🗂
【ABCI3.0】 シングルノードおよびマルチノードでのDDP学習
本ブログの概要
ABCI 3.0を活用し、シングルノードおよびマルチノードでDistributed Data Parallel(以下、DDP)を実行する方法をご紹介
背景
- 画像生成モデルをABCI 3.0上で構築するにあたり、複数GPUを効率的に活用して学習を行う必要が発生
- DDPを用いてシングルノード(rt_HFを1つ使用)で実行していたが、より一層の高速化を図るため、マルチノード(rt_HFを複数使用)環境でのDDPへ拡張
(※ABCIにおける資源タイプ「rt_HF」とは、H200 GPUが8基搭載されているノードを指す) - なお、学習対象のモデルサイズは約0.15Bであり、1 GPUに収まる規模であるため、本手順ではModel Parallelは用いず、DDPのみで並列化
シングルノードでのDDP
シングルノードでのDDPでは、ノード間通信が必要ないため、MPIやGPUのlocal_rankやglobal_rankを気にせずコードを書く事が可能
シングルノードでのDDP実行に必要なコードは、実行スクリプトと各プロセスの呼び出しであるため、以下に該当箇所を記載
実行スクリプト
run_pipeline.sh
#!/bin/sh
#PBS -q rt_HF
#PBS -l select=1
#PBS -l walltime=1:00:00
#PBS -P [group_name]
cd ${PBS_O_WORKDIR}
export PYTHONPATH=${PBS_O_WORKDIR}:$PYTHONPATH
export RESULTS_DIR="results/${PBS_JOBID}"
mkdir -p ${RESULTS_DIR}
source /etc/profile.d/modules.sh
module load cuda/12.6/12.6.1 cudnn/9.5/9.5.1
module load hpcx/2.20
source venv/bin/activate
python scripts/train.py 2>&1 | tee ${RESULTS_DIR}/output.txt
上記のrun_pipeline.shを使用する上で必要な対応事項
- [group_name]は自分の所属するgroup名に置き換え
- 事前にvenvという仮想環境を構築し必要なパッケージはインストールしておく
- walltimeに最大実行時間を設定(本スクリプトでは1時間に設定)
各プロセスの呼び出し
scripts/train.py
import argparse
import time
import os
from typing import List
import torch
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler
import torch.multiprocessing as mp
def setup(rank:int , world_size: int)-> None:
"""
Initialize the distributed environment for multi-GPU training.
Args:
rank: GPU ID for the current process
world_size: Total number of GPUs available
Returns:
None
"""
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# Initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def print_only_rank0(log: str)-> None:
"""
Print a log message only from rank 0 process.
Args:
log: Message to log
Returns:
None
"""
try:
if dist.is_initialized() and dist.get_rank() == 0:
print(log)
except:
# Fallback for when the process group isn't initialized
# In single process mode, always print
if not dist.is_initialized():
print(log)
def cleanup() -> None:
"""
Clean up the distributed environment.
Returns:
None
"""
dist.destroy_process_group()
def train(
rank: int,
world_size: int,
train_dataset: Dataset,
args: argparse.Namespace
) -> None:
"""
Main training function for each process.
Args:
rank: GPU ID for the current process
world_size: Total number of GPUs available
train_dataset: Dataset for training
args: Command line arguments
Returns:
None
"""
setup(rank, world_size)
device = torch.device(f"cuda:{rank}")
# Create model and move to device
rectified_flow = ...
