Vertex AI Studioを使用したSQL・プロンプトエンジニアリング入門
はじめに
本記事はこちらのGenerative AI Study Jam with GDGにおけるチュートリアル用に作成した記事です.
- Gemini in BigQueryやML.GENERATE_TEXT関数などについて
Marioさんセッション資料
ごく一部ですがライブ形式であることを前提とした表記がありますのでご注意ください。
想定読者
- 生成AIをこれから使っていきたい方
- BigQueryを使ってみたいがSQLがわからない方
- データ分析に入門したい方
本記事の目標
- Vertex AI Studioの使い方を覚える
- Geminiを使用したプロンプトエンジニアリングに入門する
- Geminiのサポートを活用し、所望のSQL文を作成する方法を身につける
環境構築
GoogleCloudプロジェクトをお持ちであることを前提にします.
- Vertex AI APIの有効化:Vertex AI Studio利用のため
- BigQuery APIの有効化:BigQuery利用のため
- Vertex AI APIの有効化:Vertex AI Studio利用のため
コンソール画面上部の検索窓から検索し、API管理画面を開きましょう.
画像はすでに有効化されていますが、まだ有効にしていない場合は有効化ボタンがあります.
ボタンをクリックして有効化してください.変更の反映には数分かかる場合があります.
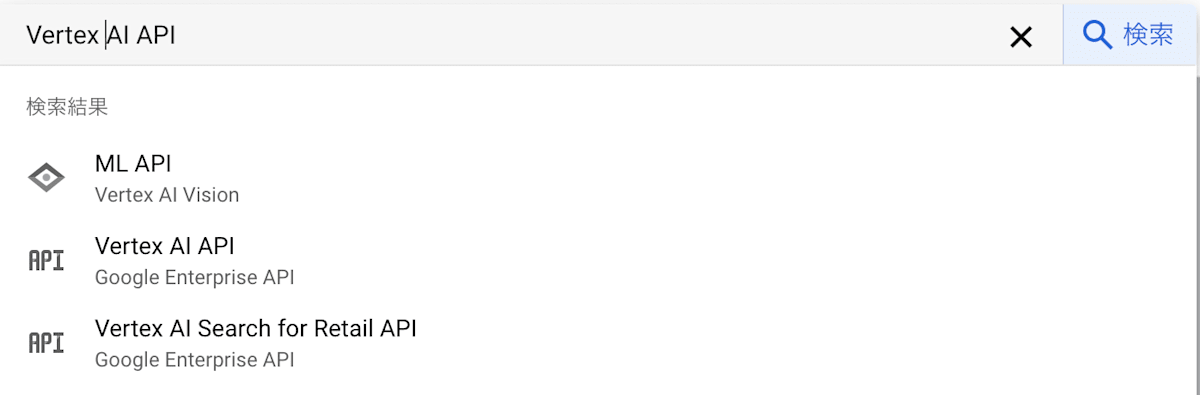
サービス検索窓から検索

Vertex AI APIの有効化
- BigQuery APIの有効化:BigQuery利用のため
Vertex AIと同様にして有効化しましょう.

BigQuery APIの有効化
Vertex AI Studioの使い方
Vertex AI Studioでは手軽にGoogle製のLLM(大規模言語モデル)であるGeminiを使用することができます.
ここではVertex AI Studioの使い方を見ていきましょう。
Vertex AI Studioを開く
まず、Vertex AIのダッシュボード(ホーム的な画面)を開きましょう.

Vertex AI
画面内のVertex AI Studio"今すぐ試す"からVertex AI Studioを開きましょう.
