自作OSにprintfを実装する
概要
printfに代表される可変長引数関数の仕組みを調べ、muslの実装を読み、それを自作OSにフルスクラッチで実装するという試みです。タイトルにはprintfとありますが、現状自作OSにメモリ管理機能なんてない(mallocなんてない)のでまずvsnprintfを実装し、それを用いてprintf(もどき)を作ることにします。環境はx64を前提とします。
標準ライブラリで実装してみる
最終的にはフルスクラッチで実装しますが、完成形を見ておこうということで標準ライブラリを用いて実装してみます。
#include <stdio.h>
#include <stdarg.h>
#define BUF_SIZ 100
void myprintf(char *fmt, ...) {
char buf[BUF_SIZ];
va_list ap;
int ret;
va_start(ap, fmt);
ret = vsnprintf(buf, BUF_SIZ, fmt, ap);
printf("buf = %s\n", buf);
va_end(ap);
}
int main(void) {
myprintf("%d, %d, %d", 1, 2, 3);
return 0;
}
これをコンパイル&リンクして実行すると出力は以下のようになります。
buf = 1, 2, 3
これをフルスクラッチで実装するのが最終目標です。そのためにはここに出てくるva_start,va_argやvsnprintfが何をしているのか理解しなければなりません。こんな面倒なことしなくてもMikan本のようにNewlibを使えば簡単に実装できるのですが、バイナリアンたるもの、仕組みの分からないバイナリなんて使えない(使えます)のでフルスクラッチで実装します。
可変長引数関数の仕組み
可変長引数関数は「何をしたいのか」を意識することで簡単に理解できます。可変長引数関数はその名の通り任意個の引数を受け取るため、n番目の引数にアクセスできる必要があります。引数の渡し方はABIによって異なるため、va_listやva_argの実装は環境によって異なります。実際、stdarg.hを見てみると以下のようなdefine命令があります。コンパイラは__builtin*を環境に応じて適切なバイナリに置き換えてくれます。このおかげでABIなんて知らなくてもva_startやva_argを使うことで可変長引数関数を実装できるのです。
#define va_start(ap, param) __builtin_va_start(ap, param)
#define va_end(ap) __builtin_va_end(ap)
#define va_arg(ap, type) __builtin_va_arg(ap, type)
以下では特にSystem V x64 ABIの場合について__builtin*が何をしているのかを説明します。
System V x64 ABIについて
可変長引数関数の実装にとって重要なのは関数の引数の渡し方です。System V x64 ABIでは関数の引数は以下のように渡すと定められています。
| 第一引数 | 第二引数 | 第三引数 | 第四引数 | 第五引数 | 第六引数 |
|---|---|---|---|---|---|
| rdi | rsi | rdx | rcx | r8 | r9 |
なお、浮動小数点数の場合はxmm0, xmm1 ... の順で渡します。これ以上の引数を渡す場合はスタック渡しになります。実際、以下のようなサンプルプログラムを作ります。
extern void func(int, int, int, int, int, int, int);
int main(void) {
func(1, 2, 3, 4, 5, 6, 7);
return 0;
}
これをコンパイルして機械語を見てみると、確かに引数がこの順番でレジスタに格納され、7つ目の引数である7はスタックで渡されていることが確認できます。
$ gcc -c sample.c
$ objdump -d -M intel sample.o
sample.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 48 83 ec 08 sub rsp,0x8
c: 6a 07 push 0x7
e: 41 b9 06 00 00 00 mov r9d,0x6
14: 41 b8 05 00 00 00 mov r8d,0x5
1a: b9 04 00 00 00 mov ecx,0x4
1f: ba 03 00 00 00 mov edx,0x3
24: be 02 00 00 00 mov esi,0x2
29: bf 01 00 00 00 mov edi,0x1
2e: e8 00 00 00 00 call 33 <main+0x33>
33: 48 83 c4 10 add rsp,0x10
37: b8 00 00 00 00 mov eax,0x0
3c: c9 leave
3d: c3 ret
va_start(ap, last)の仕組み
cでは関数の引数に...と書く事でこれが可変長引数関数であるとコンパイラに教えることができます。引数に...が指定されている場合、(x64では)コンパイラは引数に使われる可能性のあるレジスタをスタックに退避するための機械語を出力します。実際、以下のようなサンプルプログラムを作ります。
void func(char *dummy, ...) {}
これをコンパイルして機械語を見てみると確かに引数に使われる可能性のあるレジスタがスタックに退避されています。
$ gcc -c sample.c
$ objdump -d -M intel sample.o
sample.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 48 83 ec 48 sub rsp,0x48
c: 48 89 bd 48 ff ff ff mov QWORD PTR [rbp-0xb8],rdi
13: 48 89 b5 58 ff ff ff mov QWORD PTR [rbp-0xa8],rsi
1a: 48 89 95 60 ff ff ff mov QWORD PTR [rbp-0xa0],rdx
21: 48 89 8d 68 ff ff ff mov QWORD PTR [rbp-0x98],rcx
28: 4c 89 85 70 ff ff ff mov QWORD PTR [rbp-0x90],r8
2f: 4c 89 8d 78 ff ff ff mov QWORD PTR [rbp-0x88],r9