rectified_flow = rectified_flow.to(rank)
ddp_model = DDP(rectified_flow, device_ids=[rank])
optimizer = optim.Adam(ddp_model.parameters(), lr=args.lr)
# Create dataset and dataloader with DistributedSampler
train_sampler = DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=rank,
shuffle=True,
)
train_loader = DataLoader(
train_dataset,
batch_size=args.batch_size,
sampler=train_sampler,
num_workers=args.num_workers,
pin_memory=True,
shuffle=(train_sampler is None),
drop_last=True,
)
print_only_rank0(f"Train loader batch size: {train_loader.batch_size}")
start_training = time.time()
loss_history = []
start_epoch = 0
# Training loop
for epoch in range(start_epoch, start_epoch + args.epochs):
stat_time = time.time()
# Set epoch for DistributedSampler
train_sampler.set_epoch(epoch)
# Train
ddp_model.train()
running_loss = 0.0
total = 0
for idx, inputs in enumerate(train_loader):
inputs = inputs.to(rank)
n = inputs.shape[0]
optimizer.zero_grad()
loss = ddp_model(inputs)
loss.backward()
optimizer.step()
running_loss += loss.item()
total += n
train_loss = running_loss / len(train_loader)
# すべてのプロセスからの損失を集計
world_size = dist.get_world_size()
all_losses = torch.tensor([train_loss], device=device)
dist.all_reduce(all_losses, op=dist.ReduceOp.SUM)
average_train_loss = all_losses.item() / world_size
loss_history.append(average_train_loss)
dist.barrier()
end_time = time.time()
print_only_rank0(f"Epoch {epoch+1} took {end_time - stat_time:.2f} sec., total_time: {end_time - start_training:.2f} sec.")
print_only_rank0('-----------------------------------------------------------')
print_only_rank0(f"Training completed in {(time.time() - start_training)/60:.2f} minutes")
# Clean up
if world_size > 1:
cleanup()
def parse_arguments():
"""
Parse command line arguments for the training script.
Returns:
argparse.Namespace: Parsed command-line arguments
"""
parser = argparse.ArgumentParser(description="Training script with DDP support")
# Training parameters
parser.add_argument('--batch_size', type=int, default=32, help='Batch size per GPU')
parser.add_argument('--epochs', type=int, default=400, help='Number of training epochs')
parser.add_argument('--lr', type=float, default=0.0001, help='Learning rate')
parser.add_argument('--seed', type=int, default=42, help='Random seed')
# System parameters
parser.add_argument('--num-workers', type=int, default=16, help='Number of data loading workers')
parser.add_argument('--save-every', type=int, default=10, help='Save checkpoint every N epochs')
parser.add_argument('--output-dir', type=str, default='results', help='Output directory')
parser.add_argument('--checkpoint', type=str, default=None, help='Path to checkpoint for resuming training')
return parser.parse_args()
def main():
# Parse command line arguments
args = parse_arguments()
world_size = torch.cuda.device_count()
train_data = ...
mp.spawn(
train,
args=(world_size, train_data, args),
nprocs=world_size,
join=True
)
if __name__ == "__main__":
main()
上記のscripts/train.pyを使用する上で対応が必要な事項
- rectified_flow部分は自身のモデルクラスで置き換え(想定している基底クラス:torch.nn.Module)
- train_data部分は自身のデータセットクラスで置き換え(想定している基底クラス:torch.utils.data.Dataset)
- 学習経過や学習したモデルの表示・保存は自身で追加
マルチノードでのDDP
マルチノードでの学習時にはノード間通信が必要になるため、必要な設定がシングルノードでの学習時と異なる。シングルノードでのDDPと同様に実行スクリプトと各プロセスの呼び出しを下記に記載
実行スクリプト
run_pipeline_multi_node.sh
#!/bin/sh
#PBS -q rt_HF
#PBS -l select=4:mpiprocs=192
#PBS -l walltime=1:00:00
#PBS -P [group_name]
cd ${PBS_O_WORKDIR}
export PYTHONPATH=${PBS_O_WORKDIR}:$PYTHONPATH
export RESULTS_DIR="results/${PBS_JOBID}"
mkdir -p ${RESULTS_DIR}
source /etc/profile.d/modules.sh
module load cuda/12.6/12.6.1 cudnn/9.5/9.5.1
module load hpcx/2.20
source venv/bin/activate
mpirun -np ${NUM_PROCESSES} -map-by ppr:8:node -hostfile $PBS_NODEFILE python scripts/train_multi_node.py 2>&1 | tee ${RESULTS_DIR}/output.txt
上記のrun_pipeline_multi_node.shを使用する上で必要な対応事項
- 実行スクリプト(run_pipeline.sh)における必要な対応事項と同様
-
#PBS -l select=4を必要なノードに変更(上記の例は4ノード使用)。:mpiprocs=192は変更しない
実行スクリプト
scripts/train_multi_node.py
# マルチノード用setup関数
def setup(rank, world_size)-> None:
"""
Initialize the distributed environment for multi-GPU training.
