argoverseなどのデータセットが、車載カメラ、高精細マップ(HD-Map)、LiDAR、レーダー、GPS、IMU、軌跡、周辺エージェントのデータを統合したマルチセンサーアプローチを導入しました。これは、包括的な運転環境モデリングと意思決定プロセスに不可欠でした。
最近になると、NuPlan、Argoverse 2、Lyft L5が、前例のないデータ規模を提供し、最先端の研究に適した環境を整備することで、大きなインパクトを与えています。これらの大規模かつマルチモーダルセンサーを統合したデータセットは、知覚、予測、計画タスクのアルゴリズム開発に不可欠であり、最先端のEnd2Endまたはハイブリッド自動運転モデルの道を開いてきました。
KITTI
KITTIデータセットは、自動運転技術の研究開発のために作成された包括的なコンピュータビジョンデータセットで豊富なキャリブレーション済み・同期済みデータを提供します。2012年にKarlsruhe Institute of TechnologyとToyota Technological Institute at Chicagoの共同で開発されました。
ステレオビジョン、オプティカルフロー、ビジュアルオドメトリ、3D物体検出、3D物体追跡、SLAMのベンチマークを開発する用途に重点を置いています。
KITTIデータセットには以下のようなデータが含まれています:
- グレースケールおよびカラーのステレオ画像シーケンス
- 3Dベロダインポイントクラウド
- GPS/IMUデータ
- カメラキャリブレーション情報
- 3D物体トラックレットラベル
7,481枚の学習用画像に3Dバウンディングボックスでアノテーションが付けられています。
訓練セット6,347枚、検証セット423枚、テストセット711枚に分割されています。
画像、物体の位置、寸法、回転角度などの詳細な特徴量が提供されています。
自動運転分野の標準的なベンチマークデータセットとして確立されています。
Creative Commons Attribution-NonCommercial-ShareAlike 3.0ライセンスの下で提供されています。
NuScenesデータセット
NuScenesデータセットは、自動運転技術の研究開発において画期的な貢献をした包括的なマルチモーダルデータセットです。以下、その特徴と重要性について詳しく説明します。
NuScenesは、自動運転車両の完全なセンサースイートからのデータを提供する初めての大規模データセットです。具体的には、6台のカメラ、1台のLiDAR、5台のレーダー、GPS、IMUからのデータが含まれており、自動運転技術の研究者たちに都市部の複雑な運転状況を研究する機会を提供しています。
このデータセットは1,000のシーンで構成されており、各シーンは20秒の長さを持ちます。これらのシーンは、ボストンとシンガポールという2つの異なる都市環境から慎重に選択されており、多様な運転操作と独特の交通課題を捉えています。この多様性は、自動運転システムの堅牢性と汎用性を向上させるのに役立ちます。
NuScenesの特筆すべき点の一つは、その豊富なアノテーションです。23のクラスと8つの属性に対して3Dバウンディングボックスで完全にアノテーションが付けられています。これは、前身のKITTIデータセットと比較して7倍もの注釈数を誇ります。この豊富なアノテーションにより、より精密な物体検出や追跡のアルゴリズムの開発が可能となります。
NuScenesの特徴は、単なる知覚タスクにとどまらない点です。このデータセットは、知覚、運動予測、意思決定、計画など、自動運転に関わる全体的なタスクをカバーしています。これにより、エンドツーエンドの深層学習ベースのパイプラインの開発が可能となり、自動運転技術の研究をより包括的に進めることができます。
NuScenesのセンサーデータは非常に詳細です。例えば、80mの放射状距離でも最大100のLiDARポイントを含み、3mでは最大12,000のLiDARポイントを含みます。同時に、レーダーデータは10mで最大40の返信、50mで10の返信を含み、その範囲はLiDARをはるかに超えて200mに達します。この豊富なセンサーデータにより、より正確な環境認識と物体検出が可能となります。
NuScenesデータセットは7つの異なるカテゴリの物体にアノテーションを付けています。これらのアノテーションの数は、センサーからの距離が増すにつれて減少します。この特性は、実際の自動運転シナリオでの物体検出の課題を反映しており、より現実的なアルゴリズムの開発を促進します。
NuScenesの公開以来、自動運転コミュニティから大きな関心を集めています。多くの研究者がこのデータセットを活用し、3D物体検出、マルチエージェント予測、歩行者位置推定、天候増強、移動点群予測など、様々な分野で研究を進めています。特に、レーダーデータを提供する唯一のアノテーション付き自動運転データセットとして、レーダーとセンサーフュージョンを用いた物体検出の研究を促進しています。
NuScenesは、開発キット、評価コード、分類法、アノテーター指示、データベーススキーマを公開し、業界全体の標準化に貢献しています。これにより、異なるデータセット間の互換性が向上し、研究の再現性と比較可能性が高まっています。
NuScenesデータはCC BY-NC-SA 4.0ライセンスの下で公開されており、非商用の研究目的であれば誰でも利用可能です。これにより、幅広い研究者や開発者がこのデータセットにアクセスし、自動運転技術の発展に貢献することができます。
実際に私も NuScenes のデータセットを取得してみたのですが、Tutorial の手順通りに簡単に取得できました。
# !mkdir -p /data/sets/nuscenes # Make the directory to store the nuScenes dataset in.
# !wget https://www.nuscenes.org/data/v1.0-mini.tgz # Download the nuScenes mini split.
# !tar -xf v1.0-mini.tgz -C /data/sets/nuscenes # Uncompress the nuScenes mini split.
# !pip install nuscenes-devkit &> /dev/null # Install nuScenes.
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)
DriveLM データセット
こちらのDriveLMデータセットは、非常に注目されている興味深いデータセットです。
3世代目の自動運転ビッグデータのパイオニア的存在と論文ではふれられています。
DriveLM の元論文はこちらです。
こちらの論文が、3 世代目のデータセットについて説明するのに最もわかりやすかったので、こちらの論文の内容をようやくしながら3世代目データセットについて説明します。
まず最初に用意されているデータセットとはどのようなデータセットなのでしょうか。
論文内では、Visual Question Answeringというふうに名付けられており、質問と回答(QAペア)がグラフ構造で接続されています。QAペアがノードとなり、オブジェクト間の関係がエッジとなっているようなデータ構造です。質問の内容としては、Perception(知覚)、Prediction(予測)、Planning(計画)の段階に分かれており、用意された画像に対して、この 3 P のアノテーションが付与されるような形で提供されているデータセットになります。
実際に論文内で記されているデータセットについて具体的に紹介すると、たくさんの画像の中から以下の画像についているアノテーションについて説明します。
 図の出典: DriveLM Driving with Graph Visual Question Answering
図の出典: DriveLM Driving with Graph Visual Question Answering
一番上の Perception ノードには
Q: What are the objects worth noting in the current scenario?
A: There is a van , a sedan and a pedestrian in front of the ego car.
そこに接続されている Prediction ノードには、
Q: Where might the van, the sedan and the pedestrian move in the future?
A: Those objects may move to the rightlane, cross the ped-crossing, etc..
さらにそのノードに接続されている Planning ノードには
Q: What are the safe actions of the ego car considering those objects?
A: The ego car should wait for the pedestrian and the sedan, then turn right.
というようなQAペアが入っています。
また、未来の出来事を推論するために、多くの「もし〜だったら」という形式の質問が含まれています。
このようなQAノードが連なったグラフのことを DriveLM では、Graph Visual Question Answering というように呼んでおり、このデータセットの先駆者的な存在となっております。
では、DriveLM データセットはどのように作成されたのでしょうか。
実は、こちら大部分は手作業でのアノテーションが行われています。
DriveLM のデータセットには、DriveLM-nuScenesとDriveLM-CARLAの二種類からなっており、それぞれ作られ方が異なるので、それぞれ整理します。
DriveLM-nuScenes
DriveLM-nuScenesデータセットの作成プロセスは、自動運転シーンの理解と分析に重点を置いた綿密な手順で構成されています。このプロセスは、単なるデータ収集にとどまらず、自動運転システムの開発に不可欠な高品質なデータセットを生成することを目的としています。以下、その詳細なプロセスと重要性について説明します。
-
キーフレームの選択
DriveLM-nuScenesデータセットの作成プロセスの第一段階は、ビデオクリップからキーフレームを選択することです。この段階は非常に重要で、以下の点に注意して行われます:
選択基準: キーフレームの選択は、自車の動きに変化がある瞬間を基準に行われます。具体的には、車線変更、急停止、停止後の発進などの動作が含まれる場面が選ばれます。
目的: この選択プロセスにより、自動運転システムにとって最も重要で情報量の多いフレームを特定することができます。これにより、データセットの効率性と有効性が大幅に向上します。
重要性: キーフレームの適切な選択は、後続の分析や学習プロセスの基礎となります。自動運転車両の動作や周囲の環境の変化が最も顕著に表れるフレームを選ぶことで、より豊富な学習機会を提供します。 -
重要なオブジェクトの選択
キーフレームが選択された後、次のステップは各フレーム内の重要なオブジェクトを特定することです:
選択プロセス: アノテーターは、選択されたキーフレームの6方向の周囲画像を分析し、自車の行動に影響を与える可能性のあるオブジェクトを選びます。
対象オブジェクト: 重要なオブジェクトには、他の車両、歩行者、自転車、交通信号、道路標識、障害物などが含まれます。これらは自動運転車両の意思決定に直接影響を与える要素です。
選択基準: オブジェクトの選択は、その位置、動き、自車との相対的な関係などを考慮して行われます。例えば、道路を横断しようとしている歩行者や、自車の進路に入ろうとしている車両などが重要なオブジェクトとして選ばれます。
オブジェクト数: 各キーフレームには最小3つ、最大6つの重要オブジェクトが選択されます。この範囲は、シーンの複雑さを適切に表現しつつ、データの管理可能性を保つために設定されています。
アノテーション形式: 選択されたオブジェクトは「cタグ」というラベルで識別されます。このタグの形式は<c,CAM,x,y>で、cは識別子、CAMはオブジェクトの中心点が位置するカメラ、x,yは該当カメラの座標系における2Dバウンディングボックスの水平・垂直座標を表します。
Perception QAの一部はnuScenesおよびOpenLane-V2のGround Truthラベルを用いていますが、残りのQAペアは人手によるアノテーションが行われます。つまり、ほとんどのQAペアは人力でアノテーションをしています。そのため、アノテーションの品質を確保するために、厳密な品質チェックが複数回にわたって行われます。
DriveLM-CARLA
こちらは、CARLAというシミュレータを使用し、エキスパートモデルを用いてデータを収集します。
そもそもCARLAとは何かという話になると思います。
CARLAはオープンな自動運転のシミュレーターで、スペインにあるCVCにて開発されています。
