Swift で数値を高速的に読み込む方法
背景
競技プログラミングや、データファイルを読み込む場面で、文字列を数値配列に変換する必要がたまにあります。データ量が大きくなると、違う読み込む方法の速度の差も大きくなるため、この記事では、筆者は様々な方法を試して、最速の1つを探求していこうと思います。
やることは、Swift で、"45 90 20 86 77 12"のような文字列を、[45, 90, 20, 86, 77, 12] 配列に変換すること。
環境
本文のコードは全部 Swift 5.5(Xcode 13.0 beta 2)で release mode で実行するもの。性能計測は Google の swift-benchmark を使います。
入力文字列は、20万個10000以内の乱数で生成して、計測結果はすべて同じ文字列に基づいたもの。
let inputline: String = (0..<20_0000)
.map { _ in String(Int.random(in: 0..<10000)) }
.joined(separator: " ")
// inputline == "4589 8990 2020 86 5877 9712..."
また、本文のコードは想定外の事態、エラー処理に対応していません。では。
最適化していこう
Step1: String.split
はじめに、よく使われている方法はこちら。
benchmark("String.split") {
let _ = inputline
.split(separator: " ")
.map { Int($0)! }
}
入力文字列をスペースで分割し、その結果の Substring らを Int に変換する、という誰もか使ったことのある極めてシンプルな方法です。
結果
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
Step2: UTF8View.split
String 型を Collection として繰り返し処理する時、 Character ごとにアクセスしているが、より低いレベルの UTF8.CodeUnit(UInt8 の typealias) 表現でアクセスすると、処理が早くなります。
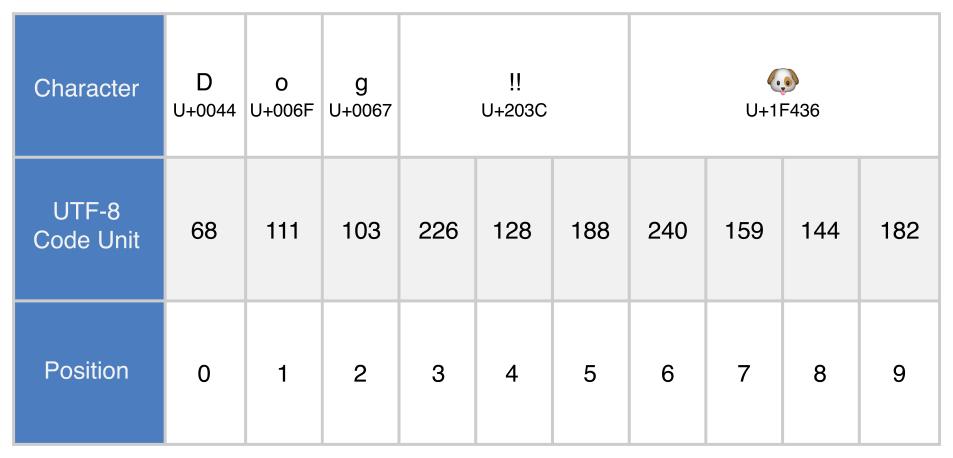
なぜかと言うと、上図のよう、ASCII 時代の1文字(D, o, g)を codeUnit 1つで表せるが、今では、1つの Unicode 文字(🐶)は複数の codeUnit で表しています。更に、👨👩👧 == 👨 + 👩 + 👧 みたいに、一つの絵文字は複数の絵文字の組み合わせということもあります。
このような多種多様な文字に正確に対応できるようにするため、Swift はすべての文字を Character に標準化してから開発者に使わせています。便利な特性だが、少しの性能損失もある:Character を繰り返す時、次の Character に何個の codeUnit があるか、そして codeUnit が複数含んでいる場合、それらを1つの Character に合成するという検査と作業が必要で、そこに時間がかかります。
String を UTF-8 表現にすると、この文字列にある文字が全部 codeUnit 1つで表せると宣言します。そうすると上述の検査作業がスキップされ、文字操作がより高速にできます。
benchmark("UTF8View.split") {
let _ = inputline.utf8
.split(separator: UTF8.CodeUnit(ascii: " ")) // 1
.map { Int(Substring($0))! } // 2
}
-
String.utf8を使うと文字列が UTF-8 表現になり、型がString.UTF8Viewになります。UTF8ViewはUTF8.CodeUnitのコレクションであるため、分離操作の separator もUTF8.CodeUnitにしなければなりません。この場合はUTF8.CodeUnit(ascii: " ")で、スペースの UTF-8 表現を使います。 -
String.UTF8Viewから直接にIntを初期化することができないため、Substringの中間層を入れて行います。
結果
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
UTF8View.split 23677.767 us ± 3.53 %
Step3: Parse Int
上記2つの方法では、配列操作が二回行われた:split で文字列を分離して [Substring] にする時と、map で [Substring] を [Int] に変換する時。
この場合、中間層となった [Substring] の初期化や append 操作に少し時間がかかったと考えられます。もし [Substring] を通さずに、文字列を分離しながら直接 Int に変換すると、読み込みがより速くなります:
func parseIntByIndex(_ text: String) -> [Int] {
let utf8View = text.utf8
