GPT-5のTTFT(Time to First Token)が遅かったのでMinimal Reasoningを設定する
気付いたこと
旅行計画を立てるために育て続けている自作WEBアプリにAIによるスポットの説明文生成機能を導入してみた.
場所の名前や緯度経度,ユーザが指定したラベルをもとに,その場所の説明を良い感じに説明してくれる,という機能.
モデルは公開されたばかりのgpt-5(gpt-5-nano)を指定し,UXを意識しレスポンスはストリーミングで実装,してみたが……
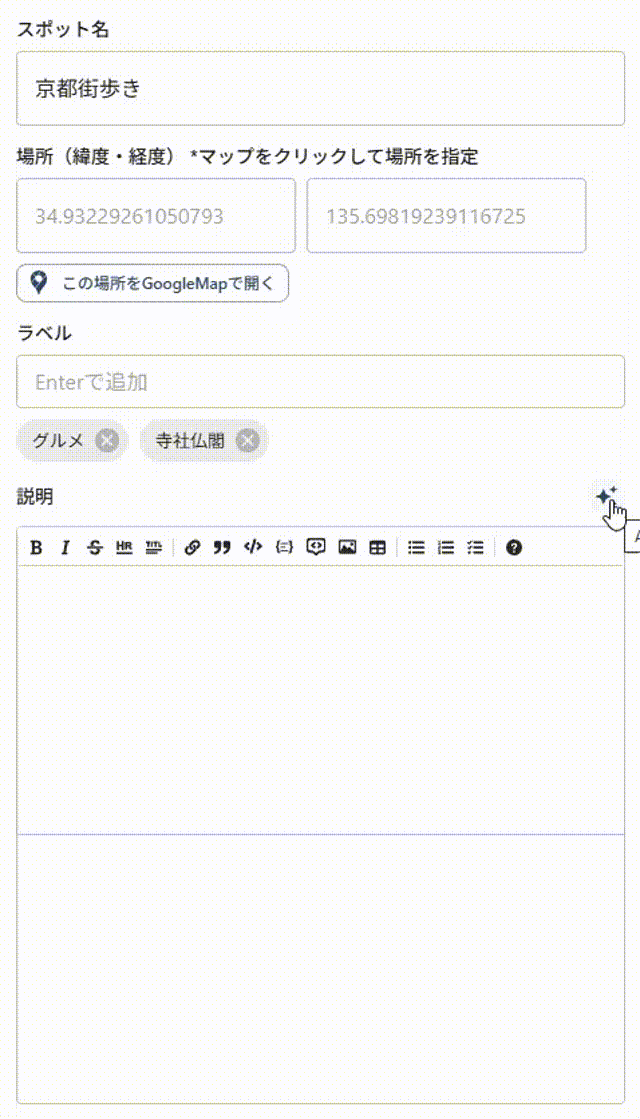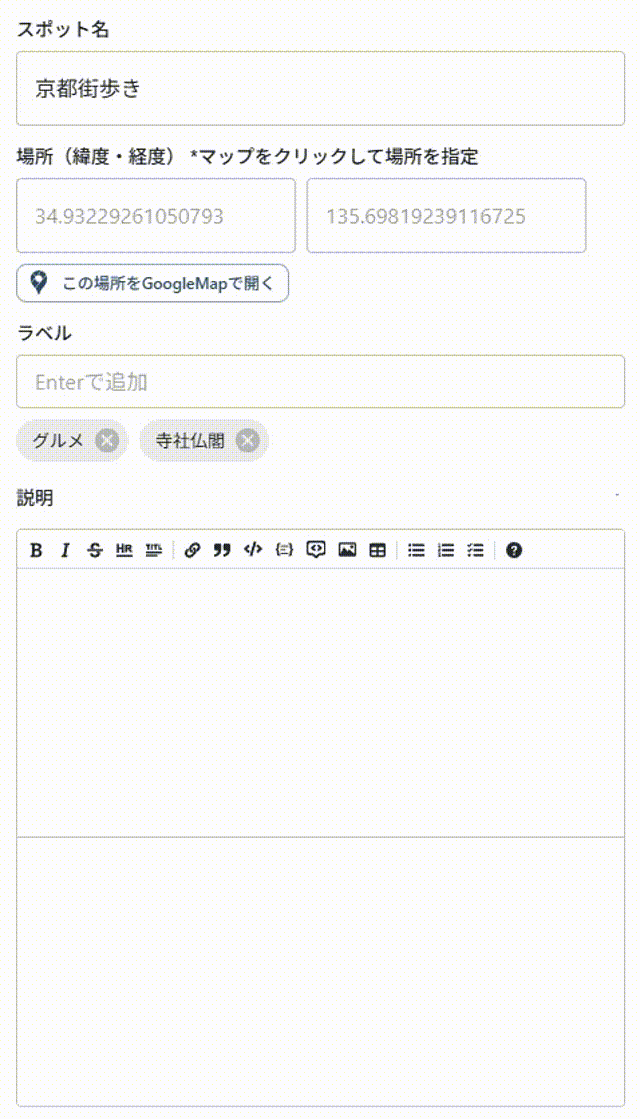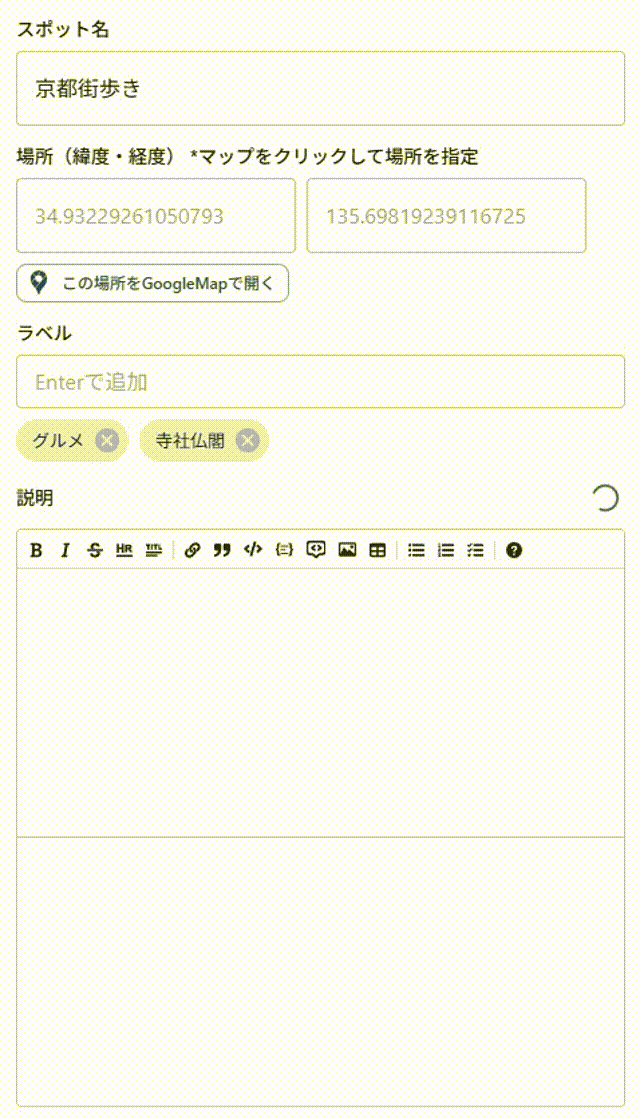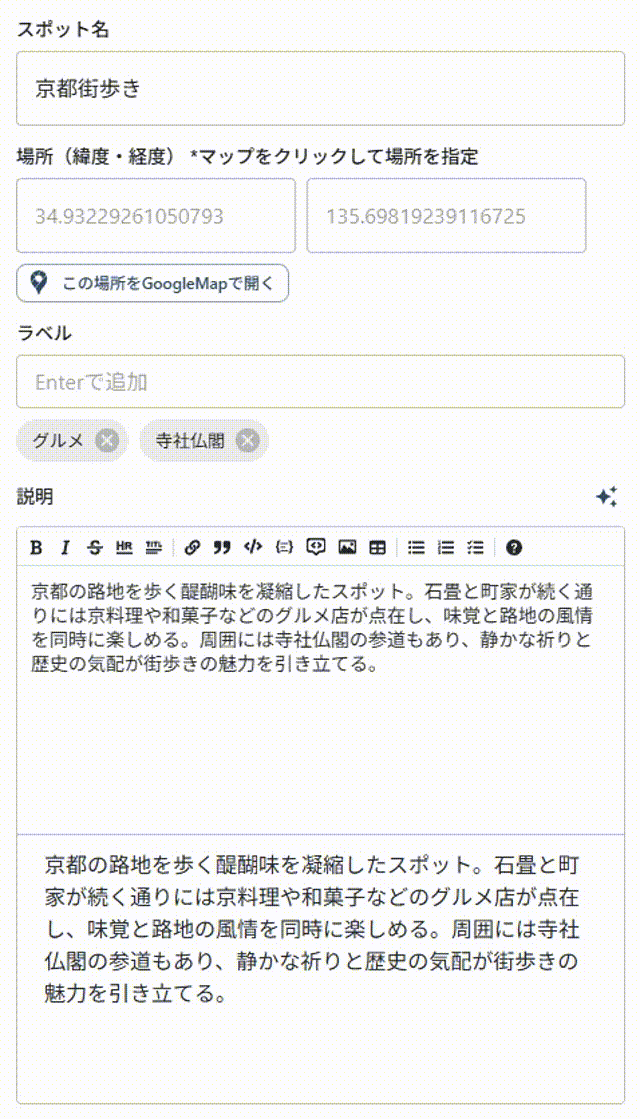
gpt-5-nano
……何か遅い.
ストリーミングで表示されているような気はするが,その割には「一気にまとめて表示」されている感が否めない.
