🧩 1. はじめに
今月、元 OpenAI 研究者を中心としたチームが発表した未来予測シナリオ AI 2027 [1] が話題になっていますね。
興味深い内容ですが、どんな将来が来たとしても、AI についての正しい知識を身につけておくことは必須のように感じました。
AI 関連の資格試験としては AWS Certified AI Practitioner (以下、「AIF」)や JDLA が実施する G 検定などがあります。
いずれも AI の入門的な資格ですが、私自身がこれらを受験するにあたり、どちらか一方で十分なのか、両方を取得するのが効果的なのか、気になりました。
そこで本記事では、両者の模擬試験問題を比較し、どれくらい出題傾向が似ているかを、自然言語処理(NLP)によるテキスト分析で可視化してみたいと思います。
🛠️ 2. 目的と方法
目的
- AIF と G 検定の模擬試験問題を比較し、実際にどれくらい似ているのかを明らかにする。
実行環境
- マシンスペック
- OS: macOS Sonoma 14.4.1
- CPU: Apple M3 Max
- Python: 3.13.2
- 主要なパッケージのバージョン
- pandas: 2.2.3
- numpy: 2.2.4
- matplotlib: 3.10.1
- sentence-transformers: 4.1.0
前提条件と選定ツール
| 項目 | 内容 |
|---|---|
| 比較対象 | AIF:260問、G検定:840問(いずれも模擬試験データを使用) |
| 言語 | 日本語 |
| 分析目的 | 意味的に類似した設問ペアを特定し、知識領域の重複程度を可視化すること |
| 制約条件 | - 学習データの著作権保護に配慮(設問全文は公開不可) - ローカル PC 環境で実行 - 実行時間は数分以内が望ましい |
| 選定項目 | 選定理由 |
|---|---|
| Sentence-BERT(SBERT) | BERTベースで、文章同士の意味的な類似度を数値化可能。事前ベクトル化により高速な類似度計算が可能。 |
| paraphrase-multilingual-MiniLM-L12-v2 | 日本語に対応しつつ軽量で高速。ローカル CPU 環境でも実用的なパフォーマンス。 |
| Cosine 類似度 | 文章ベクトル同士の意味の近さを 0 〜 1 の範囲で定量的に評価できる、SBERTと相性の良い手法。 |
| matplotlib | スコア分布の可視化に使用。ヒストグラムで傾向を直感的に把握できる。 |
| pandas | データ処理・進捗管理に使用。大量の設問ペアでも処理状況が把握しやすく、スムーズに分析可能。 |
分析方法
- 設問文と選択肢の内容に対して、意味的な類似度を SBERT [2] で測定し、その結果を分析する。
- 収集データ:Udemy 掲載の模擬試験(AIF: 260問 [3]、G 検定: 840問 [4])
- 分析手順:
- 設問文と選択肢を結合してベクトル化
- SBERT で意味ベクトルを生成
- AIF の各問題について G 検定の全問題との類似度(cosine similarity)を計算
- 類似度が大きな値を記録し、頻度分布を可視化
SBERT による AIF と G 検定との類似度計算の実装
import pandas as pd
from sentence_transformers import SentenceTransformer, util
import matplotlib.pyplot as plt
import numpy as np
from typing import List, Dict
import matplotlib as mpl
# 定数定義
AWS_KEYWORDS = ['AWS', 'Amazon']
# 日本語フォントの設定
mpl.rcParams['font.family'] = 'Hiragino Sans'
def load_data():
"""データの読み込みと前処理を行う"""
aif_df = pd.read_csv("aif_questions.csv")
g_df = pd.read_csv("g_questions.csv")
# 設問文 + 選択肢を結合
aif_texts = (aif_df["設問文"].fillna("") + " " + aif_df["選択肢"].fillna("")).tolist()
g_texts = (g_df["設問文"].fillna("") + " " + g_df["選択肢"].fillna("")).tolist()
return aif_df, g_df, aif_texts, g_texts
def get_embeddings(texts, model):
"""テキストをエンベッディングに変換"""
return model.encode(texts, convert_to_tensor=True, show_progress_bar=True)
def create_similarity_pairs(aif_df, g_df, similarity_matrix):