内部的には、Unreal Engine 4が使われており非常に高画質なシミュレータパッケージとなっております。
また、サーバークライアントモデルを採用しており、操作にはPythonのクライアントを利用して操作することとなります。
以下のようにスクリプトで、車両、歩行者、障害物などを設置することができ、再現性のあるコードを容易に作成できるところも魅力的です。
import carla
def spawn_test_objects(world):
blueprint_library = world.get_blueprint_library()
# 車両
vehicle_bp = blueprint_library.find('vehicle.tesla.model3')
spawn_point = random.choice(world.get_map().get_spawn_points())
vehicle = world.spawn_actor(vehicle_bp, spawn_point)
# 歩行者
walker_bp = blueprint_library.find('walker.pedestrian.0001')
walker_spawn_point = carla.Transform(spawn_point.location + carla.Location(x=10, y=0), spawn_point.rotation)
walker = world.spawn_actor(walker_bp, walker_spawn_point)
# 障害物
obstacle_bp = blueprint_library.find('static.prop.streetbarrier')
obstacle_spawn_point = carla.Transform(spawn_point.location + carla.Location(x=20, y=2), spawn_point.rotation)
obstacle = world.spawn_actor(obstacle_bp, obstacle_spawn_point)
return vehicle, walker, obstacle
また、CARLA は RGBカメラ、深度カメラ、セマンティックセグメンテーションなど多様なセンサーに対応しています。
こちらの記事では、以下のようなコードで、センサーをセットしています。
#manual_control.pyを編集する
#def set_sensorの中身を変える
#適当なスペックのカメラを作る
def set_sensor(self, index, notify=True, force_respawn=False):
#CARLAシミュレータの中で登場するすべての物体の設計図を読み込む
blueprint_library = self._parent.get_world().get_blueprint_library()
#設計図の中からカメラを読み込む
camera2 = blueprint_library.find('sensor.camera.rgb')
# 画像の解像度を設定する
IM_WIDTH = 640
IM_HEIGHT = 480
# カメラの解像度、FOV、カメラの名前を設定する
camera2.set_attribute('image_size_x', f'{IM_WIDTH}')
camera2.set_attribute('image_size_y', f'{IM_HEIGHT}')
camera2.set_attribute('fov', '110')
camera2.set_attribute('role_name', 'front_lookdown_camera')
# カメラの取り付け位置を設定する、ピッチングもつける
spawn_point1 = carla.Transform(carla.Location(x=2.5, z=0.7), carla.Rotation(pitch=-30.0, yaw=0, roll=0))
# カメラを手動操縦の車両に取り付ける
self.front_camera_fix = self._parent.get_world().spawn_actor(camera2, spawn_point1, attach_to=self._parent)
また、逆光、大雨、曇りなど様々な条件も再現可能であることが特徴的です。
DriveLM-CARLA では、 CARLA 0.9.14 を使って [Leaderboard 2.0フレームワーク](Leaderboard 2.0フレームワーク)でデータを収集しています。
Leaderboard 2.0フレームワークは、CARLAシミュレーター上で自動運転エージェントを開発・評価するためのプラットフォームです。複数のルートや交通シナリオでエージェントの挙動を評価でき、トレーニング用、検証用、テスト用のルートが用意されています。
そして、最新のLeaderboard 2.0には、前身のLeaderboard 1.0に比べて、多くの新しい運転シナリオが含まれています。また、DriveLMでは、Leaderboard 2.0の新しい課題に対処できる新しい専門家アルゴリズム、PDM-Liteを構築しました。PDM-Lite(Privileged Driver Model-Lite)は、CARLA自動運転シミュレーター用に開発された最先端のルールベース特権ドライバーモデルです。端的に言えば、CARLA上での自動運転エージェントからキーフレームをサンプリングし、スケーラブルなQAデータセットを生成をすることができるモデルです。
PDM-Liteは、先行車両、歩行者、停止標識、または信号機に基づいて目標速度を得るためにIntelligent Driver Model(IDM)を使用しています。PDM-Liteは、公式のCARLAの検証ルートで44%Driving Scoreを改善しました。
DriveLM-CARLAデータセットを収集するために、都市部、住宅街、田園地帯にルートを設定し、それらのルートでPDM-Liteを実行しました。この過程で、必要なセンサーデータを収集し、キーフレームをサンプリングし、オブジェクトやシーンに関する特権情報に基づいて関連するQAを生成します。
4FPSでデータとラベルを生成し、シミュレータから抽出した情報に基づき、手作りの文テンプレートを使ってQAを作成しています。正確な質問とそのグラフ構造については補足資料をご覧ください。私たちのプロセスは、CARLAでルートとシナリオ設定を定義するだけで、その後の手順を自動的に実行できるため、自動的に大量のQAが収集できるところがメリットです。実際に160万件のQA(明確なスケーリングレシピあり)を含むDriveLM-CARLAは、既存のベンチマークの中で総テキスト量が最大の運転言語ベンチマークです
データ量について
DriveLM-nuScenesは、34,149フレームのデータを含んでおり、合計で約36万件のQAペアが含まれています。QAペアの比率は、1フレームあたり平均約10.6個のQAペアがあります。
DriveLM-CARLAは、183,373フレームのデータを含んでおり、約250万件のQAペアが含まれています。QAペアの比率は、1フレームあたり平均約13.6個のQAペアがあります。
合計すると、DriveLM全体で217,522フレームのデータを含んでおり、約280万件のQAペアを含んでいます。
DriveLM-Metrics
GVQAタスクにおけるDriveLM-Metricsの評価方法について、DriveLM-Metricsは、モーションM、行動B、P1-3の5つの要素から構成されています。
モーションM(Motion)の評価:
モーションの予測精度を評価するために、nuScenesやWaymoベンチマークで使用されている標準的な指標であるADE(平均変位誤差)、FDE(最終変位誤差)、および予測軌跡における衝突率を用いています。
行動B(Behavior)の評価:
行動予測の精度は、分類accuracyで評価されます。さらに、全体のaccuracyをsteeringとspeedの2つの要素に分けて評価します。
P1-3(Perception, Predeiction, Planning)の評価:
P1-3の性能は、2つの指標を用いて評価されます。
a) SPICE: 画像キャプショニングやVQAで一般的に使用されているmetricで、予測したテキストと正解のテキストの構造的な類似度を計算します。ただし、意味的な意味は無視されます。 b) GPT Score: 予測した回答と正解の回答の意味的な一致度を測定するために使用されます。具体的には、質問文、正解の回答、予測した回答、およびその回答に対する数値スコアを求める指示を含むプロンプトをChatGPT-3.5に入力します。ChatGPTから返されたテキストから数値スコアを抽出し、スコアが高いほど意味的な正確性が高いことを示します。
DriveLM-Agentモデル
DriveLM-Agentは、自動運転タスクにおいてGVQA(Graph Visual Question Answering)を活用した新しいアプローチを提案するモデルです。このモデルは、DriveLM-Dataデータセットを用いて構築され、自動運転の全スタックを言語モデルの枠組みで実現することを目指しています。
DriveLM-AgentはBLIP-2をベースモデルとしており、LoRA(Low-Rank Adaptation)技術を用いてファインチューニングされています。モデルの主な特徴は以下の通りです:
グラフ構造化QA: 質問-回答(QA)ペアがグラフ構造で連結されており、論理的な依存関係を表現しています。各QAはトークン"Question:"と"Answer:"で区切られ、さらに特殊トークン"<sep>"で他のQAと分離されます。このエンコーディング戦略により、モデルはそれぞれのQAの文脈と構造を維持しながら、全体のコンテキストを考慮できます。この連結されたQAシーケンスは、BLIPの画像ビジョンエンコーダとBLIPの言語エンコーダの両方に通されます。得られた画像特徴と言語特徴は結合され、行動分類ヘッドに送られます。このヘッドは、車両の望ましい動作を記述する自然言語のテキストを生成します。
階層的推論: Perception (P1), Prediction (P2), Planning (P3), Behavior (B), Motion (M)の順に推論を行います。各段階で前の段階のQAペアをプロンプトのコンテキストとして利用します。
軌跡(trajectory)の離散化: 車両の軌跡(trajectory)を256の離散空間で表現し、言語モデルの語彙内のトークンに対応させています。これは、embeddingなどではなく、言語モデルの次トークン予測タスクとして扱われます。しかし、一般的なVLMを用いて細かな数値結果を出力しても精度は上がりません。ロボットの行動を扱うRT-2のアプローチを採用しています。つまり具体的に言えば、VLMのトークンを再定義しています。訓練データセットの軌跡の統計に基づき、ウェイポイントの座標を256のビンに分割します。次に、BLIP-2の言語トークナイザにおいて、各ビンに対応するトークンを再定義しています。そして、この新しい語彙でVLM(BLIP-2)をファインチューニングしています。
DriveLM の研究の意義に対する個人的な考察 - E2E 自動運転モデルに大規模言語モデルが活用される未来
DriveLMは確かに、DriveLM-Agentモデルがあり、E2E 自動運転モデルとして動作するものまで用意されています。この論文の今後の展開に対する記述では、閉ループ計画の設定についても言及されています。閉ループ計画の設定とは、この記事の最初に触れた2番目のアプローチです。
つまり、この論文では、Agentモデルについては改善の余地があるものと考えており、私もそのように考えています。DriveLMの本質的な提案はデータセットなのです。
DriveLMでは、 Graph Visual Question Answering 用いたデータセットを用意することでモデルを学習するスタイルを取り入れています。さらにそのデータセットを用意する手法についても詳しく論文内でも紹介されており、この記事では要約させていただきました。
一般的に運転モデルをトレーニングする際に様々なタスクを解かせることによって経路生成の能力が上がると考えられています。(冪乗則より)そのため、物体認識、移動予測、マップ認識などのVQAを使ってトレーニングをさせるためのデータセットが鍵を握るのです。
そして、時代は E2E の自動運転モデルに進んでいます。
こちらのブログでも、Tesla が E2E に舵を切っているという話が出ています。
Tesla AI Day 2021/2022 では、BEV 画像を生成する観点などについても触れられていました。
Tesla が考える世界観として、複数のカメラから受け取った情報として、空間をPerceptionする。つまり、BEVを作成することが第一ステップとして重要であり、高精度なBEVから次にPlannning/behaviorのステップに入っていきます。