36: 84 c0 test al,al
38: 74 20 je 5a <func+0x5a>
3a: 0f 29 45 80 movaps XMMWORD PTR [rbp-0x80],xmm0
3e: 0f 29 4d 90 movaps XMMWORD PTR [rbp-0x70],xmm1
42: 0f 29 55 a0 movaps XMMWORD PTR [rbp-0x60],xmm2
46: 0f 29 5d b0 movaps XMMWORD PTR [rbp-0x50],xmm3
4a: 0f 29 65 c0 movaps XMMWORD PTR [rbp-0x40],xmm4
4e: 0f 29 6d d0 movaps XMMWORD PTR [rbp-0x30],xmm5
52: 0f 29 75 e0 movaps XMMWORD PTR [rbp-0x20],xmm6
56: 0f 29 7d f0 movaps XMMWORD PTR [rbp-0x10],xmm7
5a: 90 nop
5b: c9 leave
5c: c3 ret
va_startはこれを使ってva_listを初期化します。va_listはx64の場合は以下のように定義されています。各変数の意味はコメントの通りです。
typedef struct {
unsigned int gp_offset; // reg_save_areaから次に利用可能なgenerel purpose registerへのoffset
unsigned int fp_offset; // reg_save_areaから次に利用可能なfloating point registerへのoffset
void *overflow_arg_area; // スタックで渡された引数が保持されているメモリ領域へのポインタ
void *reg_save_area; // レジスタで渡された引数が保持されているメモリ領域へのポインタ
} va_list[1];
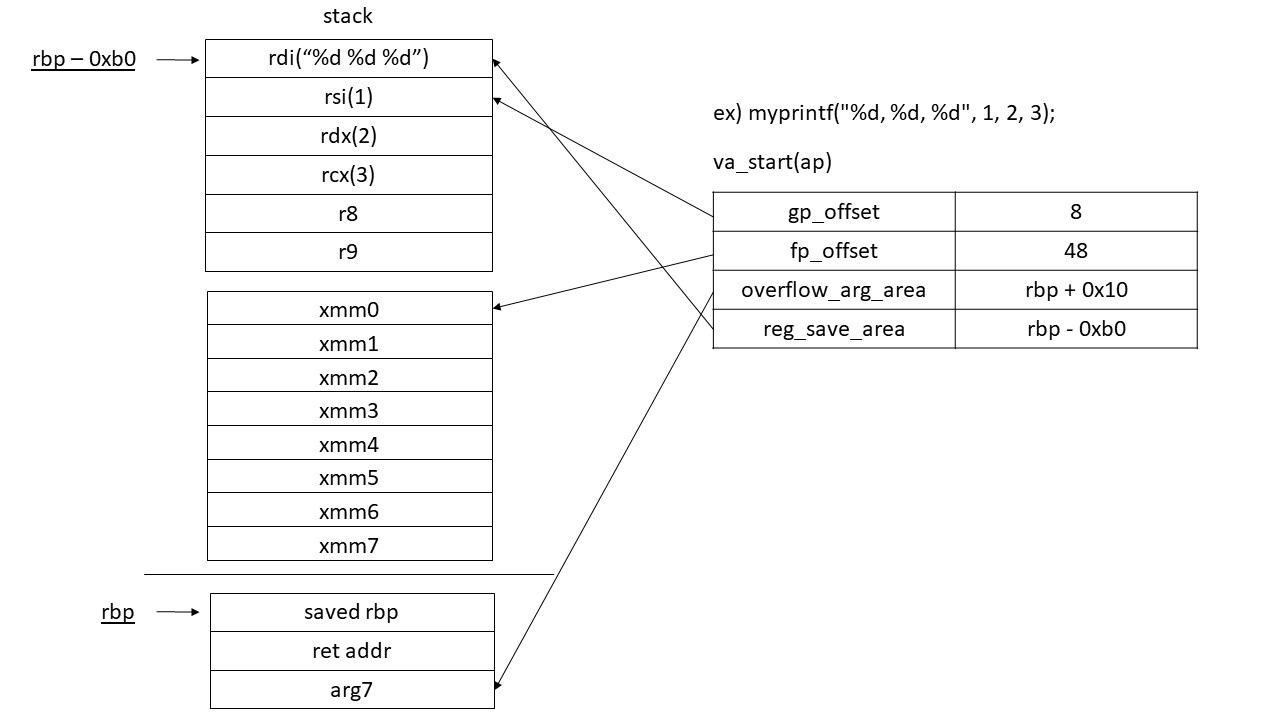
va_list apを定義してva_start(ap)を呼ぶと、va_startはapの各変数を以下のようにセットします。n1、n2はそれぞれ...の前に使用されている汎用レジスタ、浮動小数点レジスタの数で、rbp - 0xb0は関数の先頭でレジスタを退避した先の先頭アドレスです。(前の出力を確認してください。私の環境ではrbp - 0xb0固定でした)
| gp_offset | fp_offset | overflow_arg_area | reg_save_area |
|---|---|---|---|
| 8 * n1 | 48 + 16 * n2 | rbp + 0x10 | rbp - 0xb0 |
実際、一番最初のサンプルプログラムの機械語を見てみます。(コンパイルオプションにgを、objdumpのオプションにSを指定すると機械語に対応するソースコードを表示できます)
va_start(ap, fmt);
11f8: c7 85 c8 fe ff ff 08 mov DWORD PTR [rbp-0x138],0x8
11ff: 00 00 00
1202: c7 85 cc fe ff ff 30 mov DWORD PTR [rbp-0x134],0x30
1209: 00 00 00
120c: 48 8d 45 10 lea rax,[rbp+0x10]
1210: 48 89 85 d0 fe ff ff mov QWORD PTR [rbp-0x130],rax
1217: 48 8d 85 50 ff ff ff lea rax,[rbp-0xb0]
121e: 48 89 85 d8 fe ff ff mov QWORD PTR [rbp-0x128],rax
最初のサンプルプログラムでは
myprintf("%d, %d, %d", 1, 2, 3);
で関数を呼び出していました。...の前に渡されている引数は1つであるためgp_offsetは8に、浮動小数点レジスタは使っていないためfp_offsetは8 * 6 = 48に、overflow_arg_areaはrbp + 0x10に、reg_save_areaはrbp - 0xb0になっています。以下の図を見ると分かりやすいかもしれません。
va_arg(ap, type)の仕組み
サンプルプログラムを作ります。
#include <stdio.h>
#include <stdarg.h>
void func(char *dummy, ...){
va_list ap;
int i;
va_start(ap, dummy);
i = va_arg(ap, int);
printf("%d\n", i);
}
int main(void) {
func("dummy", 1, 2 ,3);
}
これをコンパイル&リンクして実行してすると出力は以下のようになります。
1
va_argは...の部分に渡された引数を順番に返します。実際、上のva_arg(ap, int)の呼び出しによって...の部分の最初の引数である1が返っています。va_argはx64の場合、以下のように動作します。
- typeが浮動小数点型でなく、かつgp_offset < 48の場合、次の引数はreg_save_are + gp_offsetにあるため、そこから8byte読んでgp_offsetに8を加えます。
- typeが浮動小数点型で、かつfp_offset < 128の場合、次の引数はreg_save_are + fp_offsetにあるため、そこから16byte読んでfp_offsetに16を加えます。
- typeが浮動小数点型でなく、かつgp_offset > 48の場合、次の引数はoverflow_arg_areaにあるため、そこから8byte読んでoverflow_arg_areaに8を加えます。
- typeが浮動小数点型で、かつfp_offset > 128の場合、次の引数はoverflow_arg_areaにあるため、そこから16byte読んでoverflow_arg_areaに16を加えます。
以上の仕組みで可変長引数関数はn番目の引数にアクセスすることができます。可変長引数関数は引数が実際に渡されたかどうかは気にしません。n番目の引数を取ってこいと言われたら、それが渡されていると期待してn番目の引数を読みに行きます。このことは脆弱性にもなり、例えばこの仕組みを悪用することでスタックの内容を読み出したり、任意のアドレスに書き込みを行ったりするFormat String Attackという攻撃手法が知られています。va*系の関数はva_start,va_argの他にva_copyとva_endがあります。va_copyはva_copy(ap1, ap2)のように使い、ap1にap2の内容をコピーします。元のva_list変数に影響を与えないという点で有用です。va_endについては何をしているのか良く分からなったため、説明を省きました。(実際、大抵の環境では何もしないようです。)
