テキスト埋め込みモデルの蒸留に関する調査
こんにちは!名古屋大学大学院 博士1年の矢野千紘です。
8月1日から9月30日までの2ヶ月間、株式会社レトリバのインターンに参加させていただきました。本記事ではインターンで取り組んだ、テキスト埋め込みモデルの蒸留に関する調査について紹介します。
テーマの概要
近年の言語モデルは高度化とともに大規模化が進んでいます。しかし、実応用においては大きなモデルは推論コストの観点から使いにくい場面も多いです。そこで、大きくて強いモデルを能力は維持したまま小さくしようという試みが存在します。
知識蒸留はそんな試みの一つであり、教師モデルと呼ばれる強いモデルの出力を利用して、生徒モデルに知識を落とし込もうという手法です。

知識蒸留のイメージ
テキストを計算可能な表現に変換する、テキスト埋め込みモデルにおいても大規模化は進んでいます。以下はMTEB (Massive Text Embedding Benchmark) というベンチマークのリーダーボードですが、多くのモデルはビリオンスケールです[1]。

2025年9月22日のMTEB leaderboard
テキスト埋め込みモデルにおいても推論コストは大きな問題です。例えばRAGでは検索器としてテキスト埋め込みモデルがよく用いられますが、検索にかかる時間はユーザー体験に直結するため、あまり大きなモデルは利用できません。
テキスト埋め込みモデルにおける知識蒸留は研究されてきましたが、画一的に比較した研究はあまりなく、どのような損失関数を用いると良いかは明らかになっていません。また、言語モデルの知識蒸留における工夫や、テキスト埋め込みモデルを通常訓練するときに用いられる工夫などを取り込むといった試みも十分行われていません。
そこで、今回のインターンではテキスト埋め込みモデルの蒸留について、以下の3点を調査しました。
- どの損失が最も有効か?
- 言語モデルの蒸留手法であるTAID[2]はテキスト埋め込みモデルの蒸留に対しても有効か?
- テキスト埋め込みモデルの訓練において有効な、正例の利用やprefixの付与は同様に有効か?
実験設定
今回はベンチマークで性能評価済みの大規模なテキスト埋め込みモデルが多く存在する、英語を対象に実験を行いました。
-
教師モデル:Qwen/Qwen3-Embedding-4B (#params: 4B)
-
生徒モデル:nomic-ai/modernbert-embed-base-unsupervised (#params: 149M)
- ModernBERTに弱教師ありの対照学習を行なったモデル
-
ベースライン:Unsupervised Simcse
-
訓練対象の文を2回エンコードし、同じ文の埋め込み表現を正解としてCrossEntropyで学習