Args:
rank: GPU ID for the current process
world_size: Total number of GPUs available
Returns:
None
"""
+ # 環境変数が設定されていなければデフォルト値を使用
+ master_addr = os.environ.get('MASTER_ADDR', 'localhost')
+ master_port = os.environ.get('MASTER_PORT', '12355')
+
+ # 分散プロセスグループを初期化
+ try:
+ dist.init_process_group(
+ "nccl",
+ init_method=f"tcp://{master_addr}:{master_port}",
+ rank=rank,
+ world_size=world_size
+ )
+ print(f"プロセス {rank} が初期化されました (world_size: {world_size})")
+ except Exception as e:
+ print(f"プロセスグループの初期化に失敗: {e}")
+ raise e
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = '12355'
-
- # Initialize the process group
- dist.init_process_group("nccl", rank=rank, world_size=world_size)
# マルチノード用train関数
def train(
rank: int,
world_size: int,
train_dataset: Dataset,
args: argparse.Namespace
) -> None:
"""
Main training function for each process.
Args:
rank: GPU ID for the current process
world_size: Total number of GPUs available
train_dataset: Dataset for training
args: Command line arguments
Returns:
None
"""
+ # MPIランクを取得
+ mpi_rank = int(os.environ.get('OMPI_COMM_WORLD_RANK', '0'))
+ mpi_size = int(os.environ.get('OMPI_COMM_WORLD_SIZE', '1'))
+ local_rank = mpi_rank % torch.cuda.device_count()
+ print("="*100)
+ print(f"MPI rank: {mpi_rank}, local rank: {local_rank}, world size: {mpi_size}")
+ print("="*100)
+ # GPUをローカルランクに設定
+ device = torch.device(f"cuda:{local_rank}")
+ torch.cuda.set_device(local_rank)
+ # 分散環境を初期化
+ setup(mpi_rank, mpi_size)
+ # ランク情報を更新
+ rank = mpi_rank
+ world_size = mpi_size
- setup(rank, world_size)
- device = torch.device(f"cuda:{rank}")
# Create model and move to device
rectified_flow = ...
+ rectified_flow = rectified_flow.to(device)
- rectified_flow = rectified_flow.to(rank)
# Wrap model with DDP
+ ddp_model = DDP(
+ rectified_flow,
+ device_ids=[device.index],
+ output_device=device.index,
+ broadcast_buffers=False, # 通信オーバーヘッドを削減
+ find_unused_parameters=False, # パフォーマンス向上
+ gradient_as_bucket_view=True # ストライド問題に対処
+ )
- ddp_model = DDP(rectified_flow, device_ids=[rank])
optimizer = optim.Adam(ddp_model.parameters(), lr=args.lr)
# Create dataset and dataloader with DistributedSampler
train_sampler = DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=rank,
shuffle=True,
)
train_loader = DataLoader(
train_dataset,
batch_size=args.batch_size,
sampler=train_sampler,
pin_memory=True,
shuffle=(train_sampler is None),
drop_last=True,
)
print_only_rank0(f"Train loader batch size: {train_loader.batch_size}")
start_training = time.time()
loss_history = []
start_epoch = 0
# Training loop
for epoch in range(start_epoch, start_epoch + args.epochs):
stat_time = time.time()
# Set epoch for DistributedSampler
train_sampler.set_epoch(epoch)
# Train
ddp_model.train()
running_loss = 0.0
total = 0
for idx, inputs in enumerate(train_loader):
+ inputs = inputs.to(device)
- inputs = inputs.to(rank)
n = inputs.shape[0]
optimizer.zero_grad()
loss = ddp_model(inputs)
loss.backward()
optimizer.step()
running_loss += loss.item()
total += n
train_loss = running_loss / len(train_loader)
# すべてのプロセスからの損失を集計
world_size = dist.get_world_size()
all_losses = torch.tensor([train_loss], device=device)
dist.all_reduce(all_losses, op=dist.ReduceOp.SUM)
average_train_loss = all_losses.item() / world_size
loss_history.append(average_train_loss)
dist.barrier()
end_time = time.time()
print_only_rank0(f"Epoch {epoch+1} took {end_time - stat_time:.2f} sec., total_time: {end_time - start_training:.2f} sec.")