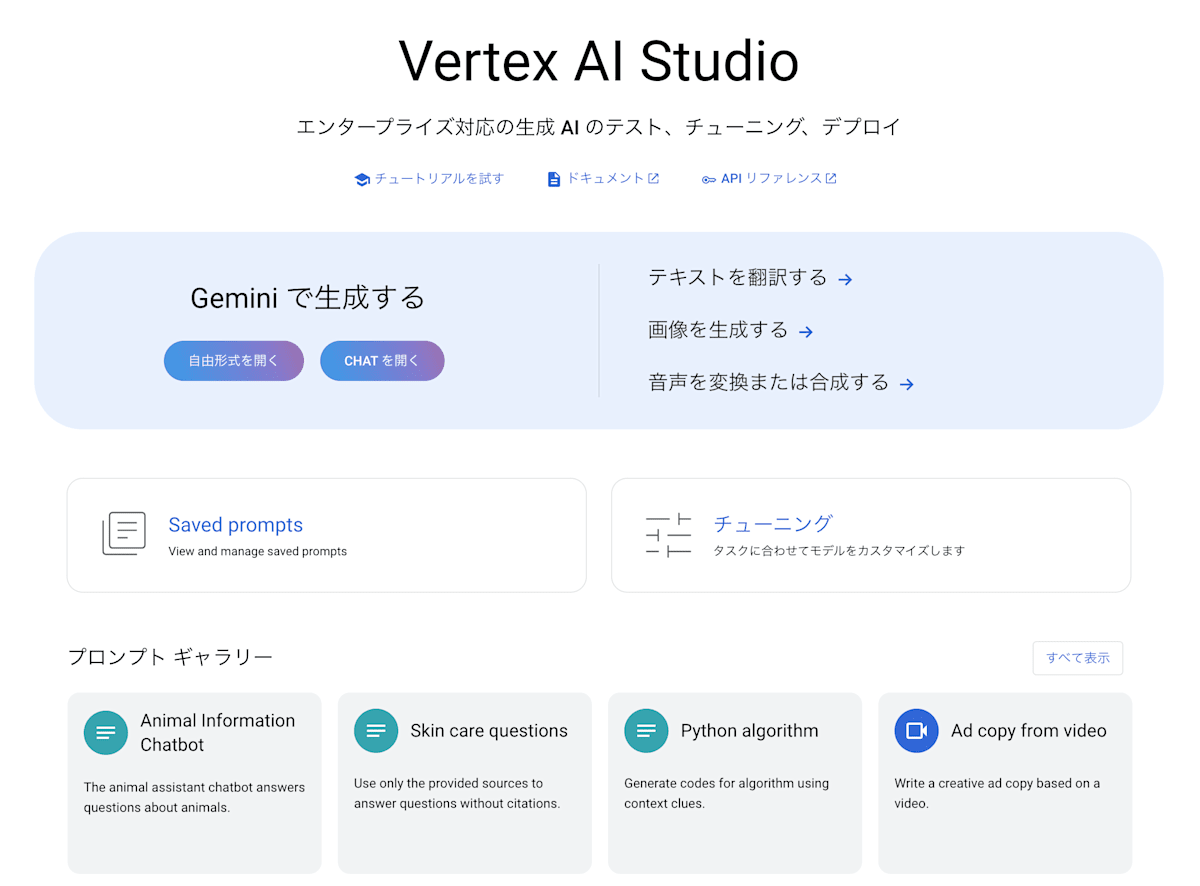
Vertex AI Studio
今回はGUI画面からGeminiを使用します。
2024/09/21現在、GUIから使用できるGeminiの形式は
- 自由形式 (シングルターン)
- チャット形式 (マルチターン)
の2種類あります.
それぞれを見てみましょう.
自由形式

自由形式
自由形式はシングルターンチャットインタフェースでGeminiを使用することができます。
シングルターンチャットとは"ユーザーの入力に対してLLMのレスポンスが返ってくる"という1ターンで対話が終了する形式です。
メッセージ欄に何か入力し、紙飛行機のボタンを押して、返事が返ってくることを確認してみましょう。
チャット形式

チャット形式
チャット形式はマルチターンチャットインタフェースでGeminiを使用することができます。
マルチターンチャットとは、シングルターンの反対です。LLMはユーザーが止めるまで、対話を何往復も続けてくれます。健気ですね.
こちらも入力欄に何か入力してEnterを押し、返事が返ってくることを確認してみましょう。繰り返して対話が可能なこともすぐに確認できるはずです。
入門ユーザーにはチャットボットなどと同じ感覚で使用できるチャット形式が使いやすくオススメです。
本記事ではチャット形式をベースに説明をしていきます。
モデルについて
現在最新のモデルである
- Gemini 1.5 Flash
- Gemini 1.5 Pro
はいずれもマルチモーダルモデルとなっています。
マルチモーダルとは:
ここでのモーダルとはデータ形式のことを指します。基本的なLLMはその名の通り言語(テキスト)のみを入力に受け付けますが、マルチモーダルモデルは多様なデータ形式を入力として受け付けられるように開発されています。Geminiも画像や音声・動画などのデータを入力に含めることが可能です。
ただし、画像・音声・動画を扱えるのは今のところ入力のみです。出力は全てテキストで返ってきます。
では2モデルの違いはなんでしょうか?