ストリーミングの実装を誤ったかな……と色々調べる中で,ふとモデルをgpt-4o-miniに変えて試してみたところ,
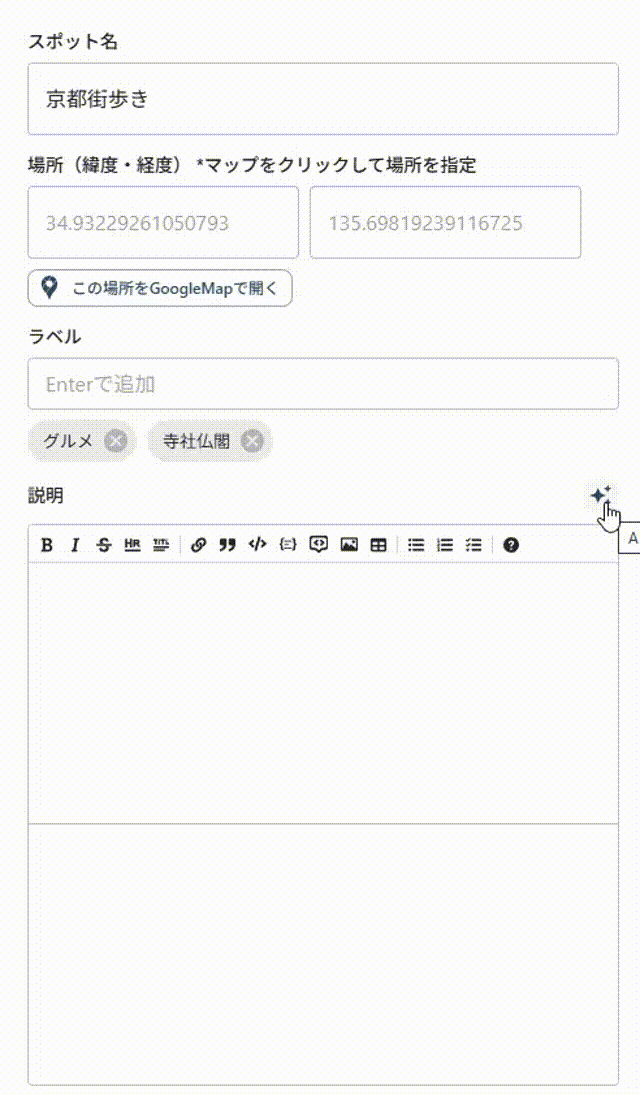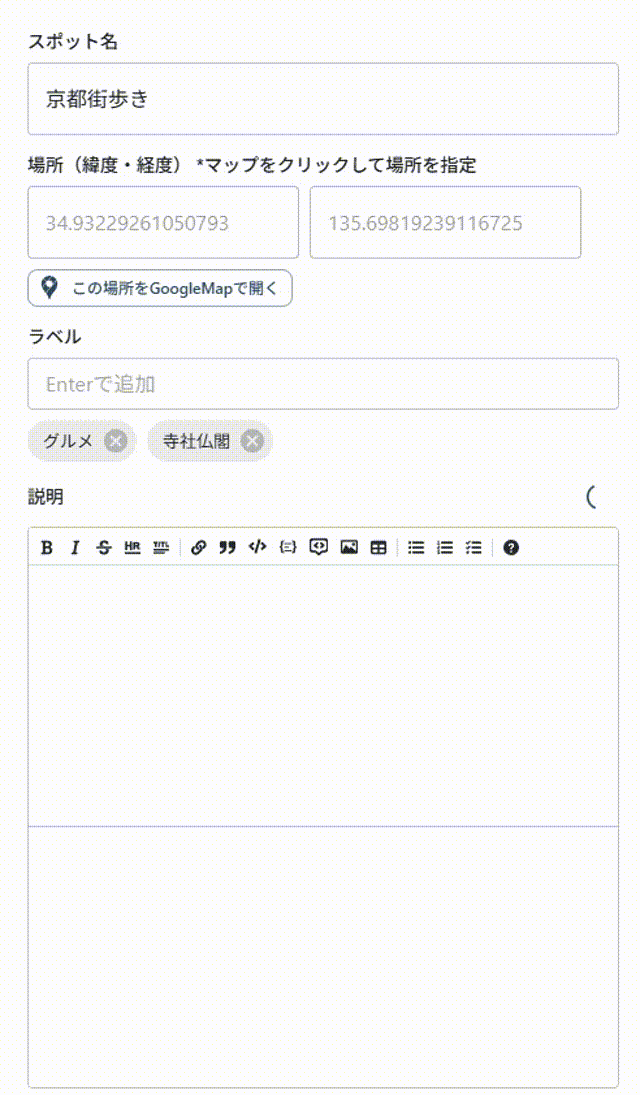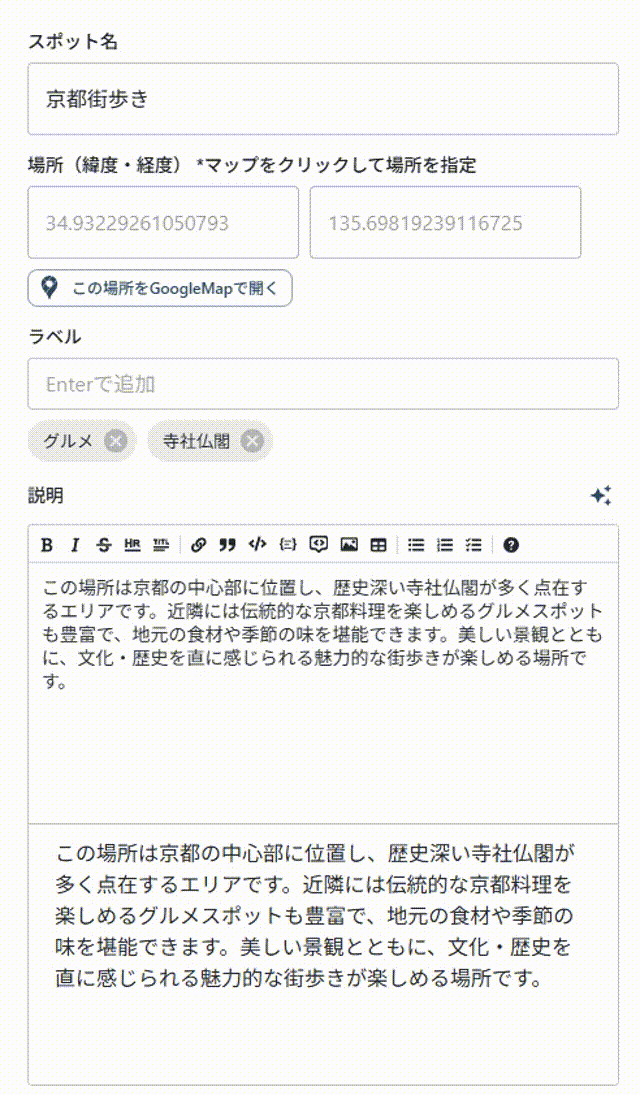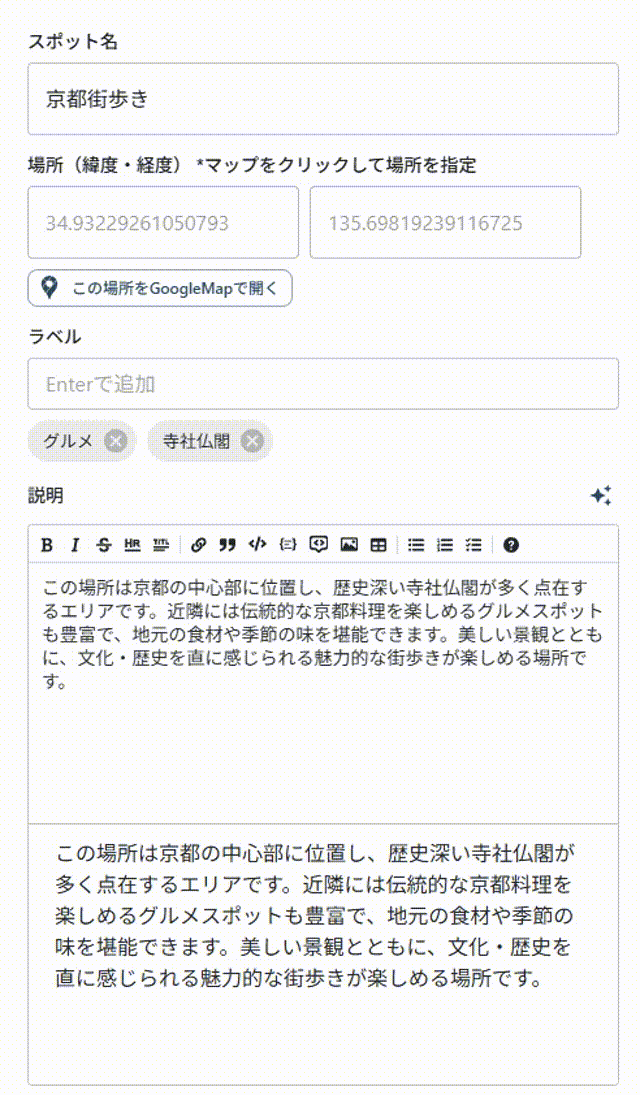