print_only_rank0('-----------------------------------------------------------')
print_only_rank0(f"Training completed in {(time.time() - start_training)/60:.2f} minutes")
# Clean up
if world_size > 1:
cleanup()
def main():
# Parse command line arguments
args = parse_arguments()
+ local_rank = int(os.environ.get('OMPI_COMM_WORLD_RANK', '0')) % torch.cuda.device_count()
+ world_size = int(os.environ.get('OMPI_COMM_WORLD_SIZE', '1'))
- world_size = torch.cuda.device_count()
train_data = ...
+ train(local_rank, world_size, train_data, args)
- mp.spawn(
- train,
- args=(world_size, train_data, args),
- nprocs=world_size,
- join=True
- )
if __name__ == "__main__":
main()
上記のscripts/train_multi_mode.pyを使用する上で必要な対応事項
-
print_only_rank0関数,cleanup関数,parse_arguments関数はシングルノードと同様のため省略(可動性の観点より) - シングルノードと同様にtrain_data, rectified_flow部分は自身のデータセットやモデルに置き換え
- シングルノードからマルチノードに増やした場合、
--batch_sizeを調整して、Global_batchサイズを合わせる必要(同じ--batch_sizeに設定した場合、損失の減少速度が遅くなる)
実験結果と考察
学習速度
| ノード数 | batch_size | 平均学習時間/Epoch |
|---|---|---|
| 1 | 32 | 119.34 ± 1.51 秒 |
| 4 | 8 | 44.51 ± 2.69 秒 |
損失の推移
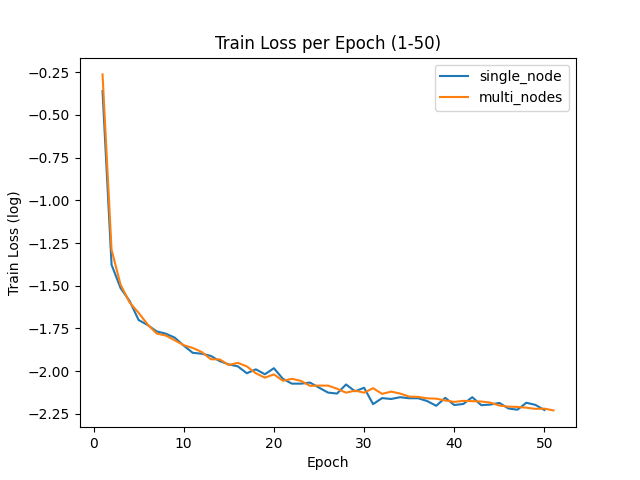
考察
ノード数を4倍にすることで、学習時間の短縮と損失減少幅の維持が可能
- ノード数の増加により、学習時間が約2.7倍高速化
- 損失の推移の図から、損失の減少速度はシングルノードの減少速度と同水準を維持
一方、長時間の学習が許容される場合は、シングルノードを長時間使用する方が消費リソースが少なく、効率的な選択肢
- シングルノードを4倍の時間使用することで、ポイント消費を抑制
今後
モデルサイズの拡大により1GPUに収まらないケースでは、Model Parallelの導入を検討する必要
参考サイト
Discussion