let _space = UTF8.CodeUnit(ascii: " ")
var numbers: [Int] = []
var startIndex = utf8View.startIndex
for endIndex in utf8View.indices {
if utf8View[endIndex] == _space {
let number = Int(Substring(utf8View[startIndex..<endIndex]))!
numbers.append(number)
startIndex = utf8View.index(after: endIndex)
}
}
return numbers
}
やってることは split と map を1つの for...in に書き換えるだけ:文字列のインデックスを繰り返し、個々の文字にアクセスし、スペースが会ったら対応部分のスライスを抽出して整数に変換する。
結果
benchmark("Parse Int by index") {
let _ = parseIntByIndex(inputline)
}
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
UTF8View.split 23677.767 us ± 3.53 %
Parse Int by index 13785.251 us ± 6.47 %
Step4: reserveCapacity
Step 3 の実現でこの2行に注目してください:
var numbers: [Int] = []
numbers.append(number)
Swift の配列は、最初は少ないメモリしか使用しないが、要素の追加につれて新しいメモリを要求し続ける仕様になっています。つまり、要素数が現在割り当てられてるメモリに収容できる範囲を超えた場合、配列は新しいメモリを要求します。もし事前に要素数が分かっていた場合、reserveCapacity(minimumCapacity:) を使うことで、事前に要素数分のメモリを確保し、何回のメモリ要求作業が省け、時間を節約することができます。
+func parseIntWithReserveCapacity(_ text: String, N: Int) -> [Int] {
/* ... */
var numbers: [Int] = []
+ numbers.reserveCapacity(N)
/* ... */
}
結果
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
UTF8View.split 23677.767 us ± 3.53 %
Parse Int by index 13785.251 us ± 6.47 %
reserveCapacity 12324.345 us ± 4.06 %
Step5: Parse Int by Digit
上述の方法では、インデックスを沿って文字を1つずつスキャンし、スペースに会った場合、前にスキャンした部分を取り出して、Int初期化関数に渡すとうい仕様になっています。
しかし、取り出された Substring は、Intの初期化関数内部で、もう一度読み込まれることが容易に想像できるでしょう。つまり、文字列が2回読まれているということです。
もし、文字列を一文字ずつ読み込んでいる最中に、既に整数の初期化を始められたとすれば、より速くなるでしょう。
これからの実装、基本的に Int 初期化関数のソースコードをアレンジしたものです:
func parseIntByDigit(_ text: String, N: Int) -> [Int] {
// 1
let _0 = UTF8.CodeUnit(ascii: "0")
let _space = UTF8.CodeUnit(ascii: " ")
var numbers: [Int] = []
numbers.reserveCapacity(N)
// 2
var value: Int = 0
// 3
for codeUnit in text.utf8 {
if codeUnit != _space {
// 4
value &*= 10
// 5
value &+= Int(codeUnit &- _0)
} else {
// 6
numbers.append(value)
value &= 0
}
}
return numbers
}
-
"0"と" "の UTF8 表現。 - 現在読まれている数値のバッファー。
- 文字列の UTF8 表現を一文字ずつアクセス。
- もし文字が数値であれば、前のバッファーを十倍にする。十進数表現から見ると、数値を、1桁左に移動して、読み取った数値文字を右に追加する、という動きです。
-
UTF8.CodeUnitとなった数字文字をIntに変換するため、その文字が ASCII 表において"0"までの距離を取って整数値になります。 - 文字がスペースだったら、バッファーを1つの数値として読み切ったと判定する。
また、各演算子が通常の *= ではなく、 &*= になることに注目してください。通常の演算子は、オーバーフローのチェックも入っていて、& をつけることで、そのチェックも省けます。