"""類似度ペアの作成"""
max_similarity_pairs = []
for i in range(len(aif_df)):
max_score_idx = np.argmax(similarity_matrix[i])
max_score = similarity_matrix[i][max_score_idx]
pair = {
'類似度': max_score,
'AIF_項番': aif_df.iloc[i]['項番'],
'G_項番': g_df.iloc[max_score_idx]['項番'],
'AIF_設問文': aif_df.iloc[i]['設問文'],
'G_設問文': g_df.iloc[max_score_idx]['設問文'],
'AIF_選択肢': aif_df.iloc[i]['選択肢'],
'G_選択肢': g_df.iloc[max_score_idx]['選択肢']
}
max_similarity_pairs.append(pair)
return max_similarity_pairs
def filter_pairs_by_score(pairs, threshold, is_high=True):
"""類似度に基づいてペアをフィルタリング"""
if is_high:
return [pair for pair in pairs if pair['類似度'] >= threshold]
return [pair for pair in pairs if pair['類似度'] <= threshold]
def save_pairs_to_csv(pairs, filename):
"""ペアをCSVファイルに保存"""
df = pd.DataFrame(pairs)
df = df.sort_values('類似度', ascending=False)
df.to_csv(filename, index=False, encoding="utf-8")
return len(df)
def create_histogram(pairs:List[Dict])->None:
aws_scores=[]
other_scores=[]
for p in pairs:
text=str(p['AIF_設問文'])+str(p['AIF_選択肢'])
(aws_scores if any(k in text for k in AWS_KEYWORDS) else other_scores).append(p['類似度'])
plt.rcParams['font.size'] = 10
plt.rcParams['axes.grid'] = True
plt.rcParams['grid.alpha'] = 0.3
plt.rcParams['grid.linestyle'] = '--'
plt.figure(figsize=(12,8))
plt.hist([other_scores,aws_scores],bins=20,alpha=0.8,
label=[f'その他の問題 : {len(other_scores)}件',f'AWS 関連問題 : {len(aws_scores)}件'],
color=['#4B79B7','#F28E2B'],
stacked=True,
edgecolor='white',
linewidth=1)
plt.xlabel('類似度スコア',fontsize=12,fontweight='bold')
plt.ylabel('出現頻度',fontsize=12,fontweight='bold')
plt.title('AIF 各問題における G 検定問題との最大類似度スコアの分布',fontsize=14,fontweight='bold',pad=15)
plt.legend(loc='upper right', fontsize=10, title=f'AIF 総問題数 : {len(pairs)}問')
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 余白の調整
plt.tight_layout(pad=3.0, h_pad=3.0, w_pad=3.0)
plt.savefig('similarity_histogram_all.png', dpi=300, bbox_inches='tight', pad_inches=0.5)
plt.close()
def main():
print("モデルをロード中...")
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
aif_df, g_df, aif_texts, g_texts = load_data()
print("テキストをエンベッディング中...")
aif_embeddings = get_embeddings(aif_texts, model)
g_embeddings = get_embeddings(g_texts, model)
print("類似度を計算中...")