とはいえ、最初のロングテールの話で話したように、実際の世界の運転にはエッジケースが多く存在します。滅多に起こらないことのデータを集めるのは極めて困難なのです。だからこそ常識を知っている、自分で考えられる人間のような汎用的な知能が求められるわけです。
そういった汎用的な知能として注目を浴びているのが、大規模言語モデルです。
言語モデルなので、言語を理解することが可能です。標識に書いてある文字も読めますし、人が歩いていると言ったらぶつかってはいけないとわかります。また、物理学としての常識も理解しています。車は瞬時には止まれません、止まるのに時間がかかります。速度が速ければ速いほど。
隣の車がウインカーを出していたら、割り込みたいという意図なので、譲ります。
人間は当然感覚として持っていますが、AIがこれまで感覚として持っていなかったものを持っているのが、Language Model の存在です。
DriveLMの研究がどうして注目を浴びているかというと、その言語モデルを学習するためのデータセットとして構築されているのが、 Graph Visual Question Answeringという仕組みだからです。
DriveLM-Agentモデルでは、プロンプトを使って推論を行なっていますが、極論推論はプロンプトを利用するかどうかは別問題だと思っています。embeddingモデルでも可能かもしれません。ただ、常識を知っている基盤モデルに運転の方法を教えるためのトレーニングセットとして、 Graph Visual Question Answeringがこの論文では提案されており、E2E自動運転のための大きな一歩であると私は捉えています。
要約すると、DriveLM-Agentモデルは本質ではなくて、LoRAを使って運転の仕方を言語を通じて教えるための方法として Graph Visual Question Answeringがある程度の成果を出したということがこの論文の価値と私は考えます。「データ中心の自動運転モデル」の時代が始まったのです。
UniAD と MultiTask Learning
CVPR Best Paper の衝撃
Drive LM の論文に関して、E2E 自度運転の未来について話しましたが、そもそも E2E 自動運転というのが一般的に実現できるのではないかと騒がれたきっかけとなった論文がおそらくこのUniADの論文、そして、Tesla AI Day での HydraNet の紹介あたりなのではないでしょうか。
UniAD の論文は、CVPR2023 で best paper になるほど印象的な論文で以下に Arxiv を記載します。
この論文での主張をざっくり説明すると、先ほどあげた E2E での学習するということを実現するためのフレームワークを考えたよというもので、
それによって研究レベルでも精度してとかなり高くなっているという結果が出ましたよと。言うものです。
この論文を初めて読んだときは、結構衝撃というか、私の中ではすごく印象に残っている論文で、
これまでテスラがE2Eに移行していますよと言っても、Pure な Transformer (いわゆるDeepでぽん)で直接的に経路出力というのはなかなか精度が出ないというのが数年前からわかっていました。
それがダメだからこそ、それまでは Modular ベースでもう少し現実的なタスクのモデルを組み合わせる手法が主流になっていたわけです。
ところが、この論文で提案されたフレームワークを利用することによって、E2E のDeep でぽんなモデルでModular ベースの手法を超える精度が出そうですよということが示唆されています。
どういうモデル構成にするとうまくできるのかが不思議だったんですが、UniAD というフレームワークは Tesla AI Day で出てる HydraNet の考え方を踏襲しながら単一のモデルをで実現していて、私も初めてこの論文に出会った時は、非常に大きな感銘を受けたものです。
Multi-Task Learning と HydraNet
HydraNet自体は Tesla AI Day にて紹介されたもので、Multi-Task Learning のようです。
MultiTask Learning というのは、カメラの入力に対して、Head をたくさん生やして、先ほど上がっていたような、Perception、Prediction、Planningというような直接経路を予測するタスク以外のタスクも同時に解かせます。ひとつのニューラルネットのモデルで同時に解くっていうようなやり方です。
特徴量を共有でき、タスクを簡単に増やせるというようなメリットがあります。そして、単一のモデルなので、「全て逆伝播できる」=「モデル全体を同時に学習できる」ということも大きなメリットです。
物体を検知したり、他の車や人が通りかかったりします。従わなければならない信号機や一時停止標識があります。車線標示には、その範囲内にとどまらなければならないというものがあります。これらは、車が理解しなければならない個々のタスクのほんの一例に過ぎません。それから、周囲の歩行者がこれからどこに向かって歩くのか、信号を渡るのか止まるのか、対向車は右折するのかしないのか、それを予測するというのも、車が理解しなければならないサブタスクです。それを一つのモデルに解かせるというのがHydraNetsのやり方です。
近年のLLM的な考え方に近いですね。さまざまなタスクを解くと色々なタスクが解けるようになる、汎化するような性質が見られています。
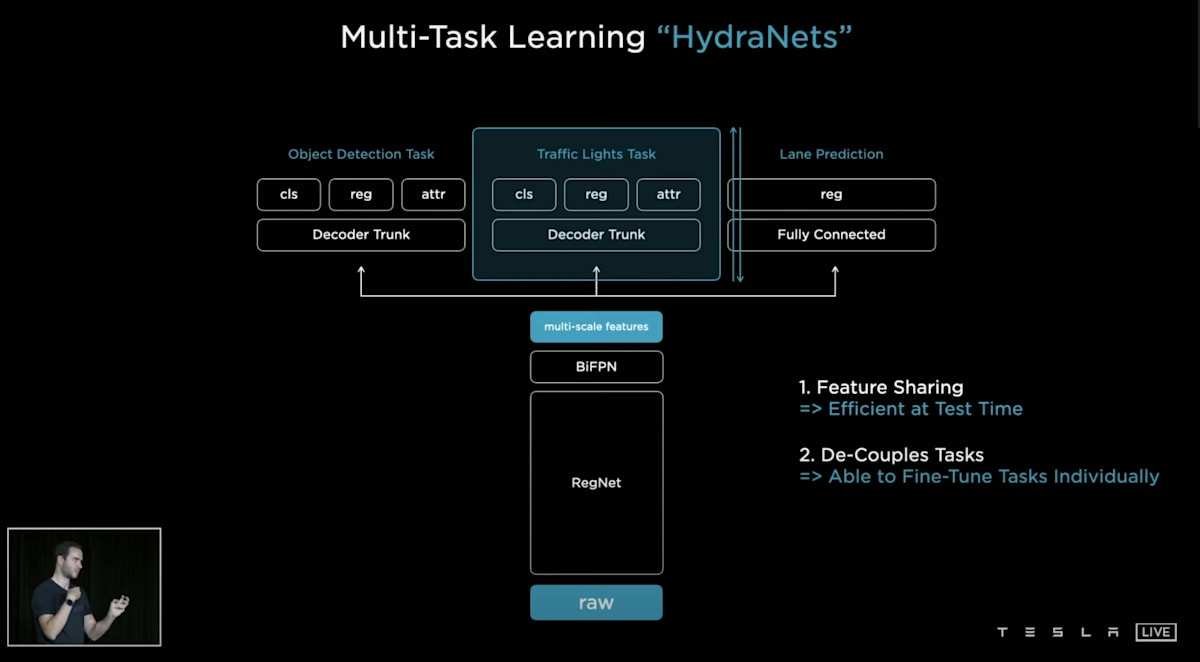
(https://driveteslacanada.ca/news/tesla-ai-day-simplified/ から引用)
UniAD
( https://arxiv.org/abs/2212.10156 から引用)
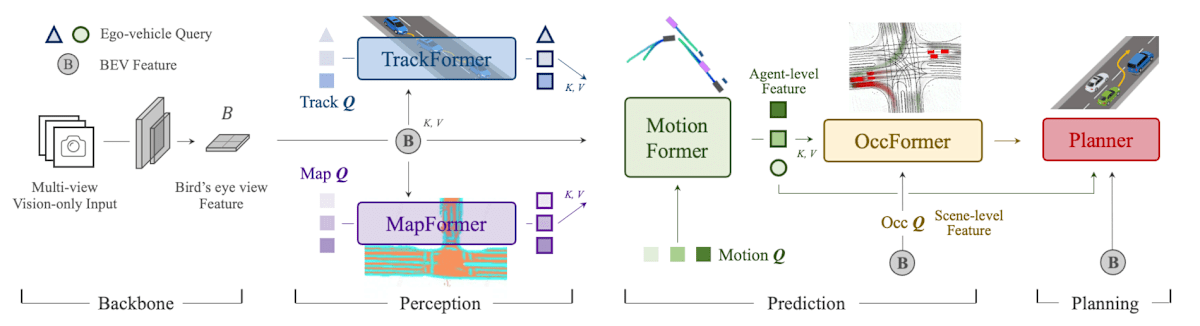
UniAD が紹介した最も大きな特徴は、CrossAttention によるベクトル更新にあります。
それぞれのタスクをとくニューラルネットのパラメーターをCrossAttention層で更新するように設計しています。
つまり、1つのモデルなのですが、いくつかのタスクごとに別のアルゴリズムを使っているんですよね。
「全て逆伝播できる」(=「モデル全体を同時に学習できる」) ことが単一のモデルであるということなので、それぞれのタスクごとのモデルを組み合わせるというアプローチをとっています。
実際にはモデル全体を同時に学習させるのは最後であって、それぞれのタスクごとにモデルを学習して、ニューロンのパラメーターを安定させてから、全体を逆伝播したほうがパラメーターが落ち着くまでのエポックが短いので効果的であるというようなことも書いてありました。
例えば、一番左の BEV という特徴量は、マルチカメラで認識した周りの物体を Perception するタスクを解いて、空間情報に変換するものです。空間を上から見た状態ですね。
現実の状態をカメラなどのセンサーデータから観測された状態をアルゴリズム内で使用する隠れ状態にエンコードするような役割をになっています。
あのような物体認識を解けるモデルを作ります。UniADの論文ではBEVFormer を使っていました。
この論文の最後には、BEVじゃなくて3Dの空間の方が精度が上がるんじゃないかという話もあって、TPVFormer というモデルが注目を集めていたりもします。
(TPVFormer については、またこの記事の後半で説明します。)
Outputは、空間情報そのものではなく、そのモデルが推論することで獲得した特徴ベクトルをCrossAttentionで裏のアルゴリズムに渡していくような使い方をします。
自然言語処理界隈でも、ベクトル表現に直したりすることが多いと思いますが、
そのようなイメージでマルチカメラで得た周りの空間情報をベクトル表現として表せるというふうに考えると理解しやすいと多います。
TrackFormer は物体を検出して、前のフレームのどの物体に対応するかを見つけるモデルです。Object Tracking なんていわれますね。
MapFormerでは、車線、分割線、交差点などを画像の中からSegmentationするようなタスクです。
これらは、BEVFormer が作成した空間情報をベクトルとして受け取るようになっていて、誤差逆伝播をシームレスに引き継げるようになっています。
MotionFormer は検出した物体が次にどのように動くかというのを予測します。
MotionFormer はこのUniADの論文で作られたアルゴリズムで内部的にはさらにいくつかのサブタスクに分けて、CrossAttentionによるクエリ更新をしています。
MotionFormer は、BEVFormer, TrackFormer, MapFormerで推論した結果のベクトルを CrossAttention によって Attention 層に反映されるようになっています。
OccFormer もこのUniADの論文で作られたアルゴリズムで、そこにその物体が存在する確率を計算するアルゴリズムです。
Occupancy のどこに存在するのかというのを計算するモデルが入った方が、のちのPlanning の精度が上がるんじゃないかと言われています。
UniAD 全体のフレームワークとして見ると、
インプットとして受け取るもの
- 6 台のカメラ(前に左右中央の3つ、後方に左右中央の3つ)
- 6 台のカメラの配置(カメラ同士の位置関係)
- ナビからの情報(右折、左折、直進)
アウトプットとして出力するもの
- BEV 空間 (推論結果)
- マルチオブジェクトのトラッキング結果
- セグメンテーションされたマップ
- Trajectories
テスラのセンターコンソールで、Occupancy Network の結果が見えるのも、E2E であると話しているところと合算すると、やはりMultiTask Learning をしているからなのだろうなと考えやすいです。
3D Gaussian について
次の項で語る世界シミュレーターに関連する部分でもありますが、最近 3D Gaussian という表現方法も注目を浴びています。
AWS からも上記のようなブログが出されています。上記のブログによると、
3D Gaussian とは、端的に言えば、三次元モデルの表現方法の一つです。従来の一般的な手法としては、従来のポリゴンベースのメッシュやボクセルが用いられてきました。
メッシュやボクセルの数が多いほど、より詳細な3D物体が表現できるというような手法で、直感的に理解しやすい手法であると思いますが、一方でメッシュ単位でしかコントロールできないので、デジタルな表現になってしまいます。
現実世界はアナログですので、より高品質にするにはアナログな表現が求められます。
3D Gaussian Splatting は視点依存の「ガウス分布」で 3D 空間を埋めることで新しい視点を生成するという点です。これらは、光の振る舞いを模倣するように色、密度、位置が調整された、ぼやけた 3D プリミティブとして現れます。
3D Gaussian Splatting はガウス分布を描画します。これにより、数十億のガウス分布を使用して複雑な実世界の環境を再現する立体的な表現が可能になります。また、3D Gaussian Splatting は NeRF とは異なり、ニューラルネットワークを使用せず、代わりに 確率的勾配降下法などの従来の機械学習最適化手法を活用している点です。この手法は NeRF と類似していますが、ニューラルネットワークのレイヤーを使用しないため、計算効率が大幅に向上しています。
ということが記述されています。非常に注目されている 3D 表現の手法です。
こちらの YouTube は、マルチカメラの映像から推論された 3D Gaussian のようです。非常に高画質で出力できることがわかるかと思います。
自動運転への活用の論文も多く見つかっていますが、GNSSなどの視点から、大量の車体視点の画像を生成することで、データ量を増やしたり、
マルチカメラでの距離推定タスクを推論、あるいはオートアノテーションするような役割で使われていくのではないかと私は考えています。
学習のためのプログラムコードは下記の GitHub に公開されています。私はまだ動かしてみてはいないですが、時間のある時にやってみたいと思います。
ビデオ生成モデルを用いた世界シミュレーター
先ほどの項ではCARLAという運転のシミュレーターを紹介しました。UnrealEngineベースのシミュレーターでしたが、近年注目を浴びているのは生成AIを活用した「世界シミュレーター/世界モデル」と言われているものです。
世界シミュレーターとは、環境の内部表現を構築し、その環境内での将来のイベントをシミュレートするAIシステムです。自動運転における世界シミュレーターは、センサーデータを統合し、将来のシナリオを予測することで、安全性と効率性の向上に貢献します。
わかりやすい例として、OpenAIのSoraといった動画生成モデルが存在します。こちらも世界シミュレーターとして活用されることが期待されており、実際にOpenAIからも記事が上がっています。