実装を考えてみる
フォーマット文字列の全ての命令を実装するのは面倒くさいので、欲しいモノのみを実装することにします。独断と偏見で以下の命令を実装することにしました。
| フラグ文字 | 変換指定子 |
|---|---|
| #, 0, ' ', '+', '-' | d, u, x, X, c, s, p |
最小フィールド幅や精度の指定はやる気の出る範囲で実装することにします。長さ修飾子は実装しません。
仕様を確認してみる
実装する前に使用を調べておきます。
printf() 関数グループは、以下で述べるように、 format に従って出力を生成するものである。
フォーマット文字列は文字の列で、 (もしあるなら) 初期シフト状態で始まり、初期シフト状態で終わる。 フォーマット用の文字列は 0 個以上の命令 (directives) によって構成される。 命令には、通常文字と変換指定 (conversion specifications) がある。 通常文字は % 以外の文字で、出力ストリームにそのままコピーされる。 変換指定は、それぞれが 0 個以上の引数を取る。 各変換指定は文字 % で始まり、 変換指定子 (conversion specifier) で終わる。 % と変換指定子の間には、0 個以上の フラグ 、 最小 フィールド幅 、 精度 、 長さ修飾子 を (この順序で) 置くことができる。
全ての仕様は多すぎて書ききれないため、各自で確認してください。ここでは今回実装するものに限って説明します。
フラグ文字
- #
xまたはX変換かつ数値が0でない場合、先頭に"0x"または"0X"を付加します。
printf("%#x\n", 16); // 0x10
- 0
変換した値の左側を空白文字の代わりに0で埋めます。-と同時に指定された場合と、精度が数値変換(d, i, o, u, x, X)と同時に指定された場合は無視されます。
printf("%04x\n", 16); // 0010
printf("%8.4x\n", 16); // 0010
printf("%08.4x\n", 16); // 0010 0フラグは無視され、左側は空白スペースで埋められる
- -
変換値を左詰めで表示します。(デフォルトでは右詰め)変換された値の右側が空白文字で埋められます。0と同時に指定された場合は-が優先されます。
printf("%-4X\n", 16); // 10
printf("%0-4x\n", 16); // 10 0フラグは無視され、左詰めで表示される
- ' '
符号付きで変換された正の数字の前に空白文字を置きます。+と一緒に指定された場合は無視されます。
printf("% d\n", 16); // 16 先頭に空白スペースが入る
printf("% +d\n", 16); // +16 ' 'は無視される
- +
符号付き変換によって出力される数字の前に常に符号を置きます。(デフォルトでは負の場合のみ)' 'と同時に指定された場合は+が優先されます。
printf("%d\n", 16); // 16
printf("%+d\n", 16); // +16 正の場合も符号がつく
最小フィールド幅
最小フィールド幅は"+"や"0X"を含めた全体の長さを指定するもので、10進数の数値文字列で指定します。最小値なので全体の長さが指定された長さよりも大きい場合は無視され、足りない分は空白スペース(0フラグが指定されている場合は0)で埋められます。負の数が指定された場合は-フラグと最小フィールド幅と解釈されます。10進数の代わりに*や*m$の形で指定することもできますが、これは実装しません。
printf("%8d\n", 16); // 16
printf("%0+8d\n", 16); // +0000016
printf("%-8d\n", 16); // 16
精度
精度はd, i, o, u, x, X変換では表示される最小の桁数、s変換では出力されるバイト数を指定するもので、'.'(ピリオド)とそれに続く10進数という形で指定します。精度として'.'のみが指定された場合は精度は0とみなされ、負の値が指定された場合は精度は指定されなかったとみなされます。最小フィールド幅と同様に*や*m$の形で指定することもできますが、これは実装しません。
printf("%8.4d\n", 16); // 0016
printf("%08.4d\n", 16); // 0016 0フラグは無視され、空白文字で埋められる
printf("%8.d\n", 16); // 16 精度は0だが最小の桁数なので16が表示される
printf("%08.*d\n", -4, 16); // 00000016 精度は無視されるので0で埋められる
変換指定子
- d
int引数を符号付き10進表記に変換します。精度指定があれば精度で指定した桁数は必ず出力され、足りない分は0で埋められます。精度のデフォルトは1で、0を表示するときに明示的に精度が0に指定されている場合、出力は空文字になります。
printf("%.4d\n", 16); // 0016
printf("%.1d\n", 0); // 0
printf("%.0d\n", 0); //
- u, x, X
unsigned int引数を符号なし10進数(u)、符号なし16進数(x, X)に変換します。精度指定があれば精度で指定した桁数は必ず出力され、足りない分は0で埋められます。
printf("%.4u\n", 16); // 0016
printf("%.4x\n", 16); // 0010
- c
int引数をunsigned charに変換してその結果に対応する文字を出力します。
printf("%c\n", 0x41); // A
- s
文字列へのポインタを受け取り、null byteまで出力します。精度が指定されている場合は指定されたバイト数まで出力されます。
printf("%s\n", "abcdef"); // abcdef
printf("%.3s\n", "abcdef"); // abc
- p
void *ポインタ引数を16進数で出力します。
printf("%p\n", "abcdef"); // 0x5623ed836004(一例)