2つの差は、一般論としては処理速度と処理性能の差であるとされています。
Flashの方が処理速度が高く、Proの方が処理性能が高い、というトレードオフがあります。
しかしながら、筆者の主観ではFlashも相当な性能を持っています。
料金的にもFlashの方が圧倒的に安く、何事もまずはFlashで試してみるというスタンスで良いでしょう。
料金
気になる料金についてです。

Geminiの料金
公式ドキュメントを引用しました。
| モデル | 機能 | タイプ | 100万字あたり |
|---|---|---|---|
| Gemini 1.5 Flash | マルチモーダル | テキスト入力 | $0.01875 |
| テキスト出力 | $0.075 | ||
| Gemini 1.5 Pro | マルチモーダル | テキスト入力 | $1.25 |
| テキスト出力 | $3.75 |
100万字あたりの料金表
今回はテキストのみでGeminiを利用していきますので、簡単のためテキストのみを対象にし、単位を100万字にした表を用意しました。
小説は平均して10万字/冊程度のようですから、小説10冊分もの入出力を10~1000円程度でできることになります。
特にFlashのコストパフォーマンスは凄まじいです。自分のお財布からでも安心して利用していただけるかと思います。
近年はChatGPTやGemini Advancedなど月額いくらのサービスが複数登場していますが、単純にLLMを使用するだけならVertexAI Studioから使用する方が安いという方も多いのではないでしょうか。
Geminiの使い方
ここではチャット形式で設定できるポイントを紹介します。
チャット形式
画面右側にはパラメタ設定ペインが用意されています。
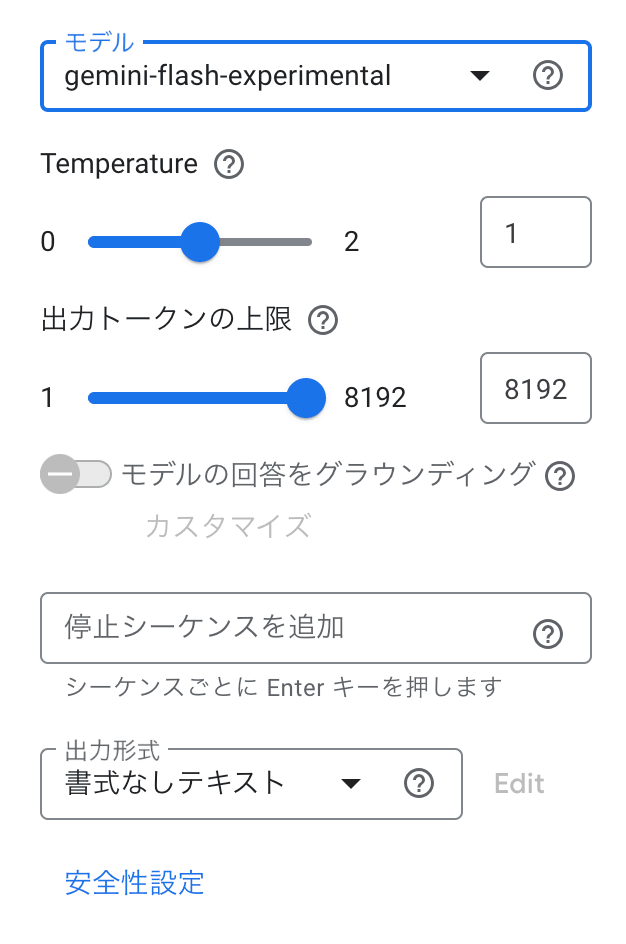
Geminiのパラメタ
上から
- モデル
- Temperature
- 出力トークン上限
- グラウンディング
- 停止シーケンス
- 出力形式
- 安全性設定
となっています。
モデル
モデルを選択できます。ここでFlashや1.5Proを選択できます。
1.0Proなどのモデルも並んでいるかと思いますが、基本的にはコストや性能などの面でFlash・1.5Pro以外を選択するメリットはありません。
Temperature
Flashによる説明を掲載します
LLM(大規模言語モデル)のTemperatureは、出力結果の創造性と確実性のバランスを調整するパラメータです。
簡単に言うと、
Temperatureが高いと、LLMはより創造的で予測不能な出力を生成します。 例えば、詩や物語を生成する際に、より斬新で意外性のある表現が出てくる可能性があります。
Temperatureが低いと、LLMはより確実で予測可能な出力を生成します。 例えば、事実確認や要約など、正確さが求められるタスクに適しています。
イメージとしては、温度が高いと「沸騰したお湯のように活発で色んな方向に飛び散る」、温度が低いと「冷めたお湯のように穏やかで予測しやすい」といった感じです。
Temperatureを調整することで、自分の目的に合ったLLMの出力を得ることができます。
概ねこの通りです。GUIからは0-2の間で選択可能です。こちらの文章はデフォルト値のTemperature=1で作成しました。
出力トークン上限
LLMの出力の上限トークン数を設定します。マルチターンチャットであるチャット形式では1ターン毎の上限トークン数を設定します。
現在の最大値は8192です。
グラウンディング,停止シーケンス
今回は使用しないので割愛します。
出力形式
出力フォーマットを矯正することができます。
現在は"書式なしテキスト"か"JSON"を選択できます。
安全性設定
ユーザーにとってリスクのある出力を制限する度合いを調整します。
Vertex AI Studioでは出力に有害な恐れがある場合はその旨が警告され出力が表示されなくなってしまいます。
デフォルトでは"一部をブロック"の設定になっています。
デフォルトだとプログラミングなどに利用していてもそこそこの頻度で検閲に引っ掛かることがあるので個人で使用する場合には"少量をブロック"にしておくとよいでしょう。

安全性設定
Geminiを使用したSQL文の作成
お待たせしました、本編です。
BigQueryの詳細な説明は共同でチュートリアルをしていただくMarioさんに譲り
BigQuery Studioが利用できることを前提に説明をしていきます。
セットアップ
とはいえ、軽く準備をしておきましょう。
今回はbigquery-public-data.london_bicyclesデータセットを利用します。