結果
benchmark("Parse Int by digit") {
let _ = parseIntByDigit(inputline, N: 20_0000)
}
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
UTF8View.split 23677.767 us ± 3.53 %
Parse Int by index 13785.251 us ± 6.47 %
reserveCapacity 12324.345 us ± 4.06 %
Parse Int by digit 2147.006 us ± 8.13 %
速度が爆上げましたね。
Step6: UTF8View.withContiguousStorageIfAvailable
Int 初期化関数のソースコードを覗いてみると、もう1つの注意点があります。UTF8View を繰り返しアクセスする時、通常の for...in ではなく、withContiguousStorageIfAvailable を使ったことです。
この両者に違いを説明すると、for...in ループは、単純にインデックスを沿って文字を1つずつアクセスするだけです。そのため、インデックスの生成にも、インデックスを使って文字列中の文字にアクセスするにも、時間がかかります。一方、withContiguousStorageIfAvailable はポインターを使っていて、メモリから直接に文字にアクセスできて、インデックスに関する手間が省けます。
func parseIntWithContiguousStorage(_ text: String, N: Int) -> [Int] {
let _0 = UTF8.CodeUnit(ascii: "0")
let _space = UTF8.CodeUnit(ascii: " ")
var numbers: [Int] = []
numbers.reserveCapacity(N)
var value: Int = 0
+ text.utf8.withContiguousStorageIfAvailable { codeUnits in
+ for ascii in codeUnits {
if ascii != _space {
value &*= 10
value &+= Int(ascii &- _0)
} else {
numbers.append(value)
value &= 0
}
}
}
return numbers
}
結果
name time std
--------------------------------------------------
String.split 39640.806 us ± 4.07 %
UTF8View.split 23677.767 us ± 3.53 %
Parse Int by index 13785.251 us ± 6.47 %
reserveCapacity 12324.345 us ± 4.06 %
Parse Int by digit 2147.006 us ± 8.13 %
utf8.WithContiguousStorage 885.438 us ± 15.04 %
速度がまだ一段上がりました。これが最後になります。
まとめ
この記事では、文字列から数値配列を高速に読み込む方法と原理を探究しました。結果から見ると、最もシンプルな String.split 方法に比べて、ポインターを使った文字ごとに読み込む方法が 45 倍速くなりました。
しかし、こういった数値を読み込むことがある時に、この方法を愚直に使う必要はない場合もあります。なぜなら、プログラミングは、速度が第一じゃない、コード量、可読性も時に同じ重要性が持っています。
最終的に、筆者は 「Step2: UTF8View.split」と「Step6: parseIntWithContiguousStorage」の2つをおすすめします。後者の実行速度がほぼ前者の25倍になりますが、実際にどの方法を使うかは、読み込む要素の個数、コード量、可読性などの方面から考慮しなければなりません。例えば、競プロやコーディングテストみたいな、個数が少なく、コードの量と簡潔性に要求がある場合、UTF8View.split は十分で;アプリでデータサイズが大きく、かつフォーマットが固定されたファイルを読み込むときは、parseIntWithContiguousStorage のような方法でいきましょう。
また、他の方法も試しましたが([Int].init(unsafeUninitializedCapacity:)、[Int].withUnsafeMutableBufferPointer)、効果がいまいちなので紹介しないことにしました。興味のある方はぜひ試してください。
以上です。なにか感想やコメントをいただけると幸いです!
What’s next?
- Point-Free の『Parsing』コースで、整数だけじゃなく、いかなるデータをどうやって高速、優雅に読み込むのかを学べます。
- objc.io が出版した『Advanced Swift』の Strings 章では、Swift の文字列について詳しく説明しました。
Discussion