muslの実装を見てみる
自分で0から考えて作るのもいいですが、先人に学ぼうということでmuslの実装、特にvsnprintfの実装を読んでみます。コードの全てを説明するのは私の力量的に無理なので、私が理解している範囲で所々かいつまんで説明します。コードは以下にあります。
sn_write関数は後で変換結果をバッファに書き込む際に使用されます。vsnprintf関数は適宜引数をセットした後にvfprintfを呼び出しています。
フォーマット文字列処理するのはprintf_core関数です。vfprintfは処理の先頭でこの関数を第一引数0で呼び出しています。これにはフォーマット文字列が受理できるか確認する意味と、ダイレクトパラメータアクセスが使用されている場合に用いられるnl_argをセットする意味があります。フォーマット文字列が正しくない場合はこの部分でエラーになります。printf_core関数のコードを読んで見ましょう(長いので載せません。各自で参照してください)
printf_coreが呼ばれると、フォーマット文字列へのポインタがsにセットされ、forループに入ります。以下の部分から分かるように、*sがnull byteになるまで処理が繰り返されます。lは1回のループで出力されたバイト数、cntは今までに出力されたバイト数です。
cnt += l;
if (!*s) break;
for (a=s; *s && *s!='%'; s++);
for (z=s; s[0]=='%' && s[1]=='%'; z++, s+=2);
if (z-a > INT_MAX-cnt) goto overflow;
l = z-a;
if (f) out(f, a, l);
if (l) continue;
if (isdigit(s[1]) && s[2]=='$') {
l10n=1;
argpos = s[1]-'0';
s+=3;
} else {
argpos = -1;
s++;
}
最初に'%'までの文字列が出力されます。z - aは'%'までの文字列の長さです。以下の部分では文字列の長さがINT_MAX - cntよりも大きくないかチェックされています。
if (z-a > INT_MAX-cnt) goto overflow;
このチェックが入るのは今までに出力したバイト数を保持するcntがint型だからでしょう。
出力を行っているのはout関数で、最終的に先ほどのsn_write関数が呼び出されます。printf_core関数の第一引数がNULLの場合はout関数は呼ばれないため、入力が不正でないか確かめられるだけです。(賢いですね)この後の処理に進むのはlが0の場合、即ちz=aとなる場合で、これはつまり初期状態で*s = '%'になっている場合です。以下の図が分かりやすいかも知れません。ちなみに2つ目のfor文は'%'を出力するための処理です。フォーマット文字列内で"%%"が指定されている場合は'%'が出力されます。

続くif文はダイレクトパラメータアクセスのための処理です。今回ダイレクトパラメータアクセスは実装しないので飛ばします。ダイレクトパラメータアクセスでない場合はargposは-1となり、s++が実行されるので、sは'%'の次を指すことになります。次の部分でフラグ文字を読んでいます。関連するコードを以下に示します。
#define ALT_FORM (1U<<'#'-' ')
#define ZERO_PAD (1U<<'0'-' ')
#define LEFT_ADJ (1U<<'-'-' ')
#define PAD_POS (1U<<' '-' ')
#define MARK_POS (1U<<'+'-' ')
#define GROUPED (1U<<'\''-' ')
#define FLAGMASK (ALT_FORM|ZERO_PAD|LEFT_ADJ|PAD_POS|MARK_POS|GROUPED)
for (fl=0; (unsigned)*s-' '<32 && (FLAGMASK&(1U<<*s-' ')); s++)
fl |= 1U<<*s-' ';
flは指定されたフラグを保持しておくための変数です。まず*s - ' 'が32以下かチェックされています。これはflがint型で、32bitだからでしょう。' 'を0として順に番号を振ることで各フラグに固有の数を割り当てることができ、この数を左シフトする回数に指定することでフラグが実装されています。このチェックのみでは*sはSP~'?'を取れますが、続くFLAGMASK&(1U<<*s-' ')の部分で有効なフラグかチェックされています。続いて、以下の部分で最小フィールド幅を読んでいます。
if (*s=='*') {
if (isdigit(s[1]) && s[2]=='$') {
l10n=1;
if (!f) nl_type[s[1]-'0'] = INT, w = 0;
else w = nl_arg[s[1]-'0'].i;
s+=3;
} else if (!l10n) {
w = f ? va_arg(*ap, int) : 0;
s++;
} else goto inval;
if (w<0) fl|=LEFT_ADJ, w=-w;
} else if ((w=getint(&s))<0) goto overflow;
今回関係あるのはelse if節のみです。前半の部分は最小フィールド幅が*や*m$の形で指定された場合の処理です。if (w<0) fl|=LEFT_ADJ, w=-w;の部分で、最小フィールド幅として負の数が指定された場合に-フラグと最小フィールド幅と解釈する仕様が実現されています。この形でない場合はgetint関数が呼ばれています。この関数は以下のように定義されています。
static int getint(char **s) {
int i;
for (i=0; isdigit(**s); (*s)++) {
if (i > INT_MAX/10U || **s-'0' > INT_MAX-10*i) i = -1;
else i = 10*i + (**s-'0');
}
return i;
}
ダブルポインタが使われているのはsを更新するためです。最小フィールド幅は10進数文字列で指定されるのでした。この関数は先頭から順に入力を読み、10進数整数に変換してその値を返します。最小フィールド幅はint型である必要があるため、値がINT_MAXを超える場合はi=-1となり、負の値が返るようになっています。以下の図が分かりやすいかも知れません。
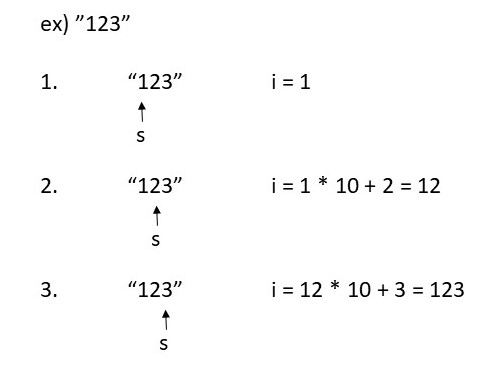