gpt-4o-mini
明らかに最初の出力の出始めはgpt-4o-miniのほうが早いように感じられる.
そこで,LangGraphのトレースを見てみると,
-
gpt-4o-mini

-
gpt-5-nano

このような結果になっていた.
ユーザが渡しているインプット文字列はどちらも同じ,LLMが返してくるアウトプットの文字列の文字数もさほど変わらず.
それでも,gpt-5-nanoのほうが
- Time to first tokenが6倍弱
- Total tokensが8倍弱
大きいという結果になった.
測定
上記は試行回数n=1なので,それぞれ10回試行してみた.
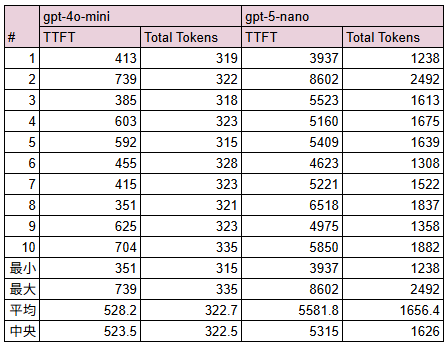
というわけで「さっきはたまたまそうだった」ということではなさそう.
「じゃあ4o-miniを使うようにしましょうか」という結論でも,自分のユースケースでは問題ない(正直そこまでアウトプットの質を求めているわけではないので,そもそもモデルにこだわりがない).