この記事では、以下のようなことが書かれています。
OpenAIは大規模なビデオデータを用いて生成モデルの訓練を行う研究を進めています。具体的には、様々な長さ、解像度、アスペクト比の動画や画像に対してテキスト条件付きの拡散モデルを共同で訓練しました。この研究では、動画と画像の潜在コードの時空間パッチを扱うトランスフォーマーアーキテクチャを活用しています。最大規模のモデルであるSoraは、1分間の高品質な動画を生成することができます。
Soraは、物理的な世界のオブジェクト、動物、人々をシミュレートする能力を示しています。これには3D一貫性、長期的な一貫性とオブジェクトの永続性、世界との相互作用、デジタル世界のシミュレーションなどが含まれます。現時点でSoraには、基本的な物理的相互作用の正確なモデル化や、長時間のサンプルにおける一貫性の維持など、いくつかの制限があります。しかし、OpenAIはこのような大規模なビデオモデルのスケーリングが、物理的およびデジタルな世界の高性能シミュレーターの開発に向けた有望な道筋であると考えています。
世界シミュレーターが大きな期待を抱いているのは、大きく分けて3つの利用用途が考えられるからです。
世界シミュレーター as DataSet
世界シミュレーターを使って、データ中心の自動運転モデルのためのデータを生成することが可能です。
DriveLMの例では、CARLAを使ってアルゴリズム的にスケールする仕組みとしてデータを取集することができました。しかし、Leaderboard 2.0フレームワークで提供されているコースには限りがありますし、CARLA で用意されているオブジェクトに限りがあります。そのため、ロングテールなデータセットを収集する目的ではそれだけでは不十分であることは明らかです。 Fleet Learning Pipeline は極めて優秀かつリアルなロングテールに対する解決策ですが、冒頭に述べたように求められるデータ量を満たすには、世の中のほとんどの車がTeslaになったとしても長年の年月が必要になることが予想されます。
世界シミュレーターであれば、既存の動画に歩いている人を追加したり、天候を雪にしたり雨にしたりといったことが可能です。そのため、確率的に滅多に怒らないような状況であってもかなりリアルに再現をすることができるのが世界シミュレーターをデータセット生成の目的で使うことです。
世界シミュレーター as Simulator
これまでも自動運転モデルのシミュレーションを行うというアプローチは広く取られており、実際にはCARLAを利用する場合も多いでしょう。
CARLA では様々なシナリオを設定することができ、実際の走行シミュレーションを想定することが可能です。
こちらの記事のように、CARLA を利用して、CI環境をクラウド上に用意し、大規模なシミュレーションを行うというような事例もあります。
悪天候や事故が起こりやすいシナリオを網羅的にテストすることができ、開発のより早い段階でDevOps的に実施することができるのが、実機でのテストに対するシミュレータでのテストの優れているところです。
しかし、シミュレーターは現実ではありません。現実のものは、こちらのリアクションに合わせて動きをとります。例えば、歩いている歩行者もこちらの車を認識すればおそらく止まるでしょう。ぶつかりそうになれば避けようとするでしょう。そのようにシミュレーターでは定義が難しいリアクションもあります。
機械学習によって獲得された世界シミュレータをシミュレータとして利用する新しいアプローチでは、より現実世界に近いリアクションをするでしょう。また、CARLAの物理演算エンジンでは個別のオブジェクトと運動則を定義する必要があるのに対し、世界シミュレーションではデータから学習することで、明示的な定義なしにオブジェクトの挙動を表現できます。雨や雪で道路が滑りやすかたったり、滑ってしまった時の判断など、CARLAでは表現が難しいようなエッジケースシナリオも世界シミュレーターでは実現が容易です。(自然言語で指定するだけなので)
世界モデルの汎化性や安全性の検証、モデルの調整が必要であることが挙げられるが、世界モデルは自動運転システム開発においてシミュレータとして有望な選択肢になり得るでしょう。
世界シミュレーター as AD Model
そもそも、E2E 自動運転を行うモデルというものは、何を受け入れて何を出力するのかという第1歩目に戻って考えましょう。
結局は、カメラやLiDARなどのセンサーデータを受け取って、trajectoryを出力する、つまりこの車はこの先どこに行くのかという軌跡を描くものがE2E 自動運転を行うMLモデルです。
あれ、これって何かと同じじゃないですか?これはまさに世界シミュレーターがやっていることなのです。
世界シミュレーターは本質的にやっていることは自動運転がやるべきことも含めてやっているわけです。
こちらの論文では、Planning-orientedな自動運転としてUniADというものを提案していますが、これまでの枠組みを超えて大幅にスコアが向上したことを示唆しています。
具体的には、周りの人や車などの動きをPredictすることが性能の向上に示唆していると主張しています。
つまり、世界シミュレーターのように世界そのものの未来を予測し、最終的には自分の車自体の未来も想像することはアプローチとして正しいのではないかと考えることも容易です。
もちろん、現状の世界シミュレーターは安全に運転するように訓練されていないので、大事故を起こす未来をシミュレーションすることもできてしまいますので、モンテカルロ木探索のように未来で事故が起きているような状況を避けるように訓練することが必要なのではないかという風に私は考えています。
AlphaGo
AlphaGoがMCTSを利用して数手先の未来を予測しながら最も優れている状態になるように訓練されていることは有名です。
こちらが AlphaGo の論文ですが、この論文の中でもちろんモンテカルロ木探索についても触れられていますし、先読みの重要性についても説かれている一方で、AlphaGoは、先読み無しで先読みをする最先端の囲碁ソフトに匹敵しているというふうにも説明されています。AlphaGoの凄さの一つはここにあると思っています。
そもそも一定以上安定した自動運転のモデルを学習するフェーズの後に、他の自動運転モデルに先読みの機能を組み込むという目的で、世界シミュレーターのモデルを組み込むこととも考えられるのではないかとも思いますね。
また、AlphaGoの学習には、教師あり学習の次に強化学習が行われていると論文では書かれています。
ここでは、Policy Network を相手にも置き、 AI vs AI を繰り返し行うことで勝てる未来を学んでいくというもので、人間が囲碁の練習をするのと同じような方法がAI同士で行われています。
実際の実装としては、network の勾配を買った場合に増やし、負けた場合に減らすというようなことをやっているというふうに記述があります。いわゆる強化学習でよく教科書的に語られるアプローチですよね。
世界シミュレーターを学習フェーズで活用することで、強化学習の文脈で、ADモデルが事故ったら勾配を減らす、事故らなければ増やすというようなシナリオをずっと解かせるようなアプローチも考えられるかもしれません。
ちなみに、AlphaGoの拡張にMuZeroというものがあります。
DeepMindが開発したMuZeroは、ゲームのルールを事前に与えることなく、複雑な環境下での意思決定と計画を可能にした画期的なアルゴリズムです
論文はこちらです。囲碁のようなシミュレーションが容易なゲームでは強化学習が行えたが、アクションゲームなどのシミュレーションがユーザーには難しいものの場合どうするのかというようなテーマのモデルがMuZeroです。(アクションゲームの場合ソースコードが手元にあればシミュレーションが簡単にできますが、一般的にゲームのプレイヤーはソースコードを理解していません)
ゲームの世界の未来を予測するエミュレーションのためのニューラルネットワークを別で作成することでMCTSが同様にできるようになるというものです。これはまさに世界シミュレーターが解決するモデルになるのではないでしょうか。
このMuZeroの世界と、今の自動運転の世界の進み方というのがすごく似ている、同じような方向に向かっているのではないかというふうに思っていて、本当に興味深い論文だったです。特に重要なところを要約します。
MuZeroでは、
- Representation network
- Dynamics network
- Prediction network
と三種類のニューラルネットワークを組み合わせています。
Representation network
Representation networkは、環境から観測された状態をアルゴリズム内で使用する隠れ状態にエンコードする役割を担います。
機能:
入力: 環境の観測値
出力: 隠れ状態
このネットワークは、生の観測データを意味のある特徴量に変換し、後続のネットワークが効率的に処理できるようにします。
Dynamics network
Dynamics networkは、現在の隠れ状態と行動から、次の隠れ状態と即時報酬を予測します。
機能:
入力: 現在の隠れ状態
出力: 次の隠れ状態
数式表現:
このネットワークにより、MuZeroは環境のダイナミクスを学習し、将来の状態を予測することができます。
Prediction network
Prediction networkは、隠れ状態から方策と価値を予測します。
機能:
入力: 隠れ状態
出力: 方策
数式表現:
このネットワークは、モンテカルロ木探索(MCTS)で使用される方策と価値の推定を提供します。
MuZeroの3つのネットワークは相互に補完し合い、環境のモデルを学習しながら効果的な計画を可能にします。Representation networkは生のデータを意味のある表現に変換し、Dynamics networkは環境の動きを予測し、Prediction networkは意思決定に必要な情報を提供します。
この構造により、MuZeroは事前知識なしに複雑な環境を理解し、効果的な戦略を立てることができます。特に、Dynamics networkが環境のシミュレーションを可能にすることで、明示的なルールがない場合でも計画を立てることができる点が革新的です。
これを自動運転の世界に当てはめると
Representation network → BEVモデル(BEVFormer, Occupancy Network)
Dynamics network → Perceptionモデル(ViT, DETR3D, CrossAttention)
Prediction network → 世界シミュレーション(GAIA-1, OccWorld, Genie, GenAD)
のように対応するモデルが開発されているように見えます。
実際、Tesla AI Dayでも、Representation networkとDynamics network の二つについては実際のE2E自動運転で使われているというような話もありました。( https://youtu.be/j0z4FweCy4M )
このMuZeroと同じようなアプローチで取り組むには、それぞれのNetworkを理解していく必要があるので、それぞれについて考察したいと思いますが、話の流れ通り、まずは世界シミュレーションのところから見ていきます。
自動運転技術の発展において重要な役割を果たす「世界モデル」について、英国のスタートアップWayveが開発したGAIA-1を特にピックアップして解説します。
Prediction network - GAIA-1
論文はこちらです。GAIA-1の論文をもとに要約を進めていきます。
GAIA-1は、動画、テキスト、運転者の行動をプロンプトとして受け取り、それらに基づいて未来のリアルな動画と行動を生成する能力を持つ世界モデルです。このモデルは、自動運転システムの訓練、シミュレーション、および研究目的に適した、高度に制御可能な環境を提供します。4,700時間分の実際の走行動画を用いて学習されていると記載があり、非常に大規模なデータを活用していることもわかります。
特にGAIA-1の特徴的なところは、動画とテキストの両方をプロンプトとして受け取ることができることです。前述したあらゆる用途で使える世界シミュレーターとしての活躍が期待されます。
前述した用途の as DataSet の用途としては、エッジケースが起きる未来を実現できるように動画だけでなくテキストを渡すことで意図的にエッジケースの動画を作成することが可能です。例えば、雪が降っている状態にしてとか、突然地割れを起こしてといったようなプロンプトをテキストで渡すことが可能です。
また、as Simulator の用途としても、CARLAなどのエミュレーターでは当然のようにADを組み込むことができましたが、それはADの操作を入力するインターフェイスを持っているからです。GAIA-1では、動画として現在の車体の状況を送るだけでなく、ステアリング操作をプロンプトとして送ることで未来を意図した方向に生成することが期待されるため、シミュレーターとして活用することが期待されます。
