はじめに
今回は Dataflow を使用し、Cloud Storage へのファイル保存をトリガーに XML データを BigQuery に保存するジョブを構成したいと思います。
概要
手順は以下の通りです。
- Dataflow テンプレート "Cloud Storage Text to BigQuery(Stream)" を選択
- 必須パラメータを設定
- オプションパラメータ(UDF)を設定
- ジョブを実行
事前準備として以下が実施されている必要があります。
- API を有効にし、アカウントに適切な権限を与える
- Cloud Storage バケットを作成する
- BigQuery データセットを作成する
- ユーザー定義関数(UDF)を作成する
詳細手順
Dataflow UI を使用して、データパイプラインを作成します。以下の手順にて設定します。
設定後の画面
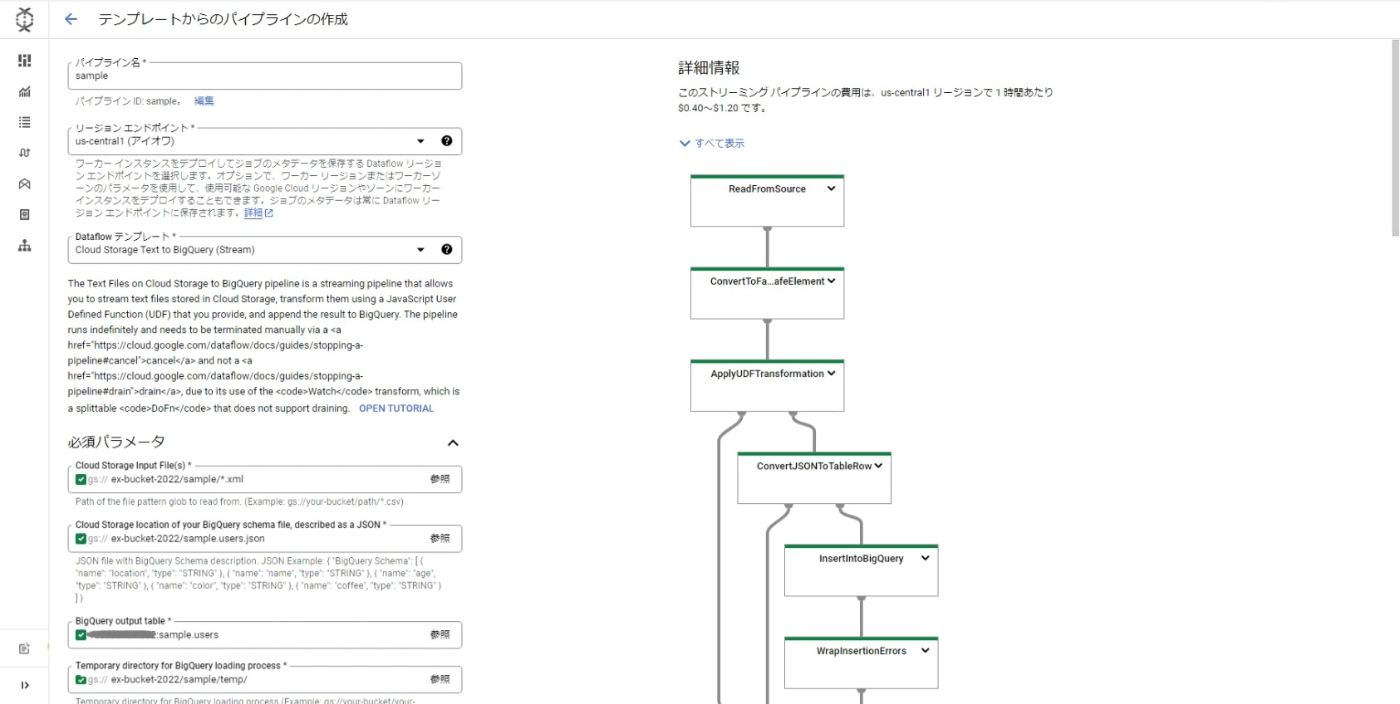
1. テンプレートの選択
テンプレートギャラリーから "Cloud Storage Text to BigQuery(Stream)" テンプレートを選択します。
2. 必須パラメータの設定
-
Cloud Storage Input File
- 入力するファイルのパスです。ワイルドカードが使用できます
- 例:gs://ex-bucket-2022/sample/*.xml
-
BigQuery Schema
- JSON形式で BigQuery のスキーマを定義します
- 例:gs://ex-bucket-2022/sample.users.json
- 今回使用した スキーマ定義
sample.users.json{ "BigQuery Schema": [{"name":"street","type":"DATE","mode":"NULLABLE"},{"name":"address","type":"STRING","mode":"NULLABLE"},{"name":"age","type":"INTEGER","mode":"NULLABLE"},{"name":"prefecture","type":"STRING","mode":"NULLABLE"},{"name":"email","type":"STRING","mode":"NULLABLE"},{"name":"name","type":"STRING","mode":"NULLABLE"},{"name":"city","type":"STRING","mode":"NULLABLE"},{"name":"id","type":"INTEGER","mode":"NULLABLE"}] } -
BigQuery output table
- BigQuery への出力先テーブルです
- 例:projectid:dataset:table
今回使用した BigQuery のデータセットと user テーブル
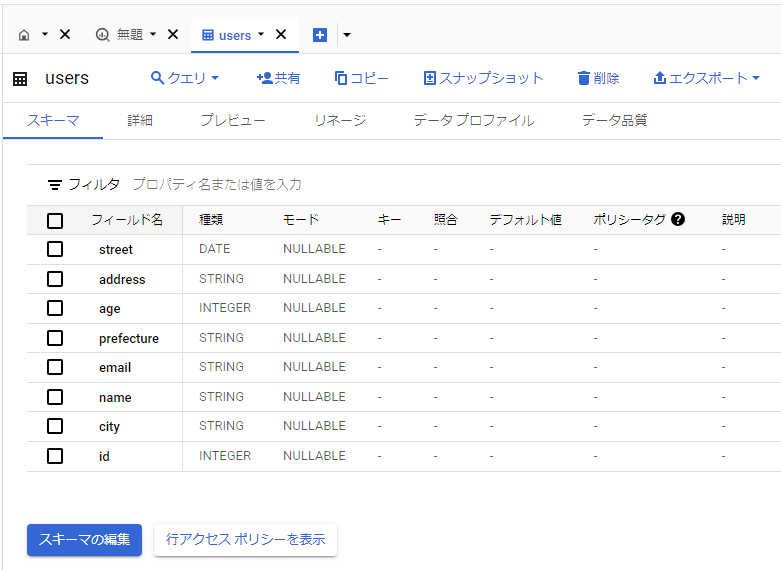 -
BigQuery loading process
- BigQuery の読み込み用の一時ディレクトリです
- 例:gs://ex-bucket-2022/sample/temp/
-
ストリーミング モード 一時的な場所
- 一時ファイルを書き込むためのパスとファイル名の接頭辞
- 例:gs://ex-bucket-2022/temp/
3. オプションパラメータの設定
- JavaScript UDF path in Cloud Storage
- ユーザー定義関数を含む JavaScript コード の Cloud Storage 配置先です
- 例:gs://ex-bucket-2022/dataflow.js
- 今回使用した UDF