unsup simcseのイメージ図
-
-
訓練データ:検索、QA、NLI、分類、要約など、様々なタスクのデータが含まれる約1,800,000件のデータセット
-
Shitao/bge-m3-data, sentence-transformers/embedding-training-dataから、ドメインの重複が多すぎないよう抽出
利用したサブセット一覧と教師モデルによるエンコード時のInstruction
-
以下のInstructionを使用
From Shitao/bge-m3-data "en_NLI_data": "Retrieve semantically similar text", "SQuAD": "Given a question, retrieve passages that answer the question", "Trivia": "Given a question, retrieval the relevant passage for the given query", "fever": "Given a claim, retrieve supporting evidence from the text", "ms-marco": "Given a web search query, retrieve relevant passages that answer the query", "NQ": "Given a question, retrieve Wikipedia passages that answer the question", "HotpotQA": "Given a multi-hop question, retrieve documents that can help answer the question", From sentence-transformers/embedding-training-data "S2ORC_title_abstract": "Given a title, retrieve the abstract from the S2ORC dataset", "SimpleWiki": "Given a query, retrieve relevant passages from SimpleWiki", "agnews": "Given a news title, retrieve relevant passages from AGNews", "amazon-qa": "Given a question, retrieve answer from Amazon QA", "amazon_review_2018": "Given a review title, retrieve the review text from Amazon Review 2018", "ccnews_title_text": "Given a title, retrieve the article from CCNews", "cnn_dailymail": "Given a news article, retrieve the highlights from CNN/DailyMail", "coco_captions": "Given an image caption, retrieve caption about same image from COCO Captions", "codesearchnet": "Given a comment, retrieve relevant code snippet from CodeSearchNet", "eli5_question_answer": "Given a question, retrieve answer from ELI5", "gooaq_pairs": "Given a question, retrieve answer from GOOAQ", "npr": "Given a web title, retrieve relevant article from NPR", "searchQA_top5_snippets": "Given a query, retrieve relevant snippets from SearchQA", "sentence-compression": "Retrieve semantically similar text", "stackexchange_duplicate_questions_body_body": "Retrieve semantically similar text", "stackexchange_duplicate_questions_title-body_title-body": "Retrieve semantically similar text", "stackexchange_duplicate_questions_title_title": "Retrieve semantically similar text", "wikihow": "Given a summary, retrieve original article", "xsum": "Given a summary, retrieve original article", "yahoo_answers_title_answer": "Given a question title, retrieve the best answer":::
-
-
各サブセットのデータが最大1,000,000件となるようにした後、全サブセットの比率を維持したまま結合
-
-
評価タスク:MTEB(Massive Text Embedding Benchmark)に含まれるeng, v2ベンチマーク
- 検索、リランキング、分類、意味類似性、クラスタリング、要約などのタスクから構成される
- 全41データセットを利用し、各タスクごとの平均、全体の平均(Micro Average)を集計
-
そのほかのパラメータ
- 学習率:1e-4
- スケジューラ:Warmup-Stable-Decay
- 学習epoch数:3
- バッチサイズ:128
- 最大系列長:512
実験1: どの損失が最も有効か?
以下の損失関数を比較に利用します。
1 Distill KL Divergence[3](KLD)
教師モデルの類似度行列と生徒モデルの類似度行列にsoftmaxをかけ、KL Divergenceで近似する損失です。
モデル同士の埋め込み表現同士を近づけるのではなく、類似度を近づけていることが特徴です。
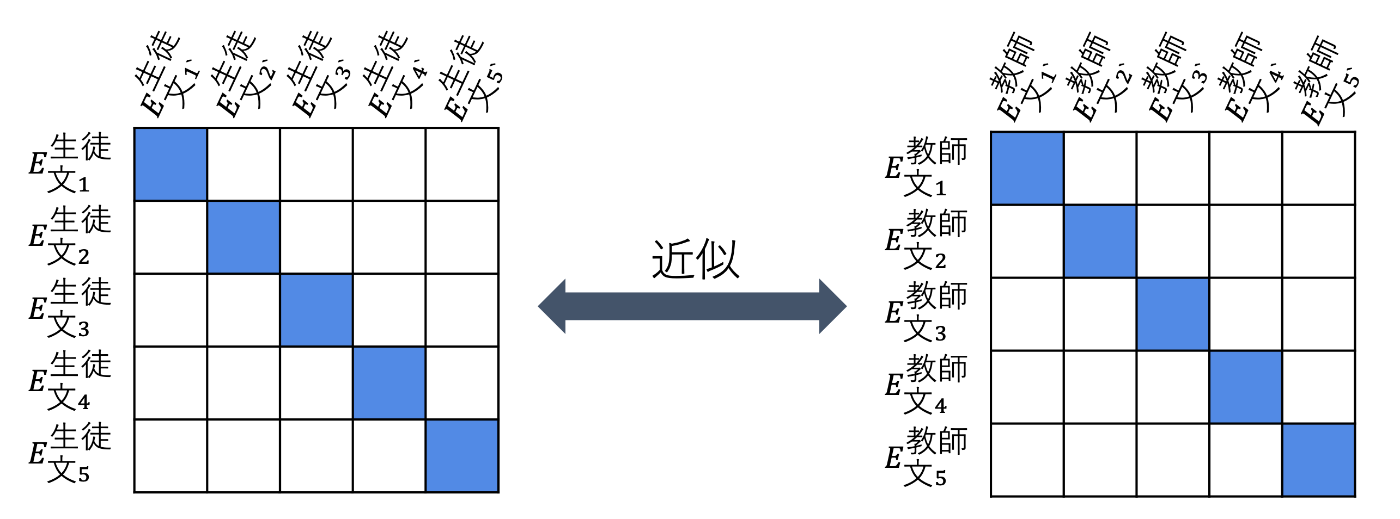
KLD損失による訓練のイメージ図
実装
2 Contrastive Knowledge Distillation[4](CKD)
教師モデルと生徒モデルの作った文埋め込みの類似度をとり、CrossEntropyで近づける損失です。

