はじめに
検索パフォーマンスを考慮する上でインデックスの利用は必要不可欠です。
この記事では、直近使用を検討しているPostgreSQLのインデックスの1つであるGINインデックスについて調べたことを共有します。
一般的なインデックスについて
GINインデックスの説明のために、まずは一般的なインデックスについて。
一般的に最もスタンダードなインデックスと言えばB-treeインデックスが思い浮かぶと思います。
B-treeインデックスは木構造の一種で、すべてのリーフノードが同じ深さになるように設計されています。
クエリを叩いて、あるテーブルのB-treeインデックスの実際のデータを確認してみました。

dataカラムには実際に格納されているインデックスキーや木構造の紐付けの内容がバイナリで記録されており、それがctidに対して紐づいています。
ポイントは、各行において1つのctidと1つのdataが紐づいていることです。
GINインデックスとは
| 項目 | 内容 |
|---|---|
| 正式名称 | Generalized Inverted Index(汎用転置インデックス) |
| 主な用途 | 配列、jsonb、全文検索(tsvector)、複数値列(multi-valued attributes) |
| 概要 | “どの値がどの行に含まれているか” を素早く引くための仕組み |
| 利点 | 1つの行に複数の値がある場合でも、高速検索できる |
例として以下のようなtagsテーブルがあるとします。
| id | keywords(jsonb) |
|---|---|
| 1 | ["python", "sql"] |
| 2 | ["json", "python"] |
| 3 | ["sql"] |
GINインデックスは項目["python", "sql"]の中のキー”python”ごとでインデックスを格納できます。
"python" → [id1, id2]
"sql" → [id1, id3]
"json" → [id2]
GINインデックスのデータは以下のようになっています。
(実際に確認したデータは見づらいため、公式ドキュメントより)

上記データにはキーの表示がありませんが、1行1行が特定の1つのキー(pythonなど)に紐づいています。
そして、テーブルの右側にはtidsカラムがあり、キーが紐づいているすべてのctid(レコード)が格納されています。
B-treeインデックスは各ctidから単一キーを作るだけで、要素に分解しません。
一方GINインデックスは、元の「ctid → 要素群」を「要素 → ctid群」に組み替えて(転置させて)索引化します。
これが転置インデックスと呼ばれる所以になります。
GINインデックスの効果測定
GINインデックスの有無における、読み取りと書き込みそれぞれの処理時間を測定しました。
テーブル構成は以下のようになっており、property_valueテーブルはitemテーブルとpropertyテーブルの中間テーブルとなっています。
この中間テーブル内にjsonb型のvalueカラムがあり、このvalueカラムに対して検索をかける形で測定を行っています。