BigQuery Studioで次のクエリが実行できることを確認しておきましょう。
SELECT rental_id
FROM `bigquery-public-data.london_bicycles.cycle_hire`
LIMIT 100

サンプルクエリ
SQLとは
SQL(Structured Query Language)は、データベースを操作するための標準的な言語です。データベースとは、構造化されたデータの集まりを指し、例えば、顧客情報、商品情報、売上データなどを格納します。SQLを用いることで、データベースから必要なデータを取り出したり、データを更新したり、新しいデータを追加したり、データを削除したりすることができます。
RDBとデータベースシステム
SQLは、主にリレーショナルデータベース(RDB)を操作するために使われます。RDBとは、データを表形式で管理するデータベースのことです。表は行と列で構成され、行はデータレコード、列はデータ項目を表します。
データベースシステムとは、RDBを管理するためのソフトウェアです。有名なデータベースシステムには、MySQL、PostgreSQL、Oracle Databaseなどがあります。
BigQueryもSQLで操作可能なデータベースシステムです。
注意点として、データベースシステムごとにSQLは少しずつ異なります。方言のようなものですね。
BigQueryにはGoogleSQLというSQLが使用されていますのでインターネットのドキュメントを参照する場合にはどのデータベースシステム・SQLの話をしているかを確認しましょう。
SQLの例
SELECT * FROM Customers;
このコードは、"Customers"という表からすべてのデータを取得するSQL文です。"*"はすべての列を表し、"Customers"はテーブル名です。
SELECT FirstName, LastName FROM Customers WHERE City = 'London';
このコードは、"Customers"という表から、"City"が"London"である顧客の"FirstName"と"LastName"を取得するSQL文です。
これらの例のように、SQLを用いることで、データベースに格納されたデータを柔軟に操作することができます。
例題
さて、ここからGeminiを使用したSQL文の作成を行なっていくにあたってのターゲットとして
テーブル:bigquery-public-data.london_bicycles.cycle_hireに対する例題を用意しておきます。
説明では例題1を取り扱います。例題2-5は自習用です。
例題1:やや簡単
- 2015年7月10日の自転車レンタル回数が多い上位5つのスタートステーションとそのレンタル回数を表示してください。
例題2: やや簡単
- 各レンタル開始地点 (start_station_name) における、平均レンタル時間 (duration) を計算してください。
例題3: 中級
- 週末 (土曜日と日曜日) にレンタルされた自転車の平均レンタル時間と、平日にレンタルされた自転車の平均レンタル時間を比較してください。
例題4: やや難しい
- 各レンタル開始地点 (start_station_name) において、最も多く利用されているレンタル終了地点 (end_station_name) を上位3つ表示してください。
例題5: 難しい
- 時間帯 (0-23時) ごとの平均レンタル時間と、その時間帯におけるレンタル開始地点 (start_station_name) の上位3つを表示してください。
クエリを生成してみる
さっそく、Geminiにクエリを生成してみてもらいましょう。
どのように聞いてみましょうか。まずは例題をそのまま打ち込んでみましょうか...

さすがに、指示が正確に伝わらなかったようです。
情報が不足していますね。何が不足しているでしょうか。まず思いつくのは以下です
- 何をして欲しいか:SQLクエリを作成する
- 何を対象にして欲しいか:テーブルを対象にする
ということで、プロンプト(Geminiへの指示)を以下のようにしてみましょう
プロンプト
テーブル:
bigquery-public-data.london_bicycles.cycle_hireに対するクエリを作成しなさい
2015年7月10日の自転車レンタル回数が多い上位5つのスタートステーションとそのレンタル回数を表示してください。
結果

何ということでしょう、たったこれだけで非常に"らしい"クエリが生成されてしまいました。
さっそく実行してみましょう!