一方で,レスポンスを見ているとgpt-5は「TTFTは遅いが出力が始まった後の速度は早い」という傾向があるように見える.つまり,「長文を出力するのでgpt-4o-miniよりgpt-5を使いたい」というケースが今後出てくるかもしれない.
そこで,gpt-5を使いつつもTTFTを短くできないか?を考えてみる.
GPT-5のパラメタ
OpenAI Cookbookによると,GPT-5の新パラメータとしては以下の4つがあるとのこと.
-
1. Verbosity Parameter
- モデルの返答の「長さ」(冗長さ)を制御する.
- low/medium(デフォルト)/highを指定できる
- (自分の解釈)
- どれだけ簡潔に答えてほしいか,あるいは逆に少しくどいくらいに答えてほしいかを.プロンプトで指定することなく制御できる.
- これまで「簡潔に答えてください」とか「詳細に説明してください」などとプロンプトで指示していたところを,このパラメタで指定できるようになった.
-
2. Freeform Function Calling
- ツールに渡すための出力をJSON形式ではなくテキスト形式で生成する.
- (自分の解釈)
- 例えばモデルにSQLを生成させてそれを実行する場合などは,JSON形式で返ってくるより生のテキストとして返ってきたほうが都合が良い場合があるので……ということか?
- でもStructured Outputとかで事足りないか?という気もしており,あまり使い所がわかっていない
-
3. Context-Free Grammar (CFG)
- 出力が"文法的に"正しいかを定義するルール.
- モデルの出力を指定した文法に沿った形にすることができる.
- (自分の解釈)
- ちょっと調べたところ,Larkまたは正規表現で文法ルールを指定できるらしいので,ユーザが柔軟にルールを策定できそうな気がする.
-
4. Minimal Reasoning
- モデルがどれだけ推論するかの設定.
- 推論を少なく,もしくは無くすことでレイテンシとTTFTを小さくすることができる.
- 推論を要さない軽量なタスクで有効.
- minimal/medium(デフォルト)を指定できる
ということで,明らかにMinimal Reasoningの設定をすれば良さそうである.
Minimal Reasoningを設定してみる
const model = new ChatOpenAI({
model: 'gpt-5-nano',
apiKey: input.apiKey,
reasoning: { effort: "minimal" }
});