また、GAIA-1の特徴的なところのもう一つのポイントとして、最も尤もらしい未来一つだけではなく、二番目に尤もらしいもの、3番目に尤もらしいものなど複数の未来を出力することが可能です。
GAIA-1のアーキテクチャとしては、大きく分けて以下の3つのコンポーネントから構成されます。
(1) Image Tokenizer (2) World Model (3) Video Decoder
Image Tokenizer
Image Tokenizerは、画像を離散的なトークン列に変換するモデルです。
このフェーズでの目的は、以下の二つです。
- 生の画素情報を圧縮し、系列モデル化問題を扱えるようにする。画像には多くの冗長性やノイズが含まれており、入力データを表現するために必要な系列長を減らしたい。
- 高周波数信号ではなく、意味的な表現に圧縮を誘導する。その結果、ワールドモデルへの入力空間は単純になり、学習過程を大きく遅らせる可能性のある高周波数信号の影響が小さくなる。
モデル構造: VQ-VAE(Vector Quantized Variational Autoencoder)を使用しています。
パラメータ数: 約0.3Bのパラメータを持つFully Convolutionalなモデルです。
Vocabulary size: ベクトル量子化に用いるEmbedding層のvocabulary sizeは8,192です。
中間層の特徴量: 学習済みのDINOモデルの特徴量に近づけるように学習されています。
Image Tokenizerの処理フローは以下のようになります:
入力画像をConvolutional層で処理
特徴マップを生成(おそらく768次元)
ベクトル量子化層で離散トークンに変換
最終的に画像を離散トークンの集合として表現
このプロセスにより、画像を言語モデルで扱えるような形式に変換します。
World Model
World Modelは、GAIA-1の中核となる未来を予測するコンポーネントです。
このモデルの入力は動画、テキスト、アクションなどの多様なデータを離散トークン(c1, z1, a1, ..., cT, zT, aT)として受け取ります.つまり、ワールドモデルは、入力系列をモデル化する自己回帰トランスフォーマネットワークです。学習目的は、トランスフォーマブロックのアテンション行列において因果的マスクを使用し、過去のすべてのトークンに基づいて次の画像トークンを予測することです。
World Modelの損失関数Lworldmodelは次のように定義されています:
この損失関数は、過去の情報や条件付けトークンを基に、現在のトークンの確率を最大化することを目的としています。
-
条件付けトークンのランダムドロップアウト:
- 目的:モデルに以下の能力を持たせる
- 無条件生成
- アクション条件付き生成
- テキスト条件付き生成
- 目的:モデルに以下の能力を持たせる
-
時間的サブサンプリング:
- 方法:入力動画を25Hzから6.25Hzに減少
- 目的:
- World Modelの扱う系列長を短縮
- より長期的な推論を可能にする
-
フルフレームレート復元:
- 方法:Video Decoderを使用した時間超解像
- 目的:元の高フレームレートでの動画予測を実現
これらの技術により、GAIA-1のWorld Modelは効率的に学習され、多様な条件下での生成と長期的な予測が可能になっています。
Video Decoder
Video Decoderは、World Modelが予測した未来の画像列を表現するトークン列を実際の画像列に変換する役割を担います。つまり、Video Decoderは、Image Tokenizerの逆の処理を行うと考えることができます。
GAIA-1のVideo Decoderは、最近の画像生成やビデオ生成の進展を踏まえ、デノイジングビデオディフュージョンモデルを採用しています。この選択には以下の利点があります:
-
時間的一貫性の向上: 各フレームを独立して処理するのではなく、時間を越えた情報にアクセスできるようにすることで、出力動画の時間的一貫性が大幅に改善されます。
-
3次元U-Net構造: 空間と時間の注意を因子分解した3次元U-Netを使用しています。これにより、空間的特徴と時間的特徴を効果的に捉えることができます。
-
学習時: 事前学習済みのImage TokenizerによってImage Tokenに変換された入力画像を条件として使用します。
-
推論時: World Modelから予測されたImage Tokenを条件として使用します。
Video Decoderは複数のタスクを同時に学習するマルチタスク学習アプローチを採用しています:
-
タスクの種類: 画像生成、ビデオ生成、自己回帰デコーディング、ビデオ補間など
-
学習方法: これらのタスクを等確率でサンプリングして学習します。
-
利点: マルチタスク学習により、個々のタスクのパフォーマンスが向上することが期待されます。
-
条件付けドロップアウト: 確率p=0.15で条件付けImage Tokenをランダムにマスクします。これにより、モデルがTokenに過度に依存するのを防ぎ、時間的一貫性を向上させます。
-
画像とビデオの共同学習: 単一のモデルで画像生成とビデオ生成の両方を学習します。ビデオ学習は時間的一貫性を、画像学習は個々のフレームの品質向上に寄与します。
ビデオデコーダの損失関数Lvideoは、ノイズ予測を目的として以下のように定義されます:
この損失関数は、L1損失とL2損失の加重平均を使用し、v-parameterizationを採用することで、自然でない色シフトを回避し、長期的な一貫性を維持することができます。
これらの高度な技術を組み合わせることで、GAIA-1のVideo Decoderは高品質で時間的に一貫性のあるビデオ出力を生成することが可能となっています。
これら3つのコンポーネントが連携することで、GAIA-1は入力された画像や動画から未来の状態を予測し、それを視覚化することが可能になります。
学習について
GAIA-1の学習はImage Tokenizer、World Model、Video Decoderそれぞれを分けて行います。
GAIA-1の他にも OccWorld, Genie, GenAD など世界シミュレーションモデルの開発に取り組んでいるところは多く、ここからさらなる発展があることが期待されています。
他のモデルについても簡単に紹介すると、OccWorldは、3D占有空間(Occupancy)を用いた世界シミュレーターです。過去の3D占有観測に基づいて、将来のシーン進化と自車の動きを同時に予測するものです。3D占有を用いることで、より細かな3D構造の表現が可能となります。また、自己教師あり学習を採用し、大規模なデータセットでの学習が可能であることも特徴です。OccupancyとBEVの違いなどは、Representation Networkの項で話しますが、Occupancyを用いた世界シミュレーターもあるということは紹介させていただきます。
Representaiton Network - Occupancy Network (マルチカメラへの対応と Tesla の事例)
Representation Network の項は、現実の状態をカメラなどのセンサーデータから観測された状態をアルゴリズム内で使用する隠れ状態にエンコードする方法について考えます。
Tesla AI Day で触れられたことをきっかけに Occupancy Network やBEV のトピックというのは脚光を浴び始めたように記憶しています。
Tesla が感じていた課題としては、車体に搭載されている複数のカメラ映像というのは区別のある別々のカメラ映像ですが、それらを組み合わせて一つの隠れ状態にエンコードする方法というのを考えていたわけです。
というのも極端な話、前についているカメラと後ろに付いているカメラでは全く役割が違うわけですから、単に入力された画像から他の車両や停止線、信号などをPerceptionできたとしてもそれらのカメラの位置を理解できないと運転にはつながらないわけです。
そこで、さまざまな方向のカメラから画像を合成する方法に最初に着手したとTeslaは説明しています。しかし、この方法はそれほどうまくいかなかったようです。合成して作成するものとして取り組んだのは、鳥の目で俯瞰して見たような鳥瞰図を作成しようとしていたようですが、同じ物体が複数のカメラで認識された場合、一つの物体を一つのもとのして統合することがうまくいかなかったそうです。
そもそも、BEV(鳥瞰図)表現では、Z軸がないのでリアルと少し異なってしまうわけです。一方でLiDARなどから取得される3次元の点群データを変換したVoxel表現は多く用いられてきたアプローチですが、計算量が大きく、車体上の限られたリソースでリアルタイムで処理をすることが難しいとされています。
こちらの論文では、BEV 表現に直行するような 2 平面 を追加した Tri-Perspective View という3枚の直行平面を提案しています。
Tri-Perspective Viewは、双線形補完を正とすれば Voxel 表現などの三次元データに変換することができます。式は論文内にも記載されていますが、非常に単純で以下のように記述されています。
-
t_{h,w} t_{d,h} t_{w,d} -
S T^{HW} T^{DH} T^{WD} -
P_{hw} P_{dh} P_{wd} (x, y, z) - 式(5)の
f_{x,y,z} A
TPVFormer
この論文内で紹介されている Transformer ベースのモデルなのですが、
Tri-Perspective View(TPV)をマルチカメラの入力から作成する方法が提案されています。
簡単に言えば、与えられた複数のセンサーの画像データの特徴量をCNNを使ってembeddingします。
それをTPV Formerでは TPV空間のQueryとCrossAttentionしてTPV空間のベクトルにマッピングするということをしています。さらにそれだけでは安定しないので、後段の層でSelf-Attention層を組み合わせることをしています。論文内では、前半のCNNで得られた特徴量とのCrossAttention部分を「ImageCrossAttention」と名付け、後段のSelf-Attention層を「Cross-View HybridAttention」と名付けています。
ImageCrossAttention
まず、TPV Query については2D特徴の3つの平面(上面、側面、正面)に対応しています。各クエリは3D空間の柱状領域を表現し、画像特徴とコンテキスト情報で強化されます。学習可能なパラメータとして初期化され、3D位置エンコーディングが追加されます。
ImageCrossAttentionというモデルは、多スケール・多カメラの画像特徴をTPV平面に投影するために使用されます。
計算効率のため、変形可能アテンション(deformable attention)が採用されています。
ImageCrossAttentionの流れは、
- TPVクエリの位置を実世界座標に変換
- 平面に垂直な方向に沿って参照点(周囲n点)をサンプリング
- サンプリングした参照点を画像のピクセル座標に透視投影
- 無効なカメラ視点(サンプリングした点に画像の対応点がないもの)を除外して計算を効率化
という流れです。
ImageCrossAttentionを適応する際には、クエリに対して線形層を適用し、オフセットとアテンションの重みを生成し、有効なカメラからの画像特徴をサンプリングし、重み付けして合計します。
二次元のSegmentationで使われているBEVFormerと似たような仕組みですし、Tesla AI Dayで紹介されてえいたNetwork友の似たようなCrossAttentionの手法を使っていますので、現時点のトレンドとして一般的な手法なのかと思います。
Cross-View HybridAttention
BEVと違ってTPVでは、他にも2平面あるので、そこからも特徴をとってきて、SelfAttention層を作りましたというのが、こちらのCross-View HybridAttentionです。
つまり、TPV平面同士でCross Attentionをしているものです。計算効率のため、変形可能アテンション(deformable attention)がこちらも採用されています。
- TPV平面同士でCross Attentionをし、コンテキスト抽出を改善する
- TPVクエリ
t_{h,w}
R_{h,w} = R^{top}_{h,w} \cup R^{side}_{h,w} \cup R^{front}_{h,w} - 上面(トップ): クエリ
t_{h,w} - 側面と正面:
- 上面に垂直な方向に3D点を均一にサンプリング
- これらの点を側面と正面に投影:
R^{side}_{h,w} = \{(d_i, h)\}_i, \quad R^{front}_{h,w} = \{(w, d_i)\}_i - 線形層を通じて各参照点のサンプリングオフセットとアテンションの重みを計算
- サンプリングされた特徴をアテンションスコアで重み付けして合計:
CVHA(t_{h,w}) = DA(t_{h,w}, R_{h,w}, T)
ここで、DA T
この手法により、異なるビュー(上面、側面、正面)間での情報交換が可能になり、3D環境の理解が向上します。
タスク
この論文では、この記事でも前述した nuScenesとKITTIに対して推論を行なっています。
画像なども実際に出ているので、論文の原文も見ていただきたいところですが、かなり綺麗に三次元のモデリングができている感じがします。
実際に数値に関しては、以下の表が掲載されていました。
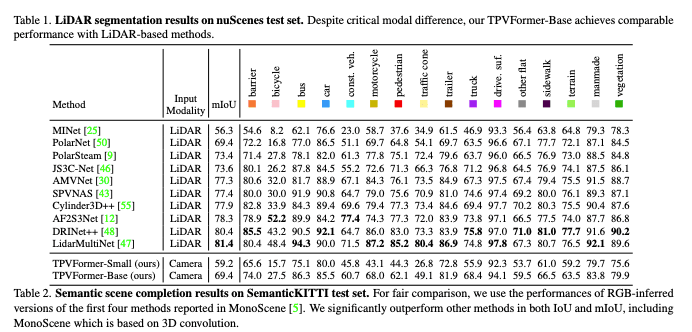
出典: https://arxiv.org/pdf/2302.07817
LiDAR を利用せず、カメラだけでもLiDARに近い数値を算出することができていることがわかります。
また、GitHubにはTeslaとの比較についても記載があります。
| Tesla's Occupancy Network | Our TPVFormer | |
|---|---|---|
| Volumetric Occupancy | Yes | Yes |
| Occupancy Semantics | Yes | Yes |
| #Semantics | >= 5 | 16 |
| Input | 8 camera images | 6 camera images |
| Training Supervision | Dense 3D reconstruction | Sparse LiDAR semantic labels |
| Training Data | ~1,440,000,000 frames | 28,130 frames |
| Arbitrary Resolution | Yes | Yes |
| Video Context | Yes | Not yet |
| Training Time | ~100,000 gpu hours | ~300 gpu hours |
| Inference Time | ~10 ms on the Tesla FSD computer | ~290 ms on a single A100 |
出典: https://github.com/wzzheng/TPVFormer?tab=readme-ov-file#comparisons-with-teslas-occupancy-network
やはり、Teslaは別次元ですね。特に推論時間が Tesla では、10ms に対して TPVFormer は290msとなっています。 これはハードウェアレベルでのチューニングも込みの話で、モデルの軽量さだけを単純に比較しているわけではないですが、やはりTeslaは別次元と感じました。
前述した、UniADであったり、Representaiton Network としてBEVやTPVを先に学習してPredictionおよびPlanningを後段で学習するというAlphaGo的な手法は広く採用されています。そして結果としても高い数値を出しているようなので、非常に注目されていくであろう手法になると考えています。
閉ループ駆動型アプローチ
こちらのサーベイ論文に戻り、閉ループ駆動型アプローチについての項を翻訳していきます。以下に上記「Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies」の第3章の要約を記します。
閉ループのデータ駆動型システムは、自動運転アルゴリズムのトレーニングとその実世界での適用/展開との間のギャップを橋渡しすることを目指しています。従来は、人間の運転データやロードテストから収集したデータセットを使ってモデルを受動的にトレーニングしていましたが、閉ループシステムでは実環境と動的にインタラクションします。この手法では、静的なデータセットから学習した振る舞いが、実世界の動的な運転シナリオに必ずしも転がらないというロングテールの問題に対処することができます。
しかし、課題もあるのが実情です。
第一の課題は、自動運転データ収集に関するものです。実世界でのデータ収集では、一般的な運転シナリオのデータサンプルが大半を占めますが、コーナーケースや異常な運転シナリオのデータはほとんど得られません。
第二に、正確で効率的な自動運転データ自動ラベリング手法の探求がさらに求められています。
第三に、都市環境におけるさまざまなシナリオでの自動運転モデルの低パフォーマンス問題を緩和するため、シーンデータマイニングとシーン理解に重点を置く必要があります。
最先端のクローズドループ自動運転パイプライン
自動運転業界では、統合ビッグデータプラットフォームの構築に積極的に取り組んでいます。
・これらのパイプラインでは通常、(I)データ収集、(II)データ保存、(III)データ選択と前処理、(IV)データラベリング、(V)ADモデルトレーニング、(VI)シミュレーション/テスト検証、(VII)実世界展開、というワークフローサイクルに従っています。
・システム内のクローズドループの設計については、既存のソリューションでは「データクローズドループ」と「モデルクローズドループ」を別々に設定するか、「R&D段階でのクローズドループ」と「展開段階でのクローズドループ」を別々のサイクルとして設定しています。
・その他にも、業界では実世界ADデータセットのロングテール分布問題とコーナーケースへの対処の難しさを重視しています。TeslaとNVIDIAはこの分野の先駆者であり、彼らのデータシステムアーキテクチャは、この分野の発展に重要な参考となります。
(I)データ収集 - Tesla の Fleet Learning Pipeline が取得する Snapshot
こちらの論文では、Tesla の Fleet Learning pipeline について以下のような説明がされています。
テスラには事故データレコーダー(EDR)が搭載されており、ほとんどの新車と同様です。事故調査を支援するため、これらの「ブラックボックス」レコーダーは、事故の5秒前までの限られた情報(速度、加速度、ブレーキ使用状況、ステアリング入力、自動ブレーキおよび車両安定性制御の作動状況など)を記録します。
テスラ車両はこれらのデータをさらに多く、永久に「インフォテインメント」コンピューター(車載メディア制御ユニット(MCU)の一部)内の4GBのSDカードまたは8GBのmicroSDカードに記録します。これらのタイムスタンプ付きの「ゲートウェイログ」ファイルには、シートベルトの使用状況や、自動運転システムのさまざまなパラメーター(運転手がハンドルを握っていたかどうかなど)の情報も含まれています。
ゲートウェイログは車両の標準コントローラーエリアネットワーク(CAN)バスからデータを取得するため、車両識別番号が含まれる可能性があります。ただし、これらのログにGPSモジュールやカメラからの情報が含まれているという証拠はありません。
所有者がテスラをWi-Fiネットワークに接続すると(新機能の追加やバグ修正のためのオーバーザエアアップデートをダウンロードする際など)、ゲートウェイログが定期的にテスラにアップロードされます。フロリダ州の訴訟から判断すると、同社にはそのデータを発信元の車両にリンクする方法があるようです。(テスラはこの件やその他の問題について説明を求める要請に応じませんでした)
ゲートウェイログファイルはデータの一部にすぎません。テスラのオートパイロットコンピューターは、車載カメラからの入力を受け取り、クルーズコントロール、車線維持支援、衝突警報などのドライバー支援機能を処理します。所有者が自分のUSBドライブを車に差し込めば、ライブダッシュカム録画やSentryモードでの駐車時周辺録画ができますが、これらの録画はテスラにアップロードされないようです。
これらのオートパイロット「スナップショット」は数分間に渡り、数百メガバイトのデータで構成されることがあると、テスラの車両やコンポーネントを調べてデータ収集プロセスをツイートしているGreen(@greentheonly)というエンジニアで匿名のテスラオーナーが指摘しています。これらのスナップショットには、ゲートウェイログと同様の高解像度ログデータが含まれますが、サンプリングレートはより高く、車輪回転速度情報では最大50回/秒にもなるとHoogendijkは述べています。
このようなデータスナップショットは、車両が衝突したときや、テスラエンジニアが知りたい特定の条件(特定の運転行動、オートパイロットシステムが検知した特定のオブジェクトや状況など)が満たされたときにトリガーされます。Greenによれば、GPSロケーションデータは常に衝突イベントに記録され、他のスナップショットに時々含まれます。ゲートウェイログデータと同様に、スナップショットはWi-Fi接続時にテスラにアップロードされますが、衝突によりトリガーされた場合は4G回線経由でもアップロードが試みられます。Greenによると、スナップショットが正常にアップロードされると、オートパイロットコンピューターの32GBストレージから削除されます。
スナップショットに加え、2017年中頃以降のテスラのオートパイロットコンピューターは、車が駐車からドライブに切り替わるたびに完全な走行ログを記録するとGreenは言います。走行ログには、走行経路のGPS座標、速度、道路種別、オートパイロット起動の有無が含まれます。Greenによると、オートパイロット(または完全自動運転モード)の使用有無にかかわらず、走行ログは常に記録されます。スナップショットと同様、走行ログもテスラにアップロードされた後、車両コンピューターから削除されます。
同社にはリアルワールドの数十億kmの走行データやGPS追跡データ、そして何百万もの写真や動画が提供されています。世界有数の電気自動車メーカーであるテスラは、このような膨大な情報をどのように活用しているのでしょうか。テスラは具体的には言及していませんが、推測するのは難しくありません。
テスラが約300万台の車両から収集したデータは、自社の自動運転ソフトウェアのトレーニングに使われていると考えられます。写真や動画は、オートパイロットシステムが道路上の様々な状況を認識する能力を高めるために役立っているはずです。GPS追跡データとセンサーログは、自動運転アルゴリズムをリアルな交通状況にさらすことで、システムをさらに洗練させることができます。
リコール、保証請求、製造上の問題の特定にもデータが役立つでしょう。フリートワイドのデータを分析すれば、車両設計の問題点を早期に発見できます。
さらに、収集データはマーケティングや製品開発の意思決定にも影響を与えるかもしれません。テスラは、どんなオプションが人気があり、どの新機能が必要とされているかを把握できます。新しいビジネスモデルの可能性も見えてくるかもしれません。
このようにテスラでは車体側のECUの機能として、snapshot (数分間に渡り、数百メガバイトのデータで構成)を取得する機能が搭載されているようです。
車両が衝突したときや、テスラエンジニアが知りたい特定の条件(特定の運転行動、オートパイロットシステムが検知した特定のオブジェクトや状況など)が満たされたときにトリガーされます
という記載にあるように、ロングテールのデータを実車両から自動的に収集する仕組みをテスラはすでに持っているようです。
「ゲートウェイログ」ファイルと言われているのは、いわゆるProbe Data のようなものと考えられるでしょう。こういったデータは現代のコネクテッドカーであれば多くのメーカーの車両で取得してるものなのでこちらは意外性はそれほどないでしょう。しかし、snapshot の機能と組み合わせることで Specific な課題と向き合っているかもしれません。
(I)データ収集 (II)データ保存 - AWS の マネージドサービスで提供されている IoT Fleetwise
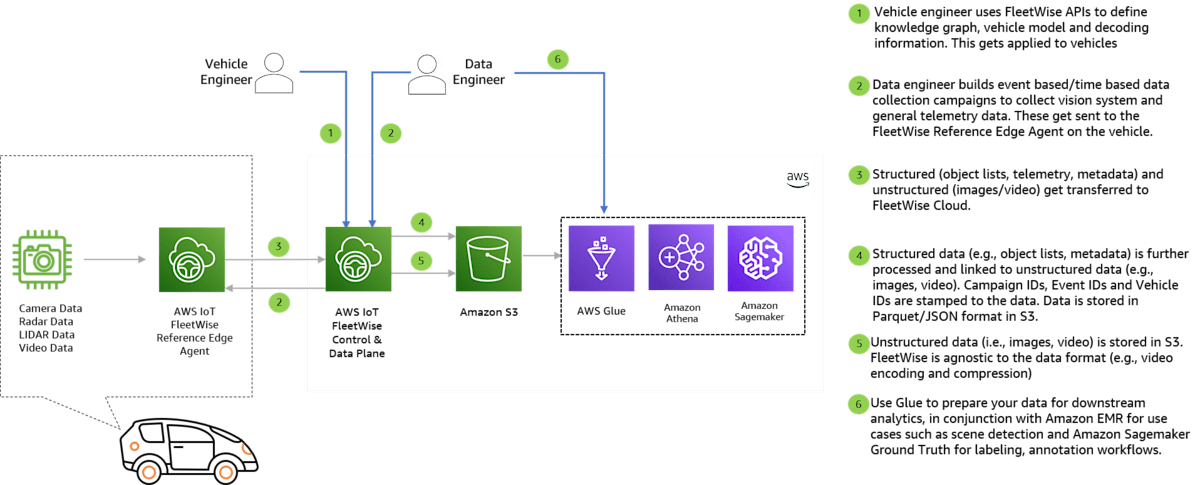
IoT Fleetwise を利用すると、カメラ、LiDAR、レーダー、その他のビジョンサブシステムからのメタデータ、オブジェクトリストと検出データ、画像やビデオを収集できます。
車体側の ECU に、 IoT Fleetwise Edge Agent をインストールすると、 FleetWise Edge Agent は、車両の CAN バスからの信号をデコードし、条件やイベントに基づいてデータをクラウドに送信し、データをAWSクラウド上に収集することができるようです。
またすべてのデータを収集すると非効率なので、どのようなテレメトリを収集するのか、どのようなイベントをもとに収集するのか(たとえば急ブレーキ)などを選択することができます。
IoT Fleetwise Edge Agent 自体は、 GitHub に公開されており、こちらを利用することでカスタマイズも可能です。
(III)データ選択と前処理
実際のところ、自動運転モデルというのは、現時点で大部分のケースにおいて問題なく走行できるところまで来ています。
しかし、ロングテール問題(エッジケース問題)は残り続けているというのが現状です。ですので、走行データのうち実際にモデルの学習に利用したいものというのはほんの一部のエッジケースのみです。
