VITSのメルスペクトログラムとtorchaudio
概要
VITSとかでよく見るメルスペクトログラムをtorchaudioのメルスペクトログラムで再現するためにはどのようにすればよいか気になったので、調べてみました。
すでに自明なことだったかもしれませんが、自分用のメモとして残しておきます。
VITSのメルスペクトログラムは以下のようなコードで与えられます。
(正直VITSのメルスペクトログラムというと語弊があるような気がしていて、もっと前の実装(例:HiFi-GAN)にも含まれていたような気がするため初出がわかりません。)
簡単に言えばlibrosaのmel filter + torch.stftというながれでメルスペクトログラムに変換し、その後1e-5でclampした後にlogを取っています。
例えばJSUTのBASIC5000/BASIC5000_0001.wavを処理してみると、以下のメルスペクトログラムが出てきます。
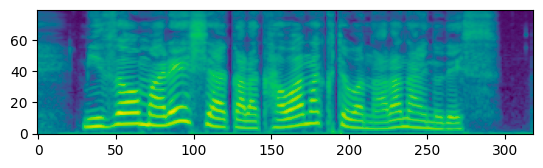
では、これをtorchaudioのMelSpectrogramで再現する方法はあるのでしょうか?
本記事では再現するための引数について説明していきます。
VITSのメルスペクトログラム
改めて流れを簡略化したコードで見てみます。
1. パディング
このコードではtorch.stftのcenter=Falseであるため、自前でパディングを行っています。
# y : 音声波形 [1, T]
pad_length = (n_fft - hop_length) // 2
y = F.pad(y, [pad_length, pad_length], mode='reflect')
2. STFT
Short-Time Fouerier Transformを行っていて、その後絶対値を取っています。
spec = torch.stft(y, n_fft, hop_length, win_length, window, center=False, normalized=False, onesided=True)
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
3. メルスペクトログラムへ
事前に以下のようにlibrosa.filters.melでフィルターバンクを作成しており、
from librosa.filters import mel as librosa_mel_fn
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
これを利用してメルスペクトログラムに変換しています。
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
4. Log-Melへ
最後にLogスケールへ変換します。
この際にlogの定義域を考慮して1e-5にclampしています
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
return torch.log(torch.clamp(x, min=clip_val) * C)
def spectral_normalize_torch(magnitudes):
output = dynamic_range_compression_torch(magnitudes)
return output
spec = spectral_normalize_torch(spec)
torchaudioの場合
では、この処理をtorchaudioを用いて再現してみましょう。
ここで、注目する部分はlibrosa.filters.melです。
このmelの引数を見てみましょう。
重要な引数としては
- htk: bool = False
- use HTK formula instead of Slaney
- norm: {None, ‘slaney’, or number} [scalar] = 'slaney'
- If ‘slaney’, divide the triangular mel weights by the width of the mel band (area normalization).
です。
つまり、メルスケールの定義として slaneyを使用していて、各フィルタはフィルタのバンド帯の幅で正規化されていることを示しています。
これはtorchaudioのMelSpectrogramではどの引数に対応するでしょうか?
を眺めてみると
- norm: Optional[str] = None
- If “slaney”, divide the triangular mel weights by the width of the mel band (area normalization). (Default: None)
- mel_scale: Optional[str] = 'htk'
- Scale to use: htk or slaney. (Default: htk)
まさに対応していそうな引数がありました。
また、VITSのメルスペクトログラムでは絶対値をとり、振幅スペクトルを使っているのでした。
一方で、torhcaudio.MelSpectrogramの対応する引数は
- power (float, optional) – Exponent for the magnitude spectrogram, (must be > 0) e.g., 1 for energy, 2 for power, etc. (Default: 2)
となっていて、デフォルトではパワースペクトル(power = 2)で計算を行っています。
なので、この引数はpower = 1にするべきでしょう。
以上の引数をもとにtorchaudio.MelSpectrogramで再現を行ってみましょう。
以下のようにtorchaudio.MelSpectrogramを継承するとすっきり書けそうです。
import torch
import torch.nn.functional as F
from torchaudio.transforms import MelSpectrogram
class MyMelSpectrogram(MelSpectrogram):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.pad_length = (self.n_fft - self.hop_length) // 2
def forward(self, wav):
# 1. パディング
wav = F.pad(wav, [self.pad_length, self.pad_length], mode='reflect')
# 2. STFT
spec = self.spectrogram(wav)
# 3. メルスペクトログラムへ
mel = self.mel_scale(spec)
# 4. Log-Melへ
mel = torch.log(torch.clamp_min(mel, min=1e-5))
return mel
今までの議論を反映すると以下のような引数にすれば良さそうです。
my_mel_spectrogram = MyMelSpectrogram(
sample_rate=24000,
n_fft=1024,
win_length=1024,
hop_length=256,
power=1,
f_min=0,
f_max=12000,
n_mels=80,
mel_scale='slaney',
norm='slaney',
center=False
)
実験
では、実際に試してみます。
# wav : [1, 76560]
wav, _ = torchaudio.load('wav24k/BASIC5000_0001.wav')
# VITSのメルスペクトログラム
mel_vits = mel_spectrogram_torch(
wav,
sampling_rate=24000,
n_fft=1024,
win_size=1024,
hop_size=256,
fmin=0,
fmax=12000,
num_mels=80,
center=False
).squeeze(0)
# torchaudioのメルスペクトログラム
mel_torchaudio = MyMelSpectrogram(
sample_rate=24000,
n_fft=1024,
win_length=1024,
hop_length=256,
power=1,
f_min=0.0,
f_max=12000,
n_mels=80,
mel_scale='slaney',
norm='slaney',
center=False
)(wav).squeeze(0)
>>> F.mse_loss(mel_vits, mel_torchaudio)
tensor(3.0439e-12)
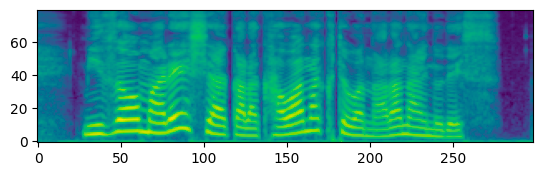
以上のようにほぼ値が一致していることがわかります。
mel_vits

mel_torchaudio
Discussion