正しくクエリできているようです。
このように、Geminiは非常にシンプルな指示でSQLクエリを生成できることがわかります。
ここで、このプロセスを汎用化するにあたり課題が2点あります。
- london_bicyclesデータセットは非常に著名なオープンデータのため、Geminiがデータセットに関する情報を知っている可能性が高いです。皆さんのお手元にあるデータなどでは、これだけの情報で正確なクエリを作成することは難しいでしょう。
- Geminiが生成したクエリは正常に動作していますが少しおかしなところがあります。生成されたクエリ内のデータセットパス
"bigquery-public-data.london_bicycles.cycle_hire"
はバッククォート囲う範囲がなぜか一部だけになってしまっています。これは大した問題ではありませんが、このようなミスがエラーにつながる場合があるので、人間側でもチェックしてあげる必要があります。
Geminiプログラミングを汎用化するために、続いては、この2つの問題への対処法を考えてみましょう。
データベースの情報をどう与えるか
先ほどの課題1についてです。
この対処法は単純で、情報を追加で与えてあげれば解決します。
もう少し踏み込んでみましょう。データベースの情報とはなんでしょうか。
1つは単純にデータ自体の説明です。どこから取られた、どのようなデータなのかという一般的な説明で良いでしょう。
もう1つ、クエリを作るにあたってのデータベースにおける重要な情報は一般的にはスキーマでしょう。
スキーマとは:
データベースのスキーマとは、データベースの構造を定義する設計図のようなものです。テーブル、列、データ型、関係などの要素を定義し、データベースにどのようなデータが格納され、どのように関連付けられるかを規定します。スキーマはデータベースの設計、構築、管理、データの整合性の維持に不可欠です。
定義だけだとイメージがつきませんね。
テーブル:bigquery-public-data.london_bicycles.cycle_hireのスキーマを確認してみましょう。
実はテーブルを選択すると開く画面がすでにスキーマを表示しています。親切ですね。
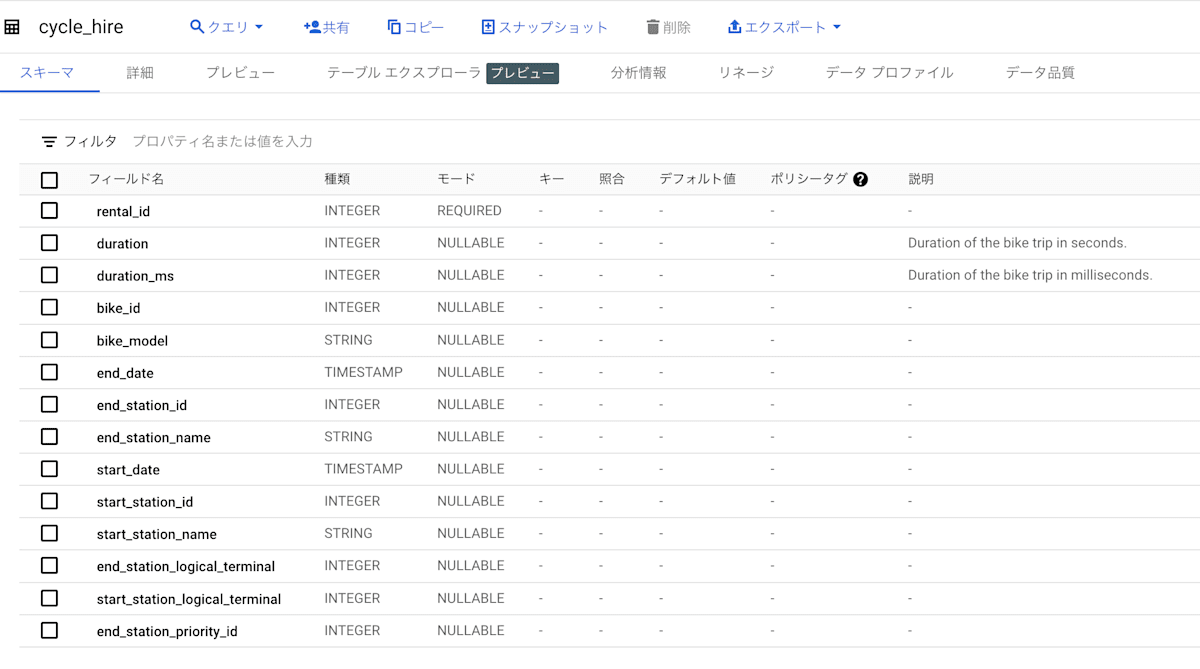
スキーマ画面
画面を読んでみましょう
- フィールド名:列名・カラム名
- 種類:データの型(数字・文字・タイムスタンプなど)
- モード:NULL(欠損)が許されているか。NULLABLEは許され、REQUIREDは許されていない
概ね主要な項目はこれらです。これらを見れば
- なんという名前で列を呼び出せば良いか(フィールド名)
- その列はどのような値でどのような処理に使えるか(種類)
- 欠損が許されているか(モード)
などが一目でわかります。
これをGeminiに与えてあげたらクエリを作る大きな助けになりそうです!