これで先程同様に10回測定してみる.

結果は上記の通りで,明らかに設定前よりTTFTが短くなり,TotalTokenが減っていることが確認できた.
GUI見た目上も,
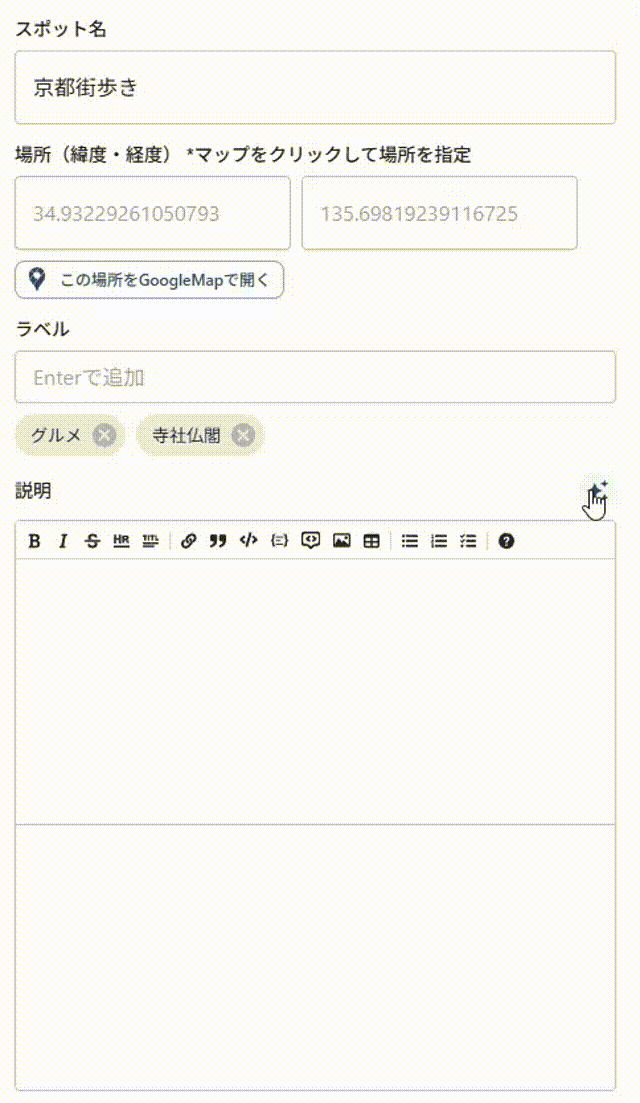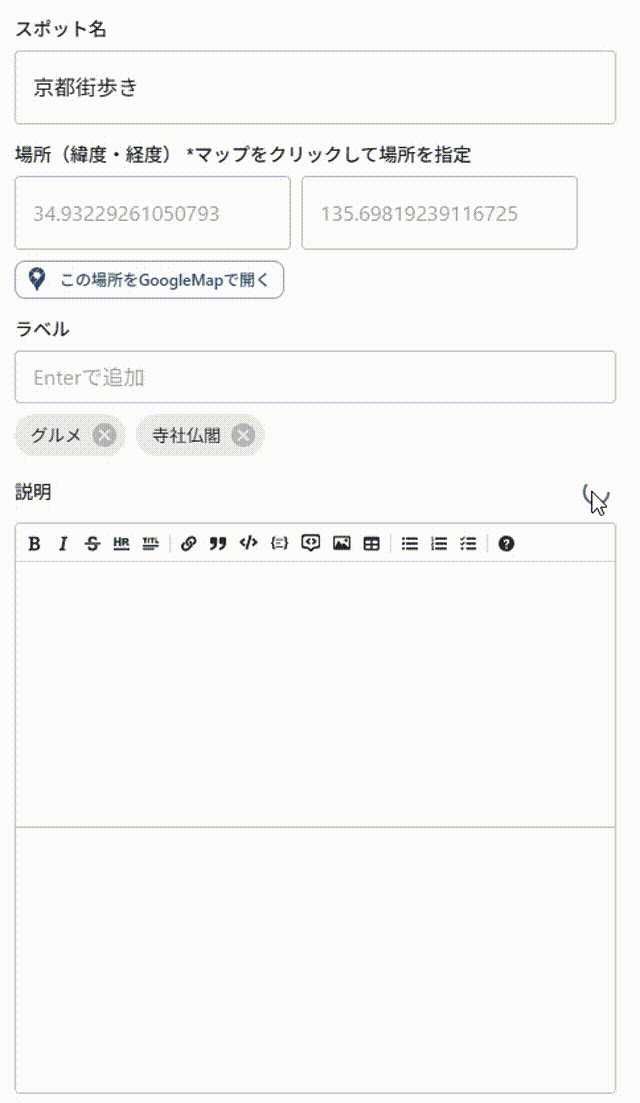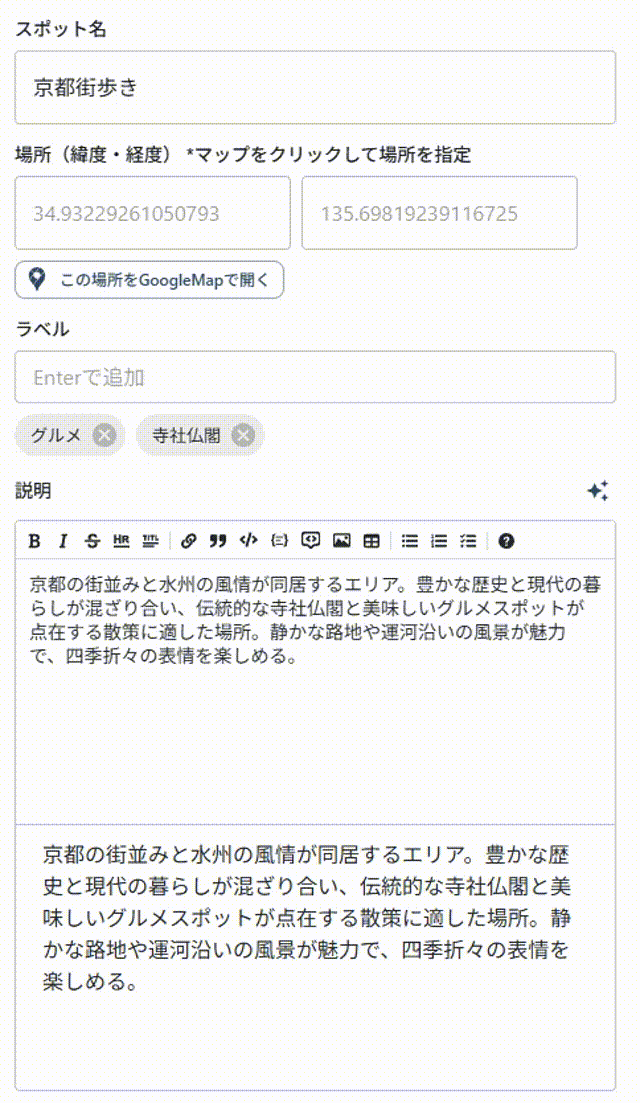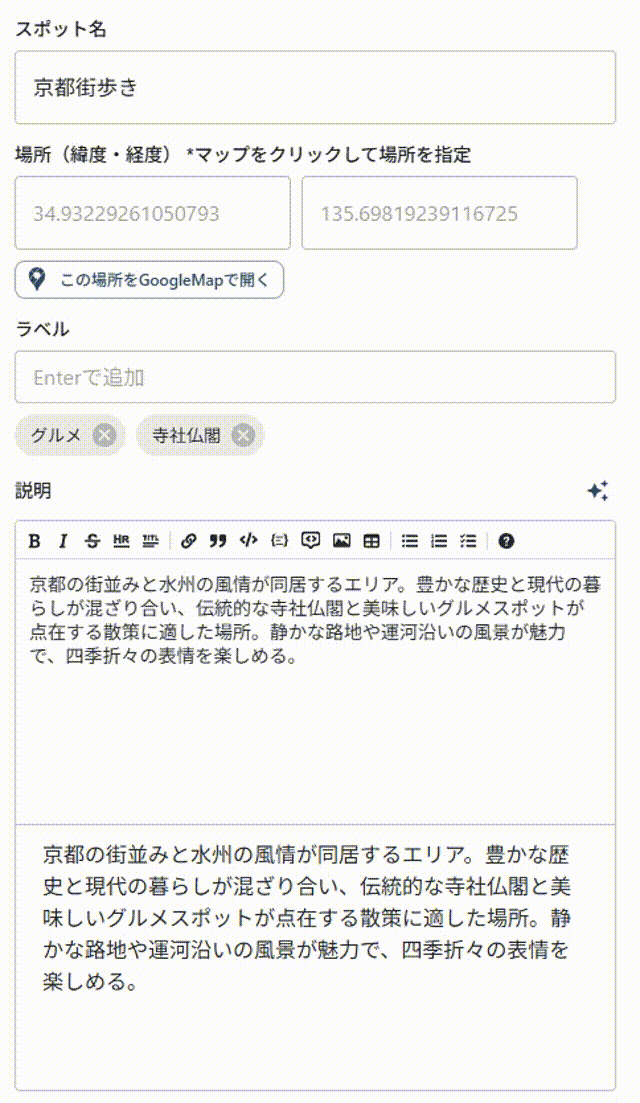
gpt-5-nano minimal reasoning
明らかに早い.
ただ一方で,試行回数10回でしかなく厳密な検証ではないものの,依然としてgpt-4o-miniよりはTTFTが遅い傾向が見られるのは気になる.
短めの文章の生成で,レスポンスの速さが命!という場合は引き続きgpt-4o-miniを使い続けるのはありかもしれない.
また,今回はreasoning effortをminimalにしたことによる生成結果の品質評価はしていない.
自分のユースケースの場合は出力結果にさほど品質を求めていないのでどうでも良いが,品質も重要な場合はMinimal Reasoningの設定有無により出力がどのように変化するかも評価する必要がある.
Discussion