CKD損失による訓練のイメージ図
実装
3 Jasper and Stellaで利用されている損失 [5](JS)
-
L_{cos} -
L_{sim} -
L_{resim}
実装
実験1: 結果と考察

損失を変更した実験結果
一貫して、CKD > KLD > JS > unsup-simcseとなっていますが、ほとんどの場合生徒モデル(= 訓練前)よりも性能が下がってしまっています。特にRetrievalタスクではかなり性能が劣化していることがわかります。
また、蒸留ではないunsup-simcseにおいても性能が劣化しています。
生徒モデルはweakly supervisedによく訓練されているので、今回のunsupervisedな訓練は簡単になりすぎてしまっている可能性があります。
実験2: TAIDはテキスト埋め込みモデルの蒸留に対しても有効か?
TAIDとは、言語モデルの知識蒸留において、進捗状況に合わせて学習難易度を調整する手法で、教師モデルと生徒モデルのあいだの能力のギャップによって発生する課題を軽減します。
具体的には、ゴールとする分布を生徒モデルの出力と教師モデルの出力の重み付き和で構成し、訓練ステップtと学習進捗に依存して教師モデル出力の重みを大きくしていくという手法です。

本テーマでは最適化したい表現はテキスト埋め込みであり、原著論文とは異なりますが、TAIDと同様の方法論でモデル間の能力ギャップを低減できないかと考え、実験1で用いた損失関数における教師信号を学習進捗に依存した重み付き和に変更する方法を定義しました。
まず、KLDでは、それぞれのモデルによる類似度行列を混ぜ合わせ、教師信号としました。

KLD + TAIDのイメージ
そして、CKDとJSではそれぞれのモデルによるテキスト埋め込み自体を混ぜ合わせ、教師信号としました。

CKD, JS + TAIDのイメージ。 Fn部分にそれぞれの損失が入ります。
実験2: 結果と考察

TAIDを導入した実験結果
lossやtaskによってTAIDの有効性は異なりますが、生徒モデルからの性能劣化は継続しており、TAIDで緩やかに蒸留するという目的は達成できていなさそうに見えます。特にCKDとTAIDの組み合わせは性能が大きく劣化しており、損失関数の設計に問題があるかもしれません。問題としては例えば、埋め込みについて線形和を取り、その後計算した類似度行列で学習しているので、過度に簡単になってしまっている可能性などが考えられそうです。
実験3: 正例の利用やprefixの付与は有効か?
実験3-1: 正例の利用
テキスト埋め込みモデルの訓練では、anchor文に対して近づけたいpositive文を正例として用意することが多くあります。どのような文ペアが用意されるかはタスクによりますが、例えば検索タスクならクエリに対する正解の文章、QAタスクなら質問に対する回答、自然言語推論(NLI)タスクなら文とそれに含意される文のようなペアが用意されます。

正例を利用することによるQAタスクでの訓練の変化イメージ
異なる文の表現を遠ざけるだけでなく、意図した文ペアの表現を近づけることができるため、ほとんどのテキスト埋め込みモデルの訓練で正例は利用されています。
実験3-1: 結果と考察

正例を利用した実験結果
CKDを除くすべての損失関数で性能が向上しており、正例の利用は有効でした。
一方CKDでは性能が劣化しています。特に、RetrievalやSummarizationなどの、性質の異なる文同士が正例ペアになるような評価タスクで大きな性能劣化が見られました。CKDは教師モデルと生徒モデルの埋め込みについて類似度が高くなるように訓練を行います。そのため、今回のような設定では、それぞれのモデルが(正例とはいえど)違う文をエンコードした時の埋め込みを近づけるような訓練になってしまっており、難しすぎる訓練タスクになっている可能性があります。
実験3-2: Prefixの付与
対称タスクと非対称タスクを単一のモデルで解かなければならない今回のような汎用モデルの構築において、タスクの性質ごとに文の前に接頭辞(prefix)をつけることが有効だと知られています[6]。
今回は多くのモデルと同じように、STSやクラスタリングなどの対象タスクでは全ての文の頭に”query: ”をつけ、検索などの非対称タスクでは検索クエリには”query: “を、検索対象の文章には”document: ”をつけることにしました。
実験3-2: 結果と考察