続く以下の部分で精度を読んでいます。最小フィールド幅の時と同様に、今回関係あるのはelse if節とelse節のみです。精度が指定されている場合は先ほどのgetint関数で精度を数値に変換してpに代入しています。(pはprecisionの頭文字)指定がない場合、pは-1になっています。xpは精度が指定されたかどうかを表すための変数です。xp = (p>=0)の部分に注目してください。この処理により、精度に負の値が指定された場合に精度は指定されなかったとみなされる仕様が実現されています。
if (*s=='.' && s[1]=='*') {
if (isdigit(s[2]) && s[3]=='$') {
if (!f) nl_type[s[2]-'0'] = INT, p = 0;
else p = nl_arg[s[2]-'0'].i;
s+=4;
} else if (!l10n) {
p = f ? va_arg(*ap, int) : 0;
s+=2;
} else goto inval;
xp = (p>=0);
} else if (*s=='.') {
s++;
p = getint(&s);
xp = 1;
} else {
p = -1;
xp = 0;
}
次の部分から変換指定子の解析が始まります。この部分は長いので特に整数変換(d, i, o, u, x, X)の処理を中心に説明することにします。変換指定子の解析の先頭は以下のようになっています。関連する定義も示しておきました。
enum {
BARE, LPRE, LLPRE, HPRE, HHPRE, BIGLPRE,
ZTPRE, JPRE,
STOP,
PTR, INT, UINT, ULLONG,
LONG, ULONG,
SHORT, USHORT, CHAR, UCHAR,
LLONG, SIZET, IMAX, UMAX, PDIFF, UIPTR,
DBL, LDBL,
NOARG,
MAXSTATE
};
#define S(x) [(x)-'A']
static const unsigned char states[]['z'-'A'+1]; // 略
#define OOB(x) ((unsigned)(x)-'A' > 'z'-'A')
st=0;
do {
if (OOB(*s)) goto inval;
ps=st;
st=states[st]S(*s++);
} while (st-1<STOP);
if (!st) goto inval;
この部分では変換指定子に対応する引数の型を調べています。OOB(*s)は*sが'A'~'z'の範囲でないときに1になります。変換指定子なら'A'~'z'の範囲になるはずなのでこれが1になる場合はエラーになります。do-whileループを抜けるのはstがSTOP+1以上になる時、即ちstがenumの定義の中で、STOPよりも後に定義されているもの(例えばPTR, INT...)になった時です。このような実装になっているのは'h'や'll'のような長さ修飾子を考慮するためです。今回は長さ修飾子は実装しないので実装はこれよりも簡単になります。最後のif(!st)の部分は*sが有効な変換指定子でなかった場合の処理です。OOBは*sが'A'~'z'の範囲にあるかしかチェックしないため、不正な変換指定子が指定される可能性があります。その場合はstが0になる(statesを初期化するときに値を指定していないから)ため、if文の条件が真になり、invalに飛ぶというわけです。例えば入力として"%d"を考えてみると、
st = states[st]S(*s++) = states[0]['d' - 'A'] = INT
となってループを抜けます。これで対応する引数の型が分かったので実際に渡された引数を取ってくる処理が続きます。
if (st==NOARG) {
if (argpos>=0) goto inval;
} else {
if (argpos>=0) {
if (!f) nl_type[argpos]=st;
else arg=nl_arg[argpos];
} else if (f) pop_arg(&arg, st, ap);
else return 0;
}
最初の部分は'm'のような引数を取らない変換指定子の場合の処理です。argposが正になるのはダイレクトパラメータアクセスが使用されている場合です。引数を取らないにも関わらずダイレクトパラメータアクセスが使用されている場合はエラーになります。else節の中ではargに対応する引数をセットしています。argposが正の場合、つまりダイレクトパラメータアクセスが使用されている場合はnl_arg[argpos]を、そうでない場合はpop_argの返り値を代入しています。pop_argと関連する定義を以下に示します。pop_argはva_argを呼んでいるだけです。
union arg
{
uintmax_t i;
long double f;
void *p;
};
static void pop_arg(union arg *arg, int type, va_list *ap)
{
switch (type) {
case PTR: arg->p = va_arg(*ap, void *);
break; case INT: arg->i = va_arg(*ap, int);
break; case UINT: arg->i = va_arg(*ap, unsigned int);
break; case LONG: arg->i = va_arg(*ap, long);
break; case ULONG: arg->i = va_arg(*ap, unsigned long);
break; case ULLONG: arg->i = va_arg(*ap, unsigned long long);
break; case SHORT: arg->i = (short)va_arg(*ap, int);
break; case USHORT: arg->i = (unsigned short)va_arg(*ap, int);
break; case CHAR: arg->i = (signed char)va_arg(*ap, int);
break; case UCHAR: arg->i = (unsigned char)va_arg(*ap, int);
break; case LLONG: arg->i = va_arg(*ap, long long);
break; case SIZET: arg->i = va_arg(*ap, size_t);
break; case IMAX: arg->i = va_arg(*ap, intmax_t);