dataflow.jsload("nashorn:mozilla_compat.js"); importPackage(java.io); importPackage(javax.xml.parsers); importPackage(org.xml.sax); function transform(line) { var inputSource = new InputSource(new StringReader(line)); var factory = DocumentBuilderFactory.newInstance(); var builder = factory.newDocumentBuilder(); var document = builder.parse(inputSource); var jsonString = {}; var elements = document.getElementsByTagName("*"); for (var i = 0; i < elements.length; i++) { var element = elements.item(i); if(element.tagName != "user") { jsonString[element.tagName] = element.textContent; } } return JSON.stringify(jsonString); }
4. ジョブの実行
「2. 必須パラメータの設定」で設定した Cloud Storage Input File の場所に XML ファイルを配置することでジョブを起動します。今回使用した XML ファイルは以下の通りです。
sample.xml
<user>
<id>10000</id>
<name>山田花子</name>
<email>hanako.yamada@example.com</email>
<age>29</age>
<address>
<prefecture>東京都</prefecture>
<city>渋谷区</city>
<street>1-2-3</street>
</address>
</user>
ジョブ実行結果
ジョブ起動後、BigQuery のテーブルを開くとデータが格納されていることが確認できます。

ジョブ実行時の注意点
- ジョブ実行前に、必要な権限が付与されていることを確認します
- 処理データ量やジョブ実行時間によって、コストが発生します
前準備
BigQuery データセットを作成する
以下のJSONファイルをインポートし、スキーマを自動生成しています。
sample.json
{
"id": "12345",
"name": "山田太郎",
"email": "taro.yamada@example.com",
"age": "30",
"address": "東京都渋谷区1-2-3",
"prefecture": "東京都",
"city": "渋谷区",
"street": "1-2-3"
}
ユーザー定義関数(UDF)を作成する
UDF JavaScript コードは Nashorn JavaScript エンジンで実行されます。デプロイ前に Nashorn エンジンで UDF をテストします。カレントディレクトリに前述の dataflow.js があるものとします。
- JDK 11 がプリインストールされている Cloud Shell にて次のコマンドを実行します
jjs
- 次に以下のコマンドを実行し、dataflow.js をテストします
jjs> load('dataflow.js')
jjs> var input = "<user><id>12345</id><name>山田太郎</name><email>taro.yamada@example.com</email><age>30</age><address><prefecture>東京都</prefecture><city>渋谷区</city><street>1-2-3</street></address></user>"
jjs> var output = transform(input)
jjs> print(output)
{"id":"12345","name":"山田太郎","email":"taro.yamada@example.com","age":"30","address":"東京都渋谷区1-2-3","prefecture":"東京都","city":"渋谷区","street":"1-2-3"}
UDF の補足説明
- Nashorn JavaScript エンジンは Java のライブラリやパッケージを使用することができます
- "nashorn:mozilla_compat.js" をロードすることにより、Java のパッケージを読み込みます
- その他の詳細は参考資料にある公式サイトを確認してください
さいごに
今回は事前構築されたテンプレートを使用し、ジョブを構築しました。参考になれば幸いです。時間があればカスタムテンプレートを使用してジョブを構築してみたいと思います。
参考資料

Discussion