prefixを付与した実験結果
タスクごとに傾向は異なりますが、全体を平均すると今回はprefixの付与は性能を劣化させることになりました。特に、Retrievalで大きく性能が劣化しており、逆にClassificationやSTSなどでは少し性能が向上しています。
今回利用した訓練データは2/3以上が検索やQAタスクで構成されており、prefixとして”query: ”, ”document: ”をそれぞれの文ペアに付与することになりました。もちろん正例ペアは近づけるように訓練が進みますが、それ以外のバッチ内negativeはすべて遠ざけるように訓練が進みます。今回はバッチ内がすべて同じタスクで構成されるような Task-homogeneous batching[7]を実装していたため、query-docmentペアを遠ざける効果が過剰に働いてしまい、Retievalタスクが難しくなってしまっている可能性が考えられます。
追加実験: データ種別、サイズの変更
これまでの実験では、一般にテキスト埋め込みモデルの対照学習で利用される、様々なタスクデータセットを訓練に利用してきましたが、単純に教師モデルの埋め込みを真似た出力をさせるという目的であれば、Webコーパスを訓練に利用することも考えられます。
そこで、CommonCrawlをフィルタリングしたHuggingFaceFW/finewebを訓練データとして利用する場合について実験を行います。
また、蒸留に必要なデータ量についても知見を得るため、元の1,800,000件から1,000,000件に減らしたデータを利用する場合についても比較を行います。
ただし、KLDについてはこれまでの実験で正例を利用した方が性能が高かったため、kld_1.8Mとkld_1Mでは正例を利用する設定となっています。
実験Ex: 結果と考察
データの種類とサイズを変更した時の実験結果
CKDとJSはデータの種類にセンシティブかつ、CKDはタスクデータセットの大きさにもかなり影響を受けています。これらの損失関数を利用する場合は正例を全く利用しないため、特に検索などのタスクデータセットを用いた訓練では検索クエリのみが利用され、平均の系列がfinewebよりも短く、より簡単な訓練になっていると考えられます。
CKDがこのような簡単なデータを大量に利用する場合にのみ高い性能を示す理由として、教師と生徒の埋め込み表現の類似度を最適化するCKDは難しいタスクで、系列長の短いなるべく易しいデータで十分訓練することが必要である可能性が考えられます。
また、CKDやJSは正例を用いないタスクデータセットで最高性能を達成しており、これらの易しいデータで十分訓練した後、教師あり対照学習などのよりリッチかつ難しいタスクで訓練することで、より高い性能のモデルが得られる可能性があります。
まとめ
本記事では、テキスト埋め込みモデルの蒸留について調査し、以下のような回答が得られました。
1. どの損失が最も有効か?
→ 訓練データの種類、量や工夫の有無によるが、2M程度のテキストを訓練に利用する場合ではCKD > KLD > JS の傾向が見られました。ただし、CKDの性能はデータの種類や量によって大きく劣化することがありました。つまり、大量にデータセットを用意できる場合にはCKD、できない場合にはKLDを用いると良さそうです。また、損失関数ごとに相性の良いデータの特徴がありそうです。
2. 言語モデルの蒸留手法であるTAID[1]はテキスト埋め込みモデルの蒸留に対しても有効か?
→ 今回試した範囲では、ほとんど効果がなくむしろ性能が劣化する場合もありました。損失関数の設計やタスク設計が原著論文からかなり離れているので、うまく動くために必要な要素を満たしていない可能性が考えられます。
3. テキスト埋め込みモデルの訓練において有効な、正例の利用やprefixの付与は同様に有効か?
→ KLDを利用する場合には正例の利用は効果的でした。prefixは一部のタスクでは有効だったものの、今回の実験設定ではRetrievalの性能を大きく下げてしまいました。
2ヶ月という短いインターン期間でしたが、レトリバの皆様に暖かく迎え入れていただき、とても楽しく有意義な時間を過ごすことができました。特に、何か相談したいときはすぐに会話の機会を設けていただき、ありがたかったです。メンターの勝又さん、チームの西鳥羽さん、木村さん、オフィスで会話してくださった皆様、ありがとうございました!
-
(eng, v2) ベンチマークにおいて、Open Weightモデルのみを表示した結果です。 ↩︎
-
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models ↩︎
-
設定が異なるため、直接の先行研究ではありませんが、Distilling Dense Representations for Ranking using Tightly-Coupled Teachersなどを参考にしています。 ↩︎
-
DistilCSE: Effective Knowledge Distillation For Contrastive Sentence Embeddings ↩︎
-
Text Embeddings by Weakly-Supervised Contrastive Pre-training ↩︎
-
SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning ↩︎

Discussion