break; case UMAX: arg->i = va_arg(*ap, uintmax_t);
break; case PDIFF: arg->i = va_arg(*ap, ptrdiff_t);
break; case UIPTR: arg->i = (uintptr_t)va_arg(*ap, void *);
break; case DBL: arg->f = va_arg(*ap, double);
break; case LDBL: arg->f = va_arg(*ap, long double);
}
}
次は出力を生成し、バッファに書き込むための処理です。整数変換に関係するもののみ示します。
z = buf + sizeof(buf);
prefix = "-+ 0X0x";
pl = 0;
t = s[-1];
switch(t) {
case 'x': case 'X':
a = fmt_x(arg.i, z, t&32);
if (arg.i && (fl & ALT_FORM)) prefix+=(t>>4), pl=2;
if (0) {
case 'o':
a = fmt_o(arg.i, z);
if ((fl&ALT_FORM) && p<z-a+1) p=z-a+1;
} if (0) {
case 'd': case 'i':
pl=1;
if (arg.i>INTMAX_MAX) {
arg.i=-arg.i;
} else if (fl & MARK_POS) {
prefix++;
} else if (fl & PAD_POS) {
prefix+=2;
} else pl=0;
case 'u':
a = fmt_u(arg.i, z);
}
// ここから整数変換共通の処理
if (xp && p<0) goto overflow;
if (xp) fl &= ~ZERO_PAD;
if (!arg.i && !p) {
a=z;
break;
}
p = MAX(p, z-a + !arg.i);
break;
この処理に入る時に*sは変換指定子の次を指しているため、t=s[-1]でtに変換指定子を代入し、tの値によって場合分けするようになっています。面白いのはswitch-caseの中で要らないところをif(0){}で囲むことで整数変換共通の処理までfall throughしている点です。(gotoじゃなくてこれが採用されている理由が知りたい)fmt_*系の関数は引数を適当な文字列にフォーマットするためのものです。例えばfmt_xは引数を16進数の文字列に変換するためのものです。
a = fmt_x(arg.i, z, t&32);
が呼ばれたとしましょう。zは変換結果の文字列を保持するバッファへのポインタです。zは
z = buf + sizeof(buf);
のように初期化されているので、バッファの終端を指すようになっています。面白いのはt&32の部分です。16進数を表示する際、変換指定子が'x'の場合は小文字('a', 'b'..)を、'X'の場合は大文字('A','B'...)を使用するという仕様があります。t&32は出力に使うのが小文字か、大文字かを判断するために用いられています。(すぐ後に説明しますが、これはもっとすごいことに使われています)32, 'x', 'X'を2進数で表すと以下のようになるため、tが'X'の場合、第三引数は0になります。
32 = 0b0100000
'x' = 0b1111000
'X' = 0b1011000
fmt_xと関連する定義を以下に示します。
static const char xdigits[16] = {
"0123456789ABCDEF"
};
static char *fmt_x(uintmax_t x, char *s, int lower)
{
for (; x; x>>=4) *--s = xdigits[(x&15)]|lower;
return s;
}
16進数一桁は4bitであるため、渡された値を4bit左シフトしながら読み進めています。15 = 0b1111とandを取り、その値をxdigitsの添え字として使用しています。xdigitsはcharの配列で、'0'~'F'が格納されているため、これで下位4bitが16進数文字として表せます。凄いのは最後に第三引数であるlowerとorを取っていることです。第三引数はt&32でした。t='X'の場合はorをとっても変わりません。変わるのはt='x'の場合です。t='x'の場合、第三引数lowerはt&32=0b100000になります。これとorを取ることで大文字が小文字に変わるのです。しかもこれが'1'~'9'の場合はそのままになります。(賢い!)
'A'(0b1000001) | 0b100000 = 0b1100001('a')
'F'(0b1000110) | 0b100000 = 0b1100110('f')
'0'(0b110000) | 0b100000 = 0b110000('0')
'9'(0b111001) | 0b100000 = 0b111001('9')
あとは変換結果をバッファに書き込み、先頭アドレスを返します。下位4bitを順に16進数文字に変換していくため、zはバッファの終端を指すように初期化されていたというわけです。以下の図が分かりやすいかも知れません。

prefixの処理も見ておきましょう。plは恐らくprefix lengthの略で、prefix全体の長さを保持するために用いられています。例えば入力として"%#X"を考え、対応する引数が0でなかったとします。#フラグは対応する引数が0でない場合に"0x"または"0X"を付加するのでした。今回は変換指定子が'X'なので"0X"を付加します。#フラグが指定されている場合、上のコードの以下の部分の条件式が真になります。
// #define ALT_FORM (1U<<'#'-' ')
if (arg.i && (fl & ALT_FORM)) prefix+=(t>>4), pl=2;
面白いのはprefix+=(t>>4)の部分です。再び'x'と'X'を二進数で示しておきます。
'x' = 0b1111000
'X' = 0b1011000
これをそれぞれ4bit右シフトすると以下のようになります。
'x' >> 4 = 0b111(7)
'X' >> 4 = 0b101(5)
prefixは
prefix = "-+ 0X0x";
のように初期化されていました。変換指定子が'X'の場合はprefix+=(t>>4)はprefix+=5となり、prefixは"0X"を指します。'x'の場合はprefix+=7となり、prefixは"0x"を指します。(賢い!)