逆にいえば、テーブルを作る際にはフィールド名を解釈性の高い名前にしておくと良いといったTipsがわかりますね。
では今回のテーブルについてどのようにスキーマ情報を用意しましょうか。
試しにスキーマ画面をコピぺしてみました。

コピペする様子
コピペ結果
フィールド名
種類
モード
キー
照合
デフォルト値
ポリシータグ
説明
rental_id
INTEGER REQUIRED - - -
-
-
duration
INTEGER NULLABLE - - -
-
Duration of the bike trip in seconds.
duration_ms
INTEGER NULLABLE - - -
-
Duration of the bike trip in milliseconds.
bike_id
INTEGER NULLABLE - - -
-
-
bike_model
STRING NULLABLE - - -
-
-
end_date
TIMESTAMP NULLABLE - - -
-
-
end_station_id
INTEGER NULLABLE - - -
-
-
end_station_name
STRING NULLABLE - - -
-
-
start_date
TIMESTAMP NULLABLE - - -
-
-
start_station_id
INTEGER NULLABLE - - -
-
-
start_station_name
STRING NULLABLE - - -
-
-
end_station_logical_terminal
INTEGER NULLABLE - - -
-
-
start_station_logical_terminal
INTEGER NULLABLE - - -
-
-
end_station_priority_id
INTEGER NULLABLE - - -
-
-
どうも崩れてしまいますね...
このままだと私たちが読みづらいです。どうしたらいいでしょうか...?
そうですね、Geminiに整理してもらいましょう!
プロンプト
BQのテーブルスキーマ画面をコピーしたテキストを与えます。
それを元にテーブルスキーマをSQL形式で作成してください.
(...ここにスキーマコピペを貼り付け...)

結果
CREATE TABLEというテーブル作成コマンドになってしまっていますが、カッコ内に非常に綺麗にschemaを作成してくれました。
これをプロンプトに追加するのは良い解決方法でしょう!
Geminiのミスをどうするか
2点目です。これは難問です。
この問題は人間のミスと同じため、結局のところ完全な解決法がありません。
ですが、多少緩和する方法があります。
そうですね、Geminiに点検してもらいましょう!
プロンプト
次のクエリを推敲してください
(...ここにクエリを入力...)

クエリの推敲
今回は簡単なクエリなためあまり有益なコメントはありません(というかBETWEENに関しては間違ってそう...)
ですが、Geminiにコメントをもらうことができるとわかります。
ミス・エラーに関しては0にすることはできませんが、Geminiのサポートを受けながら人間とのダブルチェック体制を作っていくのが有用でしょう。
プロンプトエンジニアリング
最後にプロンプトエンジニアリングについてです。
ですが、実はここまでで既にプロンプトエンジニアリングをしていたことにお気づきでしょうか。
プロンプトエンジニアリングとは
ここまでを思い出してみましょう
- はじめに問題文だけをプロンプトとして入力
- 結果を見て、クエリを作成指示、テーブル名という情報をプロンプトに追加した
- より精度や汎用性を求めてデータベースの情報やスキーマを追加できるようにした
これらの取り組みは、生成AIの出力を期待するものに近づけるためプロンプトを改良していくものでした。
このように、プロンプトエンジニアリングとはAIからの出力を所望の形にするためにプロンプトを最適化していく取り組みのことを指します。
プロンプトエンジニアリングには、人に指示を出す際に必要なスキルの多くをそのまま取り入れることができます。具体的には"齟齬が生じにくいよう情報を過不足なく伝える"・"相手が動きやすくするために何をしたら良いのかを明確に定義する"などです。
こうしたテクニックについては、ITやAIに詳しくなくとも、皆さんの日常のスキルが十分に活かせるはずです。
一方で、LLM特有のテクニックも存在します。今回はプロンプト構造化をご紹介します。
プロンプト構造化
プロンプト構造化は、AIモデル、特に大規模言語モデル(LLM)に対して、より効果的に指示や情報を伝えるための手法です。
AIが指示やコンテキストを理解しやすいように、プロンプトをプログラミングなどで使用されるデータフォーマットに整理します。
JSON,Markdown,YAML,TOML,XML etc.などの形式がよく使用されています。
今回は、私が初動でよく使っているTOMLライクなフォーマットを紹介します。
構造化プロンプトサンプル
[task]
- 指示
[conditions]
- 制約1
- 制約2
- 制約3
[context]
- 背景情報
[好きな項目]
...