similarity_matrix = util.cos_sim(aif_embeddings, g_embeddings).cpu().numpy()
max_similarity_pairs = create_similarity_pairs(aif_df, g_df, similarity_matrix)
high_similarity_pairs = filter_pairs_by_score(max_similarity_pairs, 0.7, True)
low_similarity_pairs = filter_pairs_by_score(max_similarity_pairs, 0.5, False)
create_histogram(max_similarity_pairs)
high_count = save_pairs_to_csv(high_similarity_pairs, "aif_g_high_similarity_pairs.csv")
low_count = save_pairs_to_csv(low_similarity_pairs, "aif_g_low_similarity_pairs.csv")
print(f"\n✅ 類似度0.7以上のペア {high_count} 件を出力しました: aif_g_high_similarity_pairs.csv")
print(f"✅ 類似度0.5以下のペア {low_count} 件を出力しました: aif_g_low_similarity_pairs.csv")
if __name__ == "__main__":
main()

図 1 . AIF と G 検定の類似度分析プロセス(フローチャート)
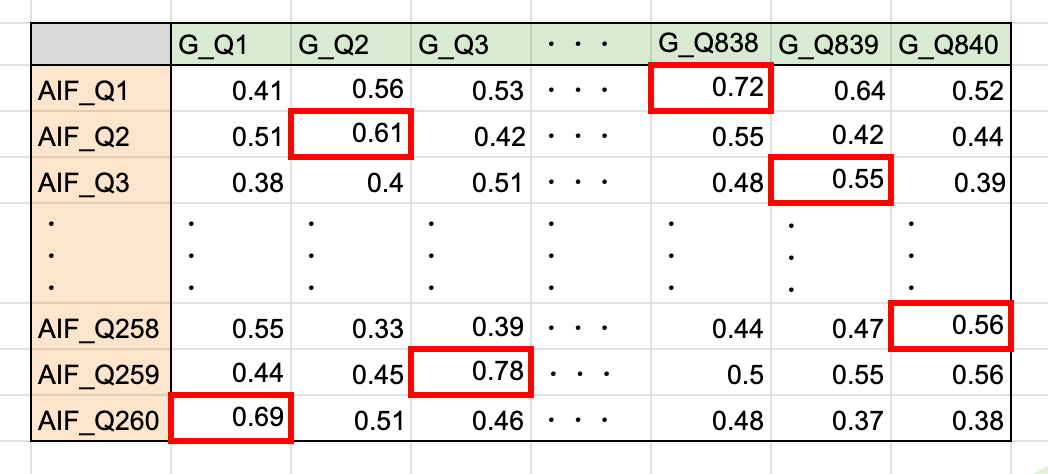
図 2 . 類似度計算メトリクスの例。各 AIF 問題ごとに最大類似度を抽出(各行で最大類似度になる問題ペアを赤枠で囲っている)
注意点
AIF と G 検定では問題数に大きな差があるため、1 対多の比較が必要でした。そのため今回は、問題数が少ない方の AIF の各問題を基準にして、G 検定問題との類似度を計算し、最も類似度が高かった問題ペアを抽出することで比較しました。
AIF 260 問に対して、それぞれ G 検定 840 問との類似度を計算し、AIF の各問題について最大類似度を抽出したものを「類似度スコア」としました。
これにより、AIF 260 問(それぞれに対する類似度最大の G 検定問題ペア)の類似度スコアごとの出現頻度をヒストグラムで表現しました。
📊 3. 結果

図 3 . AIF 各問題に対して、G 検定の全問題の中で最も類似度が高い問題とのスコア分布
このヒストグラムを見る限り、0.5 ~ 0.6 あたりに頻度が多く出ています。
類似度スコアのしきい値
そこで、類似度スコアがいくら以上なら「似ている」と判断できるか?