これが上の初期化式で、'+'と"0X"の間に不自然な空白文字が入っていた理由です。
この他にも、例えばswitch文の前に以下のような処理があり、-フラグと0フラグが一緒に指定された場合に0フラグを無視する仕様が実現されています。
// #define ZERO_PAD (1U<<'0'-' ')
// #define LEFT_ADJ (1U<<'-'-' ')
if (fl & LEFT_ADJ) fl &= ~ZERO_PAD;
終わりが見えてきました。続く処理を以下に示します。この部分は精度や最小フィールド幅を(必要があれば)更新するための処理です。
if (p < z-a) p = z-a;
if (p > INT_MAX-pl) goto overflow;
if (w < pl+p) w = pl+p;
if (w > INT_MAX-cnt) goto overflow;
fmt_xのところでみたように、aは数値を文字列に変換した結果の先頭を指しており、zはbufの末尾を指していたのでした。つまりz - aは数値を文字列に変換した結果の長さです。精度pは表示される最小の桁数でしたから、長さが精度を超えている場合は精度を長さで更新しています。精度がINT_MAX - plを超えている場合はエラーになります。次にw < pl + pの場合はwをpl + pで更新しています。wは最小フィールド幅でした。全体の長さ(pl + p)がwを超える場合はwが全体の長さに合わせて更新されます。wがINT_MAX - cntを超える場合はエラーになります。(cntは今まで出力したバイト数でした)
最後はprefixを付加したり精度や最小フィールド幅を考慮して空白文字を出力したりしながら完全な出力を生成し、呼び出された時に指定されたバッファに生成した文字列を書き込むための処理です。コードを以下に示します。
pad(f, ' ', w, pl+p, fl);
out(f, prefix, pl);
pad(f, '0', w, pl+p, fl^ZERO_PAD);
pad(f, '0', p, z-a, 0);
out(f, a, z-a);
pad(f, ' ', w, pl+p, fl^LEFT_ADJ);
l = w;
} // forループの終わり
pad関数は以下のように定義されています。
static void pad(FILE *f, char c, int w, int l, int fl)
{
char pad[256];
if (fl & (LEFT_ADJ | ZERO_PAD) || l >= w) return;
l = w - l;
memset(pad, c, l>sizeof pad ? sizeof pad : l);
for (; l >= sizeof pad; l -= sizeof pad)
out(f, pad, sizeof pad);
out(f, pad, l);
}
pad関数はw - lだけcをバッファに書き込みます。l >= wとなる場合や-, 0フラグが指定されている場合は何もしません。直接バッファに書き込むのではなく、一度ローカル変数padに書き込んでからそれをバッファに書き込むという二段階の処理になっています。forループはw - lの値が256を超える場合に、256byteずつコピーしていくための処理です。
out関数は本章の初めのほうで説明したとおり、最終的にsn_write関数を呼び出します。この呼び出しによってバッファに文字列が書き込まれます。
必要な知識が揃ったのでコードを読み解いていきましょう。再びコードを以下に示します。
pad(f, ' ', w, pl+p, fl);
out(f, prefix, pl);
pad(f, '0', w, pl+p, fl^ZERO_PAD);
pad(f, '0', p, z-a, 0);
out(f, a, z-a);
pad(f, ' ', w, pl+p, fl^LEFT_ADJ);