測定条件
- レコード数
- item:420,000
- property:1,400
- property_value:10,462,000
- 測定回数
- 各10回
- 実行クエリ
読み取り
EXPLAIN ANALYZE
SELECT * FROM property_value
WHERE value @> '["VXDRGA4v"]';
書き込み
EXPLAIN ANALYZE
INSERT INTO property_value ("projectId", "itemNumber", "propertyId", "value")
VALUES
('Uaxziveq', '1', 'lPv5uxZ2', '["9J7ejK1N", "9dpUVNDt"]');
読み取り処理
処理時間
GINインデックス無し
| Metric | Min | Max | Average | Median |
|---|---|---|---|---|
| Execution Time (ms) | 1957.702 | 5216.742 | 2876.983 | 2230.816 |
| Planning Time (ms) | 0.090 | 0.191 | 0.125 | 0.116 |
GINインデックス有り
| Metric | Min | Max | Average | Median |
|---|---|---|---|---|
| Execution Time (ms) | 10.601 | 17.973 | 12.581 | 12.3075 |
| Planning Time (ms) | 0.101 | 0.268 | 0.1364 | 0.117 |
GINインデックス無しで中央値が約2230msだったのに対して、GINインデックス有りだと約12msほどと、1/200近くにまで処理時間が減少しています。
またGINインデックス無しでは最大値約5217msと中央値の約2.3倍、GINインデックス有りでは最大値約18msで中央値の約1.5倍とネガティブケースでのバラつきに対しても改善が見られます。
なお、この最大値はどちらのケースも10回中初回のクエリ実行時に記録されており、キャッシュが効いていないことによる影響と考えられます。
クエリプラン(抜粋)
GINインデックス無し
Gather (cost=1000.00..167708.71 rows=1003 width=51) (actual time=0.275..2050.615 rows=7480 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on property_value (cost=0.00..166608.41 rows=418 width=51) (actual time=0.229..2048.157 rows=2493 loops=3)
Filter: (value @> '["VXDRGA4v"]'::jsonb)
Rows Removed by Filter: 3484840
Planning Time: 0.090 ms
Execution Time: 2051.119 ms
GINインデックス有り
Bitmap Heap Scan on property_value (cost=26.20..3748.13 rows=1002 width=51) (actual time=2.888..17.592 rows=7480 loops=1)
Recheck Cond: (value @> '["VXDRGA4v"]'::jsonb)
Heap Blocks: exact=7203
-> Bitmap Index Scan on idx_property_value_jsonb (cost=0.00..25.95 rows=1002 width=0) (actual time=1.644..1.645 rows=7480 loops=1)
Index Cond: (value @> '["VXDRGA4v"]'::jsonb)
Planning Time: 0.268 ms
Execution Time: 17.973 ms
GINインデックス無しでは、3並列でフルスキャンが行われています。
フィルタリング(Rows Removed by Filter)されたレコードは1ワーカーあたり3,484,840件に上り、3ワーカーで10,454,520件。
テーブルの全体のレコード数が10,462,000件なので、ほぼすべてのレコードがフィルタリングされる非効率な処理になっています。
GINインデックス有りでは、Bitmap Index Scanで検索対象のctidのみをかき集めた上で、Bitmap Heap Scanにより対象のレコードの取得のみを行っています。
Planning Timeでは、レコードの取得を行う前に"どういう取得方法を行うと効率が良いか"の計算が走るため、GINインデックスを使う使わないの選択肢があるGINインデックス有りの条件の方が計算量が多く、時間がかかっています。
ただ全体の処理時間からすると割合が小さいため、無視できるレベルです。
まとめ
| 項目 | GINインデックス無し | GINインデックス有り |
|---|---|---|
| スキャン | 並列シーケンシャルスキャン(フルスキャン) | GINインデックスによるビットマップ検索 |
| 実行時間 | 約2230ms | 約12ms |
| 処理方法 | 全行に対して @> を評価(フィルタベース) |
インデックスで該当TIDを抽出し、必要なブロックだけを読み込む |
| 読み取り対象 | すべての行(3ワーカーが3回スキャン) | 該当行のページのみ(Heap Blocks: exact=7203) |
| 効率 | 非効率(340万件×3以上をフィルタ) | 高効率(インデックス命中) |
書き込み処理
処理時間
GINインデックス無し
| Metric | Min | Max | Average | Median |
|---|---|---|---|---|
| Execution Time (ms) | 0.163 | 0.244 | 0.185 | 0.182 |
| Actual Time (ms) | 0.065 | 0.149 | 0.078 | 0.069 |
GINインデックス有り
| Metric | Min | Max | Average | Median |
|---|---|---|---|---|
| Execution Time (ms) | 0.170 | 0.576 | 0.261 | 0.225 |
| Actual Time (ms) | 0.075 | 0.343 | 0.113 | 0.087 |
書き込み処理においてはGINインデックス更新のオーバーヘッドのために、GINインデックス有りの方が時間がかかることが想定されますが、GINインデックス無しが約0.182msだったのに対して、GINインデックス有りは約0.225msで約1.25倍程度となりました。
想定通り増加はしたものの、読み取り処理の200倍のオーダーと比べると、その差はかなり小さくなっています。
各10回のActual Timeの値
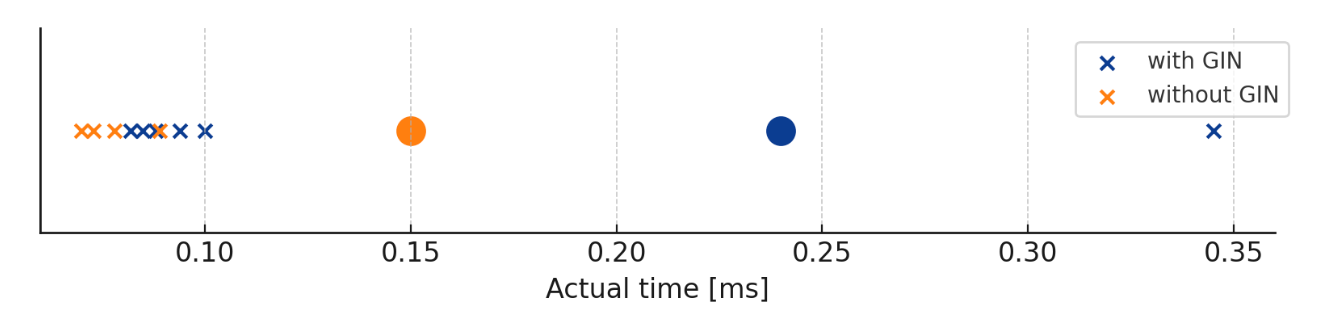
丸プロットはいずれも1回目の測定であり、読み取り処理と同様に他の処理に比べて長くなっています。
また、GINインデックス有りでは0.35ms付近に外れ値が確認できますが、このあたりを含めた解像度を上げるためにGINインデックスの詳細について調べてみました。
GINインデックスの構成について
GINインデックスは以下の3種のページで構成されます。
- meta page:GINインデックス全体の管理情報(ページ0)
- entry page:各要素(entry)と ctidのリストを格納
※entryはキーに相当するものです。 - data page:ctidリストの実体を保持(エントリーページに収まらない場合)
今回のproperty_valueテーブルのGINインデックスのメタデータを確認したところ、以下のようになっていました。
meta page