やや主観が入りますが、以下のような基準を仮置きしてみます。
| 分類 | しきい値 | 理由例 |
|---|---|---|
| 類似している | 0.70 以上 | 意味的に明確に近く、同一分野の理解が通用する |
| 参考になる | 0.60 〜 0.70 | 類似度は高いが文脈の違いに注意が必要 |
| 異なる内容 | 〜 0.60未満 | 出題分野が異なる、または文脈が限定される |
これを元に再度描画したものを以下に示します。

図 4. AIF 各問題に対して、G 検定の全問題の中で最も類似度が高い問題とのスコア分布(頻度別に色分け)
実際にデータを見て確認
類似度が高かった問題ペアを見てみました。(※引用元データが有料コンテンツであり、問題文は掲載できません。)
- 類似度スコア: 0.8062511
類似度 TOP の問題ペア
- AIF
- G 検定
設問形式は異なるものの、いずれも機械学習アルゴリズムに関する知識を問う問題なので、類似度が高い理由にも納得ですね。
ただし、類似度が高い問題ペアの中にも異なる知識を問う問題ペアも散見されたので、詳しい調査が必要そうです。
次に、類似度が低かった問題ペアも見てみました。(※引用元データが有料コンテンツであり、問題文は掲載できません)
- 類似度スコア: 0.3895379
類似度ワーストの問題ペア
- AIF
- G 検定
こちらも違いは明らかです。問題内容が全然似ていないことがわかります。
AIF には AWS 特有の問題が含まれている
分析そのものは正しくできているように見えますが、もう少し深掘りしてみます。
そもそも、AIF(AWS Certified AI Practitioner)は AWS の知識を問う設問も含まれており、AWS 特有の問題は G 検定とは異なる知識領域であり、類似度は高くないことは容易に予想できます。
そこで、AWS または Amazon という文字列を問題に含んでいるものを「AWS 関連問題」として区別してみます。
AWS 関連問題とその他の問題を色分けしたヒストグラムは、以下のようになりました。
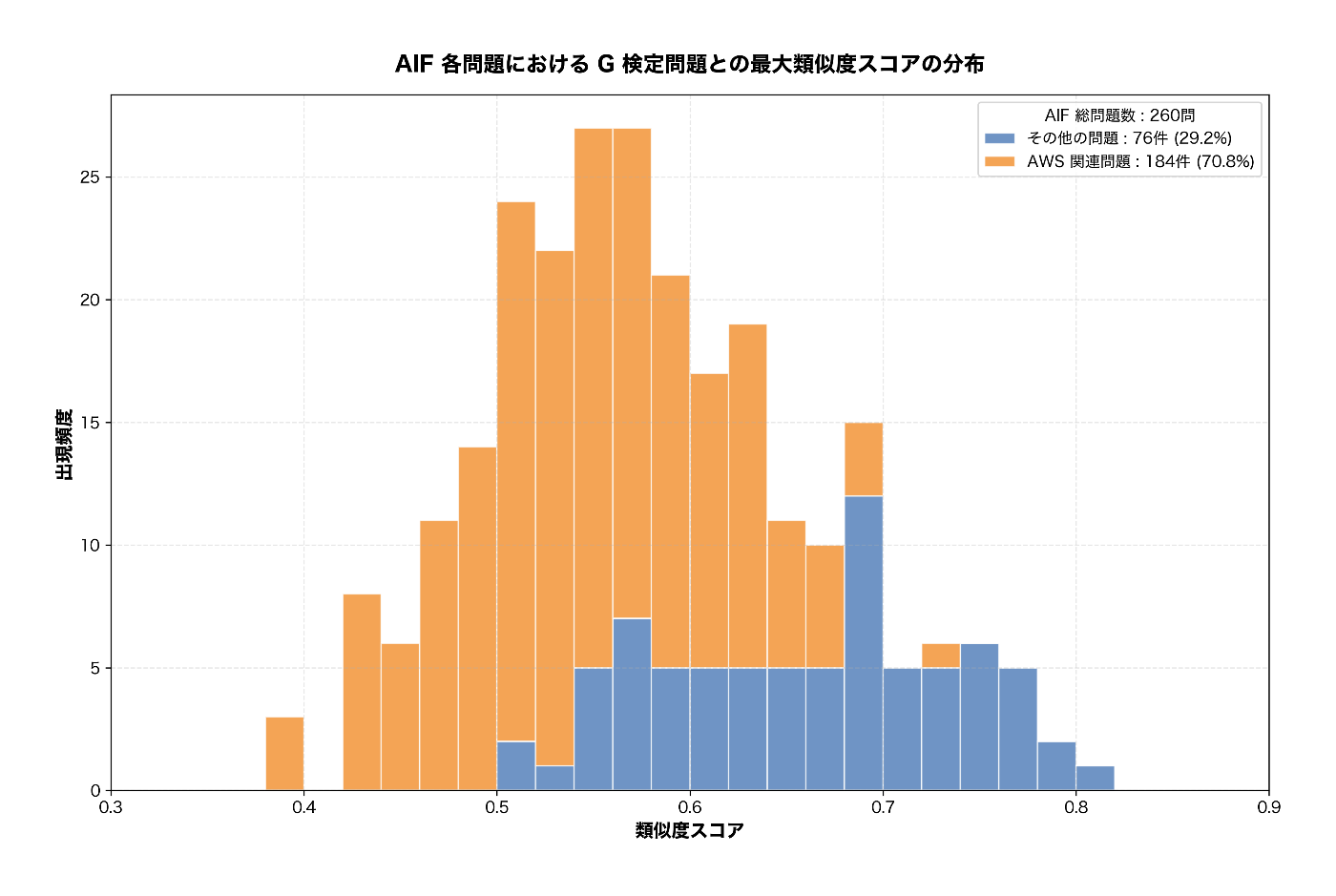
図 5. AIF 各問題に対して、G 検定の全問題の中で最も類似度が高い問題とのスコア分布(AWS 関連問題を色分け)
図 5 のように、「AWS 関連問題」は全体的にグラフの左に偏っており、スコアが低いことが分かります。スコアが 0.7 以上になると「その他の問題」がほとんどを占めています。
🔍 4. 考察