...
このようなTOMLの各テーブル([task]のような区切り)の中にMarkdownの箇条書きを組み込んだ形式です。
(これは完全に私の好みのフォーマットですので、他のフォーマットより優れていることを保証しません。)
[task]などの項目名は自由に変えて大丈夫です。
こうした構造化の利点は
- AIへの指示の明確化
- 出力の質・一貫性の向上
- 人間の可読性の向上
- プロンプトの再利用性の向上
などです。これらのメリットは実験的にそうであるとされているものであり、理論的に保証されたものではありません。
しかし、いくらか試してみると体感できる程度には効果があるものであると、私は考えています。
では今回、例題に対してやってきたプロンプトエンジニアリングを全て、このプロンプト構造化フォーマットにはめ込んでみましょう。
[task]
- BigQuery用に、[problem]を解くクエリを作成しなさい
[problem]
- 2015年7月10日の自転車レンタル回数が多い上位5つのスタートステーションとそのレンタル回数を表示してください。
[conditions]
- テーブル:bigquery-public-data.london_bicycles.cycle_hireを対象にする
- テーブルのスキーマを[schema]に示す
[schema]
Table:bigquery-public-data.london_bicycles.cycle_hire
```schema
rental_id INTEGER NOT NULL,
duration INTEGER,
duration_ms INTEGER,
bike_id INTEGER,
bike_model STRING,
end_date TIMESTAMP,
end_station_id INTEGER,
end_station_name STRING,
start_date TIMESTAMP,
start_station_id INTEGER,
start_station_name STRING,
end_station_logical_terminal INTEGER,
start_station_logical_terminal INTEGER,
end_station_priority_id INTEGER
```
(このプロンプトを使用した結果、当初のクエリを同じものを出力したため結果は割愛します。)
これまでのプロンプトを単純に代入するだけでなく、少しアレンジメントを加えました。
構造化の効能を分析する
実際にプロンプト構造化をしてみたことによって次のような利点にも気づきました
- 情報の区切りがわかりやすくなった
- 項目を変数として参照できる("[problem]を解くクエリ"など)
クエリを生成してくれたGeminiにも、このプロンプト構造化のメリットを質問してみました
Gemini回答
このプロンプト構造化のメリットは以下の点が挙げられます。
- タスクと問題の明確な分離: タスク(BigQuery用クエリの作成)と問題(具体的な分析内容)を分けて記述することで、私が何をすべきかを正確に理解しやすくなります。
- 条件の明示: 対象テーブルやスキーマ情報を明示的に提示することで、クエリの作成に必要な情報を確実に提供することができます。曖昧さを排除し、誤解を減らすことができます。
- スキーマ情報の提供: スキーマ情報を提供することで、私がテーブル構造を理解し、適切なカラム名やデータ型を用いたクエリを作成することができます。
- 再現性の向上: プロンプトが構造化されていることで、同じタスクを異なるデータセットに適用したり、異なる条件で実行したりする場合でも、プロンプトを少し変更するだけで対応できます。
- 可読性の向上: 全体的に整理された構造になっているため、人間にとっても理解しやすく、内容の確認や修正が容易になります。
これらのメリットにより、私がより正確で効率的にタスクを遂行し、高品質なクエリを生成することに繋がります。
そうですね、私もそう思います。
ついでに次のような質問もしてみました
このプロンプトからあなたはどのように問題を処理したら良いと理解したか説明してください
Gemini回答(構造化ver)
このプロンプトから、私は以下のように問題を処理したら良いと理解しました。
- タスクの把握: まず、"[task]" セクションから、BigQueryで実行可能なSQLクエリを作成することが目的だと理解しました。
- 問題の理解: "[problem]" セクションから、2015年7月10日における自転車レンタル回数の多い上位5つのスタートステーションとそのレンタル回数を求める必要があると理解しました。
-
条件の確認: "[conditions]" セクションから、
bigquery-public-data.london_bicycles.cycle_hireテーブルを対象とし、"[schema]" セクションで提供されるスキーマ情報に従ってクエリを作成する必要があると理解しました。 -
スキーマ情報の活用: "[schema]" セクションで提供されたスキーマ情報から、必要なカラム (
start_station_name,start_date) とそのデータ型を把握しました。 -
クエリの構築: 上記の情報に基づき、以下の処理を行うSQLクエリを構築する必要があると理解しました。
-
start_dateが2015年7月10日のデータのみを抽出 -
start_station_nameでグループ化し、各スタートステーションのレンタル回数 (COUNT(*)) を計算 - レンタル回数が多い順にソート
- 上位5件のみを出力
-
このように、プロンプトの各セクションから必要な情報を抽出し、それらを組み合わせて問題解決に必要な手順を理解しました。そして、最終的にBigQueryで実行可能なSQLクエリを生成しました。
概ね期待した通りにGeminiの思考を誘導できていたようです。
比較として、