Tesla のように本当に必要な部分を抽出するやり方は素晴らしいですが、どのような走行データが必要かというのはモデルの学習を進めていく上で変わっていく要素もあり、適切なECUをOTAで頻繁に更新できるような販売車両が大量にあるTeslaだからこそできる技とも言えます。
一方で、上がってきたセンサーデータには、カメラのデータだけでなく、ProbeデータやLiDARのデータ、NIR(近赤外線)、GNSS など多様なデータがあり、それらに対して「動画から画像への変換」「歪みの矯正」「バリデーションやクレンジング」「メタデータの収集(timestamp, GNSS, 天気、気温、走行速度 etc...)」「MLモデルを利用した加工」など様々な処理/ETLを施す必要があります。バリデーションやクレンジングでは、「フレーム飛び」「カメラの前に障害物があり何も映ってないもの」「ファイル自体の破損」などが含まれます。
しかし、問題なく走行できるデータばかりが集まってしまうのが現状なので、全てのデータを利用する必要はありません。
ロングテール問題への対処に寄与できそうなものに限定して処理していくことが重要です。
そのため、データレイクに集約した様々なデータに関しては、Scene Search や ML モデルなどを利用して、機械的にロングテール問題に対処できるものを探して学習データとして集約していくことも求められます。
AWS Summit Tokyo 2024 では、自然言語を使って、シーンを検索する機能のデモンストレーションが紹介されていました。
技術的には、マルチモーダル生成AIの Embedding 使って画像と自然言語を同じベクトル空間にマッピングして、コサイン類似度を用いた検索をしています。
(III)データ選択と前処理 (IV)データラベリング、(V)ADモデルトレーニング、(VI)シミュレーション/テスト検証 - NVIDIAの MagLev AV プラットフォーム
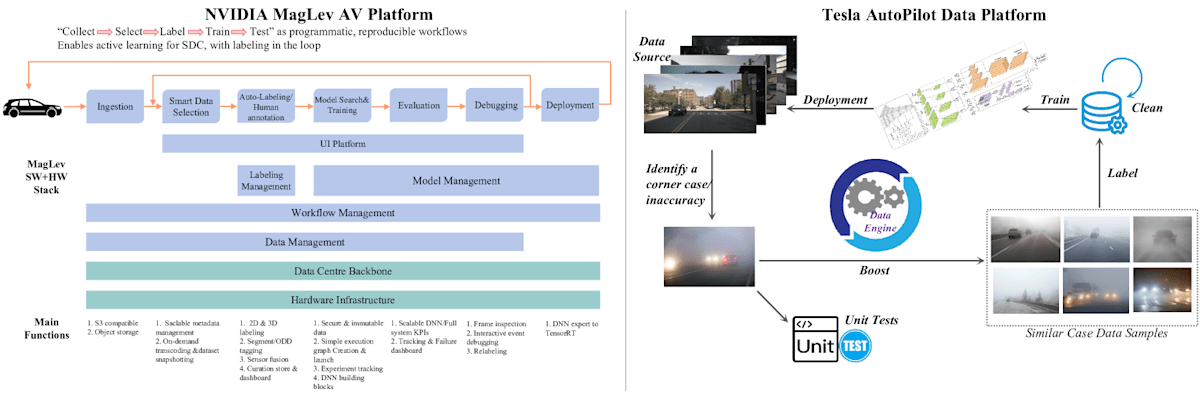
NVIDIAの MagLev AV プラットフォームは、https://www.usenix.org/conference/opml20/presentation/farabet で示されているように、「収集→選択→ラベリング→トレーニング→テスト」というプログラマティックなワークフローに従っています。これは、インテリジェントラベリングをループに組み込んだ、自動運転車(SDC)のためのアクティブラーニングを可能にする再現性のあるワークフローです。MagLevには主に2つのクローズドループパイプラインが含まれています。最初のループはデータ中心の自動運転ループで、データ取り込みとスマートな選択から始まり、ラベリング付けとアノテーションを経て、モデル探索とトレーニングが行われます。トレーニングされたモデルは評価、デバッグされた後、最終的に実世界で展開されます。2番目のクローズドループは、プラットフォームのインフラストラクチャサポートシステムで、データセンターのバックボーンとハードウェアインフラストラクチャが含まれます。このループには、セキュリティデータ処理、スケーラブルなDNNとシステムKPI、追跡とデバッグ用のダッシュボードが含まれます。AVの開発全体のサイクルをサポートし、実世界のデータとシミュレーションフィードバックを開発プロセスに継続的に統合し、改善を図ることができます。
OpML '20 - Inside NVIDIA’s AI Infrastructure for Self-driving Cars ( https://www.youtube.com/watch?v=HuIWTwE28QE )
(III)データ選択と前処理 (IV)データラベリング、(V)ADモデルトレーニング、(VI)シミュレーション/テスト検証 - Teslaの AutoPilot Data プラットフォーム
Teslaの AutoPilot Data プラットフォームは、Elluswamy に示されているように、ビッグデータ駆動のクローズドループパイプラインを強調し、自動運転モデルの性能を大幅に向上させることを目指す代表的なADプラットフォームの一つです。このパイプラインは、Teslaのフリートラーニング、イベントトリガー車両端末データ収集、シャドウモードなどからのソースデータ収集から始まります。収集したデータはデータプラットフォームのアルゴリズムまたは人間の専門家によって保存、管理、検査されます。コーナーケースや不正確性が特定されると、データエンジンが既存のデータベースから、そのコーナーケース/不正確性のイベントと非常に類似したデータサンプルを検索してマッチングします。同時に、そのシナリオを再現してシステムの応答を厳密にテストするためのユニットテストが開発されます。次に、検索されたデータサンプルは自動ラベリングアルゴリズムまたは人間の専門家によってラベル付けされます。適切にラベルが付けられたデータはADデータベースにフィードバックされ、データベースが更新されて、AD の知覚/予測/プランニング/制御モデル用の新しいトレーニングデータセットのバージョンが生成されます。その後、モデルのトレーニング、検証、シミュレーション、実世界テストを経て、性能が向上した新しいADモデルがリリースされ、展開されます。
出典 - Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies, https://arxiv.org/html/2401.12888v2
その後、前述したようにデータセットの収集が重要だということが記されています。CARLAと世界モデルGAIA-1(Hu et al. 2023)について触れられていますが、すでに説明しているので割愛します。
そこから、次の項のラベリング/アノテーションの自動化につながります。
(VI)シミュレーション/テスト検証 - 自動運転データセットの自動ラベリング/アノテーション手法
高品質のデータアノテーションは、自動運転アルゴリズムの成功と信頼性に不可欠です。現在までに、データラベリング パイプラインには、従来の手作業ラベリングから半自動ラベリング、そして最も高度な完全自動ラベリングまで、3種類の特徴があります。

出典 - Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies, https://arxiv.org/html/2401.12888v2
従来の自動ラベリング タスクには、以下の論文のClassic auto-labeling tasks include scene classification & understandingというものがあります。
最近では、BEVの普及に伴い、自動運転データのラベリング業界標準も上がり、自動ラベリングタスクがより複雑になっています。現在の産業フロンティアのシナリオでは、3D動的オブジェクト自動ラベリングと3D静的シーン自動ラベリングが、よく言及される高度な自動ラベリングタスクの2つです。
シーン分類と理解は、自動運転ビッグデータプラットフォームの基礎となるものです。システムは、運転場所(街路、高速道路、都市の高架道路、メイン道路など)や天候(晴れ、雨、雪、霧、雷雨など)などの事前定義されたシナリオに、ビデオフレームを分類します。シーン分類には通常、CNNベースの手法が用いられ、事前学習+ファインチューニングCNNモデル( https://www.sciencedirect.com/science/article/abs/pii/S0925231219301833 )、マルチビューマルチレイヤーCNNモデル( https://arxiv.org/pdf/2304.00501 )、シーン表現を改善するさまざまなCNNベースモデル( https://proceedings.neurips.cc/paper_files/paper/2016/file/856fc81623da2150ba2210ba1b51d241-Paper.pdf ; https://ieeexplore.ieee.org/document/9067002)などがあります。シーン理解(Peng et al. 2023; YOLOv8 2023)は単なる分類を超えたものです。周辺の車両、歩行者、信号機などのシーン内の動的要素を解釈することが含まれます。
3D動的オブジェクト自動ラベリングと3D静的シーン自動ラベリングの台頭は、広く採用されているBEV perception の要件を満たすためです。Waymo( https://arxiv.org/pdf/2103.05073 )は、LiDARポイントクラウドシーケンシャルデータから3D自動ラベリングパイプラインを提案し、3Dディテクターを使ってフレーム単位でオブジェクトを検出します。フレーム間で検出されたオブジェクトのバウンディングボックスは、マルチオブジェクトトラッカーでリンクされます。各オブジェクトのオブジェクトトラックデータ(対応するポイントクラウド+各フレームの3Dバウンディングボックス)が抽出され、分割統治アーキテクチャのオブジェクト中心自動ラベリングを経て、最終的に洗練された3Dバウンディングボックスのラベルが生成されます。
このWaymoの論文では、点群シーケンス全体から教師なし学習により3D物体検出を行う手法を提案しています。従来の逐次処理とは異なり、シーケンス全体を入力として扱うことで、より人間に近い物体認識プロセスを実現するところが新規性です。具体的には、
- 初めに点群からの物体検出を行う
- 次に自己運動(エゴモーション)を除去する
- シーケンス全体から検出した物体をトラッキングする
教師なしで物体検出を行うため、人手によるラベリング作業が不要になる点がこの文脈で大きなポイントです。
Uberが提案したAuto4Dパイプライン( https://arxiv.org/pdf/2101.06586 )は、空間的-時間的スケールでの自動運転知覚ラベリングを探求しています。Auto4Dの主な目的は、連続的なLiDARポイントクラウドデータから4次元物体ラベルを自動的に生成することです。空間スケールでの3Dオブジェクトバウンディングボックスラベルと、時間スケールでの対応するタイムスタンプの1Dラベルを、自動運転分野では4Dラベリングと呼びます。この二つを組み合わせることにより、物体の空間的な位置と形状だけでなく、時間経過に伴う動きも捉えることができます。
Auto4Dパイプラインでは、最初にシーケンシャルLiDARポイントクラウドから初期のオブジェクトの軌跡を確立します。この軌跡はObject Size Branchによって洗練され、オブジェクト観測を使ってオブジェクトサイズをエンコードおよびデコードします。同時に、Motion Path Branchはパス観測と動作をエンコードし、Path Decoderがオブジェクトサイズを一定に保ちながら軌跡を洗練できるようにします。
先ほど紹介した MagLev( https://www.youtube.com/watch?v=HuIWTwE28QE&t ) にも ラベリング/アノテーションのワークフローに記載があったので、紹介します。
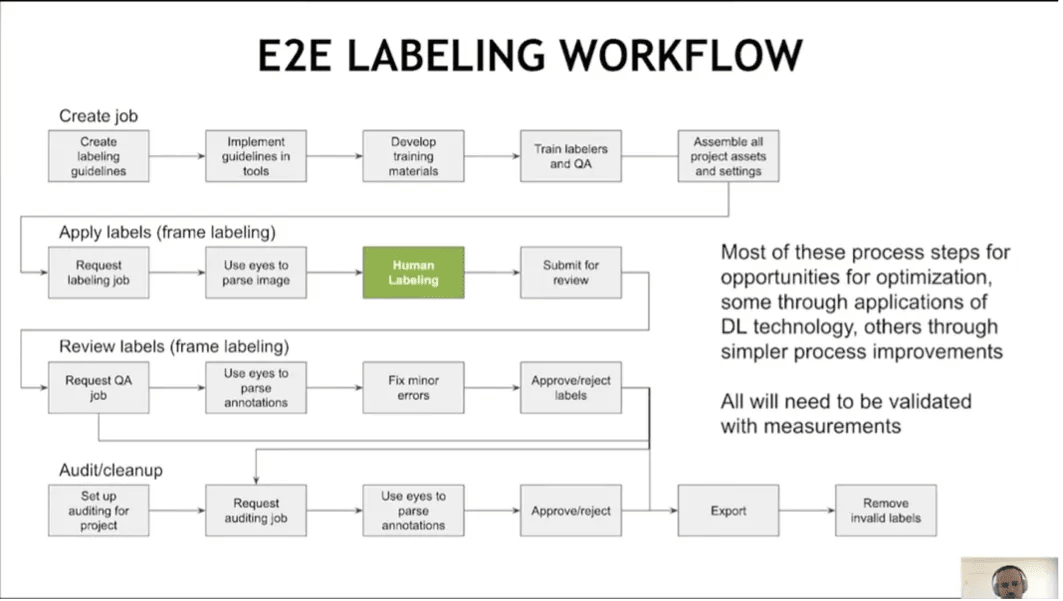
出典 - https://www.youtube.com/watch?v=HuIWTwE28QE
Production Level での E2E ラベリングのプロセスは非常に複雑であることがわかります。
特に、みどい色でハイライトされているようにラベリングは人の手で行われています。先ほどのAuto4D のように自動化していくことは将来的に考えられますが、現時点ではHuman Labeling が行われることは一般的なようです。こういった手動でのラベリングを効率化するために MagLev では、以下のようなラベリングツールを導入することで効率化しています。
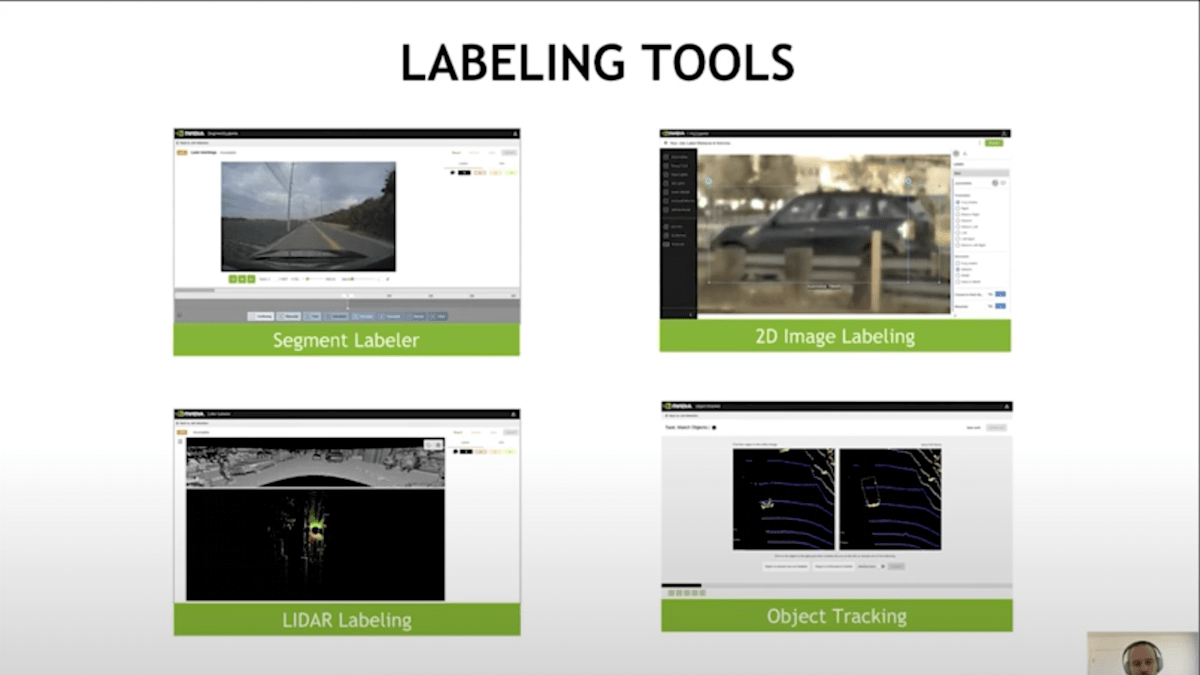
出典 - https://www.youtube.com/watch?v=HuIWTwE28QE
ラベリングツールには、Segment Labeler があります。これはビデオの特定の区間にタグを付けるものです。ほとんど何でもできて、非常に高速です。この利点は、収集された全ての運転セッションにこれを適用できることです。 2D Image Labeling では、典型的にオブジェクト検出のためのバウンディングボックスを付けます。LiDARのラベリング作業は、通常カメラと連携して行われ、センサー融合のためのいくつかの工夫が必要です。オブジェクトトラッキングは、複数フレームにわたって同じオブジェクトを追跡するものです。これらは一例ですが、他にもできることはたくさんあります。
重要な点は、フレームにラベリングを行う際、特定の要求に対して一度にすべてのラベリング作業を行うのではなく、小さな部分に分割して、プラグイン可能で構成可能なものにしているということです。このようにすることで、スループットと品質の向上が図れることがわかっています。もちろん、この構成可能性を実現するためのインフラストラクチャが制約となります。