- 類似度スコアが 0.7 以上のペアは全体の約 10 % であった。両者に共通する知識領域かどうかは実際の問題を見て主観的に判断するしかないものの、一定の可能性を見出すことができた。
- スコアが 0.6 以上 0.7 未満の問題ペアについても、より詳しく調査する必要があり、知識が重複しているかどうかは分からない。
- スコアが 0.6 未満の設問が全体の 60 % 以上あったことは、AIF と G 検定で重視する分野の違いが反映されていると考えられる。特に AIF は AWS 特有の知識を問う設問が多く、この点については G 検定と明確に異なる。
💡 5. 結論
- AIF における「G 検定に近い問題」をある程度の幅で可視化できた。
- 具体的には、AIF 問題のうち、10 %(悲観的) 〜 40 % 未満(楽観的)程度について、G 検定の問題内容と類似している可能性があることが示唆された。ただし、類似度が高い問題ペア全てが同じ知識を問うているわけではないため、今回の分析結果における類似度が高い問題が「役に立つ」とは明言できない。
- 今回の分析では AIF を基準に最大類似度を抽出したが、反対に G 検定を基準に最大類似度を計算するケースを同様に分析すれば、G 検定における「AIF に近い問題」がわかるはず(そちらの検討はまたの機会に)。
-
AI 2027 は、元OpenAI社員らが予測した未来シナリオで、2027年までにAIが自己進化し、超知能(ASI)に到達すると想定している。AIは自動化された研究やプログラミングを超人的に行い、AI同士の研究開発も加速。これにより、知能爆発や大量失業、社会変革が予測されており、AIの安全性や人類の未来に重大な影響をもたらすと考えられている。 ↩︎
-
SBERT(Sentence-BERT) は、2つの文章がどれくらい意味的に似ているかを数値で測ることができる AI モデル。
従来の BERT とは異なり、文章間の比較タスクに最適化されており、事前にベクトル化しておけば多くの組み合わせの類似度を効率よく算出できる。
文章はベクトルとして表現され、Cosine 類似度を使って「意味の近さ」を評価する。 ↩︎ -
【AIF-C01】AWSトップ講師によるAWS認定AIプラクティショナー模擬試験問題集(4回分260問)
作成者: Shingo Shibata / AWS certified solutions architect, AWS certified cloud practitioner, AZ-900 ↩︎ ↩︎ ↩︎ -
【全840問】G検定対策 模擬演習試験!重要度の高い問題を厳選(最新シラバス対応)【模擬試験4回分】
作成者: 辻 大貴 ↩︎ ↩︎ ↩︎

Discussion