テーブル:bigquery-public-data.london_bicycles.cycle_hireに対するクエリを作成しなさい 2015年7月10日の自転車レンタル回数が多い上位5つのスタートステーションとそのレンタル回数を表示してください。
このプロンプトを実行した後に同じ質問をしてみました
Gemini回答(非構造化ver)
このプロンプトを処理するために、私は以下のステップを踏みました。
-
プロンプトの理解: プロンプトは、特定の日付における自転車レンタル回数上位5つのスタートステーションを求めています。対象となるデータは
bigquery-public-data.london_bicycles.cycle_hireテーブルであり、日付は2015年7月10日です。 - 必要な情報抽出: プロンプトから必要な情報は、日付、テーブル名、上位5つのスタートステーションとそのレンタル回数です。
-
SQLクエリの構築: 必要な情報を抽出したら、SQLクエリを構築します。
-
FROM句で対象のテーブルを指定します。 -
WHERE句で日付を2015年7月10日に絞り込みます。 -
GROUP BY句でスタートステーションごとにグループ化します。 -
COUNT(*)で各ステーションのレンタル回数を計算します。 -
ORDER BY句でレンタル回数で降順に並べ替えます。 -
LIMIT句で上位5つの結果のみを取得します。
-
- クエリの出力: 構築したSQLクエリを実行すると、指定された日付における自転車レンタル回数上位5つのスタートステーションとそのレンタル回数が得られます。
つまり、私はプロンプトを解析し、必要な情報を抽出し、BigQuery SQLの知識を用いて適切なクエリを構築することで、問題を解決しました。
これをみると、どちらのプロンプトでも正解はできるわけですが
プロンプト構造化をしていない場合はGeminiが自ら方針を思案しているのに対して
プロンプト構造化をすることにより、Geminiにセクションや指示を強く意識した上で、問題に取り組ませることに成功していることがわかります。
ヒトにとっても可読性向上などのメリットづくしでコストも低い、プロンプト構造化をどうぞマスターしていただければと思います。
終わりに
イベント参加者の方にお土産を用意したくて、今回初めて記事を作成したのですが...読みやすいものになっていたでしょうか。
本記事ではVertex AI Studioのイントロから初めてBigQuery用のSQLをGeminiで作成することを題材にプロンプトエンジニアリングに入門していただきました。
生成AIの挙動には摩訶不思議な部分も多く、プロンプト技法もモデルも今後ますます発展していくでしょう。
本記事で生成AI活用に入門された方には、さらに自分ユーズを深めていっていただければと思います。
何か質問があれば、気兼ねなくコメントください。
例題解答
難易度2: やや簡単
各レンタル開始地点 (start_station_name) における、平均レンタル時間 (duration) を計算してください。
SELECT
start_station_name,
AVG(duration) AS average_duration
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY start_station_name
難易度3: 中級
週末 (土曜日と日曜日) にレンタルされた自転車の平均レンタル時間と、平日にレンタルされた自転車の平均レンタル時間を比較してください。
SELECT
CASE
WHEN EXTRACT(DAYOFWEEK FROM start_date) IN(1, 7) THEN 'Weekend'
ELSE 'Weekday'
END AS day_type,
AVG(duration) AS average_duration
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY day_type
難易度4: やや難しい
各レンタル開始地点 (start_station_name) において、最も多く利用されているレンタル終了地点 (end_station_name) を上位3つ表示してください。
SELECT
start_station_name,
end_station_name,
COUNT(*) AS trip_count
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY 1, 2
QUALIFY ROW_NUMBER() OVER (PARTITION BY start_station_name ORDER BY trip_count DESC) <= 3
難易度5: 難しい
時間帯 (0-23時) ごとの平均レンタル時間と、その時間帯におけるレンタル開始地点 (start_station_name) の上位3つを表示してください。
WITH HourlyRental AS (
SELECT
EXTRACT(HOUR FROM start_date) AS hour,
start_station_name,
AVG(duration) AS average_duration
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY 1, 2
),
RankedStations AS (
SELECT
hour,
start_station_name,
average_duration,
ROW_NUMBER() OVER (PARTITION BY hour ORDER BY average_duration DESC) AS station_rank
FROM
HourlyRental
)
SELECT
hour,
start_station_name,
average_duration
FROM
RankedStations
WHERE station_rank <=3
ORDER BY hour, average_duration DESC
Discussion