私たちにとって重要な点は、すべてがトレーサブルでバージョン管理されていることを確認することです。ラベリング作業の手順書を作成する際、コード化されていて、実際にラベリングを可能にするツールと密接に関連付けられていることを確認しています。そのため、私たちはこの法的な手順書の形式を使用しています。これは、作業内容を指定するだけでなく、UIそのものにリンクされています。そして、UIのバージョンを参照しています。その結果、ラベリング手順書がどのように形作られたか、どのURLが使用されたかを完全に追跡することができます。そして一旦ラベリングが完了し、UIからラベルが生成されると、実際にそのラベルをインストールし、ガイドラインに逆にリンクさせます。つまり、常に、どのガイドラインに基づいてどのラベルが付けられたかを確認できるのです。ラベリング作業が完了すると、データレイクにラベルがあります。
そして、OpML '20 の NVIDIA のセッションでは、アクティブラーニングを活用していることも紹介されていました。
上記のブログの方がより詳細に書かれていますが、アクティブラーニングは多様なデータを自動的に見つける機械学習のトレーニングデータ選択方法です。人間がキュレーションするのにかかる時間のほんの数分の1の時間で、より優れたデータセットを構築できます。
トレーニングされたモデルを使用して収集されたデータを調べ、認識に問題があるフレームにフラグを立てるという仕組みです。次に、これらのフレームに人間がラベルを付けます。その後、トレーニングデータに追加されます。これにより、厳しい条件で物体を知覚するような状況でのモデルの精度が向上します。
NVIDIA による調査によると、( https://medium.com/nvidia-ai/scalable-active-learning-for-autonomous-driving-a-practical-implementation-and-a-b-test-4d315ed04b5f )アクティブラーニングデータを使用してトレーニングを行うと、手動で選択したデータの増加と比較して、歩行者検出で3倍、自転車検出で4.4倍になることがわかりました。
前述した Tesla においても Labeling の大部分を手作業で行っており、ラベリングツールの開発も行われています。Tesla は 4D ラベリングのために社内にラベリング チーム(1000 人以上)を構築しているそうです。(Tesla AI day,2021 - https://www.youtube.com/watch?v=j0z4FweCy4M)

出典 - Tesla AI day,2021 https://www.youtube.com/watch?v=j0z4FweCy4M
ここからは、私の感想ですが、 Tesla, NVIDIA の手動でのラベリングの事例は、2020年、2021 年に発表されたものであり、この項の冒頭に述べたような近年の論文の様子や実際のモデルの精度を見ていると、自動ラベリング/アノテーションではほとんど正確な精度を出すことができています。三次元物体のPerception というのは、 VLMのサブタスクとして精度向上に有意に働くのではないかと考えています。(スケーリング測から)
というのも、アノテーションを付与するというタスクは、自動運転モデルが解く必要のあるタスクです。というのも、アノテーションというタスクのサブタスクは主に、マルチカメラ画像からの「物体検出」「深度推定」「オブジェクトトラッキング」あたりになりますが、これは自動運転におけるサブタスクとしても必要になるからです。
ですので、逆に言えば、Pseudo Labeling的なアプローチでも一定の成果を得ることができるのではないかと仮説をたてています。VLM はある程度アノテーションのタスクを解けますし、アノテーションタスクを学習データとして入れることでVLM自体の汎化性能を高めることができるものになっている互いが互いに高め合うような関係になっているでしょう。
しかし、実際には、Pseudo Labeling的なアプローチは流行っておらず、自動アノテーションを行うモデルを開発しているのが一般的な流れです。
というのも、そもそも自動運転モデルによって解けるタスクとして解いたアノテーションデータを利用して学習しても結局はロングテール問題(エッジケース)に対応できないこと。
結局はロングテールで解けないタスクが解けない学習データが生成されるだけなので、手作業での確認作業を効率化する程度の役割は果たせるが、完全に自動化はできないということです。
また、ラベリングというタスクを解くためには、マルチカメラセンサーデータ以外にも学習に用いることができるものがあります。例えば、未来のカメラのデータです。
未来のデータがあることで、オブジェクトトラッキングの観点で、その歩行者や車がどちらに向かっているのかであったり、
深度推定においても、画像からは深度が掴みにくいような状況でも目の前まで移動していたとしたら、深度はわかるはずです。仮に目の前まではいっていなくても、10m, 20m 近づいた時の挙動で距離感というのは容易にわかります。(少なくとも静止画よりは格段に推定タスクの精度が上がる)
これは、実際の自動運転モデルにおいても、あくまでもego car は動的に動いている中で物体がどれほど近づいているかという情報も合わせて、進度推定をするのでLiDARなどを使わずとも深度推定のタスクの精度というのは全く問題がないほどに高くなっています。深度推定タスクには自分が動くという要素が非常に重要です。
物体検出においても、ある角度からは見えにくかったり、遠すぎて判断しにくかったりするものも、未来のデータを参照することで、より近づいてわかりやすいデータから判断できることがあります。
そのような簡単から、自動運転モデルでは参照できない未来の情報も使いながら自動アノテーションというのは行えるというところがかなり優位な点です。
さらに、Tesla や NVIDIA では、手作業でアノテーションデータを準備していたので、それを用いて自動ラベリング用のモデルの教師データにすることができるはずです。
それらを活用して、現在はアノテーションタスクはほぼ自動で行われているのではないでしょうか。
また、先ほど紹介した Waymo や Uber の論文ではLiDARデータも併用しています。こちらを活用することでさらに高精度な物体検出や深度推定が可能になるため、完全自動アノテーションモデルはかなり精度が出ているように感じています。
(VII)実世界展開 - 実証実験
本研究で述べた高度なクローズドループ自動運転データプラットフォームを詳しく説明するため、実証研究を提供します。全体の手順図を下記に示します。この場合の研究者の目標は、生成AIとさまざまな深層学習ベースのアルゴリズムに基づいて、自動運転ビッグデータのクローズドループパイプラインを開発し、自動運転アルゴリズムのR&D段階とリアルワールド展開後のOTAアップグレード段階の両方でデータクローズドループを実現することです。
具体的には、生成AIモデルが以下の目的で使用されます。
(1)エンジニアが提供するテキストプロンプトに基づいて、シーン固有の高精度自動運転データを生成する。
(2)自動運転ビッグデータの自動ラベリングを効率的に行い、ground truth label を準備する。
図には2つのクローズドループが示されています。大きい方は自動運転アルゴリズムのR&D段階用で、生成AIモデルから生成された合成自動運転データと実世界の運転から取得したデータサンプルの両方を収集することから始まります。(図の左上の [Synthetic Autonomous Driving Data from Generative AI Mode] と [Real-World Vehicle Data Collection]に対応する。)
2種類のデータソースが統合され、自動運転データセット(図の[Autonomous Driving Dataset])となり、クラウド側で価値ある洞察を得るためにデータマイニングされます。(図の[Cloud-End Big Data Mining])その後、データセットは深層学習ベースの自動ラベリング(図の[DL-based Big Data Auto Labeling])か手作業ラベリング(図の[Handcraft Labeling])の2つの経路に分かれ、アノテーションの速度と正確性が確保されます。ラベル付きデータは、高性能な自動運転スーパーコンピューティングプラットフォーム上でモデルを訓練するために使用されます。これらのモデルはシミュレーションと実際の路上テストを経て、有効性が評価され(図の[Learge-Scale Cloud-end Simulation + Real World Road Testing])、自動運転モデルがリリースされ、実装されます。(図の[Release Updated Model & Core Deployment])
小さい方はリアルワールド展開後のOTAアップグレード段階用で、大規模なクラウド側シミュレーションと実世界テストを含み、自動運転アルゴリズムの不正確さやコーナーケースを収集します。特定された不正確さやコーナーケースは、次のモデルテストとアップデートのサイクルにフィードバックされます。例えば、自動運転アルゴリズムがトンネル走行シナリオでの性能が低いことがわかったとします。特定されたこのトンネル走行のコーナーケースはすぐにループに通知され、次の反復でアップデートされます。生成AIモデルはトンネル走行シナリオに関連する説明をテキストプロンプトとして受け取り、大規模なトンネル走行データサンプルを生成します。生成されたデータと元のデータセットがシミュレーション、テスト、モデル更新に送られます。このようなプロセスの反復的な性質は、モデルを洗練し、困難な環境や新しいデータに適応させ、自動運転機能の高い精度と信頼性を維持するのに不可欠です。
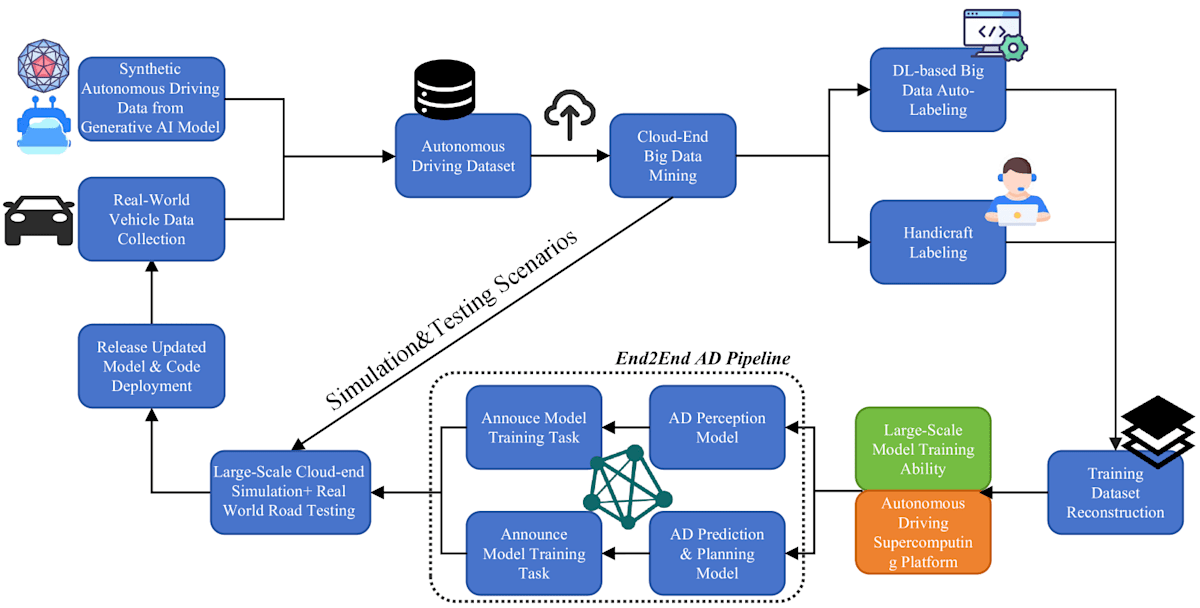
出典 - Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies, https://arxiv.org/html/2401.12888v2
以上が、https://arxiv.org/abs/2401.12888 の翻訳および要約です。
(V)ADモデルトレーニング - Tesla Training Node Architecture - Dojo
Labeling を行って DataLake にアノテーション付き走行データが入るわけですが、その後は大規模なモデルのトレーニングが行われます。
Dojoは、Teslaが自社開発した機械学習トレーニング用のスーパーコンピューターシステムです。主に自動運転技術の開発に使用されることを目的としています。
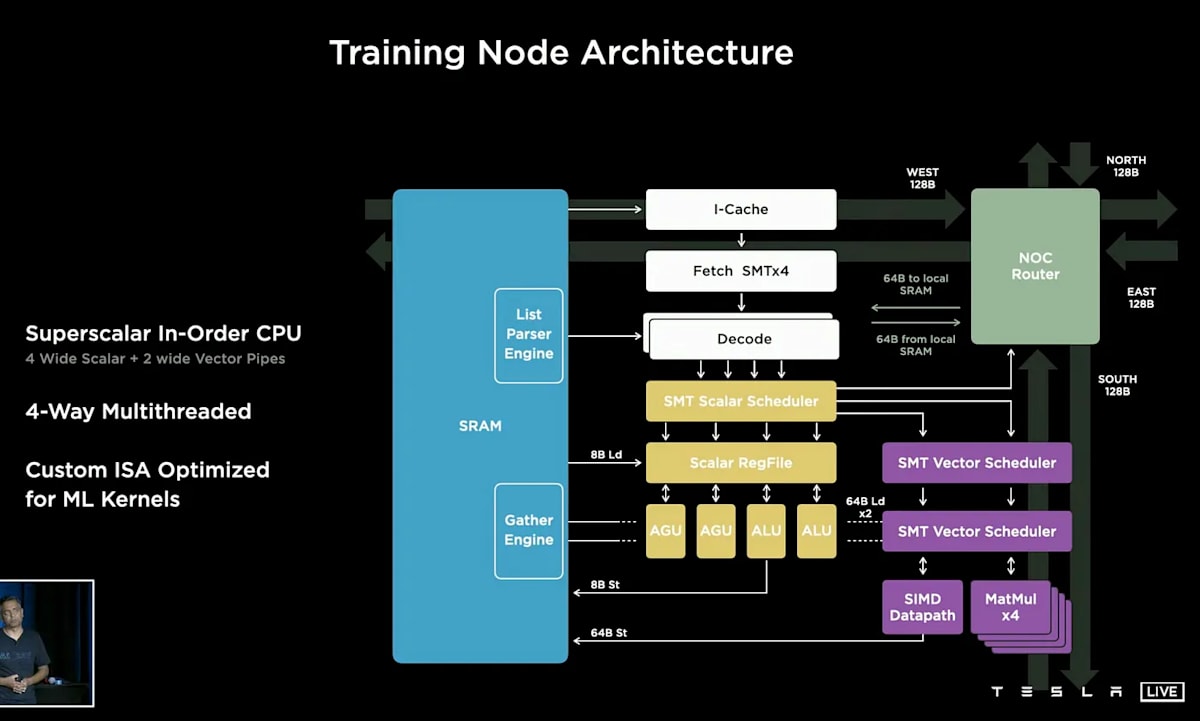
出典 - Tesla AI day,2021 https://www.youtube.com/watch?v=j0z4FweCy4M
Dojoシステムの基本単位は「D1チップ」と呼ばれるプロセッサーです。D1チップの主な特徴は以下の通りです:
- TSMCの7nmプロセスで製造
- 50億トランジスタを搭載
- ダイサイズは645mm²
- 354個の演算コアを搭載
- 1.25MBのSRAMを搭載(コアあたり)
- 2GHzで動作
- 消費電力は400W
- 16,000GBps (4x 4TB)のネットワーク帯域幅
25個のD1チップを組み合わせて「トレーニングタイル」を構成します。トレーニングタイルの特徴は以下の通りです:
- サイズは約1平方フィート
- 8,850個の演算コア
- 36,000GBps (4x 9TB)のネットワーク帯域幅
- 消費電力は15kW (D1チップで10kW、電圧レギュレータなどで5kW)
6個のトレーニングタイルを組み合わせて「システムトレイ」を構成します。システムトレイの特徴は以下の通りです:
- 53,100個の演算コア
- 20枚のDojo Interface Processor (DIP)カード
- 4台のホストサーバー
- 高さ75mm、重量135kg
- 2,000Aの電流を消費
DIカードは以下の特徴を持ちます:
- 32GBの高帯域幅メモリ(HBM2eまたはHBM3)
- イーサネットインターフェース
- PCIe 4.0 x16スロットに接続 (32GB/秒の帯域幅)
10個のキャビネットで1つの「ExaPOD」を構成します。ExaPODの特徴は以下の通りです:
- 1,062,000個の演算コア
- 3,000個のD1チップ
- BF16およびCFloat8フォーマットで1エクサフロップスの演算性能
- 1.3TBのオンタイルSRAMメモリ
- 13TBのHBMメモリ
Dojoシステムは非常に高速なネットワークを特徴としています:
- Tesla Transport Protocol (TTP): PCIe上の独自プロトコル
- 50GB/秒のTTPリンクがイーサネット上で動作
- 400Gb/秒または200Gb/秒x2のポートをサポート
Dojoは、非常に高い演算性能と高速なネットワークを特徴とする独自のAIトレーニングシステムで、規格外の規模で構築されていることがわかります。
References
Discussion