l = w;
} // forループの終わり
一番最初のpad関数でpl + p - wだけ空白文字を出力しています。これは全体の長さ(pl + p)が最小フィールド幅(w)よりも小さく、かつ0,-フラグが指定されていない場合に意味のある処理です。次のout関数でprefixを出力しています。続くpad関数でpl + p - wだけ0を出力しています。これは全体の長さ(pl + p)が最小フィールド幅(w)よりも小さく、かつ0フラグが指定されている場合に意味のある処理です。flとZERO_PADのxorを取ることでZERO_PADが有効な場合に0が出力されるようになっています。ZERO_PADが無効な場合はxorを取ることでZERO_PADが有効になるため、pad関数は何もしません。続くpad関数でz - a - pだけ0を出力しています。z - aは数値を文字列に変換した結果の長さでした。変換結果の長さが精度よりも小さい場合に0で埋められるという仕様が実現されています。次のout関数で数値を文字列に変換した結果を出力しています。最後のpad関数では数値の右側にw - pl + pだけ空白文字を出力しています。これは全体の長さ(pl + p)が最小フィールド幅(w)より小さく、かつ-フラグが指定されている場合に意味のある処理です。ZERO_PADの時と同様に、flとLEFT_ADJのxorを取ることでLEFT_ADJが有効な場合にのみ出力されるようになっています。
以上でmuslのコードの説明を終わります。ダイレクトパラメータアクセスや説明しなかった変換指定子のコードに興味がある方は各自で呼んで見て下さい。
自作OSに実装してみる
ここが一番大事なところなんですが記事も長くなってきましたし、何より疲れたのでコードを示すだけにします。printf(もどき)とsnprintfは以下のように実装しました。ほとんどのコードがmuslと同じです。muslでは出力できる最大文字数がINT_MAXになっていましたが、そんなに長い文字列を表示することはないですし、メモリが無駄なので最大文字数を100にしています。
これを自作OS上で動かしてみると、今回作ったprintf(もどき)がちゃんと動いていることが確認できます。(やったね♪)
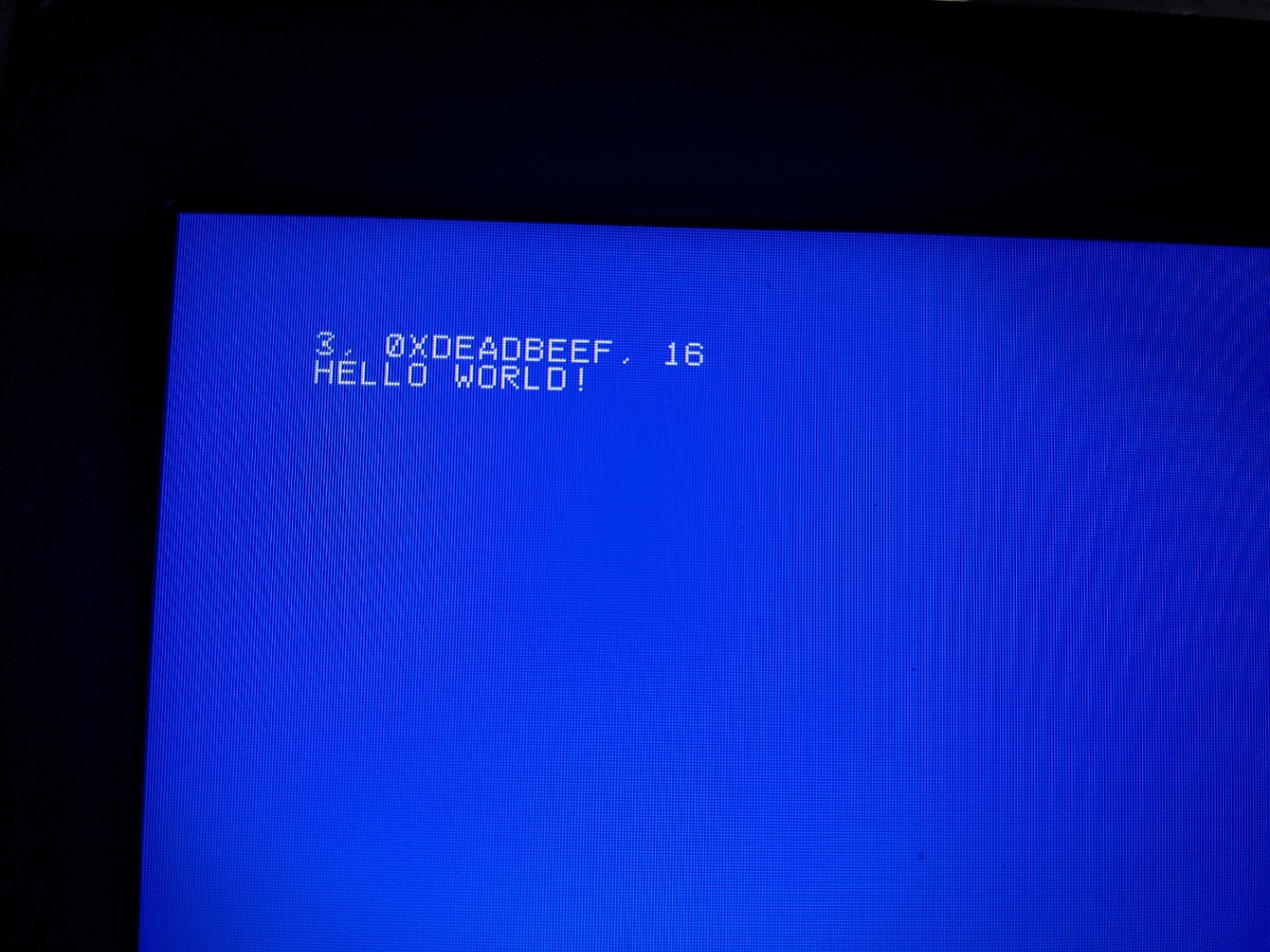
ちなみにprintf(もどき)と書いているのは、現状自作OSにシステムコールやstdoutなんてなく、直接フレームバッファにピクセル情報を書き込んでいるからです。でもまあやっていることはほとんど変わらないのでprintf(もどき)と呼んでも問題ないでしょう。
おわりに
本記事では可変長引数関数の仕組みを調べ、muslの実装を読み、それを自作OSにフルスクラッチで実装することに取り組んでみました。こんな面倒なことをしなくてもMikan本のようにNewlibを使えば簡単に実装できます。しかし自分でフルスクラッチで作ることで今まで気付かなかったことに気づけたり、理解が深まったりします。仕様にも詳しくなれますし、muslのような広く使われているソフトウェアのソースコードを読むことで上手い書き方を吸収して自分のものにできたりと、いいことばかりです。
フルスクラッチで自作OSに取り組みたい方にぜひおすすめしたい本として、大神祐真さんの「フルスクラッチで作る!UEFIベアメタルプログラミング」シリーズと「フルスクラッチで作る!x86_64自作OS」シリーズを挙げます。この本はedk2等のツールチェインを使わずにUEFIの仕様書を読みながらフルスクラッチでOSを開発するというもので、なんと無料で公開されています。以下からダウンロードできます。
私もこの本を参考にしつつOSを開発しています。現状、この本と違うところはkernelをELF形式にしている点とprintf(もどき)を実装していることです。(もちろんELFローダーもフルスクラッチです)良ければ参考にしてみてください。
Discussion