data page(見づらいですが、entryに紐づくctidが格納されています。)
meta pageより、GINインデックスの全体のページ数が分かります。
- n_entry_pages:entry pageのページ数
- n_data_pages:data pageのページ数
- n_total_pages:GINインデックスデータ全体のページ数
- meta page 1ページ
- entry page 10ページ
- data page 8388ページ
- 計8399ページ
1ページ8KBなので、今回のGINインデックスのデータ量は約66MBであることがわかります。
8399ページ × 8KB/ページ = 67,192KB
67,192KB / 1,024KB/MB = 65.6MB
entryの数が増えたり、entryとctidの紐付けが増えたりすることでentry pageやdata pageが大きくなり、GINインデックスのデータ量が増え、書き込み処理時のオーバーヘッドも大きくなっていきます。
書き込み処理のオーバーヘッドについて
書き込み処理のオーバーヘッドに影響がある仕組みとしては以下があります。
ctidの保持形式
- posting list(=ctidの配列)が大きくなりすぎるとposting tree に変換される。
- 配列構造 → ツリー構造になることで、書き込み時に階層をたどって更新が必要になる。
- → B-tree型インデックスのような構造になり、コストが上昇。
イメージ
"python" →
├─ Posting List(TIDが10個) → そのまま格納
└─ Posting Tree(TIDが10000個) → B-Treeで管理
├─ Page 1: [(123,4), (123,5)...]
├─ Page 2: [(124,1), (124,3)...]
今回用意したデータにおいては、entryに紐づくctidの数がそれほど多くはないので配列構造となっていましたが、 紐づけの組み合わせが増えてツリー構造になることで、書き込み処理におけるオーバーヘッドが大きくなっていくことになります。
高速更新処理(後でまとめて処理)
- insert時、一時的に「待機リスト」に入れてGINインデックスの更新はすぐにはしない。
- 新しい行の情報を「待機中リスト(pending list)」に入れておく。
- GINインデックスの更新は、以下をトリガーに走る。
- 自動 or 手動でVACUUM や ANALYZE(不要領域の回収や解析)
- 待機中リストが大きくなり過ぎたとき。
GINインデックス有りの書き込み処理において、actual timeが大きな外れ値が測定されたことに関して、今回これが原因であるかどうかは分かりませんが、この仕組みがあることで今回の測定結果のように、特定の書き込み処理において処理時間が長くなるという挙動が発生し得るというデメリットがあること注意しておくべきことの1つです。
まとめ
- GINインデックスについて
- 配列/jsonb/tsvectorなどの"要素 → ctid群"で引ける“転置”型索引。B-treeインデックスの"単一キー → ctid"とは役割が違う。
- 処理速度の実測値について
- 読み取り:約2230ms → 約12ms(≈ 200倍高速)で、ばらつきも縮小。
- 書き込み:更新は約1.25倍に増(ケースによりスパイク)
- GINインデックスの構造について
- meta page、entry page、data pageで構成
- 今回の索引サイズは約66MB
- 更新処理のオーバーヘッドについて
- entryに紐づくctidが大きくなるとposting listからposting treeに構造が変わる。
- GINインデックスを後から更新する機能あり。読み込みの処理時間を安定させたい場合は fastupdate=off も選択肢

プレイドの新規事業からスピンオフしたスタートアップです。Webサポートプラットフォーム「RightSupport by KARTE」「RightConnect by KARTE」等を開発・提供しています。
Discussion